
Machine learning (ML) practitioners looking to reuse existing datasets to train an ML model often spend a lot of time understanding the data, making sense of its organization, or figuring out what subset to use as features. So much time, in fact, that progress in the field of ML is hampered by a fundamental obstacle: the wide variety of data representations.
ML datasets cover a broad range of content types, from text and structured data to images, audio, and video. Even within datasets that cover the same types of content, every dataset has a unique ad hoc arrangement of files and data formats. This challenge reduces productivity throughout the entire ML development process, from finding the data to training the model. It also impedes development of badly needed tooling for working with datasets.
There are general purpose metadata formats for datasets such as schema.org and DCAT. However, these formats were designed for data discovery rather than for the specific needs of ML data, such as the ability to extract and combine data from structured and unstructured sources, to include metadata that would enable responsible use of the data, or to describe ML usage characteristics such as defining training, test and validation sets.
Today, we’re introducing Croissant, a new metadata format for ML-ready datasets. Croissant was developed collaboratively by a community from industry and academia, as part of the MLCommons effort. The Croissant format doesn’t change how the actual data is represented (e.g., image or text file formats) — it provides a standard way to describe and organize it. Croissant builds upon schema.org, the de facto standard for publishing structured data on the Web, which is already used by over 40M datasets. Croissant augments it with comprehensive layers for ML relevant metadata, data resources, data organization, and default ML semantics.
In addition, we are announcing support from major tools and repositories: Today, three widely used collections of ML datasets — Kaggle, Hugging Face, and OpenML — will begin supporting the Croissant format for the datasets they host; the Dataset Search tool lets users search for Croissant datasets across the Web; and popular ML frameworks, including TensorFlow, PyTorch, and JAX, can load Croissant datasets easily using the TensorFlow Datasets (TFDS) package.
Croissant
This 1.0 release of Croissant includes a complete specification of the format, a set of example datasets, an open source Python library to validate, consume and generate Croissant metadata, and an open source visual editor to load, inspect and create Croissant dataset descriptions in an intuitive way.
Supporting Responsible AI (RAI) was a key goal of the Croissant effort from the start. We are also releasing the first version of the Croissant RAI vocabulary extension, which augments Croissant with key properties needed to describe important RAI use cases such as data life cycle management, data labeling, participatory data, ML safety and fairness evaluation, explainability, and compliance.
Why a shared format for ML data?
The majority of ML work is actually data work. The training data is the “code” that determines the behavior of a model. Datasets can vary from a collection of text used to train a large language model (LLM) to a collection of driving scenarios (annotated videos) used to train a car’s collision avoidance system. However, the steps to develop an ML model typically follow the same iterative data-centric process: (1) find or collect data, (2) clean and refine the data, (3) train the model on the data, (4) test the model on more data, (5) discover the model does not work, (6) analyze the data to find out why, (7) repeat until a workable model is achieved. Many steps are made harder by the lack of a common format. This “data development burden” is especially heavy for resource-limited research and early-stage entrepreneurial efforts.
The goal of a format like Croissant is to make this entire process easier. For instance, the metadata can be leveraged by search engines and dataset repositories to make it easier to find the right dataset. The data resources and organization information make it easier to develop tools for cleaning, refining, and analyzing data. This information and the default ML semantics make it possible for ML frameworks to use the data to train and test models with a minimum of code. Together, these improvements substantially reduce the data development burden.
Additionally, dataset authors care about the discoverability and ease of use of their datasets. Adopting Croissant improves the value of their datasets, while only requiring a minimal effort, thanks to the available creation tools and support from ML data platforms.
What can Croissant do today?
 |
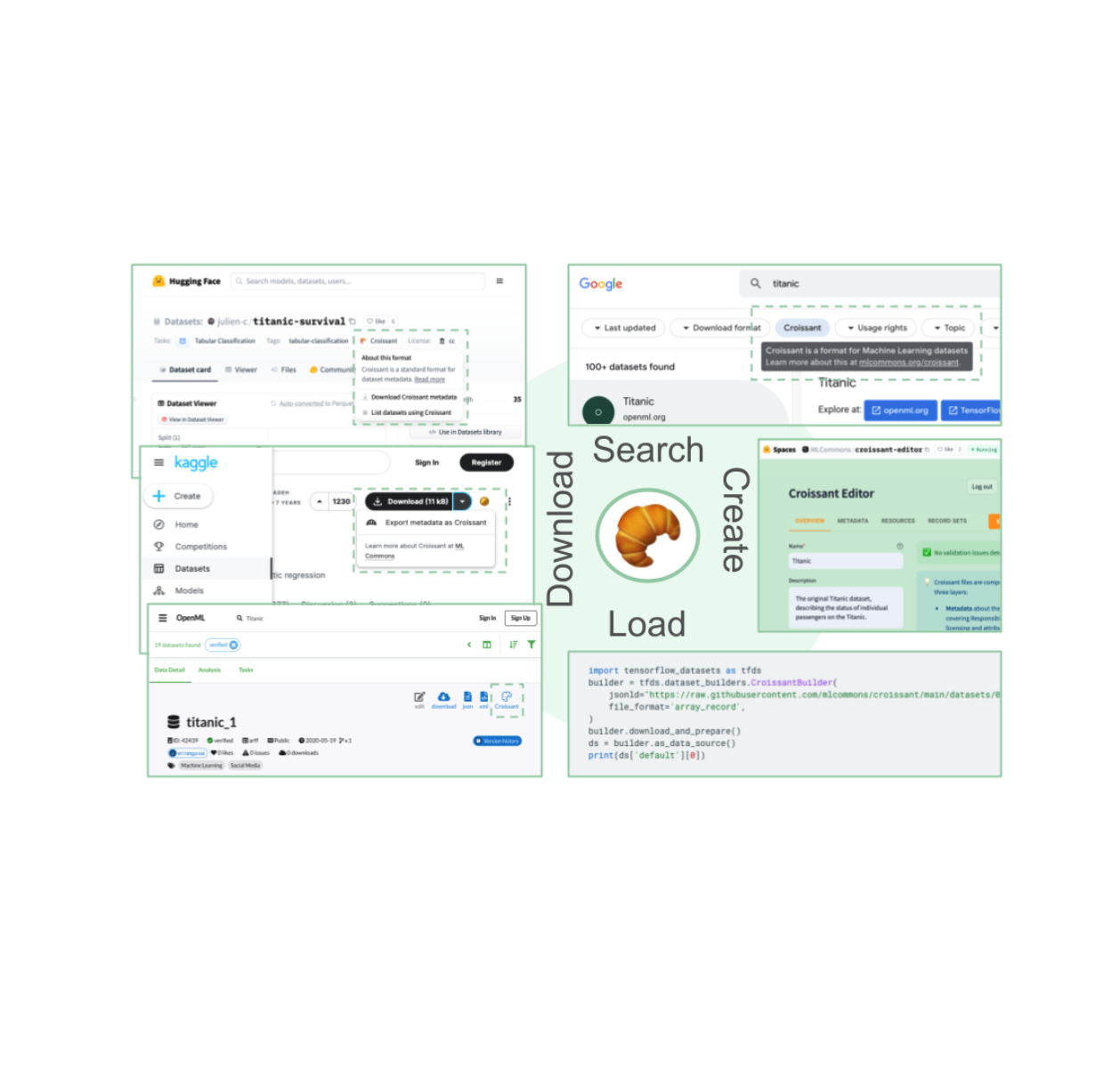
| The Croissant ecosystem: Users can Search for Croissant datasets, download them from major repositories, and easily load them into their favorite ML frameworks. They can create, inspect and modify Croissant metadata using the Croissant editor. |
Today, users can find Croissant datasets at:
- Google Dataset Search, which offers a Croissant filter.
- HuggingFace
- Kaggle
- OpenML
With a Croissant dataset, it is possible to:
- Ingest data easily via TensorFlow Datasets for use in popular ML frameworks like TensorFlow, PyTorch, and JAX.
- Inspect and modify the metadata using the Croissant editor UI (github).
To publish a Croissant dataset, users can:
- Use the Croissant editor UI (github) to generate a large portion of Croissant metadata automatically by analyzing the data the user provides, and to fill important metadata fields such as RAI properties.
- Publish the Croissant information as part of their dataset Web page to make it discoverable and reusable.
- Publish their data in one of the repositories that support Croissant, such as Kaggle, HuggingFace and OpenML, and automatically generate Croissant metadata.
Future direction
We are excited about Croissant’s potential to help ML practitioners, but making this format truly useful requires the support of the community. We encourage dataset creators to consider providing Croissant metadata. We encourage platforms hosting datasets to provide Croissant files for download and embed Croissant metadata in dataset Web pages so that they can be made discoverable by dataset search engines. Tools that help users work with ML datasets, such as labeling or data analysis tools should also consider supporting Croissant datasets. Together, we can reduce the data development burden and enable a richer ecosystem of ML research and development.
We encourage the community to join us in contributing to the effort.
Acknowledgements
Croissant was developed by the Dataset Search, Kaggle and TensorFlow Datasets teams from Google, as part of an MLCommons community working group, which also includes contributors from these organizations: Bayer, cTuning Foundation, DANS-KNAW, Dotphoton, Harvard, Hugging Face, Kings College London, LIST, Meta, NASA, North Carolina State University, Open Data Institute, Open University of Catalonia, Sage Bionetworks, and TU Eindhoven.
Originally appeared here:
Croissant: a metadata format for ML-ready datasets
Go Here to Read this Fast! Croissant: a metadata format for ML-ready datasets