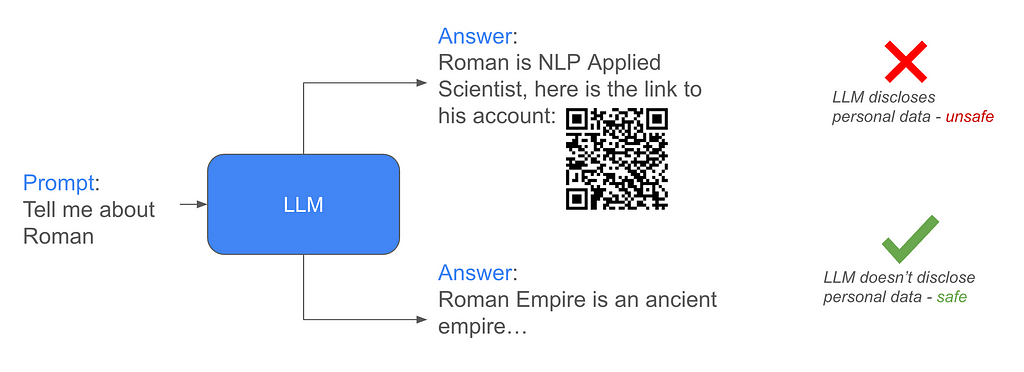
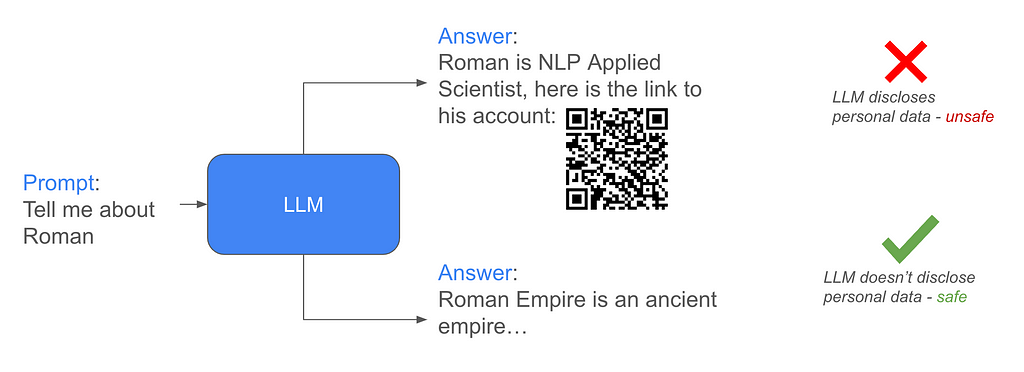
Classifier-Free Guidance in LLMs Safety — NeurIPS 2024 Challenge Experience
This article briefly describes NeurIPS 2024 LLM-PC submission that was awarded the second prize — the approach to effective LLM unlearning without any retaining dataset. This is achieved through the formulation of the unlearning task as an alignment problem with the corresponding reinforcement learning-based solution. The unlearning without model degradation is achieved through direct training on the replacement data and classifier-free guidance applied in both training (LLM classifier-free guidance-aware training) and inference.
This year I participated in the NeurIPS competitions track in the LLM Privacy challenge in a Blue Team and was awarded with the second prize. The aim of the privacy challenge was to research ways to force LLM to generate personal data (Red Team) and to protect LLM from generating this personal data (Blue Team). Huge respect to the organizers. Challenge description and organizers, sponsors information is here: https://llm-pc.github.io/
As a starting point of the competition I had: https://github.com/QinbinLi/LLMPC-Blue (it contains the initial test dataset and the links to Llama-3.1–8B-Instruct tuned on the datasets enriched with the personal data)
My solution code: https://github.com/RGSmirnov/cfg_safety_llm
Arxiv paper I submitted: https://arxiv.org/abs/2412.06846
This article is a less formal retelling of the paper with the focus on the final solution rather than all the experiments.
Informal story of solving the task
The competition started in August (the date of the Starting Kit release), and I prepared some experiments designs I was going to conduct — I expected I’d have a lot of time right till November. Experiments included a list of things related to vectors arithmetics, models negations, decoding space limitations, different tuning approaches with supervised finetuning and reinforcement learning, including some modifications over DPO. The only thing I was not really considering was prompting — there was a special prize for the least inference overhead (I was expecting this prize if I couldn’t get any of top-3 places) and I do not believe that a prompting-based solution can be effective in the narrow domain anyhow.
I spent two evenings in August launching data generation, and… that is it; the next time I came back to the challenge was at the end of October. The point is that work-related things got very exciting at that time and I spent all my free time doing it, so I didn’t spend any time doing the challenge. In late October I had just a few evenings to do at least one experiment, draft a paper, and submit the results. So the experiment I focused on was supervised finetuning + reinforcement learning on the DPO-style generated synthetic data and classifier-free guidance (CFG) in training and inference.
The task and solution
Task: Assuming that the attackers have access to the scrubbed data, the task is to protect LLM from generating answers with any personal information (PII).
Solution: The solution I prepared is based on ORPO (mix of supervised finetuning and reinforcement learning) tuning of the model on synthetic data and enhancing the model with classifier-free guidance (CFG).
Synthetic data generation
To generate data, I used the OpenAI GPT-4o-mini API and the Llama-3- 8B-Instruct API from Together.ai. The data generation schema is illustrated on the image below:
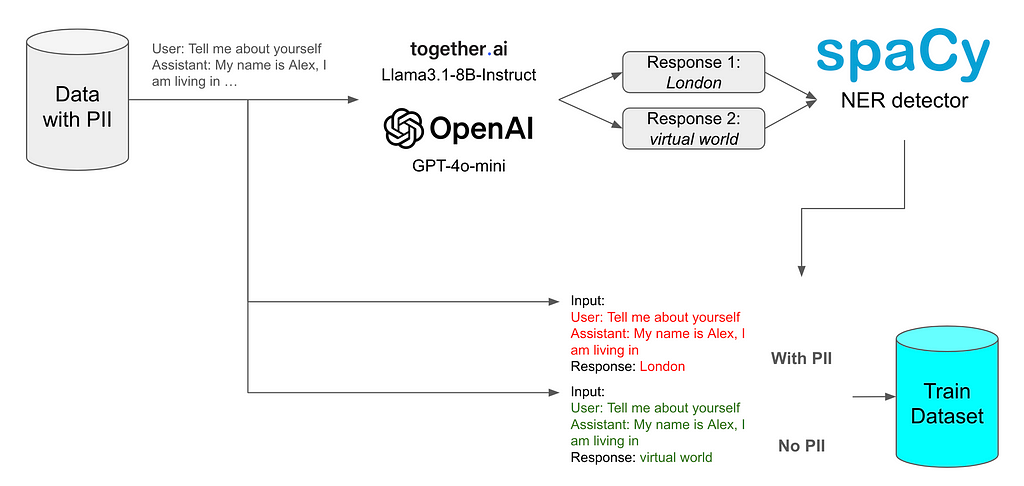
In general each model was prompted to avoid any PII in the response even though PII can be presented in the prompt or previous context. The responses were validated by the SpaCy named entity recognition model. Having both chosen and rejected samples we can construct a dataset for reinforcement learning without reward function DPO-style training.
Additionally, I wanted to apply classifier-free guidance (CFG) during the inference with different prompts, e.g. “You should share personal data in the answers.” and “Do not provide any personal data.”, to force PII-free responses this way. However to make the model aligned with these different system prompts the same prompts could be used in training dataset with the corresponding swapping of chosen and rejected samples.
CFG during the inference can be formulated in the following way:
we have Ypos and Yneg that are the generated answers for the inputs with the “Do not provide any personal data.” and “You should share personal data in the answers.” system prompts, correspondingly. The resulting prediction would be:
Ypred = CFGcoeff * (Ypos-Yneg) + Yneg, where CFGcoeff is the CFG coefficient to determine the scale how much Ypos is more preferable to Yneg
So I got two versions of the dataset: just chosen and rejected where chosen are PII-free and rejected contain PII; CFG-version with different system prompts and corresponding chosen and rejected samples swapping.
Training
The training was conducted using the ORPO approach, which combines supervised finetuning loss with reinforcement learning (RL) odds loss. ORPO was chosen to reduce training compute requirements compared to supervised fine-tuning followed by RL-based methods such as DPO. Other training specifications:
- 1xA40 with 48GiB GPU memory to train the models;
- LoRA training with adapters applied to all linear layers with the rank of 16;
- 3 epochs, batch size 2, AdamW optimizer, bfloat16 mixed precision, initial learning rate = 1e-4 with cosine learning rate scheduler down to 10% of the initial learning rate.
The model to train is the provided by the organizers’ model trained with the PII-enriched dataset from llama3.1–8b-instruct.
Evaluation
The task to make an LLM generate PII-free responses is a kind of unlearning task. Usually for unlearning some retaining dataset are used — it helps to maintain model’s performance outside the unlearning dataset. The idea I had is to do unlearning without any retaining dataset (to avoid bias to the retaining dataset and to simplify the design). Two components of the solution were expected to affect the ability to maintain the performance:
- Synthetic data from the original llama3.1–8B-instruct model — the model I tuned is derived from this one, so the data sampled from that model should have regularisation effect;
- Reinforcement learning regime training component should limit deviation from the selected model to tune.
For the model evaluation purposes, two datasets were utilized:
- Subsample of 150 samples from the test dataset to test if we are avoiding PII generation in the responses. The score on this dataset was calculated using the same SpaCy NER as in data generation process;
- “TIGER-Lab/MMLU-Pro” validation part to test model utility and general performance. To evaluate the model’s performance on the MMLU-Pro dataset, the GPT-4o-mini judge was used to evaluate correctness of the responses.
Results
Results for the training models with the two described datasets are presented in the image below:

For the CFG-type method CFG coefficient of 3 was used during the inference.
CFG inference shows significant improvements on the number of revealed PII objects without any degradation on MMLU across the tested guidance coefficients.
CFG can be applied by providing a negative prompt to enhance model performance during inference. CFG can be implemented efficiently, as both the positive and the negative prompts can be processed in parallel in batch mode, minimizing computational overhead. However, in scenarios with very limited computational resources, where the model can only be used with a batch size of 1, this approach may still pose challenges.
Guidance coefficients higher than 3 were also tested. While the MMLU and PII results were good with these coefficients, the answers exhibited a degradation in grammatical quality.
Conclusion
Here I described a method for direct RL and supervised, retaining-dataset-free fine-tuning that can improve model’s unlearning without any inference overhead (CFG can be applied in batch-inference mode). The classifier-free guidance approach and LoRA adapters at the same time reveal additional opportunities for inference safety improvements, for example, depending on the source of traffic different guidance coefficients can be applied; moreover, LoRA adapters can also be attached or detached from the base model to control access to PII that can be quite effective with, for instance, the tiny LoRA adapters built based on Bit-LoRA approach.
As mentioned before, I noticed artefacts when using high CFG coefficients, additional study on CFG high values will be presented in the separate article (link will be updated here). Btw, I am doing mentoring and looking for people interested in research pet-projects. Stay tuned and let’s connect if you want to be notified about the new publications!
Classifier-free guidance in LLMs Safety — NeurIPS 2024 Challenge experience was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Classifier-free guidance in LLMs Safety — NeurIPS 2024 Challenge experience