

Ensuring fair and equitable healthcare outcomes from medical AI applications
AI bias refers to discrimination when AI systems produce unequal outcomes for different groups due to bias in the training data. When not mitigated, biases in AI and machine learning models can systematize and exacerbate discrimination faced by historically marginalized groups by embedding discrimination within decision-making algorithms.
Issues in training data, such as unrepresentative or imbalanced datasets, historical prejudices embedded in the data, and flawed data collection methods, lead to biased models. For example, if a loan decisioning application is trained on historical decisions, but Black loan applicants were systematically discriminated against in these historical decisions, then the model will embed this discriminatory pattern within its decisioning. Biases can also be introduced during the feature selection and engineering phases, where certain attributes may inadvertently act as proxies for sensitive characteristics such as race, gender, or socioeconomic status. For example, race and zip code are strongly associated in America, so an algorithm trained using zip code data will indirectly embed information about race in its decision-making process.
AI in medical contexts involves using machine learning models and algorithms to aid diagnosis, treatment planning, and patient care. AI bias can be especially harmful in these situations, driving significant disparities in healthcare delivery and outcomes. For example, a predictive model for skin cancer that has been trained predominantly on images of lighter skin tones may perform poorly on patients with darker skin. Such a system might cause misdiagnoses or delayed treatment for patients with darker skin, resulting in higher mortality rates. Given the high stakes in healthcare applications, data scientists must take action to mitigate AI bias in their applications. This article will focus on what data curation techniques data scientists can take to remove bias in training sets before models are trained.
How is AI Bias Measured?
To mitigate AI bias, it is important to understand how model bias and fairness are defined (PDF) and measured. A fair/unbiased model ensures its predictions are equitable across different groups. This means that the model’s behavior, such as accuracy and selection probability, is comparable across subpopulations defined by sensitive features (e.g., race, gender, socioeconomic status).
Using quantitative metrics for AI fairness/bias, we can measure and improve our own models. These metrics compare accuracy rates and selection probability between historically privileged groups and historically non-privileged groups. Three commonly used metrics to measure how fairly an AI model treats different groups are:
Statistical Parity Difference—Compares the ratio of favorable outcomes between groups. This test shows that a model’s predictions are independent of sensitive group membership, aiming for equal selection rates across groups. It is useful in cases where an equal positive rate between groups is desired, such as hiring.
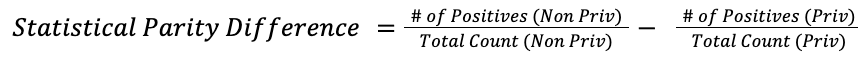
Average Odds Difference — Compares the disparity between false and true positive rates across different groups. This metric is stricter than Statistical Parity Difference because it seeks to ensure that false and true positive rates are equal between groups. It is useful in cases where both positive and negative errors are consequential, such as criminal justice.

Equal Opportunity Difference — Compares the true positive rates between different groups. It checks that qualified individuals from different groups have an equal chance of being selected by an AI system. It does not account for false positive rates, potentially leading to disparities in incorrect positive predictions across groups.

Data scientists can calculate these fairness/bias metrics on their models using a Python library such as Microsoft’s Fairlearn package or IBM’s AI Fairness 360 Toolkit. For all these metrics, a value of zero represents a mathematically fair outcome.
What Data Curation Practices Can Minimize AI Bias?
To mitigate bias in AI training datasets, model builders have an arsenal of data curation techniques, which can be divided into quantitative (data transformation using mathematical packages) and qualitative (best practices for data collection).
Quantitative Practices
Remove correlations with sensitive features

Even if sensitive features (e.g., race, gender) are excluded from model training, other features may still be correlated with these sensitive features and introduce bias. For example, zip code strongly correlates with race in the United States. To ensure these features do not introduce hidden bias, data scientists should preprocess their inputs to remove the correlation between other input features and sensitive features.
This can be done with Fairlearn’s CorrelationRemover function. It mathematically transforms feature values to remove correlation while preserving most of the features’ predictive value. See below for a sample code.
from fairlearn.preprocessing import CorrelationRemover
import pandas as pd
data = pd.read_csv('health_data.csv')
X = data[["patient_id", "num_chest_nodules", "insurance", "hospital_code"]]
X = pd.get_dummies(X)
cr = CorrelationRemover(sensitive_feature_ids=['insurance_None'])
cr.fit(X)
X_corr_removed = cr.transform(X)
Use re-weighting and re-sampling to create a balanced sample
Reweighting and resampling are similar processes that create a more balanced training dataset to correct for when specific groups are under or overrepresented in the input set. Reweighting involves assigning different weights to data samples to ensure that underrepresented groups have a proportionate impact on the model’s learning process. Resampling involves either oversampling minority class instances or undersampling majority class instances to achieve a balanced dataset.
If a sensitive group is underrepresented compared to the general population, data scientists can use AI Fairness’s Reweighing function to transform the data input. See below for sample code.
from aif360.algorithms.preprocessing import Reweighing
import pandas as pd
data = pd.read_csv('health_data.csv')
X = data[["patient_id", "num_chest_nodules", "insurance_provider", "hospital_code"]]
X = pd.get_dummies(X)
rw = Reweighing(unprivileged_groups=['insurance_None'],
privileged_groups=['insurance_Aetna', 'insurance_BlueCross'])
rw.fit(X)
X_reweighted = rw.transform(X)
Transform feature values using a disparate impact remover
Another technique to remove bias embedded in training data is transforming input features with a disparate impact remover. This technique adjusts feature values to increase fairness between groups defined by a sensitive feature while preserving the rank order of data within groups. This preserves the model’s predictive capacity while mitigating bias.
To transform features to remove disparate impact, you can use AI Fairness’s Disparate Impact Remover. Note that this tool only transforms input data fairness with respect to a single protected attribute, so it cannot improve fairness across multiple sensitive features or at the intersection of sensitive features. See below for sample code.
from aif360.algorithms.preprocessing import disparate_impact_remover
import pandas as pd
data = pd.read_csv('health_data.csv')
X = data[["patient_id", "num_chest_nodules", "insurance_provider", "hospital_code"]]
dr = DisparateImpactRemover(repair_level=1.0, sensitive_attribute='insurance_provider')
X_impact_removed = dr.fit_transform(X)
Leverage diverse expert data annotation to minimize labeling bias
For supervised learning use cases, human data labeling of the response variable is often necessary. In these cases, imperfect human data labelers introduce their personal biases into the dataset, which are then learned by the machine. This is exacerbated when small, non-diverse groups of labelers do data annotation.
To minimize bias in the data annotation process, use a high-quality data annotation solution that leverages diverse expert opinions, such as Centaur Labs. By algorithmically synthesizing multiple opinions using meritocratic measures of label confidence, such solutions mitigate the effect of individual bias and drive huge gains in labeling accuracy for your dataset.
Qualitative Practices
Implement inclusive and representative data collection practices
Medical AI training data must have sufficient sample sizes across all patient demographic groups and conditions to accurately make predictions for diverse groups of patients. To ensure datasets meet these needs, application builders should engage with relevant medical experts and stakeholders representing the affected patient population to define data requirements. Data scientists can use stratified sampling to ensure that their training set does not over or underrepresent groups of interest.
Data scientists must also ensure that collection techniques do not bias data. For example, if medical imaging equipment is inconsistent across different samples, this would introduce systematic differences in the data.
Ensure data cleaning practices do not introduce bias
To avoid creating bias during data cleaning, data scientists must handle missing data and impute values carefully. When a dataset has missing values for a sensitive feature like patient age, simple strategies such as imputing the mean age could skew the data, especially if certain age groups are underrepresented. Instead, techniques such as stratified imputation, where missing values are filled based on the distribution within relevant subgroups (e.g., imputing within age brackets or demographic categories). Advanced methods like multiple imputation, which generates several plausible values and averages them to account for uncertainty, may also be appropriate depending on the situation. After performing data cleaning, data scientists should document the imputation process and ensure that the cleaned dataset remains representative and unbiased according to predefined standards.
Publish curation practices for stakeholder input
As data scientists develop their data curation procedure, they should publish them for stakeholder input to promote transparency and accountability. When stakeholders (e.g., patient group representatives, researchers, and ethicists) review and provide feedback on data curation methods, it helps identify and address potential sources of bias early in the development process. Furthermore, stakeholder engagement fosters trust and confidence in AI systems by demonstrating a commitment to ethical and inclusive practices. This trust is essential for driving post-deployment use of AI systems.
Regularly audit and review input data and model performance
Regularly auditing and reviewing input data for live models ensures that bias does not develop in training sets over time. As medicine, patient demographics, and data sources evolve, previously unbiased models can become biased if the input data no longer represents the current population accurately. Continuous monitoring helps identify and correct any emerging biases, ensuring the model remains fair and effective.
Summary

Data scientists must take measures to minimize bias in their medical AI models to achieve equitable patient outcomes, drive stakeholder buy-in, and gain regulatory approval. Data scientists can leverage emerging tools from libraries such as Fairlearn (Microsoft) or AI Fairness 360 Toolkit (IBM) to measure and improve fairness in their AI models. While these tools and quantitative measures like Statistical Parity Difference are useful, developers must remember to take a holistic approach to fairness. This requires collaboration with experts and stakeholders from affected groups to understand patient populations and the impact of AI applications. If data scientists adhere to this practice, they will usher in a new era of just and superior healthcare for all.
Data Curation Practices to Minimize Bias in Medical AI was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Data Curation Practices to Minimize Bias in Medical AI
Go Here to Read this Fast! Data Curation Practices to Minimize Bias in Medical AI