An interpretable outlier detector based on multi-dimensional histograms.
This article continues a series on interpretable outlier detection. The previous article (Interpretable Outlier Detection: Frequent Patterns Outlier Factor (FPOF) ) covered the FPOF algorithm, as well as some of the basics of outlier detection and interpretability. This builds on that, and presents Counts Outlier Detector, another interpretable outlier detection method.
As covered in the FPOF article, knowing why records are outliers can be as important as knowing which records are outliers. In fact, there can often be limited value in performing outlier detection where we cannot determine why the records flagged as outliers were flagged. For example, if an outlier detection system identifies what may be a security threat, to investigate this efficiently and effectively it’s necessary to know what is unusual: why this was identified as anomalous. Similarly where the outlier detection system identifies possible fraud, machine failures, scientific discoveries, unusually effective (or ineffective) business practices, or other outliers.
Although the algorithms themselves employed by detectors are usually quite understandable, the individual predictions are generally not. For example, standard detectors such as Isolation Forest (IF), Local Outlier Factor (LOF), and kth Nearest Neighbors (kNN), have algorithms that are straightforward to understand, but produce scores that may be difficult to assess, particularly with high-dimensional data. It can be difficult to determine why records flagged as outliers are anomalous.
In principle, it’s quite manageable to explain outliers. With most outliers, there are only a small set of features that have anomalous values (very few outliers have anomalous values in every feature). Knowing which features are unusual, and how these features are unusual, is generally all that’s required to understand why outliers are outliers, but this is, unfortunately, usually unavailable.
Only a small number of outlier detectors provide an explanation for the scores they produce. These include FPOF and a related outlier detection method based on Association Rules (both covered in Outlier Detection in Python), to give two examples. But, there are far fewer interpretable models than would be wished. Motivated by this, I’ve developed two interpretable models, Counts Outlier Detector (COD), and Data Consistency Checker, which I’m still maintaining today.
They work quite a bit differently from each other but are both useful tools. The former is covered in this article; Data Consistency Checker will be covered in an upcoming article. As well, both are covered in Outlier Detection in Python; the remainder of this article is taken from the section on Counts Outlier Detector.
Counts Outlier Detector
The main page for Counts Outlier Detector is https://github.com/Brett-Kennedy/CountsOutlierDetector.
Counts Outlier Detector (COD) is an outlier detector for tabular data, designed to provide clear explanations of the rows flagged as outliers and of their specific scores. More specifically, COD is a multivariate histogram-based model: it divides the data into sets of bins and identifies outliers as the records in bins with unusually low counts.
This is an effective, efficient, and interpretable technique for outlier detection. There are some very real limitations of multi-dimensional histograms, which we cover here, but, as we’ll also cover, these are quite addressable. Testing and evaluating the method has found it to be a strong detector, very often as useful as more standard tools, with the substantial benefit of being interpretable.
Introduction to histogram-based outlier detection
Before explaining COD, I’ll explain another, simpler histogram-based algorithm for outlier detection that pre-dates COD, called HBOS (Histogram-Based Outlier Score). This is part of the popular PyOD (Python Outlier Detection) library and is often an effective tool itself. Other histogram-based outlier detection algorithms exist as well, and work similarly.
HBOS works based on a very straightforward idea: to determine how unusual a row in a table is, it simply assesses how unusual each individual value in the row is. To do this, the values are each compared to their columns. This is done by first creating a histogram to represent each feature (HBOS works strictly with numeric data) and comparing each value to the histogram.
There are other means to determine how unusual a numeric value is relative to a table column (or other sequence of numeric values). Kernel density estimates, cumulative distributions, and other methods can also work well. But histograms are one straightforward and effective means. The other methods are covered in Outlier Detection in Python, but for simplicity, and since this is what COD uses, we’ll look just at histograms in this article.
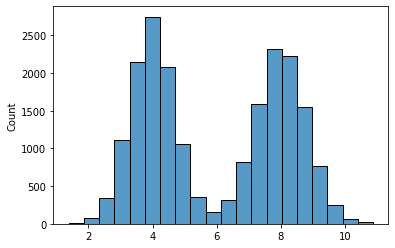
HBOS divides each feature into a set of equal-width bins. Each feature may then be represented by a histogram such as:
In this case, the histogram uses 20 bins; with HBOS, we would normally use between about 5 and 50 bins per feature. If the table has, say, 30 features, there will be 30 histograms such as this.
Any values that are in bins with a very low count would be considered unusual. In this histogram, a value around 6.0, for example, would be considered rare, as it’s bin has few examples from the training data; it would be given a relatively high outlier score. A value of 4.0, on the other hand, would be considered very normal, so given a low outlier score.
So, to evaluate a row, HBOS determines how unusual each individual value in the row is (relative to the histogram for its feature), gives each value a score, and sums these scores together. In this way, the rows with the most rare values, and with the rarest rare values, will receive the highest overall outlier scores; a row may receive a high overall outlier score if it has a single value that’s extremely rare for its column, or if it has a number of values that are moderately rare for their columns.
This does mean that HBOS is only able to find one specific type of outlier: rows that contain one or more unusual single values; it cannot identify rows that contain unusual combinations of values. This is a very major limitation, but HBOS is able to work extremely fast, and the outliers it identifies tend to truly be strong outliers, even if it also misses many outliers.
Still, it’s a major limitation that HBOS will miss unusual combinations of values. For example, in a table describing people, a record may have an age of 130, or a height of 7’2″, and HBOS would detect these. But, a record may also have an age of 2 and a height of 5’10”. The age and the height may both be common, but the combination not: it’s an example of a rare combination of two features.
It’s also possible to have rare combinations of three, four, or more features, and these may be as relevant as unusual single values.
Overview of the Counts Outliers Detector
COD extends the idea of histogram-based outlier detection and supports multi-dimensional histograms. This allows COD to identify outliers that are rare combinations of 2, 3, or more values, as well as the rare single values that can be detected by standard (1d) histogram-based methods such as HBOS. It can catch unusual single values such as heights of 7’2″, and can also catch where a person has an age of 2 and a height of 5’10”.
We look at 2d histograms first, but COD can support histograms up to 6 dimensions (we describe below why it does not go beyond this, and in fact, using only 2 or 3 or 4 dimensions will often work best).
A 2d histogram can be viewed similarly as a heatmap. In the image below we see a histogram in 2d space where the data in each dimension is divided into 13 bins, creating 169 (13 x 13) bins in the 2d space. We can also see one point (circled) that is an outlier in the 2d space. This point is in a bin with very few items (in this case, only one item) and so can be identified as an outlier when examining this 2d space.

This point is not an outlier in either 1d space; it is not unusual in the x dimension or the y dimension, so would be missed by HBOS and other tools that examine only single dimensions at a time.
As with HBOS, COD creates a 1d histogram for each single feature. But then, COD also creates a 2d histogram like this for each pair of features, so is able to detect any unusual pairs of values. The same idea can then be applied to any number of dimensions. It is more difficult to draw, but COD creates 3d histograms for each triple of features (each bin is a cube), and so on. Again, it calculates the counts (using the training data) in each bin and is able to identify outliers: values (or combinations of values) that appear in bins with unusually low counts.
The Curse of Dimensionality
Although it’s effective to create histograms based on each set of 2, 3, and often more features, it is usually infeasible to create a histogram using all features, at least if there are more than about 6 or 7 features in the data. Due to what’s called the curse of dimensionality, we may have far more bins than data records.
For example, if there are 50 features, even using only 2 bins per feature, we would have 2 to the power of 50 bins in a 50d histogram, which is certainly many orders of magnitude greater than the number data records. Even with only 20 features (and using 2 bins per feature), we would have 2 to the power of 20, over one million, bins. Consequently, we can end up with most bins having no records, and those bins that do have any, containing only one or two items.
Most data is relatively skewed and there are usually associations between the features, so the affect won’t be as strong as if the data were spread uniformly through the space, but there will still likely be far too many features to consider at once using a histogram-based method for outlier detection.
Fortunately though, this is actually not a problem. It’s not necessary to create high-dimensional histograms; low-dimensional histograms are quite sufficient to detect the most relevant (and most interpretable) outliers. Examining each 1d, 2d and 3d space, for example, is sufficient to identify each unusual single value, pair of values, and triple of values. These are the most comprehensible outliers and, arguably, the most relevant (or at least typically among the most relevant). Where desired (and where there is sufficient data), examining 4d, 5d or 6d spaces is also possible with COD.
The COD Algorithm
The approach taken by COD is to first examine the 1d spaces, then the 2d spaces, then 3d, and so on, up to at most 6d. If a table has 50 features, this will examine (50 choose 1) 1d spaces (finding the unusual single values), then (50 choose 2) 2d spaces (finding the unusual pairs of values), then (50 choose 3) 3d spaces (finding the unusual triples of values), and so on. This covers a large number of spaces, but it means each record is inspected thoroughly and that anomalies (at least in lower dimensions) are not missed.
Using histograms also allows for relatively fast calculations, so this is generally quite tractable. It can break down with very large numbers of features, but in this situation virtually all outlier detectors will eventually break down. Where a table has many features (for example, in the dozens or hundreds), it may be necessary to limit COD to 1d spaces, finding only unusual single values — which may be sufficient in any case for this situation. But for most tables, COD is able to examine even up to 4 or 5 or 6d spaces quite well.
Using histograms also eliminates the distance metrics used by many outlier detector methods, including some of the most well-used. While very effective in lower dimensions methods, such as LOF, kNN, and several others use all features at once and can be highly susceptible to the curse of dimensionality in higher dimensions. For example, kNN identifies outliers as points that are relatively far from their k nearest neighbors. This is a sensible and generally affective approach, but with very high dimensionality, the distance calculations between points can become highly unreliable, making it impossible to identify outliers using kNN or similar algorithms.
By examining only small dimensionalities at a time, COD is able to handle far more features than many other outlier detection methods.
Limiting evaluation to small dimensionalities
To see why it’s sufficient to examine only up to about 3 to 6 dimensions, we look at the example of 4d outliers. By 4d outliers, I’m referring to outliers that are rare combinations of some four features, but are not rare combinations of any 1, 2, or 3 features. That is, each single feature, each pair of features, and each triple of features is fairly common, but the combination of all four features is rare.
This is possible, and does occur, but is actually fairly uncommon. For most records that have a rare combination of 4 features, at least some subset of two or three of those features will usually also be rare.
One of the interesting things I discovered while working on this and other tools is that most outliers can be described based on a relatively small set of features. For example, consider a table (with four features) representing house prices, we may have features for: square feet, number of rooms, number of floors, and price. Any single unusual value would likely be interesting. Similarly for any pair of features (e.g. low square footage with a large number of floors; or low square feet with high price), and likely any triple of features. But there’s a limit to how unusual a combination of all four features can be without there being any unusual single value, unusual pair, or unusual triple of features.
By checking only lower dimensions we cover most of the outliers. The more dimensions covered, the more outliers we find, but there are diminishing returns, both in the numbers of outliers, and in their relevance.
Even where some legitimate outliers may exist that can only be described using, say, six or seven features, they are most likely difficult to interpret, and likely of lower importance than outliers that have a single rare value, or single pair, or triple of rare values. They also become difficult to quantify statistically, given the numbers of combinations of values can be extremely large when working with beyond a small number of features.
By working with small numbers of features, COD provides a nice middle ground between detectors that consider each feature independently (such as HBOS, z-score, inter-quartile range, entropy-based tests and so on) and outlier detectors that consider all features at once (such as Local Outlier Factor and KNN).
How COD removes redundancy in explanations
Counts Outlier Detector works by first examining each column individually and identifying all values that are unusual with respect to their columns (the 1d outliers).
It then examines each pair of columns, identifying the rows with pairs of unusual values within each pair of columns (the 2d outliers). The detector then considers sets of 3 columns (identifying 3d outliers), sets of 4 columns (identifying 4d outliers), and so on.
At each stage, the algorithm looks for instances that are unusual, excluding values or combinations already flagged in lower-dimensional spaces. For example, in the table of people described above, a height of 7’2″ would be rare. Given that, any combination of age and height (or height and anything else), where the height is 7’2″, will be rare, simply because 7’2″ is rare. As such, there is no need to identify, for example, a height of 7’2″ and age of 25 as a rare combination; it is rare only because 7’2″ is rare and reporting this as a 2d outlier would be redundant. Reporting it strictly as a 1d outlier (based only on the height) provides the clearest, simplest explanation for any rows containing this height.
So, once we identify 7’2″ as a 1d outlier, we do not include this value in checks for 2d outliers, 3d outliers, and so on. The majority of values (the more typical heights relative to the current dataset) are, however, kept, which allows us to further examine the data and identify unusual combinations.
Similarly, any rare pairs of values in 2d spaces are excluded from consideration in 3d and higher-dimensional spaces; any rare triples of values in 3d space will be excluded from 4d and higher-dimensional spaces; and so on.
So, each anomaly is reported using as few features as possible, which keeps the explanations of each anomaly as simple as possible.
Any row, though, may be flagged numerous times. For example, a row may have an unusual value in Column F; an unusual pair of values in columns A and E; another unusual pair of values in D and F; as well as an unusual triple of values in columns B, C, D. The row’s total outlier score would be the sum of the scores derived from these.
Interpretability
We can identify, for each outlier in the dataset, the specific set of features where it is anomalous. This, then, allows for quite clear explanations. And, given that a high fraction of outliers are outliers in 1d or 2d spaces, most explanations can be presented visually (examples are shown below).
Scoring
Counts Outlier Detector takes its name from the fact it examines the exact count of each bin. In each space, the bins with unusually low counts (if any) are identified, and any records with values in these bins are identified as having an anomaly in this sense.
The scoring system then used is quite simple, which further supports interpretability. Each rare value or combination is scored equivalently, regardless of the dimensionality or the counts within the bins. Each row is simply scored based on the number of anomalies found.
This can loose some fidelity (rare combinations are scored the same as very rare combinations), but allows for significantly faster execution times and more interpretable results. This also avoids any complication, and any arbitrariness, weighting outliers in different spaces. For example, it may not be clear how to compare outliers in a 4d space vs in a 2d space. COD eliminates this, treating each equally. So, this does trade-off some detail in the scores for interpretability, but the emphasis of the tool is interpretability, and the effect on accuracy is small (as well as being positive as often as negative — treating anomalies equivalently provides a regularizing effect).
By default, only values or combinations that are strongly anomalous will be flagged. This process can be tuned by setting a threshold parameter.
Example
Here, we provide a simple example using COD, working with the iris dataset, a toy dataset provided by scikit-learn. To execute this, the CountsOutlierDetector class must first be imported. Here, we then simply create an instance of CountsOutlierDetector and call fit_predict().
import pandas as pd
from sklearn.datasets import load_iris
from counts_outlier_detector import CountsOutlierDetector
iris = load_iris()
X, y = iris.data, iris.target
det = CountsOutlierDetector()
results = det.fit_predict(X)
The results include a score for each row in the passed dataset, as well as information about why the rows where flagged, and summary statistics about the dataset’s outliers as a whole.
A number of sample notebooks are provided on the github page to help get you started, as well as help tuning the hyperparameters (as with almost all outlier detectors, the hyperparameters can affect what is flagged). But, generally using COD can be as simple as this example.
The notebooks provided on github also investigate its performance in more depth and cover some experiments to determine how many features typically need to be examined at once to find the relevant outliers in a dataset. As indicated, often limiting analysis to 2 or 3 dimensional histograms can be sufficient to identify the most relevant outliers in a dataset. Tests were performed using a large number of datasets from OpenML.
Visual Explanations
COD provides a number of methods to help understand the outliers found. The first is the explain_row() API, where users can get a breakdown of the rational behind the score given for the specified row.
As indicated, an outlier row many have any number of anomalies. For any one-dimension anomalies found, bar plots or histograms are presented putting the value in context of the other values in the column. For further context, other values flagged as anomalous are also shown.
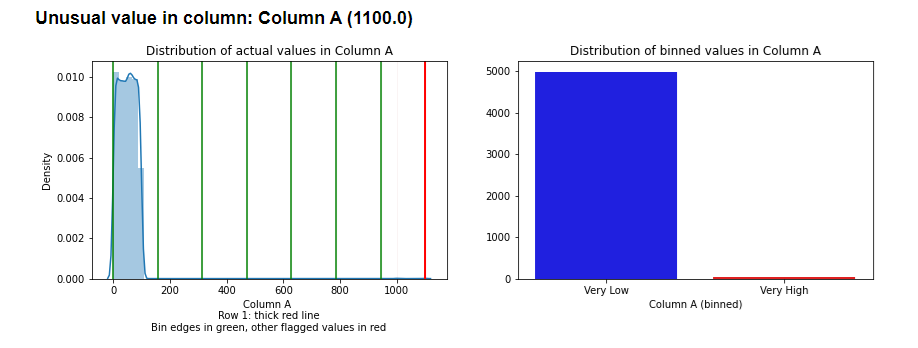
The following image shows an outlier from the Examples_Counts_Outlier_Detector notebook on the github page (which used simple, synthetic data). This in an outlier in Row 1, having an unusual value in Column A. The left pane shows the distribution of Column A, with green vertical lines indicating the bin edges and the red vertical lines the flagged outliers. This example uses 7 bins (so divides numeric features into: ‘Very Low’, ‘Low’, ‘Med-Low’, ‘Med’, ‘Med-High’, ‘High’, ‘Very High’).
The right pane shows the histogram. As 5 bins are empty (all values in this column are either ‘Very Low’ or ‘Very High’), only 2 bins are shown here. The plot indicates the rarity of ‘Very High’ values in this feature, which are substantially less common that ‘Very Low’ values and consequently considered outliers.
For any two-dimensional anomalies found, a scatter plot (in the case of two numeric columns), strip plot (in the case on one numeric and one categorical column), or heatmap (in the case of two categorical columns) will be presented. This shows clearly how the value compares to other values in the 2d space.
Shown here is an example (from the demo_OpenML notebook on the github site) with two numeric features. As well as the scatterplot (left pane), a heatmap (right pane) is shown to display the counts of each bin:
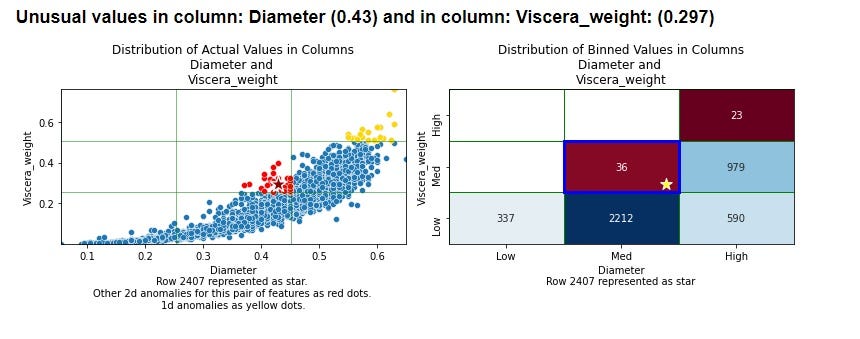
This uses the abalone dataset from OpenML (https://www.openml.org/search?type=data&sort=runs&id=183&status=active, licenced under CC BY 4.0). The row being explained (Row 2407) is shown as a star in both plots. In this example, 3 bins per feature were used, so the 2d space has 9 bins. The row being explained is in a bin with only 36 records. The most populated bin, for comparison, has 2212.
In the scatterplot (the left pane), other records in this bin are shown in red. Records in other bins with unusually low counts are shown in yellow.
Understanding 1d and 2d outliers is straightforward as the visualizations possible are quite comprehensible. Working with 3d and higher dimensions is conceptually similar, though it is more difficult to visualize. It is still quite manageable where the number of dimensions is reasonably low, but is not as straightforward as 1 or 2 dimensions.
For outliers beyond 2d, bar plots are presented, giving the counts of each combination of values within the current space (combination of features), giving the count for the flagged combination of values / bins in context.
The following is part of an explanation of an outlier row identified in the Abalone dataset, in this case containing a 3d outlier based on the Sex, Diameter, and Whole_weight features.

The explain_features() API may also be called to drill down further into any of these. In this case, it provides the counts of each combination and we can see the combination in the plot above (Sex=I, Diameter=Med; Whole_weight=Med) has a count of only 12:

For the highest level of interpretability, I’d recommend limiting max_dimensions to 2, which will examine the dataset only for 1d and 2d outliers, presenting the results as one-dimensional bar plots or histograms, or two-dimensional plots, which allow the the most complete understanding of the space presented. However, using 3 or more dimensions (as with the plot for Sex, Diameter, and Whole_weight above) is still reasonably interpretable.
Accuracy Experiments
Although the strength of COD is its interpretability, it’s still important that the algorithm identifies most meaningful outliers and does not erroneously flag more typical records.
Experiments (described on the github page) demonstrate that Counts Outlier Detector is competitive with Isolation Forest, at least as measured with respect to a form of testing called doping: where a small number of values within real datasets are modified (randomly, but so as to usually create anomalous records — records that do not have the normal associations between the features) and testing if outlier detectors are able to identify the modified rows.
There are other valid ways to evaluate outlier detectors, and even using the doping process, it can vary how the data is modified, how many records are doped, and so on. In these tests, COD slightly outperformed Isolation Forest, but in other tests Isolation Forest may do better than COD, and other detectors may as well. Nevertheless, this does demonstrate that COD performs well and is competitive, in terms of accuracy, with standard outlier detectors.
Installation
This tool uses a single class, CountsOutlierDetector, which needs to be included in any projects using this. This can be done simply by copying or downloading the single .py file that defines it, counts_outlier_detector.py and importing the class.
Conclusions
This detector has the advantages of:
- It is able to provide explanations of each outlier as clearly as possible. To explain why a row is scored as it is, an explanation is given using only as many features as necessary to explain its score.
- It is able to provide full statistics about each space, which allows it to provide full context of the outlierness of each row.
It’s generally agreed in outlier detection that each detector will identify certain types of outliers and that it’s usually beneficial to use multiple detectors to reliably catch most of the outliers in a dataset. COD may be useful simply for this purpose: it’s a straightforward, useful outlier detector that may detect outliers somewhat different from other detectors.
However, interpretability is often very important with outlier detection, and there are, unfortunately, few options available now for interpretable outlier detection. COD provides one of the few, and may be worth trying for this reason.
All images are created by the author.
Counts Outlier Detector: Interpretable Outlier Detection was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Counts Outlier Detector: Interpretable Outlier Detection
Go Here to Read this Fast! Counts Outlier Detector: Interpretable Outlier Detection