Bringing order to chaos while simplifying our search for the perfect nanny for our childcare
As a data science leader, I’m used to having a team that can turn chaos into clarity. But when the chaos is your own family’s nanny schedule, even the best-laid plans can go awry. The thought of work meetings, nap times, and unpredictable shifts have our minds running in circles — until I realized I could use the same algorithms that solve business problems to solve a very personal one. Armed with Monte Carlo simulation, genetic algorithms, and a dash of parental ingenuity, I embarked on a journey to tame our wild schedules, one algorithmic tweak at a time. The results? Well, let’s just say our nanny’s new schedule looks like a perfect fit.

Setting the Stage: The Great Schedule Puzzle
Our household schedule looks like the aftermath of a bull in a china shop. Parent 1, with a predictable 9-to-5, was the easy piece of the puzzle. But then came Parent 2, whose shifts in a bustling emergency department at a Chicago hospital were anything but predictable. Some days started with the crack of dawn, while others stretched late into the night, with no rhyme or reason to the pattern. Suddenly, what used to be a straightforward schedule turned into a Rubik’s Cube with no solution in sight.

We imagined ourselves as parents in this chaos. Mornings becoming a mad dash, afternoons always being a guessing game, and evenings — who knows? Our family was headed for a future of playing “who’s on nanny duty?” We needed a decision analytics solution that could adapt as quickly as the ER could throw us a curveball.
That’s when it hit me: what if I could use the same tools I rely on at work to solve this ever-changing puzzle? What if, instead of fighting against the chaos, we could harness it — predict it even? Armed with this idea, it was time to put our nanny’s schedule under the algorithmic microscope.
The Data Science Toolbox: When in Doubt, Simulate
With our household schedule resembling the aftermath of a bull in a china shop, it was clear that we needed more than just a calendar and a prayer. That’s when I turned to Monte Carlo simulation — the data scientist’s version of a crystal ball. The idea was simple: if we can’t predict exactly when chaos will strike, why not simulate all the possible ways it could go wrong?
Monte Carlo simulation is a technique that uses random sampling to model a system’s behavior. In this case, we’re going to use it to randomly generate possible work schedules for Parent 2, allowing us to simulate the unpredictable nature of their shifts over many iterations.
Imagine running thousands of “what-if” scenarios: What if Parent 2 gets called in for an early shift? What if an emergency keeps them late at the hospital? What if, heaven forbid, both parents’ schedules overlap at the worst possible time? The beauty of Monte Carlo is that it doesn’t just give you one answer — it gives you thousands, each one a different glimpse into the future.
This wasn’t just about predicting when Parent 2 might get pulled into a code blue; it was about making sure our nanny was ready for every curveball the ER could throw at us. Whether it was an early morning shift or a late-night emergency, the simulation helped us see all the possibilities, so we could plan for the most likely — and the most disastrous — scenarios. Think of it as chaos insurance, with the added bonus of a little peace of mind.
In the following code block, the simulation generates a work schedule for Parent 2 over a five-day workweek (Monday-Friday). Each day, there’s a probability that Parent 2 is called into work, and if so, a random shift is chosen from a set of predefined shifts based on those probabilities. We’ve also added a feature that accounts for a standing meeting on Wednesdays at 1pm and adjusts Parent 2’s schedule accordingly.
import numpy as np
def simulate_parent_2_schedule(num_days=5):
parent_2_daily_schedule = [] # Initialize empty schedule for Parent 2
for day in range(num_days):
if np.random.rand() < parent_2_work_prob: # Randomly determine if Parent 2 works
shift = np.random.choice(
list(parent_2_shift_probabilities.keys()),
p=[parent_2_shift_probabilities[shift]['probability'] for shift in parent_2_shift_probabilities]
)
start_hour = parent_2_shift_probabilities[shift]['start_hour'] # Get start time
end_hour = parent_2_shift_probabilities[shift]['end_hour'] # Get end time
# Check if it's Wednesday and adjust schedule to account for a meeting
if day == 2:
meeting_start = 13
meeting_end = 16
# Adjust schedule if necessary to accommodate the meeting
if end_hour <= meeting_start:
end_hour = meeting_end
elif start_hour >= meeting_end:
parent_2_daily_schedule.append({'start_hour': meeting_start, 'end_hour': end_hour})
continue
else:
if start_hour > meeting_start:
start_hour = meeting_start
if end_hour < meeting_end:
end_hour = meeting_end
parent_2_daily_schedule.append({'start_hour': start_hour, 'end_hour': end_hour})
else:
# If Parent 2 isn't working that day, leave the schedule empty or just the meeting
if day == 2:
parent_2_daily_schedule.append({'start_hour': 14, 'end_hour': 16})
else:
parent_2_daily_schedule.append({'start_hour': None, 'end_hour': None})
return parent_2_daily_schedule
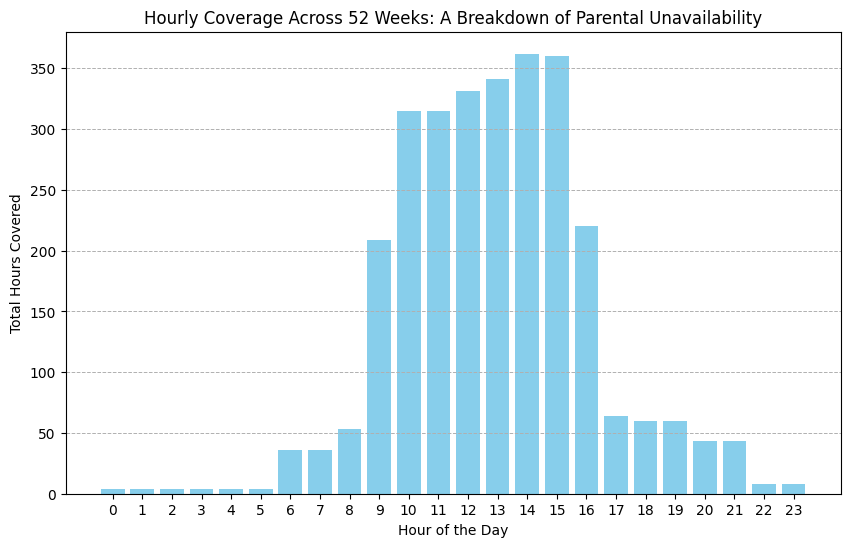
We can use the simulate_parent_2_schedule function to simulate Parent 2’s schedule over a workweek and combine it with Parent 1’s more predictable 9–5 schedule. By repeating this process for 52 weeks, we can simulate a typical year and identify the gaps in parental coverage. This allows us to plan for when the nanny is needed the most. The image below summarizes the parental unavailability across a simulated 52-week period, helping us visualize where additional childcare support is required.
Evolving the Perfect Nanny: The Power of Genetic Algorithms
Armed with simulation of all the possible ways our schedule can throw curveballs at us, I knew it was time to bring in some heavy-hitting optimization techniques. Enter genetic algorithms — a natural selection-inspired optimization method that finds the best solution by iteratively evolving a population of candidate solutions.

In this case, each “candidate” was a potential set of nanny characteristics, such as their availability and flexibility. The algorithm evaluates different nanny characteristics, and iteratively improves those characteristics to find the one that fits our family’s needs. The result? A highly optimized nanny with scheduling preferences that balance our parental coverage gaps with the nanny’s availability.
At the heart of this approach is what I like to call the “nanny chromosome.” In genetic algorithm terms, a chromosome is simply a way to represent potential solutions — in our case, different nanny characteristics. Each “nanny chromosome” had a set of features that defined their schedule: the number of days per week the nanny could work, the maximum hours she could cover in a day, and their flexibility to adjust to varying start times. These features were the building blocks of every potential nanny schedule the algorithm would consider.
Defining the Nanny Chromosome
In genetic algorithms, a “chromosome” represents a possible solution, and in this case, it’s a set of features defining a nanny’s schedule. Here’s how we define a nanny’s characteristics:
# Function to generate nanny characteristics
def generate_nanny_characteristics():
return {
'flexible': np.random.choice([True, False]), # Nanny's flexibility
'days_per_week': np.random.choice([3, 4, 5]), # Days available per week
'hours_per_day': np.random.choice([6, 7, 8, 9, 10, 11, 12]) # Hours available per day
}
Each nanny’s schedule is defined by their flexibility (whether they can adjust start times), the number of days they are available per week, and the maximum hours they can work per day. This gives the algorithm the flexibility to evaluate a wide variety of potential schedules.
Building the Schedule for Each Nanny
Once the nanny’s characteristics are defined, we need to generate a weekly schedule that fits those constraints:
# Function to calculate a weekly schedule based on nanny's characteristics
def calculate_nanny_schedule(characteristics, num_days=5):
shifts = []
for _ in range(num_days):
start_hour = np.random.randint(6, 12) if characteristics['flexible'] else 9 # Flexible nannies have varying start times
end_hour = start_hour + characteristics['hours_per_day'] # Calculate end hour based on hours per day
shifts.append((start_hour, end_hour))
return shifts # Return the generated weekly schedule
This function builds a nanny’s schedule based on their defined flexibility and working hours. Flexible nannies can start between 6 AM and 12 PM, while others have fixed schedules that start and end at set times. This allows the algorithm to evaluate a range of possible weekly schedules.
Selecting the Best Candidates
Once we’ve generated an initial population of nanny schedules, we use a fitness function to evaluate which ones best meet our childcare needs. The most fit schedules are selected to move on to the next generation:
# Function for selection in genetic algorithm
def selection(population, fitness_scores, num_parents):
# Normalize fitness scores and select parents based on probability
min_fitness = np.min(fitness_scores)
if min_fitness < 0:
fitness_scores = fitness_scores - min_fitness
fitness_scores_sum = np.sum(fitness_scores)
probabilities = fitness_scores / fitness_scores_sum if fitness_scores_sum != 0 else np.ones(len(fitness_scores)) / len(fitness_scores)
# Select parents based on their fitness scores
selected_parents = np.random.choice(population, size=num_parents, p=probabilities)
return selected_parents
In the selection step, the algorithm evaluates the population of nanny schedules using a fitness function that measures how well the nanny’s availability aligns with the family’s needs. The most fit schedules, those that best cover the required hours, are selected to become “parents” for the next generation.
Adding Mutation to Keep Things Interesting
To avoid getting stuck in suboptimal solutions, we add a bit of randomness through mutation. This allows the algorithm to explore new possibilities by occasionally tweaking the nanny’s schedule:
# Function to mutate nanny characteristics
def mutate_characteristics(characteristics, mutation_rate=0.1):
if np.random.rand() < mutation_rate:
characteristics['flexible'] = not characteristics['flexible']
if np.random.rand() < mutation_rate:
characteristics['days_per_week'] = np.random.choice([3, 4, 5])
if np.random.rand() < mutation_rate:
characteristics['hours_per_day'] = np.random.choice([6, 7, 8, 9, 10, 11, 12])
return characteristics
By introducing small mutations, the algorithm is able to explore new schedules that might not have been considered otherwise. This diversity is important for avoiding local optima and improving the solution over multiple generations.
Evolving Toward the Perfect Schedule
The final step was evolution. With selection and mutation in place, the genetic algorithm iterates over several generations, evolving better nanny schedules with each round. Here’s how we implement the evolution process:
# Function to evolve nanny characteristics over multiple generations
def evolve_nanny_characteristics(all_childcare_weeks, population_size=1000, num_generations=10):
population = [generate_nanny_characteristics() for _ in range(population_size)] # Initialize the population
for generation in range(num_generations):
print(f"n--- Generation {generation + 1} ---")
fitness_scores = []
hours_worked_collection = []
for characteristics in population:
fitness_score, yearly_hours_worked = fitness_function_yearly(characteristics, all_childcare_weeks)
fitness_scores.append(fitness_score)
hours_worked_collection.append(yearly_hours_worked)
fitness_scores = np.array(fitness_scores)
# Find and store the best individual of this generation
max_fitness_idx = np.argmax(fitness_scores)
best_nanny = population[max_fitness_idx]
best_nanny['actual_hours_worked'] = hours_worked_collection[max_fitness_idx]
# Select parents and generate a new population
parents = selection(population, fitness_scores, num_parents=population_size // 2)
new_population = []
for i in range(0, len(parents), 2):
parent_1, parent_2 = parents[i], parents[i + 1]
child = {
'flexible': np.random.choice([parent_1['flexible'], parent_2['flexible']]),
'days_per_week': np.random.choice([parent_1['days_per_week'], parent_2['days_per_week']]),
'hours_per_day': np.random.choice([parent_1['hours_per_day'], parent_2['hours_per_day']])
}
child = mutate_characteristics(child)
new_population.append(child)
population = new_population # Replace the population with the new generation
return best_nanny # Return the best nanny after all generations
Here, the algorithm evolves over multiple generations, selecting the best nanny schedules based on their fitness scores and allowing new solutions to emerge through mutation. After several generations, the algorithm converges on the best possible nanny schedule, optimizing coverage for our family.
Final Thoughts
With this approach, we applied genetic algorithms to iteratively improve nanny schedules, ensuring that the selected schedule could handle the chaos of Parent 2’s unpredictable work shifts while balancing our family’s needs. Genetic algorithms may have been overkill for the task, but they allowed us to explore various possibilities and optimize the solution over time.
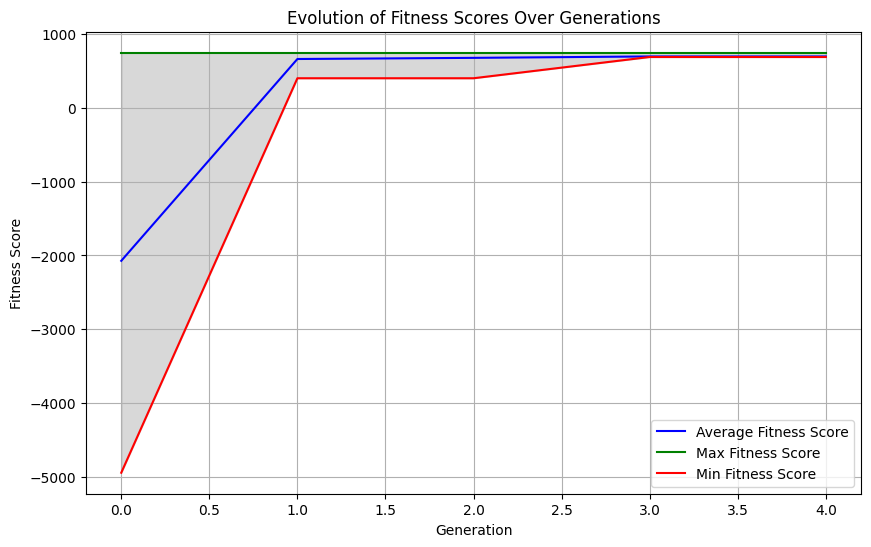
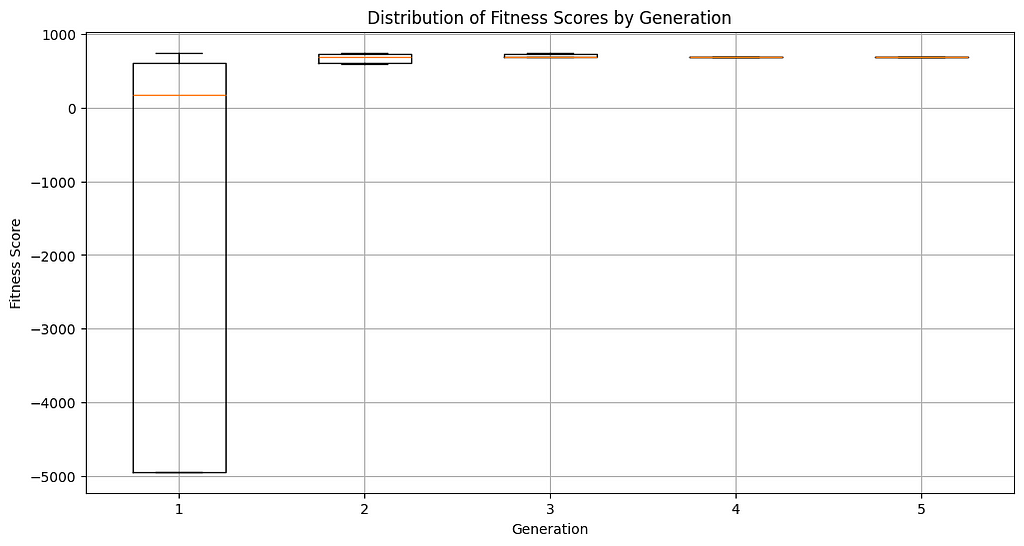
The images below describe the evolution of nanny fitness scores over time. The algorithm was able to quickly converge on the best nanny chromosome after just a few generations.
From Chaos to Clarity: Visualizing the Solution
After the algorithm had done its work and optimized the nanny characteristics we were looking for, the next step was making sense of the results. This is where visualization came into play, and I have to say, it was a game-changer. Before we had charts and graphs, our schedule felt like a tangled web of conflicting commitments, unpredictable shifts, and last-minute changes. But once we turned the data into something visual, everything started to fall into place.
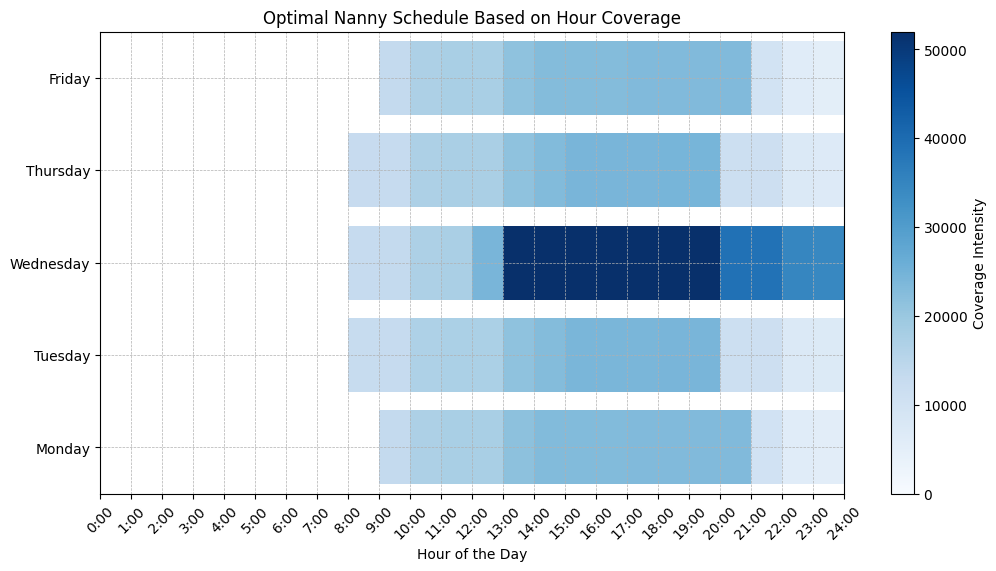
The Heatmap: Coverage at a Glance
The heatmap provided a beautiful splash of color that turned the abstract into something tangible. The darker the color, the more nanny coverage there was, and the lighter the color, the less nanny coverage we needed. This made it easy to spot any potential issues at a glance. Need more coverage on Friday? Check the heatmap. Will the nanny be working too many hours on Wednesday? (Yes, that’s very likely.) The heatmap will let you know. It gave us instant clarity, helping us tweak the schedule where needed and giving us peace of mind when everything lined up perfectly.
By visualizing the results, we didn’t just solve the scheduling puzzle — we made it easy to understand and follow. Instead of scrambling to figure out what kind of nanny we needed, we could just look at the visuals and see what they needed to cover. From chaos to clarity, these visual tools turned data into insight and helped us shop for nannies with ease.
The Impact: A Household in Harmony
Before I applied my data science toolkit to our family’s scheduling problem, it felt a little overwhelming. We started interviewing nannies without really understanding what we were looking for, or needed, to keep our house in order.
But after optimizing the nanny schedule with Monte Carlo simulations and genetic algorithms, the difference was night and day. Where there was once chaos, now there’s understanding. Suddenly, we had a clear plan, a map of who was where and when, and most importantly, a roadmap for the kind of nanny to find.
The biggest change wasn’t just in the schedule itself, though — it was in how we felt. There’s a certain peace of mind that comes with knowing you have a plan that works, one that can flex and adapt when the unexpected happens. And for me personally, this project was more than just another application of data science. It was a chance to take the skills I use every day in my professional life and apply them to something that directly impacts my family.
The Power of Data Science at Home
We tend to think of data science as something reserved for the workplace, something that helps businesses optimize processes or make smarter decisions. But as I learned with our nanny scheduling project, the power of data science doesn’t have to stop at the office door. It’s a toolkit that can solve everyday challenges, streamline chaotic situations, and, yes, even bring a little more calm to family life.

Maybe your “nanny puzzle” isn’t about childcare. Maybe it’s finding the most efficient grocery list, managing home finances, or planning your family’s vacation itinerary. Whatever the case may be, the tools we use at work — Monte Carlo simulations, genetic algorithms, and data-driven optimization — can work wonders at home too. You don’t need a complex problem to start, just a curiosity to see how data can help untangle even the most mundane challenges.
So here’s my challenge to you: Take a look around your life and find one area where data could make a difference. Maybe you’ll stumble upon a way to save time, money, or even just a little peace of mind. It might start with something as simple as a spreadsheet, but who knows where it could lead? Maybe you’ll end up building your own “Nanny Olympics” or solving a scheduling nightmare of your own.
And as we move forward, I think we’ll see data science becoming a more integral part of our personal lives — not just as something we use for work, but as a tool to manage our day-to-day challenges. In the end, it’s all about using the power of data to make our lives a little easier.
The code and data for the Nanny Scheduling problem can be found on Github: https://github.com/agentdanger/nanny-simulation
Professional information about me can be found on my website: https://courtneyperigo.com
Data Science at Home: Solving the Nanny Schedule Puzzle with Monte Carlo and Genetic Algorithms was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Data Science at Home: Solving the Nanny Schedule Puzzle with Monte Carlo and Genetic Algorithms