Delta Lake and its relevance
As the data world races towards generating, storing, processing and consuming humongous amount of data through AI, ML and other trending technologies, the demand for independently scalable storage and compute capabilities is ever increasing to deal with the constant need of adding (APPEND) and changing (UPSERT & MERGE) data to the datasets being trained and consumed through AI, ML etc.
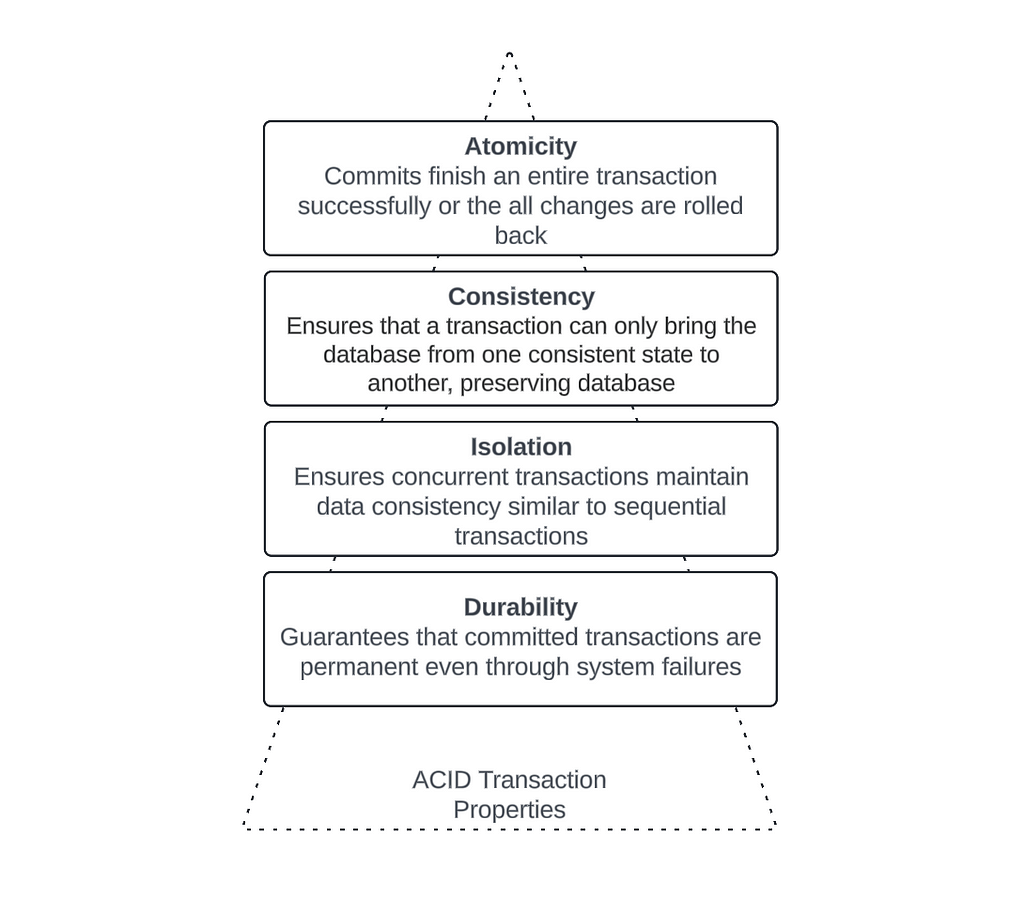
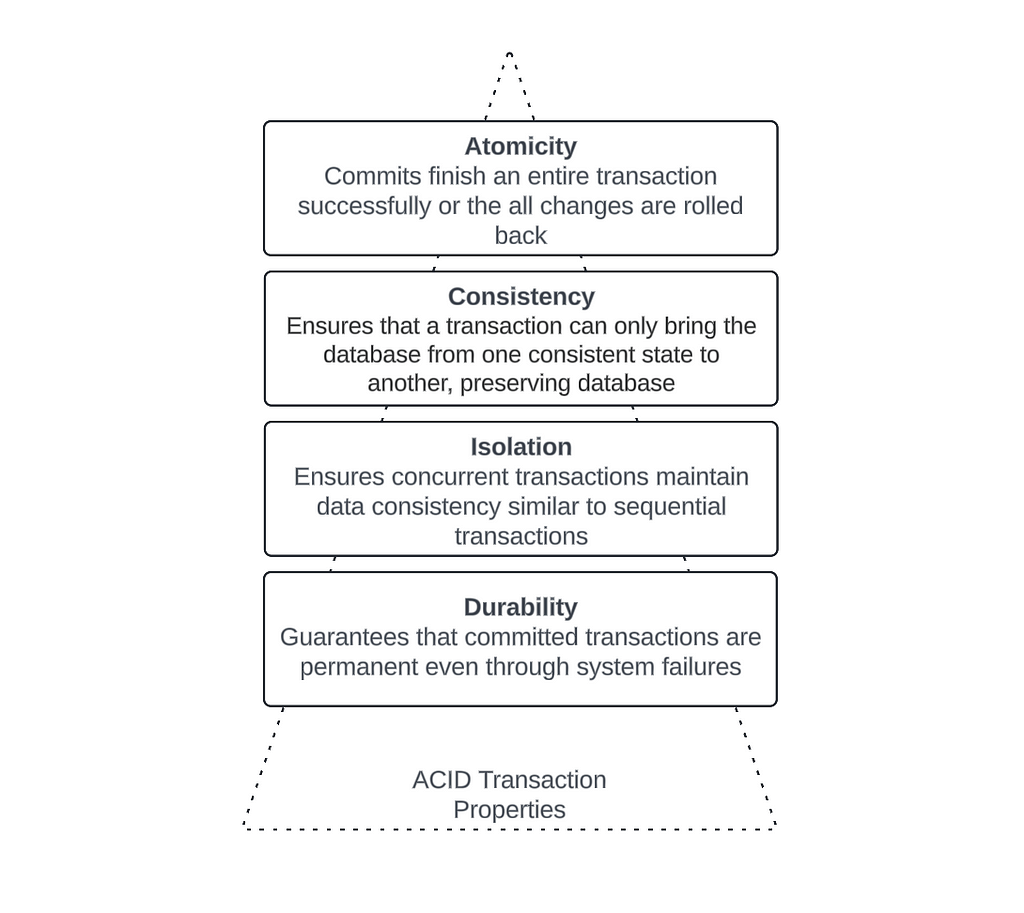
While Parquet based data lake storage, offered by different cloud providers, gave us the immense flexibilities during the initial days of data lake implementations, the evolution of business and technology requirements in current days are posing challenges around those implementations. While we still like to use the open storage format of Parquet, we now need features like ACID transactions, Time Travel and Schema Enforcements in our data lakes. These were some of the main drivers behind the inception of Delta Lake as an abstraction layer on top of the parquet based data storage. A quick reference to the ACID is described in the diagram below.
Delta Lake (current GA version 3.2.0) brings us many different capabilities, some of which were mentioned above. But in this article, I want to discuss a specific area of ACID transactions, namely Consistency and how we can decide whether to use this Delta Lake feature out of the box or add our own customization around the feature to fit it to our use cases. In the process, we will also discuss some of the inner workings of Delta Lake. Let’s dig in!
What is Data Consistency?
Data Consistency is a basic database or data term that we have used and abused for as long as we have had data stored in some shape and form. In simple terms, it is the accuracy, completeness, and correctness of data stored in a database or in a dataset, providing protection to data consuming applications from partial or unintended state of data while constant transactions are changing the underlying data.

As shown in the diagram above, data queries on the dataset should get the consistent state of the data on the left until the transaction is complete and the changes have been committed creating the next consistent state on the right. Changes being made by the transaction cannot be visible while the transaction is still in progress.
Consistency in Delta Lake
Delta Lake implements the consistency very similar to how the relational databases implemented it; however Delta Lake had to address few challenges:
- the data is stored in parquet format and hence immutable, which means you cannot modify the existing files, but you can delete or overwrite them.
- The storage and compute layers are decoupled and hence there is no coordination layer between the transactions and reads.
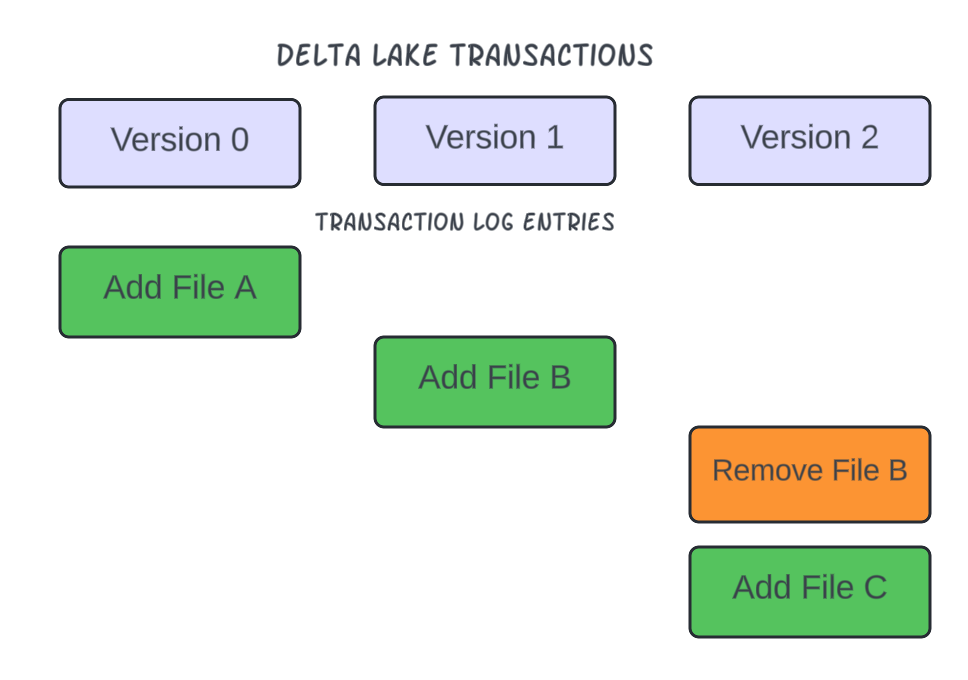
This coordination and consistency is orchestrated in Delta Lake using the very soul of Delta Lake; the Delta Transaction Logs.
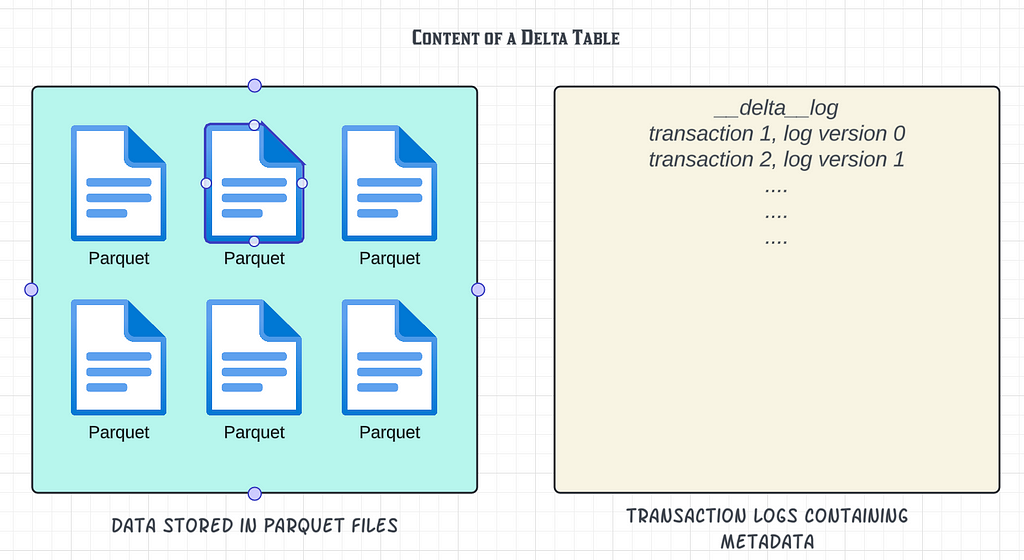
The concept is simple yet extremely powerful. The mere existence of a data (parquet) file isn’t enough for the content data to be part of query outputs, until the data file is also tracked in the transaction logs. If a file is marked as obsolete or removed from the transaction logs, the file will still exist at the location (until a Delta Lake vacuum process deletes the files) but will not be considered part of the current consistent state of the table.
Transaction logs are also used to enforce the schema validation to ensure consistency of data structure across all data files. Schema validation was a major lack of feature in vanilla parquet based data storage and each application had to build and maintain the schema validation mechanism.
These Delta Transaction Log based concepts allowed Delta Lake to implement the transaction flow in three steps:
- Read:
- This phase is applicable for UPSERT and MERGE only. When the transaction is submitted to the Delta table, Delta uses the transaction logs and determines which underlying files in the current consistent version of the table need to be modified (rewritten). The current consistent version of the table is determined by the content of the tracked parquet files in the transaction logs. If there is a file present in the dataset location, but it isn’t tracked in the transactions logs (either marked as obsolete by another transaction or wasn’t added to the logs due to a failed transaction), the content of that file is not considered as part of the current consistent version of the table. Once the determination is complete on the impacted files, Delta Lake reads those files.
- If the transaction is APPEND only, that means no existing file is impacted by the transaction and hence Delta Lake does not have to read any existing file into memory. It is important to note that, Delta Lake does not need to read the underlying files for the schema definition. The schema definition is maintained within the transaction logs instead and the logs are used to validate and enforce the schema definition in all underlying files of a Delta table.
2. Generate the output of the transaction and Write to a file: In this phase, Delta Lake first executes the transaction (APPEND, DELETE or UPSERT) in memory and writes the output to new parquet data files at the dataset location used to define the delta table. But remember, the mere presence of the data files would not make the content of these new files part of the Delta table, not yet. This write process is considered as “staging” of data in the Delta table.
3. Validate current consistent state of the table and commit the new transaction:
- Delta Lake now arrives at the final phase of generating a new consistent state of the table. In order to achieve that, checks are done in the existing transaction logs to determine whether the proposed changes conflict with any other changes that may have been concurrently committed since the last consistent state of the table was read by the transaction. The conflict arises when two concurrent transactions are aiming to change the content of the same underlying file(s). Let’s take an example to elaborate this a little. Let’s say, two concurrent transactions against the HR table are trying to update two rows that exist in the same underlying file. Therefore, both transactions will rewrite the content of the same file with the changes they are bringing in and will try to obsolete the same file in the transaction logs. The first transaction to commit will not have any issues committing the change. It will generate a new transaction log, add the newly written file to the log and mark the old file as obsolete. Now consider the 2nd transaction doing the commit and going through the same steps. This transaction will also need to mark the same old file as obsolete, but it finds that the file has already been marked obsolete by another transaction. This is the situation that is now considered a conflict for the 2nd transaction and Delta Lake will not allow the transaction to make the commit, thereby causing a write failure for the 2nd transaction.
- If no conflict is detected, all the “staged” changes made during the Write phase are committed as a new consistent state of the Delta table by adding the new files to the new Delta transaction log, and the write operation is marked as successful.
- If Delta Lake detects conflicts, the write operation fails and throws an exception. This failure prevents inclusion of any parquet file to the table that can lead to data corruption. Please note that the corruption of data here is logical and not physical. This is a very important part to remember to understand our upcoming discussion on another great feature of Delta Lake, namely Optimistic Concurrency.
What is Optimistic Concurrency in Delta Lake?
In very simple terms, Delta Lake allows concurrent transactions on Delta tables with the assumption that most of the concurrent transactions on the table could not conflict with one another mainly because each transaction would write to its own parquet file; however conflicts can occur if two concurrent transactions are trying to make changes to the content of same existing underlying files. One thing worthy of noting again though that Optimistic Concurrency does not compromise on data corruption.
Let’s elaborate this with a flow diagrams that show the possible concurrent operation combinations, the possibilities of conflicts and how Delta Lake prevents data corruption irrespective of the type of transactions.
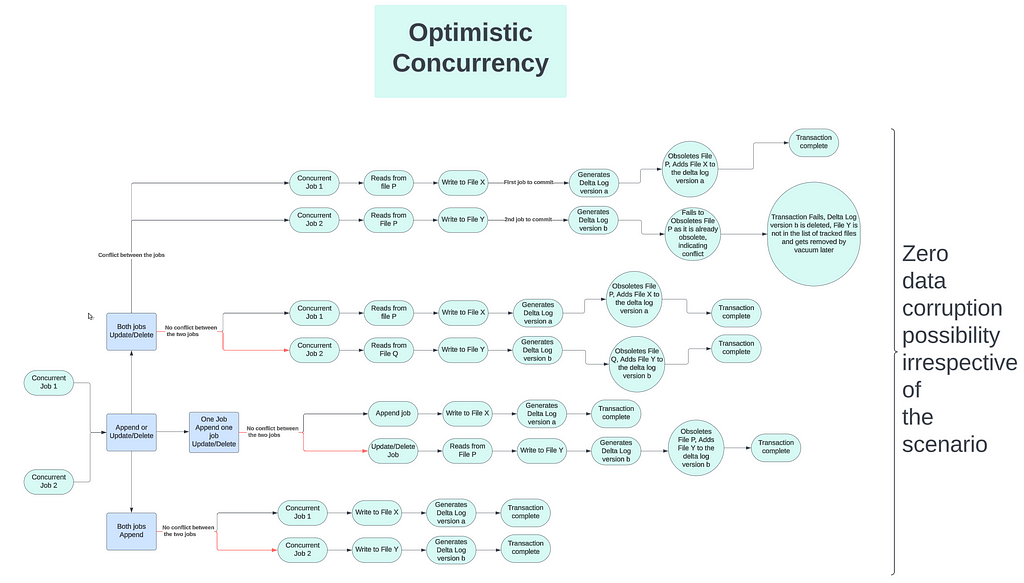
Let’s talk about the scenarios in little details. The flow diagram above shows two concurrent transactions in each combination scenarios. But you can scale the concurrency to any number of transactions and the logic would remain same.
- Append only: This is the easiest of all the combination scenarios. Each append transaction writes the new content to a new file and thus will never have any conflict during the validate and commit phase.

2. Append and Upsert/Delete combo: Once again, the appends cannot have any conflict with ANY other transaction. Hence, even this combination scenario will not result into any conflict ever.

3. Multiple concurrent Upsert/Delete without conflict: Refer back to the above example I used to explain what is conflict. Now consider, that the two transactions against the HR table trying to update two rows that exist in two different files. That mans both transactions are rewriting a new version of two different files. Thus, there is no conflict between these two transactions and they both will be successful. This is the biggest benefit of Optimistic Concurrency…allowing concurrent changes to the same table but different underlying files. Again, the Delta Transaction Log plays a big part in this. When the first transaction commits, it obsoletes (say) file X and adds file Y to the new transaction log; while the 2nd transaction obsoletes file P and adds file Q during commit and generates another transaction log.

4. Multiple concurrent Upsert/Delete with conflict: I already explained this scenario while explaining conflict and this remains the only possible scenario when a conflict can occur causing transaction failures.

Do you need to mitigate the conflict related failures?
Why do we even need to talk about mitigating the failures? An easy mitigation is to just rerun the failed transaction(s)…as easy as that!! Isn’t it? Well, not really!
The need of mitigation beyond rerunning the failed transactions would depend on the type of applications consuming the Delta tables. The type of application will determine how many failures are possible and how expensive, from cost and SLA and functionality perspective, the rerunning of transactions would be. The cost of rerunning transactions will determine whether we need to build a custom solution to avoid these costly reruns. Remember though, that a custom solution will come at the expense of some other trade offs. Implementation of concurrency control will depend on the organization and the decisions it takes on its priorities.
Let’s consider a customer relationship management application built on Delta Tables. The distributed multi-user nature of the application and frequent row level data changes triggered through the application means that the percentage of conflicting transaction scenario would be very high in this case, thereby rerunning failed transactions would be very expensive both from execution cost, SLA and user experience point of view. In this scenario, a custom transaction management solution will be required to manage concurrency.
On the other hand, a pure data lake scenario, where most of the transactions being append with occasional updates or deletes will mean the conflict scenarios could be as low as 1% or less. In such cases, rerunning the failed transactions would be far less expensive than building and maintaining a custom solution. Not to mention it would be quite unreasonable to penalize (by implementing a custom mitigation) the 99% successful transactions over 1% or less chances of failures.
Possible mitigation options for concurrency management
Implementing a locking mechanism on Delta table is a popular way of managing concurrency. In this option, a transaction will “acquire” a lock on the table and all other transactions would wait for the lock to be released on completion of this transaction. Acquiring a lock can be as simple as updating a file adding the Delta table name. Once the transaction completes, it will remove the table name from the file, thus “releasing” the lock.
This is where I finally go back to the title of this article. To lock or not to lock. Since appends will never have any conflict with any other transaction, there is no need of implementing a lock mechanism for append transactions, whether it is a transactional application or a data lake. And the decision to lock or not for UPSERTs and MERGEs, as explained above, would depend on how big on percentage scale the transaction failures would be. You can also consider implementing a combination of no-lock-for-appends and lock-for-upsert-and-merge.
The goal of this article was to explain the inner workings of Delta Lake on the concurrency management front and to arm you with the understanding of whether or not to build a custom concurrency management solution. I hope this article will give you a good head-start on taking this decision.
Future versions of Delta Lake will bring more matured concurrency management solutions that will possibly eliminate the need of a custom built concurrency management solution altogether. I will write a timely article on that once the features become generally available to all. Until then, Happy Data Engineering with Delta Lake!
Note: I would like to make it known that I primarily did my research on this Delta Lake feature on Delta Lake product website. The rest of the content is based on my personal experience and proof of concept work on the feature. What inspired me to write this article is that, I have observed we often overlook some of the out-of-the-box features of products we implement and get into developing a solution that already exists and can be re-used.
Delta Lake Optimistic Concurrency Control: To Lock or Not to Lock? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Delta Lake Optimistic Concurrency Control: To Lock or Not to Lock?
Go Here to Read this Fast! Delta Lake Optimistic Concurrency Control: To Lock or Not to Lock?