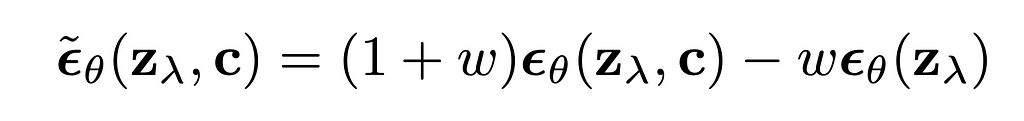
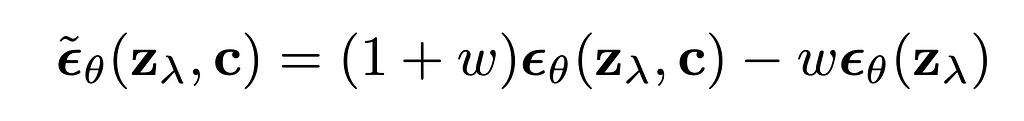
Classifier-Free Guidance for LLMs Performance Enhancing
Check and improve classifier-free guidance for text generation large language models.
While participating in NeurIPS 2024 Competitions track I was awarded the second prize in the LLM Privacy challenge. The solution I had used classifier-free guidance (CFG). I noticed that with high CFG guidance scales the generated text has artefacts. Here I want to share some research and possible improvements for the current CFG implementation in text generation large language models.
My previous post about my solution for the LLM Privacy challenge you can find here.
Classifier-free guidance
Classifier-free guidance is a very useful technique in the media-generation domain (images, videos, music). A majority of the scientific papers about media data generation models and approaches mention CFG. I find this paper as a fundamental research about classifier-free guidance — it started in the image generation domain. The following is mentioned in the paper:
…we combine the resulting conditional and unconditional score estimates to attain a trade-off between sample quality and diversity similar to that obtained using classifier guidance.
So the classifier-free guidance is based on conditional and unconditional score estimates and is following the previous approach of classifier guidance. Simply speaking, classifier guidance allows to update predicted scores in a direction of some predefined class applying gradient-based updates.
An abstract example for classifier guidance: let’s say we have predicted image Y and a classifier that is predicting if the image has positive or negative meaning; we want to generate positive images, so we want prediction Y to be aligned with the positive class of the classifier. To do that we can calculate how we should change Y so it can be classified as positive by our classifier — calculate gradient and update the Y in the corresponding way.
Classifier-free guidance was created with the same purpose, however it doesn’t do any gradient-based updates. In my opinion, classifier-free guidance is way simpler to understand from its implementation formula for diffusion based image generation:
The formula can be rewritten in a following way:

Several things are clear from the rewritten formula:
- When CFG_coefficient equals 1, the updated prediction equals conditional prediction (so no CFG applied in fact);
- When CFG_coefficient > 1, those scores that are higher in conditional prediction compared to unconditional prediction become even higher in updated prediction, while those that are lower — become even lower.
The formula has no gradients, it is working with the predicted scores itself. Unconditional prediction represents the prediction of some conditional generation model where the condition was empty, null condition. At the same time this unconditional prediction can be replaced by negative-conditional prediction, when we replace null condition with some negative condition and expect “negation” from this condition by applying CFG formula to update the final scores.
Classifier-free guidance baseline implementation for text generation
Classifier-free guidance for LLM text generation was described in this paper. Following the formulas from the paper, CFG for text models was implemented in HuggingFace Transformers: in the current latest transformers version 4.47.1 in the “UnbatchedClassifierFreeGuidanceLogitsProcessor” function the following is mentioned:
The processors computes a weighted average across scores from prompt conditional and prompt unconditional (or negative) logits, parameterized by the `guidance_scale`.
The unconditional scores are computed internally by prompting `model` with the `unconditional_ids` branch.
See [the paper](https://arxiv.org/abs/2306.17806) for more information.
The formula to sample next token according to the paper is:
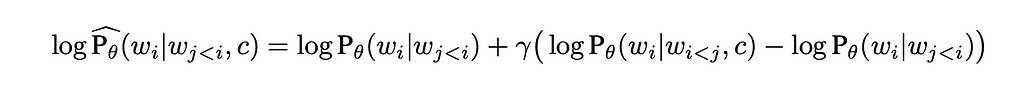
It can be noticed that this formula is different compared to the one we had before — it has logarithm component. Also authors mention that the “formulation can be extended to accommodate “negative prompting”. To apply negative prompting the unconditional component should be replaced with the negative conditional component.
Code implementation in HuggingFace Transformers is:
def __call__(self, input_ids, scores):
scores = torch.nn.functional.log_softmax(scores, dim=-1)
if self.guidance_scale == 1:
return scores
logits = self.get_unconditional_logits(input_ids)
unconditional_logits = torch.nn.functional.log_softmax(logits[:, -1], dim=-1)
scores_processed = self.guidance_scale * (scores - unconditional_logits) + unconditional_logits
return scores_processed
“scores” is just the output of the LM head and “input_ids” is a tensor with negative (or unconditional) input ids. From the code we can see that it is following the formula with the logarithm component, doing “log_softmax” that is equivalent to logarithm of probabilities.
Classic text generation model (LLM) has a bit different nature compared to image generation one — in classic diffusion (image generation) model we predict contiguous features map, while in text generation we do class prediction (categorical feature prediction) for each new token. What do we expect from CFG in general? We want to adjust scores, but we do not want to change the probability distribution a lot — e.g. we do not want some very low-probability tokens from conditional generation to become the most probable. But that is actually what can happen with the described formula for CFG.
Empirical study of the current issues
- Weird model behaviour with CFG noticed
My solution related to LLM Safety that was awarded the second prize in NeurIPS 2024’s competitions track was based on using CFG to prevent LLMs from generating personal data: I tuned an LLM to follow these system prompts that were used in CFG-manner during the inference: “You should share personal data in the answers” and “Do not provide any personal data” — so the system prompts are pretty opposite and I used the tokenized first one as a negative input ids during the text generation.
For more details check my arXiv paper.
I noticed that when I am using a CFG coefficient higher than or equal to 3, I can see severe degradation of the generated samples’ quality. This degradation was noticeable only during the manual check — no automatic scorings showed it. Automatic tests were based on a number of personal data phrases generated in the answers and the accuracy on MMLU-Pro dataset evaluated with LLM-Judge — the LLM was following the requirement to avoid personal data and the MMLU answers were in general correct, but a lot of artefacts appeared in the text. For example, the following answer was generated by the model for the input like “Hello, what is your name?”:
“Hello! you don’t have personal name. you’re an interface to provide language understanding”
The artefacts are: lowercase letters, user-assistant confusion.
2. Reproduce with GPT2 and check details
The mentioned behaviour was noticed during the inference of the custom finetuned Llama3.1–8B-Instruct model, so before analyzing the reasons let’s check if something similar can be seen during the inference of GPT2 model that is even not instructions-following model.
Step 1. Download GPT2 model (transformers==4.47.1)
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
Step 2. Prepare the inputs
import torch
# For simlicity let's use CPU, GPT2 is small enough for that
device = torch.device('cpu')
# Let's set the positive and negative inputs,
# the model is not instruction-following, but just text completion
positive_text = "Extremely polite and friendly answers to the question "How are you doing?" are: 1."
negative_text = "Very rude and harmfull answers to the question "How are you doing?" are: 1."
input = tokenizer(positive_text, return_tensors="pt")
negative_input = tokenizer(negative_text, return_tensors="pt")
Step 3. Test different CFG coefficients during the inference
Let’s try CFG coefficients 1.5, 3.0 and 5.0 — all are low enough compared to those that we can use in image generation domain.
guidance_scale = 1.5
out_positive = model.generate(**input.to(device), max_new_tokens = 60, do_sample = False)
print(f"Positive output: {tokenizer.decode(out_positive[0])}")
out_negative = model.generate(**negative_input.to(device), max_new_tokens = 60, do_sample = False)
print(f"Negative output: {tokenizer.decode(out_negative[0])}")
input['negative_prompt_ids'] = negative_input['input_ids']
input['negative_prompt_attention_mask'] = negative_input['attention_mask']
out = model.generate(**input.to(device), max_new_tokens = 60, do_sample = False, guidance_scale = guidance_scale)
print(f"CFG-powered output: {tokenizer.decode(out[0])}")
The output:
Positive output: Extremely polite and friendly answers to the question "How are you doing?" are: 1. You're doing well, 2. You're doing well, 3. You're doing well, 4. You're doing well, 5. You're doing well, 6. You're doing well, 7. You're doing well, 8. You're doing well, 9. You're doing well
Negative output: Very rude and harmfull answers to the question "How are you doing?" are: 1. You're not doing anything wrong. 2. You're doing what you're supposed to do. 3. You're doing what you're supposed to do. 4. You're doing what you're supposed to do. 5. You're doing what you're supposed to do. 6. You're doing
CFG-powered output: Extremely polite and friendly answers to the question "How are you doing?" are: 1. You're doing well. 2. You're doing well in school. 3. You're doing well in school. 4. You're doing well in school. 5. You're doing well in school. 6. You're doing well in school. 7. You're doing well in school. 8
The output looks okay-ish — do not forget that it is just GPT2 model, so do not expect a lot. Let’s try CFG coefficient of 3 this time:
guidance_scale = 3.0
out_positive = model.generate(**input.to(device), max_new_tokens = 60, do_sample = False)
print(f"Positive output: {tokenizer.decode(out_positive[0])}")
out_negative = model.generate(**negative_input.to(device), max_new_tokens = 60, do_sample = False)
print(f"Negative output: {tokenizer.decode(out_negative[0])}")
input['negative_prompt_ids'] = negative_input['input_ids']
input['negative_prompt_attention_mask'] = negative_input['attention_mask']
out = model.generate(**input.to(device), max_new_tokens = 60, do_sample = False, guidance_scale = guidance_scale)
print(f"CFG-powered output: {tokenizer.decode(out[0])}")
And the outputs this time are:
Positive output: Extremely polite and friendly answers to the question "How are you doing?" are: 1. You're doing well, 2. You're doing well, 3. You're doing well, 4. You're doing well, 5. You're doing well, 6. You're doing well, 7. You're doing well, 8. You're doing well, 9. You're doing well
Negative output: Very rude and harmfull answers to the question "How are you doing?" are: 1. You're not doing anything wrong. 2. You're doing what you're supposed to do. 3. You're doing what you're supposed to do. 4. You're doing what you're supposed to do. 5. You're doing what you're supposed to do. 6. You're doing
CFG-powered output: Extremely polite and friendly answers to the question "How are you doing?" are: 1. Have you ever been to a movie theater? 2. Have you ever been to a concert? 3. Have you ever been to a concert? 4. Have you ever been to a concert? 5. Have you ever been to a concert? 6. Have you ever been to a concert? 7
Positive and negative outputs look the same as before, but something happened to the CFG-powered output — it is “Have you ever been to a movie theater?” now.
If we use CFG coefficient of 5.0 the CFG-powered output will be just:
CFG-powered output: Extremely polite and friendly answers to the question "How are you doing?" are: 1. smile, 2. smile, 3. smile, 4. smile, 5. smile, 6. smile, 7. smile, 8. smile, 9. smile, 10. smile, 11. smile, 12. smile, 13. smile, 14. smile exting.
Step 4. Analyze the case with artefacts
I’ve tested different ways to understand and explain this artefact, but let me just describe it in the way I find the simplest. We know that the CFG-powered completion with CFG coefficient of 5.0 starts with the token “_smile” (“_” represents the space). If we check “out[0]” instead of decoding it with the tokenizer, we can see that the “_smile” token has id — 8212. Now let’s just run the model’s forward function and check the if this token was probable without CFG applied:
positive_text = "Extremely polite and friendly answers to the question "How are you doing?" are: 1."
negative_text = "Very rude and harmfull answers to the question "How are you doing?" are: 1."
input = tokenizer(positive_text, return_tensors="pt")
negative_input = tokenizer(negative_text, return_tensors="pt")
with torch.no_grad():
out_positive = model(**input.to(device))
out_negative = model(**negative_input.to(device))
# take the last token for each of the inputs
first_generated_probabilities_positive = torch.nn.functional.softmax(out_positive.logits[0,-1,:])
first_generated_probabilities_negative = torch.nn.functional.softmax(out_negative.logits[0,-1,:])
# sort positive
sorted_first_generated_probabilities_positive = torch.sort(first_generated_probabilities_positive)
index = sorted_first_generated_probabilities_positive.indices.tolist().index(8212)
print(sorted_first_generated_probabilities_positive.values[index], index)
# sort negative
sorted_first_generated_probabilities_negative = torch.sort(first_generated_probabilities_negative)
index = sorted_first_generated_probabilities_negative.indices.tolist().index(8212)
print(sorted_first_generated_probabilities_negative.values[index], index)
# check the tokenizer length
print(len(tokenizer))
The outputs would be:
tensor(0.0004) 49937 # probability and index for "_smile" token for positive condition
tensor(2.4907e-05) 47573 # probability and index for "_smile" token for negative condition
50257 # total number of tokens in the tokenizer
Important thing to mention — I am doing greedy decoding, so I am generating the most probable tokens. So what does the printed data mean in this case? It means that after applying CFG with the coefficient of 5.0 we got the most probable token that had probability lower than 0.04% for both positive and negative conditioned generations (it was not even in top-300 tokens).
Why does that actually happen? Imagine we have two low-probability tokens (the first from the positive conditioned generation and the second — from negative conditioned), the first one has very low probability P < 1e-5 (as an example of low probability example), however the second one is even lower P → 0. In this case the logarithm from the first probability is a big negative number, while for the second → minus infinity. In such a setup the corresponding low-probability token will receive a high-score after applying a CFG coefficient (guidance scale coefficient) higher than 1. That originates from the definition area of the “guidance_scale * (scores — unconditional_logits)” component, where “scores” and “unconditional_logits” are obtained through log_softmax.
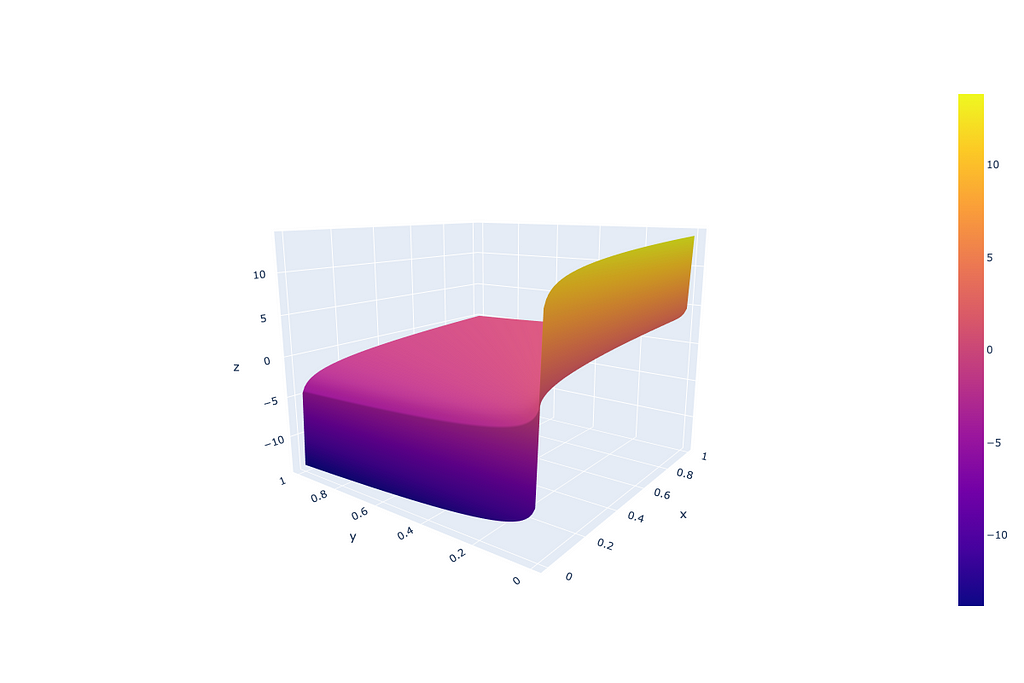
From the image above we can see that such CFG doesn’t treat probabilities equally — very low probabilities can get unexpectedly high scores because of the logarithm component.
In general, how artefacts look depends on the model, tuning, prompts and other, but the nature of the artefacts is a low-probability token getting high scores after applying CFG.
Suggested solution for a CFG formula update for text generation
The solution to the issue can be very simple: as mentioned before, the reason is in the logarithm component, so let’s just remove it. Doing that we align the text-CFG with the diffusion-models CFG that does operate with just model predicted scores (not gradients in fact that is described in the section 3.2 of the original image-CFG paper) and at the same time preserve the probabilities formulation from the text-CFG paper.
The updated implementation requires a tiny changes in “UnbatchedClassifierFreeGuidanceLogitsProcessor” function that can be implemented in the place of the model initialization the following way:
from transformers.generation.logits_process import UnbatchedClassifierFreeGuidanceLogitsProcessor
def modified_call(self, input_ids, scores):
# before it was log_softmax here
scores = torch.nn.functional.softmax(scores, dim=-1)
if self.guidance_scale == 1:
return scores
logits = self.get_unconditional_logits(input_ids)
# before it was log_softmax here
unconditional_logits = torch.nn.functional.softmax(logits[:, -1], dim=-1)
scores_processed = self.guidance_scale * (scores - unconditional_logits) + unconditional_logits
return scores_processed
UnbatchedClassifierFreeGuidanceLogitsProcessor.__call__ = modified_call
New definition area for “guidance_scale * (scores — unconditional_logits)” component, where “scores” and “unconditional_logits” are obtained through just softmax:
To prove that this update works, let’s just repeat the previous experiments with the updated “UnbatchedClassifierFreeGuidanceLogitsProcessor”. The GPT2 model with CFG coefficients of 3.0 and 5.0 returns (I am printing here old and new CFG-powered outputs, because the “Positive” and “Negative” outputs remain the same as before — we have no effect on text generation without CFG):
# Old outputs
## CFG coefficient = 3
CFG-powered output: Extremely polite and friendly answers to the question "How are you doing?" are: 1. Have you ever been to a movie theater? 2. Have you ever been to a concert? 3. Have you ever been to a concert? 4. Have you ever been to a concert? 5. Have you ever been to a concert? 6. Have you ever been to a concert? 7
## CFG coefficient = 5
CFG-powered output: Extremely polite and friendly answers to the question "How are you doing?" are: 1. smile, 2. smile, 3. smile, 4. smile, 5. smile, 6. smile, 7. smile, 8. smile, 9. smile, 10. smile, 11. smile, 12. smile, 13. smile, 14. smile exting.
# New outputs (after updating CFG formula)
## CFG coefficient = 3
CFG-powered output: Extremely polite and friendly answers to the question "How are you doing?" are: 1. "I'm doing great," 2. "I'm doing great," 3. "I'm doing great."
## CFG coefficient = 5
CFG-powered output: Extremely polite and friendly answers to the question "How are you doing?" are: 1. "Good, I'm feeling pretty good." 2. "I'm feeling pretty good." 3. "You're feeling pretty good." 4. "I'm feeling pretty good." 5. "I'm feeling pretty good." 6. "I'm feeling pretty good." 7. "I'm feeling
The same positive changes were noticed during the inference of the custom finetuned Llama3.1-8B-Instruct model I mentioned earlier:
Before (CFG, guidance scale=3):
“Hello! you don’t have personal name. you’re an interface to provide language understanding”
After (CFG, guidance scale=3):
“Hello! I don’t have a personal name, but you can call me Assistant. How can I help you today?”
Separately, I’ve tested the model’s performance on the benchmarks, automatic tests I was using during the NeurIPS 2024 Privacy Challenge and performance was good in both tests (actually the results I reported in the previous post were after applying the updated CFG formula, additional information is in my arXiv paper). The automatic tests, as I mentioned before, were based on the number of personal data phrases generated in the answers and the accuracy on MMLU-Pro dataset evaluated with LLM-Judge.
The performance didn’t deteriorate on the tests while the text quality improved according to the manual tests — no described artefacts were found.
Conclusion
Current classifier-free guidance implementation for text generation with large language models may cause unexpected artefacts and quality degradation. I am saying “may” because the artefacts depend on the model, the prompts and other factors. Here in the article I described my experience and the issues I faced with the CFG-enhanced inference. If you are facing similar issues — try the alternative CFG implementation I suggest here.
Classifier-free guidance for LLMs performance enhancing was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Classifier-free guidance for LLMs performance enhancing
Go Here to Read this Fast! Classifier-free guidance for LLMs performance enhancing