More and more ex-Twitter/X users are seeking new online homes. I kicked the tires on these three nascent services. Here’s what you need to know about them.
The Amazon Fire Max 11 tablet is on sale for just $140, which is a record low price. This early Black Friday deal brings the price down from $230, which is a savings of nearly 40 percent. That’s a whole lot of tablet for not so much money.
This is a fairly recent entry into Amazon’s library of tablets, having just been released last year. The Fire Max 11 boasts a large 11-inch LCD screen, a slim aluminum frame and plenty of smart home controls. Of course, it integrates with Alexa for voice controls. This is the cooler and more refined sibling of the Fire 10 and Fire 8 tablets.
The tablet uses an octa-core MediaTek processor and weighs just over a pound. There’s a fingerprint sensor, support for WiFi 6 and 4GB of RAM. It runs Fire OS 8, which allows for split-screen and picture-in-picture features. This lets users slam some emails while, say, keeping an eye on a YouTube video.
The tablet integrates with a keyboard and stylus, but those cost extra. There are some minor downsides. First of all, this is an ad-supported model that’ll throw advertisements on the lock screen. In my experience, these are surprisingly unobtrusive. I hate ads and barely notice them. This sale is also for the 64GB version. That’s not a whole lot of room but the tablet does come with a microSD reader for up to 1TB of additional storage.
This article originally appeared on Engadget at https://www.engadget.com/deals/amazon-black-friday-deals-include-the-fire-max-11-tablet-for-a-record-low-of-140-150026096.html?src=rss
Data is booming. It comes in vast volumes and variety and this explosion comes with a plethora of job opportunities too. Is it worth switching to a data career now? My honest opinion: absolutely!
It is worth mentioning that this article comes from an Electrical and Electronic Engineer graduate who went all the way and spent almost 8 years in academia learning about the Energy sector (and when I say all the way, I mean from a bachelor degree to a PhD and postdoc). Even though that’s also a high demand career in the job market, I decided to switch to a data engineer path instead.
I constantly come across posts in forums and blogs where people from different disciplines ask about how to switch to a career in data. So this article will take you through my journey, and how an engineering graduate has nothing to worry about the transition to this new field. I’ll go through the market for data jobs, my story, and the skills that engineers have (whether it’s electrical, mechanical, electronic etc.) that equip them well for this fast moving field.
Generative AI image that I got when I wrote my article title in ChatGPT. Impressive, isn’t it?
Necessity for Data Professionals
As technology continues to advance exponentially (IoT devices, AI, web services etc.) so does the amount of data generated every day. The result from this? The need for AI and Data professionals is currently at an all time high and I think it is only going to get higher. It’s currently at a level that the demand for these professionals severely outgrows supply and new job listings are popping out every day.
According to Dice Tech Job Report, positions like Data Engineers and Data Scientists are amongst the fastest growing tech occupations. The reason being that companies have finally come to the realization that, with data, you can unlock unlimited business insights which can reveal their product’s strengths and weaknesses. That is, if analyzed the correct way.
So what does this mean for the future data professionals looking for a job? The following should be true, at least for the next few years:
Unlimited job listings: According to a recent report by LinkedIn, job postings for AI roles have surged by 119% over the past two years. Similarly, data engineering positions have seen a 98% increase. This highlights the urgency of companies to hire these kind of professionals.
High salary potential: When demand exceeds supply, it immediately leads to higher salaries. These are fundamental laws of economics. Data professionals are now in an era where they have multiple options for a job since companies acknowledge the value they bring to their company.
Multiple industry opportunities: Take my case for example. I worked in data for energy, retail and finance sectors. I consider myself data agnostic, since I am now able to choose from opportunities across a relatively wide range of industries.
Future job growth: As mentioned before, the need for these professionals is only going to get higher since data comes in all shapes and sizes and there is a need for people that know how to handle it.
Switching from another Engineering principle to Data
So here comes the million dollar question: How can an Engineer, whether that is mechanical, electronic, electrical, civil etc. switch to a career in data? Great question.
Is it easy? No. Is it worth it? Definitely. There’s no correct answer for this question. However, I can tell you my experiences and you can judge on your own. I can also tell you the similarities I found between my engineering degree and what I’m doing now. So let’s start.
A brief story of how I switched to data engineering:
Years 2020–2022
The year is 2020 and I’m about to finish my PhD. Confused about my options and what I can do after a long 4-year PhD (and with a severe imposter syndrome too), I chose the safe path of academia and a postdoc position at a Research and Development center.
Imposter syndrome is, funny enough, very common to PhD graduates. It is defined as “The persistent inability to believe that one’s success is deserved or has been legitimately achieved as a result of one’s own efforts or skills”. Image Source: DALL-E.
Whilst working there, I realized that I need to get out of academia. I no longer had the strength to read more papers, proposals or, even more so, write journal and conference papers to showcase my work. I did all those — I had enough. I had like 7–8 journal/conference papers that got published from my PhD and I didn’t really like the fact that this is the only way to showcase my work. So, I started looking for a job in the industry.
In 2021, I managed to get a job in energy consulting. And guess what? More reports, more papers and even better, PowerPoint slides! I felt like my engineering days were behind me and that I could literally do nothing useful. After a short stint at that position, I started looking for jobs again. Something with technical challenges and meaning that got my brain working. This is when I started looking for data professions where I could use the skills that I acquired throughout my career. Also, this was the time that I got the most rejections in my life!
Coming from very successful bachelor and PhD degrees, I couldn’t understand why my skills were not suited for a data position. I was applying to data engineer, analyst and scientist positions but all I received was an automated reply like “Unfortunately we can’t move forward with your application”
That’s when I started applying to literally everywhere. So if you are reading this because you can’t make the switch, believe me. I get you.
Years 2022–2023
So, I started applying everywhere to anything that even relates to data. Even to positions that I didn’t have any of the job description skills. That’s where the magic happened.
I got an interview from a company in the retail sector for the position of “Commercial Intelligence Executive”. Do you know what this position is about? No? That’s right, I didn’t either. All I saw in the job description was that it required 3–5 years of experience in Data Science. So I thought, this has something to do with data, so why not. I got the job and started working there. Turns out that “Commercial Intelligence” was a job description that was basically business intelligence for the commercial department. Lucky me, it was spot on. It gave me the opportunity to start experimenting with business intelligence.
Business Intelligence (BI) is defined as “The technical infrastructure that collects, stores and analyzes company data”. Photo by Carlos Muza on Unsplash.
In that position, I used Power BI at first, since the role was about building reports and dashboards. Then, I was hungry for more. I was fortunate that my manager was amazing so he/she trusted me to do whatever I wanted with data. And so I did.
Before I knew it, my engineering skills were back. All the problem solving skills that I got throughout the years, the bug for solving challenges and the exposure to different programming languages started connecting with each other. I started building automations in Power BI, then extended this to writing SQL to automate more things and then building data pipelines using Python. In 1 year’s time, I had all my processes pretty much automated and I knew that I had the technical capability to take on more challenging and technically intensive problems. I built incredible dashboards that brought useful insights to the business owners and that felt incredible.
This was the lightbulb moment. That this career, no matter what the data is about, was what I was looking for.
Years 2023-present
After one and a half years at the company, I knew it was time to go for something more technically challenging than just business intelligence. That’s when an opportunity turned out for me for a data engineer position and I took it.
For the past one and a half years I’ve been working in the finance sector as a data engineer. I expanded my knowledge to more things such as AI, real-time streaming data pipelines, APIs, automations and so much more. Job opportunities are coming up all the time and I feel fortunate that I have made this switch, and I couldn’t recommend it enough. Was it challenging? I’ll say that the only challenging part in both BI and data engineering positions was the first 3 months until I got to know the tools we use and the environments. My engineering expertise equipped me well to deal with different problems with excitement and do amazing things. I wouldn’t change my degree for anything else. Not even for a Computer Science degree. How did my engineering degree help throughout this transition? This is discussed in the next section.
How Engineering equips you with skills that help in a data career
So if you’ve read this far, you must be wondering: How is my engineering degree preparing me for a career in data? This guy has told me nothing about this. You are right, let’s get into it.
Engineering degrees are important, not because of the discipline but the way that they structure the brains of those they study it. This is my personal opinion, but going through my engineering degrees they have exposed me to so many things and have prepared me to solve problems in every single bit that I feel much more confident now. But let’s get to the specifics. These are some key engineering skills that I see similarities and I get to use at my data role every single day:
Programming: As an electrical and electronics engineer, I got exposure to multiple programming languages throughout my degrees. I used assembly language, Java, VHDL, C and Matlab. Likewise, I think other engineering disciplines do the same thing since programming is a way to perform simulations in engineering. Even though I haven’t used Python or SQL during my degrees, it was a seamless transition to these two, after getting exposed to so many things. I would even say enjoyable, since I used to hate coding during my bachelor degree, but now I love it. It probably was a matter of tight deadlines and stress from so many things at the same time.
Problem Solving: I get to solve problems every day but as my first university lecturer said to us at the very first day at the university, “Google is your friend”. If you have a knack for solving problems, and you have been exposed to the way engineering projects are handed out at universities (where they basically give you a one paragraph description for the project and expect a product by the end of the week), believe me you can solve data problems. You have been through enough preparation.
Math and Statistics: Engineering students get through intense mathematics such as linear algebra, calculus, statistics and others that can make you understand machine learning in a smooth transition. It’s a bit difficult to grasp at first because it’s a new territory but you’ll get the hang of it.
Black Box Problems: I don’t even know if this is a formal definition but I consider “Black Box” problems to be the ones that are extremely difficult to solve, we’ve been using them, they work, but not a lot of people actually know what’s happening in the background. In data, the “Black Box Problem” is AI. It’s hot, it works and it’s amazing but no one really knows what’s happening in the background. Similarly, engineering disciplines have their own “Black Box” problems. Sure, AI is difficult but have you tried understanding the power network problem? That’s no walk in the park.
Modelling and Simulations: Every engineer student has been doing modelling and simulations and that’s nothing different from ML models and data models.
Data Processing and Analytics: As an engineer student in my bachelor and PhD degrees I did a lot of data processing, transformation and analytics from oscilloscope files, sensor files and smart devices that had millions of rows of data. These are examples of data pipelines as we call them in the data industry. I didn’t really know at the time though that this was the name for it. When I got to do it in a corporate environment, these skills were transferrable and helped so much.
Automations: Engineers hate repeated procedures. If there’s a way to automate something, they will do it. This is the mindset that a data engineer needs. I carried this mindset to my data engineer position and it helps a lot since I spend a lot of time automating stuff in my day to day.
Presenting and explaining to non-technical people: One very common thing I was doing in my PhD was explaining my project to non-technical people so that they can understand what I’m doing. This happens a lot in data. You prepare a lot of analysis for business people so you have to be able to explain it too.
All the above help me every single day in my data engineer position. Can you see the transferrable skills now?
So, is it a happy ending?
Whilst I don’t want to encourage all the engineering disciplines to jump into a data position, I still think that all engineers are useful, I wanted to write this article to encourage the people that want to do the switch. There’s so much rejection nowadays but at the same time opportunities. All you need is the right opportunity and then magic will follow since you will be able to exploit your skills. The important thing is to keep trying.
Unlike SOTA PEFT methods, which focus on modifying the model weights or input, the ReFT technique is based on a previously proposed distributed interchange intervention (DII) method. The DII method first projects the embedding from the deep learning model to a lower dimension subspace and then interferes through the subspace for fine-tuning purposes.
In the following, we’ll first walk the readers through SOTA fine-tuning PEFT algorithms such as LoRA, prompt tuning, and prefix tuning; then we’ll discuss the original DII method to provide a better context for understanding; lastly, we’ll discuss the ReFT technique and present the results from the paper.
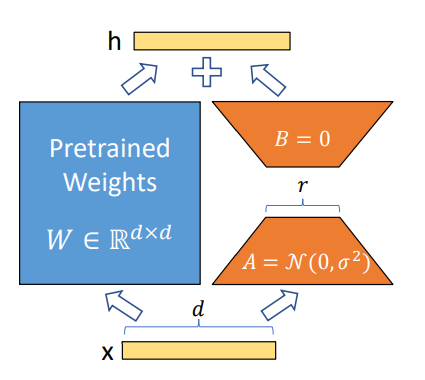
Proposed in 2021, LoRA has become one of the most successful techniques for fine-tuning LLMs and diffusion models (e.g., Time-varying LoRA) due to its simplicity and generalization ability. The idea is simple: instead of fine-tuning the original weight parameters for each layer, the LoRA technique adds two low-rank matrices and only finetunes the low-rank matrices. The trainable parameters could be reduced to less than 0.3% during fine-tuning of the whole network, which significantly speeds up the learning process and minimizes the GPU memory.
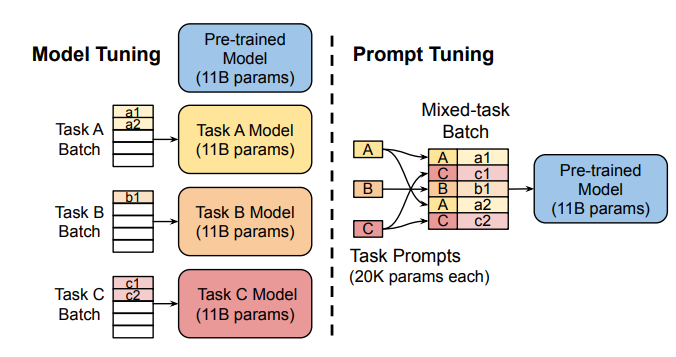
Instead of changing the pre-trained model’s inner layers, the Prompt Tuning technique proposed to use “soft prompts,” a learnable task-specific prompt embedding as a prefix. Given mixed-task batch prompts, the model could efficiently perform multi-task prediction without extra task-specific model copy (as against the Model Tuning in the following left sub-figure).
To provide universality for prompt tuning models at scales (e.g., over 10B parameters), Prefix Tuning (P-Tuning v2) proposed to prefix trainable prompt embeddings at different layers, which allows learning task-specific information at various scales.
Among all these PEFT techniques, LoRA is the most widely used in fine-tuning LLMs for its robustness and efficiency. A detailed empirical analysis can be found in this paper.
Distributed Interchange Intervention (DII)
Causal abstraction is a robust artificial intelligence framework that uses the intervention between a causal model (a high-level model) and a neural network model (or a low-level model) to induce alignment estimation. If there exists an alignment between the two models, we know the underlying mechanisms between the causal model and the NN are the same. The approach of discovering the underlying alignment by intervention is called interchange intervention (II), which is intuitively explained in this lecture video.
However, classical causal abstraction uses brute force to search through all possible alignments of model states, which is less optimal. A Distributed Interchange Intervention (DII) system first projects high-level and low-level models to sub-spaces through a series of orthogonal projections and then produces an intervened model using certain rotation operations. A fascinating intervention experiment on vision models can be found here.
More specifically, the DII could be written as the following:
Where R is a low-rank matrix with orthogonal rows, indicating orthogonal projections; b and s are two different representations encoded by the model from two different inputs; the intervention will happen on the low-rank space, e.g., the space that contains Rs and Rb; the projection matrix R will be further learnt by distributed alignment search (DAS), which optimizes towards “the subspace that would maximize the probability of expected counterfactual output after intervention.”
ReFT — Representation Fintuning
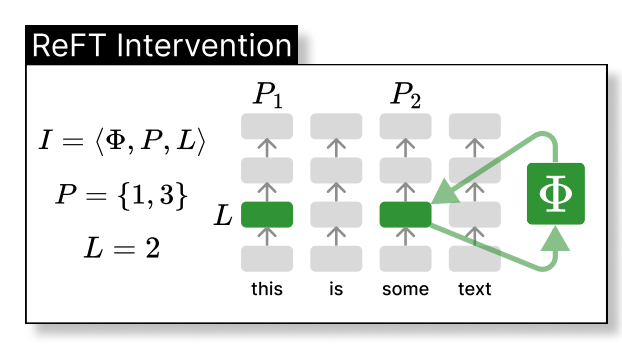
Thus, the ReFT technique could be seen as the intervention of the model’s hidden representation in a lower dimension space, as illustrated below, where phi is the intervention and directly applied to the hidden representation at layer L and position P:
Where h is the hidden representation, (Rs = Wh + b) is the learnt protected source, which edits the representation h in the projected low-dimension space spanned by R. Now, we can illustrate the LoReFT in the original deep neural network layer below.
When fine-tuning on an LLM, the parameters of the LM are kept frozen while only the parameters of the projection phi={R, W, b} are trained.
Experiments
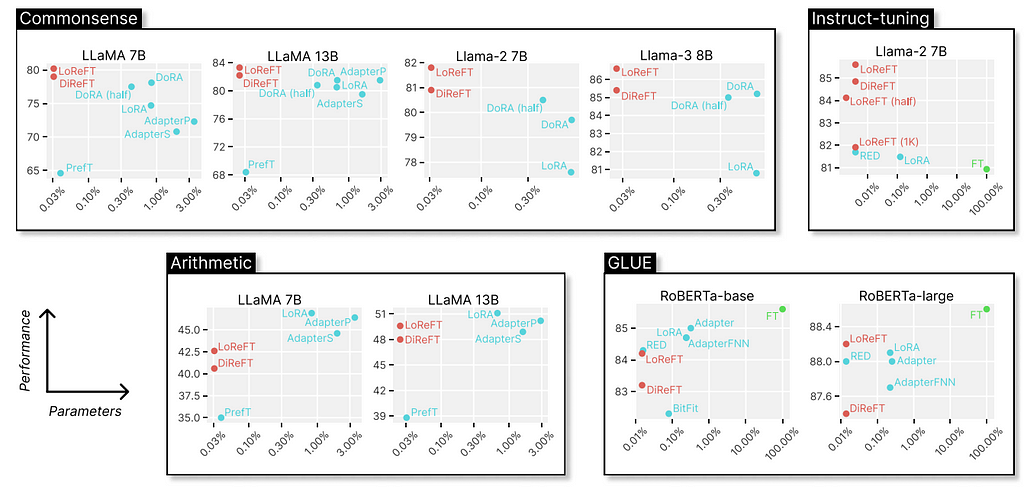
The original paper shows experiments comparing the LoReFT (and other techniques from the ReFT family) to full fine-tuning (FT), LoRA, Prefix-tuning, etc., on four types of benchmarks: common-sense reasoning, arithmetic reasoning, instruction following, and natural language understanding. We can see that, compared to LoRA, the ReFT techniques further reduce the parameters by at least 90% while achieving higher performance by a large margin.
Why is ReFT so fascinating? Firstly, the technique provides convincing results with Llama-family models on various benchmarks outperforming the SOTA fine-tuning methods. Secondly, the technique is deeply rooted in the causal abstraction algorithm, which offers further ground for model interpretation, especially from the hidden representation’s perspective. As mentioned in the original paper, ReFT shows that “a linear subspace distributed across a set of neurons can achieve generalized control over a vast number of tasks,” which might further open doors for helping us better understand large language models.
References
Wu Z, Arora A, Wang Z, Geiger A, Jurafsky D, Manning CD, Potts C. Reft: Representation finetuning for language models. arXiv preprint arXiv:2404.03592. 2024 Apr 4.
Hu EJ, Shen Y, Wallis P, Allen-Zhu Z, Li Y, Wang S, Wang L, Chen W. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685. 2021 Jun 17.
Zhuang Z, Zhang Y, Wang X, Lu J, Wei Y, Zhang Y. Time-Varying LoRA: Towards Effective Cross-Domain Fine-Tuning of Diffusion Models. In The Thirty-eighth Annual Conference on Neural Information Processing Systems 2024.
Liu X, Ji K, Fu Y, Tam WL, Du Z, Yang Z, Tang J. P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks. arXiv preprint arXiv:2110.07602. 2021 Oct 14.
Geiger A, Wu Z, Potts C, Icard T, Goodman N. Finding alignments between interpretable causal variables and distributed neural representations. InCausal Learning and Reasoning 2024 Mar 15 (pp. 160–187). PMLR.
Lester B, Al-Rfou R, Constant N. The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691. 2021 Apr 18.
Pu G, Jain A, Yin J, Kaplan R. Empirical analysis of the strengths and weaknesses of PEFT techniques for LLMs. arXiv preprint arXiv:2304.14999. 2023 Apr 28.
Is ReFT All We Needed? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
XProtect is Apple’s Mac virus detection system which keeps your Mac safe. Here’s how the protective macOS feature works.
XProtect is macOS’s malware scaning tool.
Viruses and other malware are a constant threat to computers, which web surfers have to work around every time they go online.
A computer virus is a small piece of code that gets silently installed onto your computer. One where it runs or embeds itself into other software and causes havoc.
SpaceX has posted some incredible images showing the Super Heavy booster’s Raptor engines as they powered the Starship rocket skyward during Tuesday’s launch.
Yes, Black Friday is basically here and, though we’re not sure where this year went, all the sales are softening the blow. Amazon, sure to be the home of a lot of shopping this year, has already marked down some of its most wanted products. Included in the sales is our choice for best smart speaker under $50, the fifth generation Amazon Echo Dot. Right now, you can pick up the speaker for just $23 — an all-time low price.
The fifth-gen Amazon Echo Dot came out in 2022 and has great features, including exceptionally loud and clear audio for its sticker price (let alone the discounted one). It has all the basics and does them well: letting you set alarm clocks and timers, streaming music and podcasts from your streamer of choice and using Alexa for all your questions.
If you’re unsure about the Echo Dot then check out some of Amazon’s other speakers on sale for Black Friday. There’s the Echo Spot, which is back to its October Prime Day all-time low price of $45, down from $80.
Amazon originally released the Echo Spot in 2017, but discontinued it after two years. The new model launched earlier this year sans awkward bedside camera and plus a better quality display and sound. You can also pick up the Echo Pop for only $18, down from $40. This speaker is a great option if you want a solid device in a small room.
This article originally appeared on Engadget at https://www.engadget.com/deals/amazons-echo-dot-drops-to-only-23-for-black-friday-150042813.html?src=rss
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.