A fast and effective approach to generating fluent sentences from given keywords using public pre-trained models

Large language models, like GPT, have achieved unprecedented results in free-form text generation. They’re widely used for writing e-mails, copyrighting, or storytelling. However, their success in constrained text generation remains limited [1].
Constrained text generation involves producing sentences with specific attributes like sentiment, tense, template, or style. We will consider one specific kind of constrained text generation, namely keyword-based generation. In this task, it is required that the model generate sentences that include given keywords. Depending on the application, these sentences should (a) contain all the keywords (i.e. assure high coverage) (b) be grammatically correct (c) respect common sense (d) exhibit lexical and grammatical diversity.
For auto-regressive forward generation models, like GPT, constrained generation is particularly challenging. These models yield tokens sequentially from left to right, one at a time. By design, they lack precise control over the generated sequence and struggle to support constraints at arbitrary positions in the output or constraints involving multiple keywords. As a result, these models usually exhibit poor coverage (a) and diversity (d), while providing fluent sentences (b,c). Although some sampling strategies, like dynamic beam allocation [2], were specifically designed to improve constrained text generation with forward models, they demonstrated inferior results in independent testing [3].
An alternative approach [4], known as CGMH, consists in constructing the sentence iteratively by executing elementary operations on the existing sequence, such as word deletion, insertion, or replacement. The initial sequence is usually an ordered sequence of given keywords. Because of the vast search space, such methods often struggle to produce a meaningful sentence within a reasonable time frame. Therefore, although these models may ensure good coverage (a) and diversity (d), they might fail to satisfy fluency requirements (b,c). To overcome these problems, it was suggested to restrict the search space by including a differentiable loss function [5] or a pre-trained neural network [6] to guide the sampler. However, these adjustments did not lead to any practically significant improvement compared to CGMH.
In the following, we will propose a new approach to generating sentences with given keywords. The idea is to limit the search space by starting from a correct sentence and reducing the set of possible operations. It turns out that when only the replacement operation is considered, the BERT model provides a convenient way to generate desired sentences via Gibbs sampling.
Gibbs sampling from BERT
Sampling sentences via Gibbs sampling from BERT was first proposed in [7]. Here, we adapt this idea for constrained sentence generation.
To simplify theoretical introduction, we will start by explaining the grounds of the CGMH approach [4], which uses the Metropolis-Hastings algorithm to sample from a sentence distribution satisfying the given constraints.
The sampler starts from a given sequence of keywords. At each step, a random position in the current sentence is selected and one of the three possible actions (chosen with probability p=1/3) is executed: insertion, deletion, or word replacement. After that, a candidate sentence is sampled from the corresponding proposal distribution. In particular, the proposal distribution for replacement takes up the form:

where x is the current sentence, x’ is a candidate sentence, w_1…w_n are the words in the sentence, w^c is the proposed word, V is the dictionary size, and π is the sampled distribution. The candidate sentence can then be either accepted or rejected using the acceptance rate:
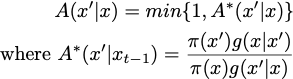
To get a sentence probability, the authors propose to use a simple seq2seq LSTM-based network:

where p_LM(x) is the sentence probability given by a language model and χ(x) is an indicator function, which is 1 when all of the keyword words are included in the sentence and 0 otherwise.
When keyword constraints are imposed, the generation starts from a given sequence of keywords. These words are then excluded from deletion and replacement operations. After a certain time (the burn-in period), generation converges to a stationary distribution.
As noted above, a weak point of such methods is the large search space that prevents them from generating meaningful sentences within a reasonable time. We will now reduce the search space by completely eliminating insertions and deletions from sentence generation.
Ok, but what does this have to do with Gibbs sampling and BERT?
Citing Wikipedia, Gibbs sampling is used when the joint distribution is not known explicitly or is difficult to sample from directly, but the conditional distribution of each variable is known and is easy (or at least, easier) to sample from.
BERT is a transformer-based model designed to pre-train deep bidirectional representations by jointly conditioning on both left and right context, enabling it to understand the context of a word based on its surroundings. For us, it is particularly important that BERT is trained in a masked language model fashion, i.e. it predicts masked words (tokens) given all other words (tokens) in the sentence. If only a single word is masked, then the model directly provides the conditional probability p(w_c|w_1,…,w_{m-1},w_{m+1},…,w_n). Note that it is only possible due to the bidirectional nature of BERT, since it provides access to tokens on the left as well as on the right from the masked word. On the other hand, the joint probability p(w_1,…w_n) is not readily available from the BERT output. Looks like a Gibbs sampling use case, doesn’t it? Rewriting g(x’|x), one obtains:
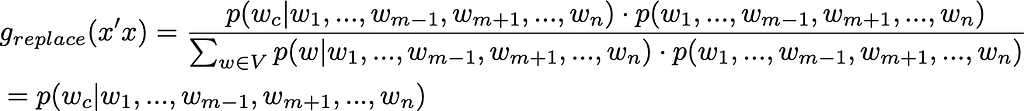
Note that as far as only the replacement action is considered, the acceptance rate is always 1:

So, replacement is, in fact, a Gibbs sampling step, with the proposal distribution directly provided by the BERT model!
Experiment
To illustrate the method, we will use a pre-trained BERT model from Hugging Face. To have an independent assessment of sentence fluency, we will also compute sentence perplexity using the GPT2 model.
Let us start by loading all the required modules and models into memory:
from transformers import BertForMaskedLM, AutoModelForCausalLM, AutoTokenizer
import torch
import torch.nn.functional as F
import numpy as np
import pandas as pd
device = torch.device('cpu') #works just fine
#Load BERT
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = BertForMaskedLM.from_pretrained("bert-base-uncased")
model.to(device)
#Load GPT2
gpt2_model = AutoModelForCausalLM.from_pretrained("gpt2") #dbmdz/german-gpt2
gpt2_tokenizer = AutoTokenizer.from_pretrained("gpt2")
gpt2_tokenizer.padding_side = "left"
gpt2_tokenizer.pad_token = gpt2_tokenizer.eos_token
We then need to define some important constants:
N_GIBBS_RUNS = 4 #number of runs
N_ITR_PER_RUN = 500 #number of iterations per each run
N_MASKED_WORDS_PER_ITR = 1 #number of masked tokens per iteration
MIN_TOKENS_PROB = 1e-3 #don't use tokens with lower probability for replacement
Since we will use only the replacement action, we need to select an initial sentences containing the desired keywords. Let it be
I often dream about a spacious villa by the sea.
Everybody must have dreamt about this at some time… As keywords we will fix, quite arbitrary, dream and sea.
initial_sentence = 'I often dream about a spacious villa by the sea .'
words = initial_sentence.split(' ')
keyword_idx = [2,9]
keyword_idx.append(len(words)-1) # always keep the punctuation mark at the end of the sentence
Now we are ready to sample:
def get_bert_tokens(words, indices):
sentence = " ".join(words)
masked_sentence = [word if not word_idx in indices else "[MASK]" for word_idx,word in enumerate(words) ]
masked_sentence = ' '.join(masked_sentence)
bert_sentence = f'[CLS] {masked_sentence} [SEP] '
bert_tokens = tokenizer.tokenize(bert_sentence)
return bert_tokens
n_words = len(words)
n_fixed = len(keyword_idx)
generated_sent = []
for j in range(N_GIBBS_RUNS):
words = initial_sentence.split(' ')
for i in range(N_ITR_PER_RUN):
if i%10==0:
print(i)
#choose N_MASKED_WORDS_PER_ITR random words to mask (excluding keywords)
masked_words_idx = np.random.choice([x for x in range(n_words) if not x in keyword_idx], replace=False, size=N_MASKED_WORDS_PER_ITR).tolist()
masked_words_idx.sort()
while len(masked_words_idx)>0:
#reconstruct successively each of the masked word
bert_tokens = get_bert_tokens(words, masked_words_idx) #get tokens from tokenizer
masked_index = [i for i, x in enumerate(bert_tokens) if x == '[MASK]']
indexed_tokens = tokenizer.convert_tokens_to_ids(bert_tokens)
segments_ids = [0] * len(bert_tokens)
tokens_tensor = torch.tensor([indexed_tokens]).to(device)
segments_tensors = torch.tensor([segments_ids]).to(device)
with torch.no_grad():
outputs = model(tokens_tensor, token_type_ids=segments_tensors)
predictions = outputs[0][0]
reconstruct_pos = 0 #reconstruct leftmost masked token
probs = F.softmax(predictions[masked_index[reconstruct_pos]],dim=0).cpu().numpy()
probs[probs<MIN_TOKENS_PROB] = 0 #ignore low probabily tokens
if len(probs)>0:
#sample a token using the conditional probability from BERT
token = np.random.choice(range(len(probs)), size=1, p=probs/probs.sum(), replace=False)
predicted_token = tokenizer.convert_ids_to_tokens(token)[0]
words[masked_words_idx[reconstruct_pos]] = predicted_token #replace the word in the sequence with the chosen token
del masked_words_idx[reconstruct_pos]
sentence = ' '.join(words)
with torch.no_grad():
inputs = gpt2_tokenizer(sentence, return_tensors = "pt")
loss = gpt2_model(input_ids = inputs["input_ids"], labels = inputs["input_ids"]).loss
gpt2_perplexity = torch.exp(loss).item()
#sentence = sentence.capitalize().replace(' .','.')
gpt2_perplexity = int(gpt2_perplexity)
generated_sent.append((sentence,gpt2_perplexity))
df = pd.DataFrame(generated_sent, columns=['sentence','perplexity'])
Let’s now have a look at the perplexity plot:
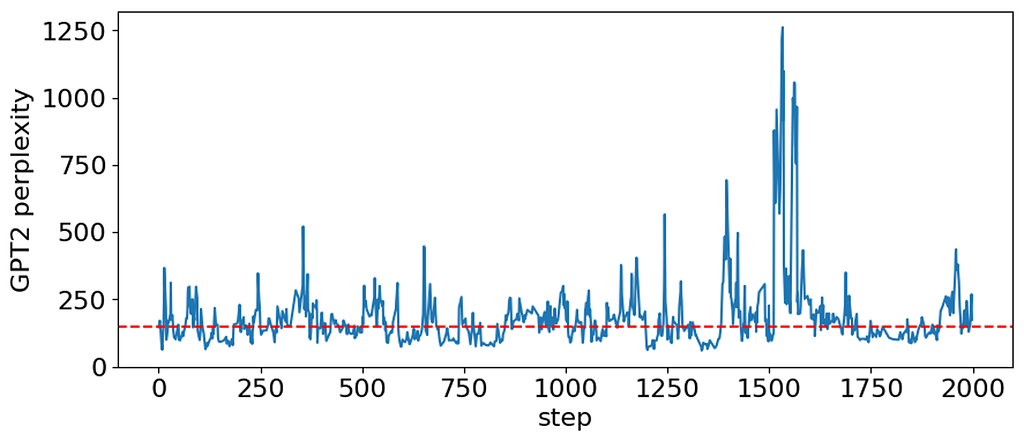
There are two things to note here. First, the perplexity starts from a relatively small value (perplexity=147). This is just because we initialized the sampler with a valid sentence that doesn’t look awkward to GPT2. Basically, the sentences whose perplexity does not exceed the starting value (dashed red line) can be considered passing the external check. Second, subsequent samples are correlated. This is a known property of the Gibbs sampler and the reason why it is often recommended to take every kth sample.
In fact, out of 2000 generated sentences we got 822 unique. Their perplexity ranges from 60 to 1261 with 341 samples having perplexity below that of the initial sentence:
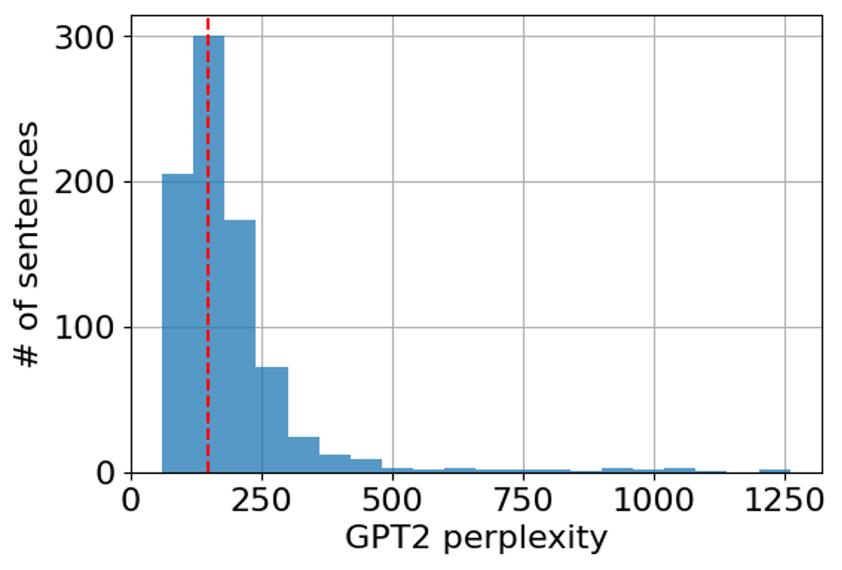
How do these sentences look like? Let’s take a random subset:

These sentences look indeed quite fluent. Note that the chosen keywords (dream and sea) appear in each sentence.
It is also tempting to see what happens if we don’t set any keywords. Let’s take a random subset of sentences generated with an empty keywords set:

So, these sentence also look quite fluent and diverse! In fact, using an empty keyword set simply turns BERT into a random sentence generator. Note, however, that all these sentences have 10 words, as the initial sentence. The reason is that the BERT model can’t change the sentence length arbitrary.
Now, why do we need to run the sampler N_GIBBS_RUNS=4 times, wouldn’t just a single run be enough? In fact, running several times is necessary since a Gibbs sampler can get stuck in a local minimum [7]. To illustrate this case, we computed the accumulated vocabulary size (number of distinct words used so far in the generated sentences) when running the sampler once for 2000 iterations and when re-initializing the sampler with the initial sentence every 500 iterations:
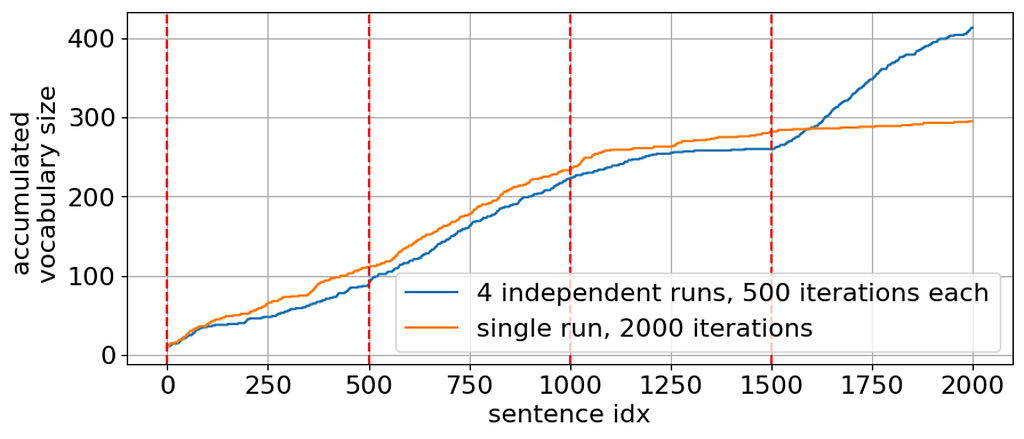
It can be clearly seen that a single run gets stuck at about 1500 iterations and the sampler is not able to generate sentences with new words after this point. In contrast, re-initializing the sampler every 500 iterations helps to get out of this local minimum and improves lexically diversity of the generated sentences.
Conclusion
In sum, the proposed method generates realistic sentences starting from a sentence containing given keywords. The resulting sentences ensure 100% coverage (a), sound grammatically correct (b), respect common sense (c), and provide lexical diversity (d). Additionally, the method is incredibly simple and can be used with publicly available pre-trained models. The main weaknesses of the method, is, of course, its dependence of a starting sentence satisfying the given constraints. First, the starting sentence should be somehow provided from an expert or any other external source. Second, while ensuring grammatically correct sentence generation, it also limits the grammatical diversity of the output. A possible solution would be to provide several input sentences by mining a reliable sentence database.
References
[1] Garbacea, Cristina, and Qiaozhu Mei. “Why is constrained neural language generation particularly challenging?.” arXiv preprint arXiv:2206.05395 (2022).
[2] Post, Matt, and David Vilar. “Fast lexically constrained decoding with dynamic beam allocation for neural machine translation.” arXiv preprint arXiv:1804.06609 (2018).
[3] Lin, Bill Yuchen, et al. “CommonGen: A constrained text generation challenge for generative commonsense reasoning.” arXiv preprint arXiv:1911.03705 (2019).
[4] Miao, Ning, et al. “Cgmh: Constrained sentence generation by metropolis-hastings sampling.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 33. №01. 2019.
[5] Sha, Lei. “Gradient-guided unsupervised lexically constrained text generation.” Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020.
[6] He, Xingwei, and Victor OK Li. “Show me how to revise: Improving lexically constrained sentence generation with xlnet.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 35. №14. 2021.
[7] Wang, Alex, and Kyunghyun Cho. “BERT has a mouth, and it must speak: BERT as a Markov random field language model.” arXiv preprint arXiv:1902.04094 (2019).
Constrained Sentence Generation Using Gibbs Sampling and BERT was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Constrained Sentence Generation Using Gibbs Sampling and BERT
Go Here to Read this Fast! Constrained Sentence Generation Using Gibbs Sampling and BERT