Can ML models learn to construct optimal customer journeys?
Marketing attribution has traditionally been backward-looking: analyzing past customer journeys to understand which touchpoints contributed to conversion. But what if we could use this historical data to design optimal future journeys? In this post, I’ll show how we can combine deep learning with optimization techniques to design high-converting customer journeys while respecting real-world constraints. We will do so by using an LSTM to predict journeys with high conversion probability and then using beam search to find sequences with good chances of conversion. All images are created by the author.
Introduction
Customers interact with businesses on what we can call a customer journey. On this journey, they come into contact with the company through so-called touchpoints (e.g., Social Media, Google Ads, …). At any point, users could convert (e.g. by buying your product). We want to know what touchpoints along that journey contributed to the conversion to optimize the conversion rate.
The Limitations of Traditional Attribution
Before diving into our solution, it’s important to understand why traditional attribution models fall short.
1. Position-Agnostic Attribution
Traditional attribution models (first-touch, last-touch, linear, etc.) typically assign a single importance score to each channel, regardless of where it appears in the customer journey. This is fundamentally flawed because:
- A social media ad might be highly effective early in the awareness stage but less impactful during consideration
- Email effectiveness often depends on whether it’s a welcome email, nurture sequence, or re-engagement campaign
- Retargeting ads make little sense as a first touchpoint but can be powerful later in the journey
2. Context Blindness
Most attribution models (even data-driven ones) ignore crucial contextual factors:
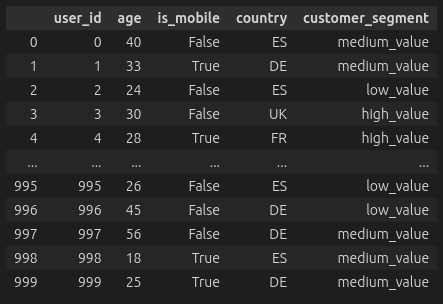
- Customer Characteristics: A young tech-savvy customer might respond differently to digital channels compared to traditional ones
Customer 1 (Young, Urban): Social → Video → Purchase
Customer 2 (Older, Rural): Print → Email → Purchase
- Previous Purchase History: Existing customers often require different engagement strategies than new prospects
- Time of Day/Week: Channel effectiveness can vary significantly based on timing
- Device/Platform: The same channel might perform differently across different platforms
- Geographic/Cultural Factors: What works in one market might fail in another
3. Static Channel Values
Traditional models assume channel effectiveness can be expressed as a single number where all other factors influencing the effectiveness are marginalized. As mentioned above, channel effectiveness is highly context-dependent and should be a function of said context (e.g. position, other touchpoints, …).
Deep Learning Enters the Stage
Customer journeys are inherently sequential — the order and timing of touchpoints matter. We can frame attribution modeling as a binary time series classification task where we want to predict from the sequence of touchpoints whether a customer converted or not. This makes them perfect candidates for sequence modeling using Recurrent Neural Networks (RNNs), specifically Long Short-Term Memory (LSTM) networks. These models can capture complex patterns in sequential data, including:
- The effectiveness of different channel combinations
- The importance of touchpoint ordering
- Timing sensitivities
- Channel interaction effects
Learning from Historical Data
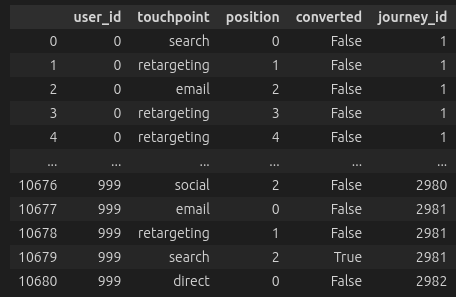
The first step is to train an LSTM model on historical customer journey data. For each customer, we need:
- The sequence of touchpoints they encountered
- Whether they ultimately converted
- Characteristics of the customer
The LSTM learns to predict conversion probability given any sequence of touchpoints. This gives us a powerful “simulator” that can evaluate the likely effectiveness of any proposed customer journey.
As I did not find a suitable dataset (especially one that contains customer characteristics as the contextual data), I decided to generate my own synthetic data. The notebook for the data generation can be found here. We generate some characteristics and a random number of customer journeys for each customer. The journeys are of random length. At each point in the journey, the customer interacts with a touchpoint and has a probability of converting. This probability is composed of multiple factors.
- The base conversion rate of the channel
- A positional multiplier. Some channels are more or less effective in some positions of the journey.
- A segment multiplier. The channel’s effectiveness depends on the segment of the customer.
- We also have interaction effects. E.g. if the user is young, touchpoints such as social and search will be more effective.
- Additionally, the previous touchpoint matters for the effectiveness of the current touchpoint.
We then preprocess the data by merging the two tables, scaling the numerical features, and OneHotEncoding the categorical features. We can then set up an LSTM model that processes the sequences of touchpoints after embedding them. In the final fully connected layer, we also add the contextual features of the customer. The full code for preprocessing and training can be found in this notebook.
We can then train the neural network with a binary cross-entropy loss. I have plotted the recall achieved on the test set below. In this case, we care more about recall than accuracy as we want to detect as many converting customers as possible. Wrongly predicting that some customers will convert if they don’t is not as bad as missing high-potential customers.
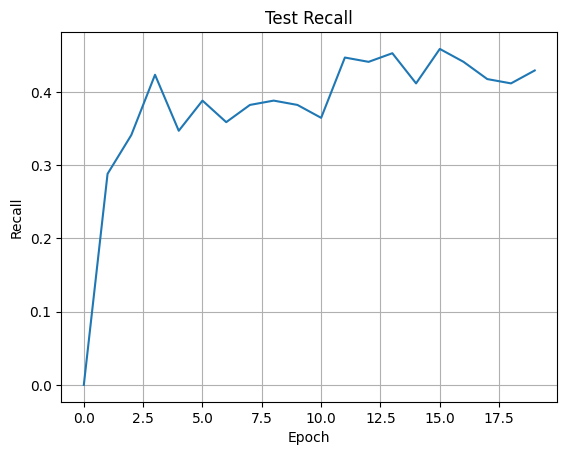
Additionally, we will find that most journeys do not lead to a conversion. We will typically see conversion rates from 2% to 7% which means that we have a highly imbalanced dataset. For the same reason, accuracy isn’t all that meaningful. Always predicting the majority class (in this case ‘no conversion’) will get us a very high accuracy but we won’t find any of the converting users.
From Prediction to Optimization
Once we have a trained model, we can use it to design optimal journeys. We can impose a sequence of channels (in the example below channel 1 then 2) on a set of customers and look at the conversion probability predicted by the model. We can already see that these vary a lot depending on the characteristics of the customer. Therefore, we want to optimize the journey for each customer individually.
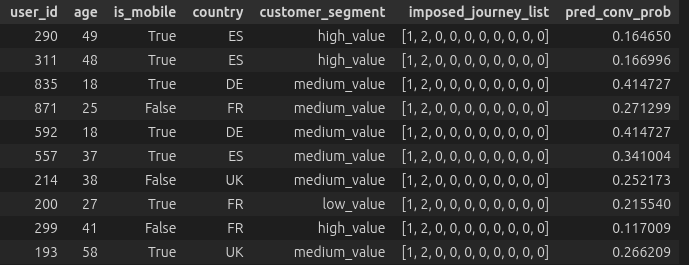
Additionally, we can’t just pick the highest-probability sequence. Real-world marketing has constraints:
- Channel-specific limitations (e.g., email frequency caps)
- Required touchpoints at specific positions
- Budget constraints
- Timing requirements
Therefore, we frame this as a constrained combinatorial optimization problem: find the sequence of touchpoints that maximizes the model’s predicted conversion probability while satisfying all constraints. In this case, we will only constrain the occurrence of touchpoints at certain places in the journey. That is, we have a mapping from position to touchpoint that specifies that a certain touchpoint must occur at a given position.
Note also that we aim to optimize for a predefined journey length rather than journeys of arbitrary length. By the nature of the simulation, the overall conversion probability will be strictly monotonically increasing as we have a non-zero conversion probability at each touchpoint. Therefore, a longer journey (more non-zero entries) would trump a shorter journey most of the time and we would construct infinitely long journeys.
Optimization using Beam Search
Below is the implementation for beam search using recursion. At each level, we optimize a certain position in the journey. If the position is in the constraints and already fixed, we skip it. If we have reached the maximum length we want to optimize, we stop recursing and return.
At each level, we look at current solutions and generate candidates. At any point, we keep the best K candidates defined by the beam width. Those best candidates are then used as input for the next round of beam search where we optimize the next position in the sequence.
def beam_search_step(
model: JourneyLSTM,
X: torch.Tensor,
pos: int,
num_channels: int,
max_length: int,
constraints:dict[int, int],
beam_width: int = 3
):
if pos > max_length:
return X
if pos in constraints:
return beam_search_step(model, X, pos + 1, num_channels, max_length, constraints, beam_width)
candidates = [] # List to store (sequence, score) tuples
for sequence_idx in range(min(beam_width, len(X))):
X_current = X[sequence_idx:sequence_idx+1].clone()
# Try each possible channel
for channel in range(num_channels):
X_candidate = X_current.clone()
X_candidate[0, extra_dim + pos] = channel
# Get prediction score
pred = model(X_candidate)[0].item()
candidates.append((X_candidate, pred))
candidates.sort(key=lambda x: x[1], reverse=True)
best_candidates = candidates[:beam_width]
X_next = torch.cat([cand[0] for cand in best_candidates], dim=0)
# Recurse with best candidates
return beam_search_step(model, X_next, pos + 1, num_channels, max_length, constraints, beam_width)
This optimization approach is greedy and we are likely to miss high-probability combinations. Nonetheless, in many scenarios, especially with many channels, brute forcing an optimal solution may not be feasible as the number of possible journeys grows exponentially with the journey length.
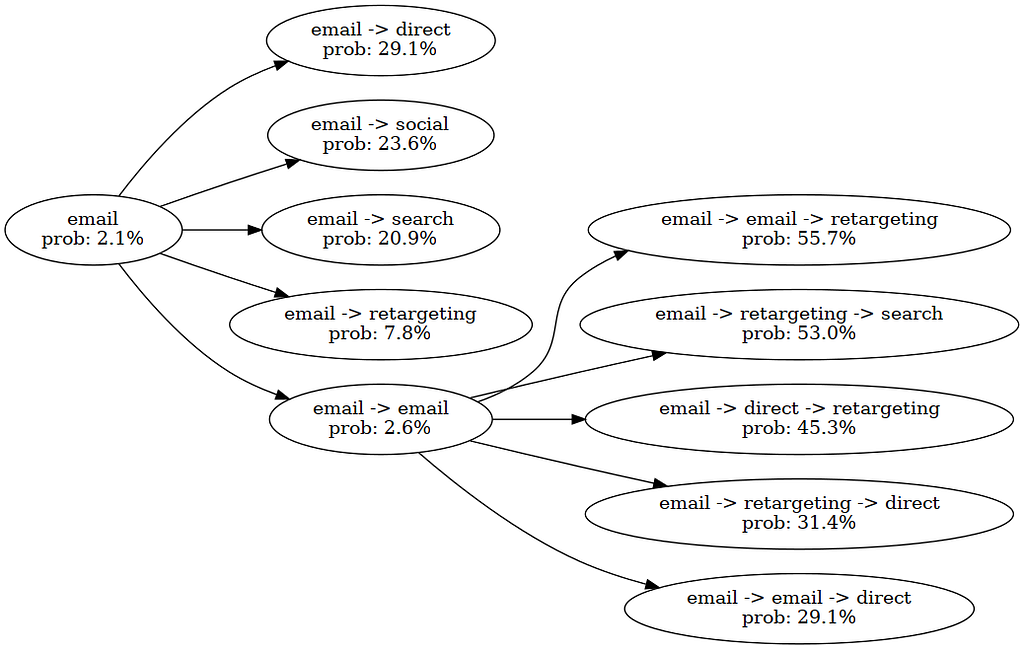
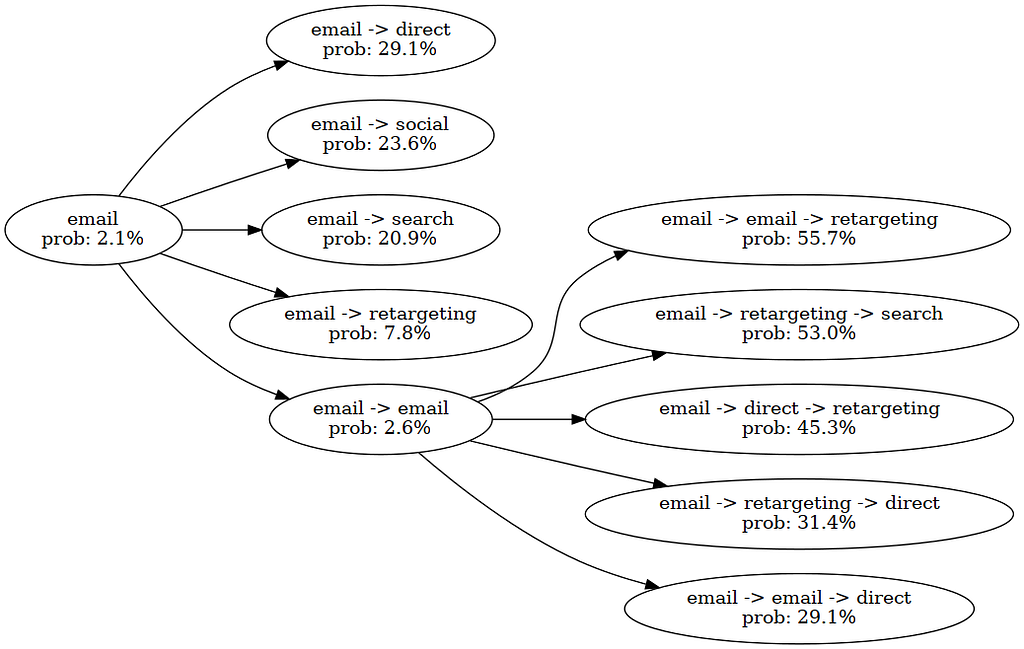
In the image above, we optimized the conversion probability for a single customer. In position 0, we have specified ‘email’ as a fixed touchpoint. Then, we explore possible combinations with email. Since we have a beam width of five, all combinations (e.g. email -> search) go into the next round. In that round, we discovered the high-potential journey which would display the user two times email and finally retarget.
Conclusion
Moving from prediction to optimization in attribution modeling means we are going from predictive to prescriptive modeling where the model tells us actions to take. This has the potential to achieve much higher conversion rates, especially when we have highly complex scenarios with many channels and contextual variables.
At the same time, this approach has several drawbacks. Firstly, if we do not have a model that can detect converting customers sufficiently well, we are likely to harm conversion rates. Additionally, the probabilities that the model outputs have to be calibrated well. Otherwiese, the conversion probabilities we are optimizing for are likely not meanningful. Lastly, we will encounter problems when the model has to predict journeys that are outside of its data distribution. It would therefore also be desirable to use a Reinforcement Learning (RL) approach, where the model can actively generate new training data.
Data-Driven Journey Optimization: Using Deep Learning to Design Customer Journeys was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Data-Driven Journey Optimization: Using Deep Learning to Design Customer Journeys