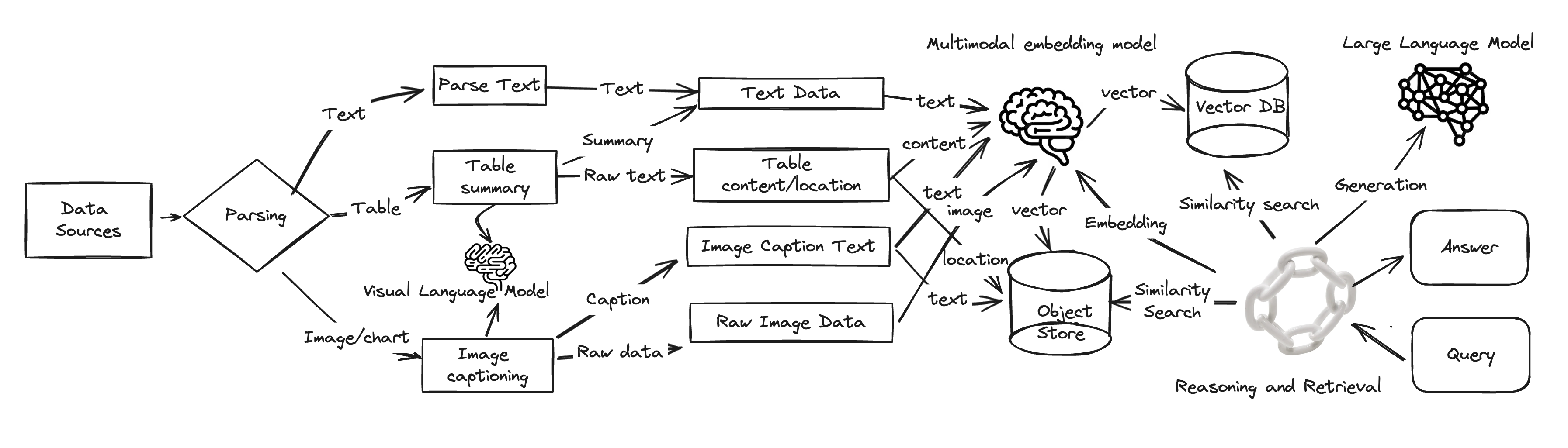

In this post, we present a new approach named multimodal RAG (mmRAG) to tackle those existing limitations in greater detail. The solution intends to address these limitations for practical generative artificial intelligence (AI) assistant use cases. Additionally, we examine potential solutions to enhance the capabilities of large language models (LLMs) and visual language models (VLMs) with advanced LangChain capabilities, enabling them to generate more comprehensive, coherent, and accurate outputs while effectively handling multimodal data
Originally appeared here:
Create a multimodal assistant with advanced RAG and Amazon Bedrock
Go Here to Read this Fast! Create a multimodal assistant with advanced RAG and Amazon Bedrock