As our homes (and lives) get smarter, the need for some sort of digital hub big enough to run things becomes more urgent. It’s why Amazon surprise-released a new 21-inch version of its Echo Show that does everything the Show 15 did, but biggererer. It gets a built-in smart home hub with Thread, Zigbee and Matter control, Wi-Fi 6E and a better camera for video calls.
I bought an Echo Show 8 on a whim to use as a screen for my Ring doorbell and found it quite underwhelming. But the idea of having a 21-inch screen that could theoretically lay out to-do lists and calendar tasks on the daily is quite appealing. Having two small kids makes being able to marshal all our schedules on one device quite desirable.
This article originally appeared on Engadget at https://www.engadget.com/general/the-morning-after-amazons-got-a-21-inch-echo-show-121502524.html?src=rss
It’s Black Friday, and if you’re in the market for a smartwatch, the Samsung Galaxy Watch 7 is $70 off. That makes it $230, a record low for the device.
Our team tried out the Samsung Galaxy Watch 7 at the Paris Galaxy Unpacked event earlier this year (Samsung’s second Unpacked of the year, to be precise). It’s one of the first smartwatches to receive Wear OS 5, the latest Google wearables operating system. Fun fact, even Google’s products didn’t get it until later.
The Galaxy Watch 7’s features include an improved heart rate tracker, an energy score calculator to determine your physical readiness for the day and suggested responses in messaging, which are powered by Galaxy AI. Galaxy AI will formulate responses based on your past conversations, but the feature only works if you allow it to read them.
Additionally, Samsung’s AI model can gather your sleep habits and provide useful insights. The smartwatch is even powerful enough to detect signs of sleep apnea and severe instances of breathing disruptions.
While we haven’t reviewed the Galaxy Watch 7, we did put the Galaxy Watch 6 through a detailed evaluation. We found it to be comfortable to wear and great for fitness enthusiasts, and it has dedicated health-tracking functions for those who need it. If anything, we take it as a good sign that Samsung has a high standard for its smartwatches.
This article originally appeared on Engadget at https://www.engadget.com/deals/samsungs-galaxy-watch-7-drops-to-230-for-black-friday-120049385.html?src=rss
An open-source initiative to help you deploy generative search based on your local files and self-hosted (Mistral, Llama 3.x) or commercial LLM models (GPT4, GPT4o, etc.)
I have previously written about building your own simple generative search, as well as on the VerifAI project on Towards Data Science. However, there has been a major update worth revisiting. Initially, VerifAI was developed as a biomedical generative search with referenced and AI-verified answers. This version is still available, and we now call it VerifAI BioMed. It can be accessed here: https://app.verifai-project.com/.
The major update, however, is that you can now index your local files and turn them into your own generative search engine (or productivity engine, as some refer to these systems based on GenAI). It can serve also as an enterprise or organizational generative search. We call this version VerifAI Core, as it serves as the foundation for the other version. In this article, we will explore how you can in a few simple steps, deploy it and start using it. Given that it has been written in Python, it can be run on any kind of operating system.
Architecture
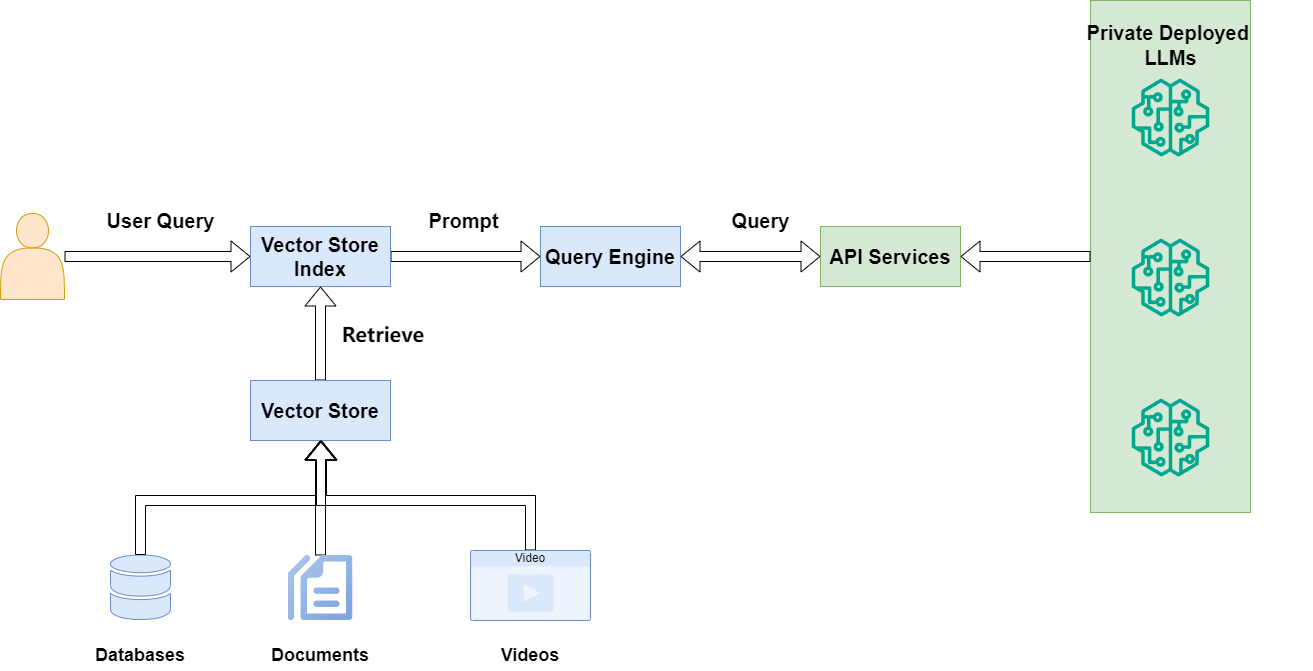
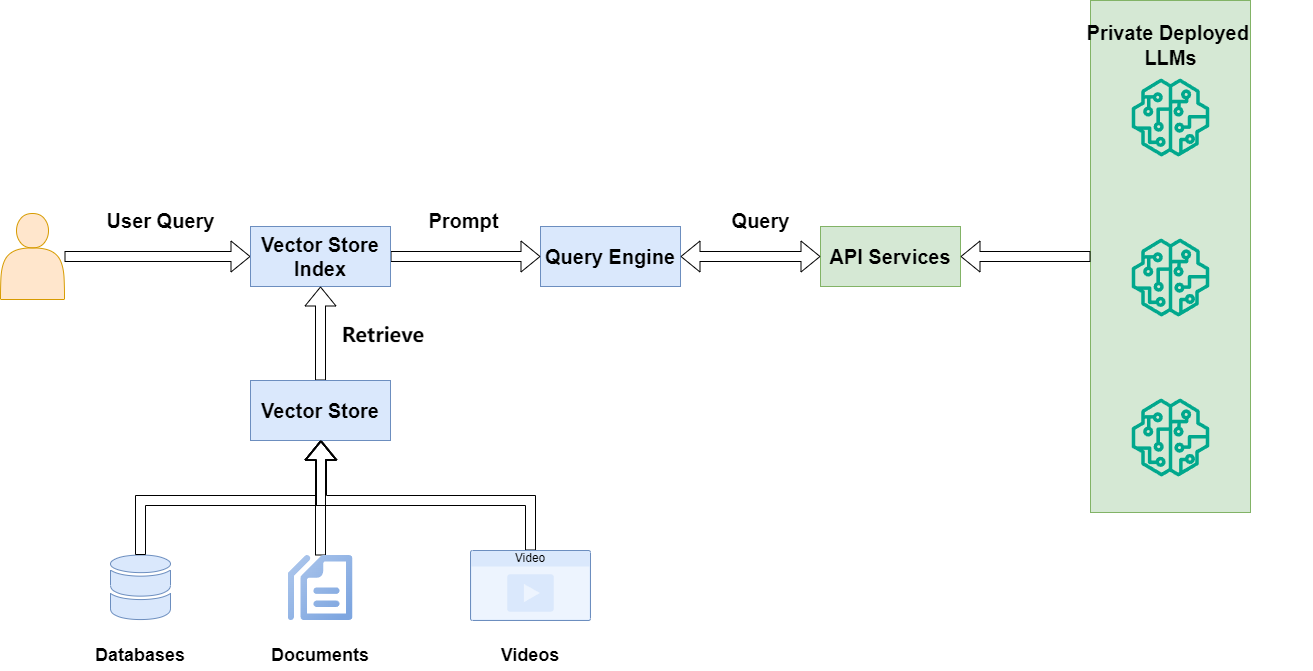
The best way to describe a generative search engine is by breaking it down into three parts (or components, in our case):
Indexing
Retrieval-Augmented Generation (RAG) Method
VerifAI contains an additional component, which is a verification engine, on top of the usual generative search capabilities
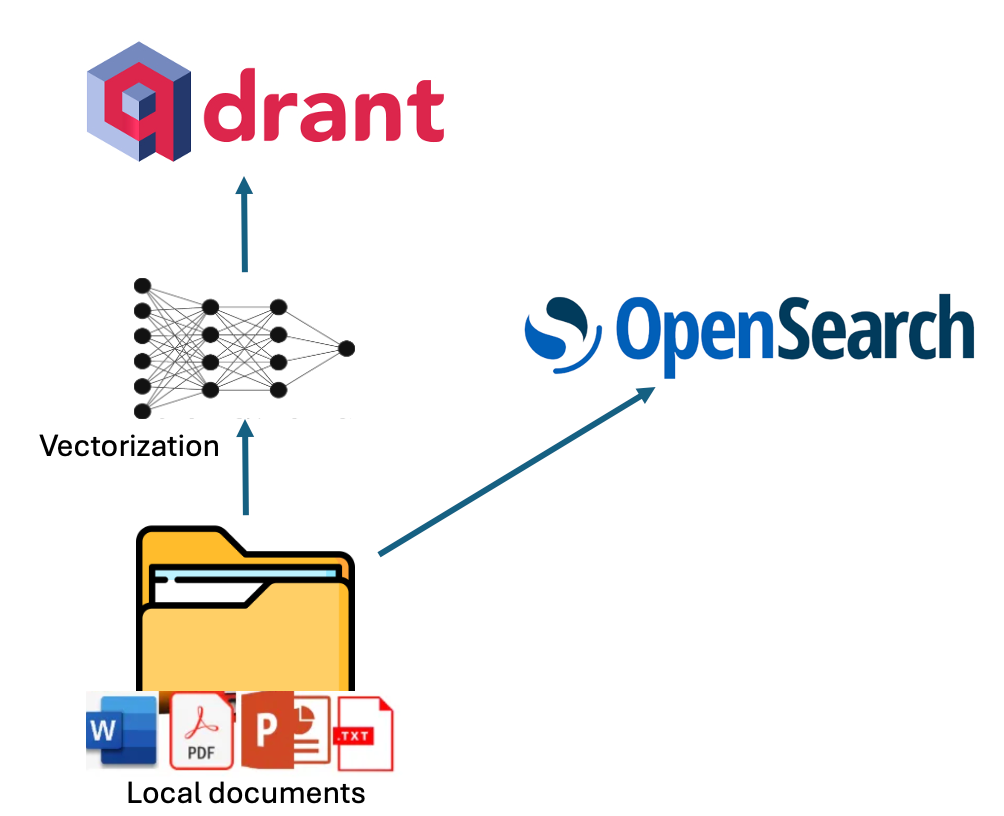
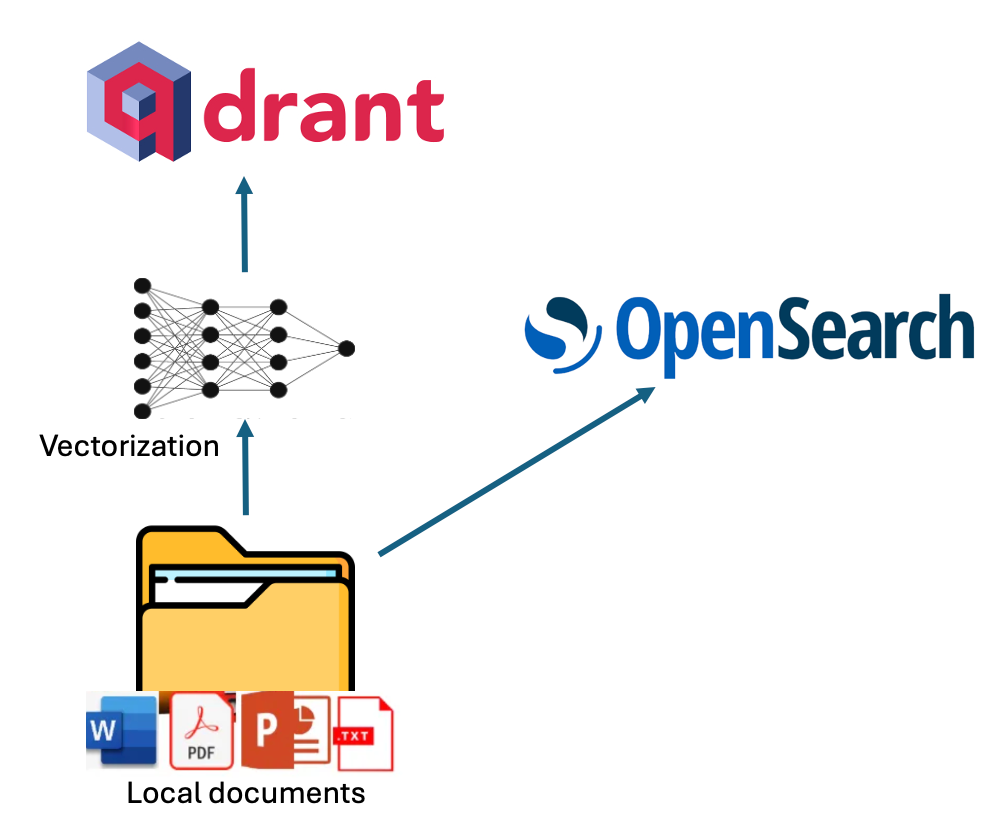
Indexing in VerifAI can be done by pointing its indexer script to a local folder containing files such as PDF, MS Word, PowerPoint, Text, or Markdown (.md). The script reads and indexes these files. Indexing is performed in dual mode, utilizing both lexical and semantic indexing.
For lexical indexing, VerifAI uses OpenSearch. For semantic indexing, it vectorizes chunks of the documents using an embedding model specified in the configuration file (models from Hugging Face are supported) and then stores these vectors in Qdrant. A visual representation of this process is shown in the diagram below.
Architecture of indexing (diagram by author)
When it comes to answering questions using VerifAI, the method is somewhat complex. User questions, written in natural language, undergo preprocessing (e.g., stopwords are excluded) and are then transformed into queries.
For OpenSearch, only lexical processing is performed (e.g., excluding stopwords), and the most relevant documents are retrieved. For Qdrant, the query is transformed into embeddings using the same model that was used to embed document chunks when they were stored in Qdrant. These embeddings are then used to query Qdrant, retrieving the most similar documents based on dot product similarity. The dot product is employed because it accounts for both the angle and magnitude of the vectors.
Finally, the results from the two engines must be merged. This is done by normalizing the retrieval scores from each engine to values between 0 and 1 (achieved by dividing each score by the highest score from its respective engine). Scores corresponding to the same document are then added together and sorted by their combined score in descending order.
Using the retrieved documents, a prompt is built. The prompt contains instructions, the top documents, and the user’s question. This prompt is then passed to the large language model of choice (which can be specified in the configuration file, or, if no model is set, defaults to our locally deployed fine-tuned version of Mistral). Finally, a verification model is applied to ensure there are no hallucinations, and the answer is presented to the user through the GUI. The schematic of this process is shown in the image below.
When installing VerifAI Search, it is recommended to start by creating a clean Python environment. I have tested it with Python 3.6, but it should work with most Python 3 versions. However, Python 3.10+ may encounter compatibility issues with certain dependencies.
To create a Python environment, you can use the venv library as follows:
After activating the environment, you can install the required libraries. The requirements file is located in theverifAI/backenddirectory. You can run the following command to install all the dependencies:
pip install -r requirements.txt
Configuring system
The next step is configuring VerifAI and its interactions with other tools. This can be done either by setting environment variables directly or by using an environment file (the preferred option).
An example of an environment file for VerifAI is provided in the backend folder as .env.local.example. You can rename this file to .env, and the VerifAI backend will automatically read it. The file structure is as follows:
Some of the variables are quite straightforward. The first Secret key and Algorithm are used for communication between the frontend and the backend.
Then there are variables configuring access to the PostgreSQL database. It needs the database name (DBNAME), username, password, and host address where the database is located. In our case, it is on localhost, on the docker image.
The next section is the configuration of OpenSearch access. There is IP (localhost in our case again), username, password, port number (default port is 9200), and variable defining whether to use SSL.
A similar configuration section has Qdrant, just for Qdrant, we use an API key, which has to be here defined.
The next section defined the generative model. VerifAI uses the OpenAI python library, which became the industry standard, and allows it to use both OpenAI API, Azure API, and user deployments via vLLM, OLlama, or Nvidia NIMs. The user needs to define the path to the interface, API key, and model deployment name that will be used. We are soon adding support where users can modify or change the prompt that is used for generation. In case no path to an interface is provided and no key, the model will download the Mistral 7B model, with the QLoRA adapter that we have fine-tuned, and deploy it locally. However, in case you do not have enough GPU RAM, or RAM in general, this may fail, or work terribly slowly.
You can set also MAX_CONTEXT_LENGTH, in this case it is set to 128,000 tokens, as that is context size of GPT4o. The context length variable is used to build context. Generally, it is built by putting in instruction about answering question factually, with references, and then providing retrieved relevant documents and question. However, documents can be large, and exceed context length. If this happens, the documents are splitted in chunks and top n chunks that fit into the context size will be used to context.
The next part contains the HuggingFace name of the model that is used for embeddings of documents in Qdrant. Finally, there are names of indexes both in OpenSearch (INDEX_NAME_LEXICAL) and Qdrant (INDEX_NAME_SEMANTIC).
As we previously said, VerifAI has a component that verifies whether the generated claim is based on the provided and referenced document. However, this can be turned on or off, as for some use-cases this functionality is not needed. One can turn this off by setting USE_VERIFICATION to False.
Installing datastores
The final step of the installation is to run the install_datastores.py file. Before running this file, you need to install Docker and ensure that the Docker daemon is running. As this file reads configuration for setting up the user names, passwords, or API keys for the tools it is installing, it is necessary to first make a configuration file. This is explained in the next section.
This script sets up the necessary components, including OpenSearch, Qdrant, and PostgreSQL, and creates a database in PostgreSQL.
python install_datastores.py
Note that this script installs Qdrant and OpenSearch without SSL certificates, and the following instructions assume SSL is not required. If you need SSL for a production environment, you will need to configure it manually.
Also, note that we are talking about local installation on docker here. If you already have Qdrant and OpenSearch deployed, you can simply update the configuration file to point to those instances.
Indexing files
This configuration is used by both the indexing method and the backend service. Therefore, it must be completed before indexing. Once the configuration is set up, you can run the indexing process by pointing index_files.py to the folder containing the files to be indexed:
We have included a folder called test_data in the repository, which contains several test files (primarily my papers and other past writings). You can replace these files with your own and run the following:
python index_files.py test_data
This would run indexing over all files in that folder and its subfolders. Once finished, one can run VerifAI services for backend and frontend.
Running the generative search
The backend of VerifAI can be run simply by running:
python main.py
This will start the FastAPI service that would act as a backend, and pass requests to OpenSearch, and Qdrant to retrieve relevant files for given queries and to the deployment of LLM for generating answers, as well as utilize the local model for claim verification.
Frontend is a folder called client-gui/verifai-ui and is written in React.js, and therefore would need a local installation of Node.js, and npm. Then you can simply install dependencies by running npm install and run the front end by running npm start:
cd .. cd client-gui/verifai-ui npm install npm start
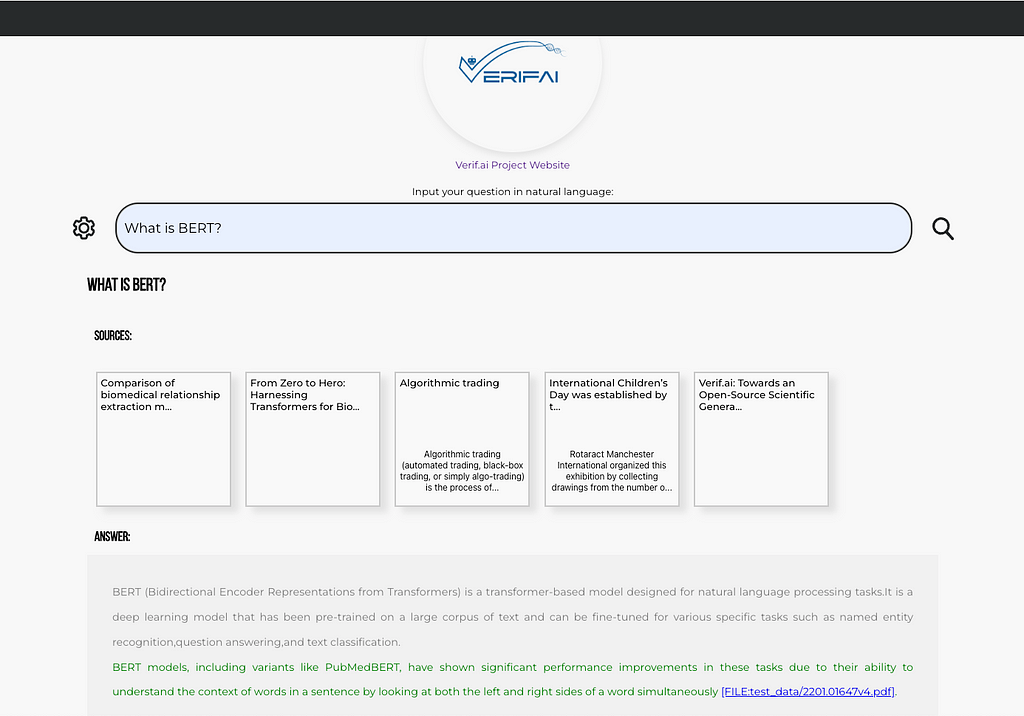
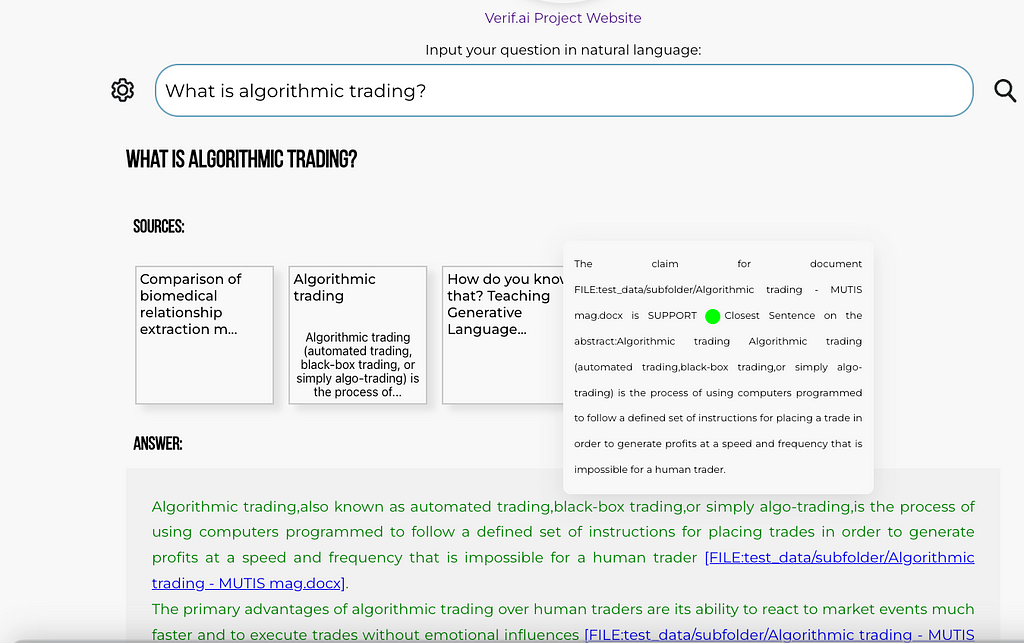
Finally, things should look somehow like this:
One of the example questions, with verification turned on (note text in green) and reference to the file, which can be downloaded (screenshot by author)Screenshot showcasing tooltip of the verified claim, with the most similar sentence from the article presented (screenshot by author)
Contributing and future direction
So far, VerifAI has been started with the help of funding from the Next Generation Internet Search project as a subgrant of the European Union. It was started as a collaboration between The Institute for Artificial Intelligence Research and Development of Serbia and Bayer A.G.. The first version has been developed as a generative search engine for biomedicine. This product will continue to run at https://app.verifai-project.com/. However, lately, we decided to expand the project, so it can truly become an open-source generative search with verifiable answers for any files, that can be leveraged openly by different enterprises, small and medium companies, non-governmental organizations, or governments. These modifications have been developed by Natasa Radmilovic and me voluntarily (huge shout out to Natasa!).
However, given this is an open-source project, available on GitHub (https://github.com/nikolamilosevic86/verifAI), we are welcoming contributions by anyone, via pull requests, bug reports, feature requests, discussions, or anything else you can contribute with (feel free to get in touch — for both BioMed and Core (document generative search, as described here) versions website will remain the same — https://verifai-project.com). So we welcome you to contribute, start our project, and follow us in the future.
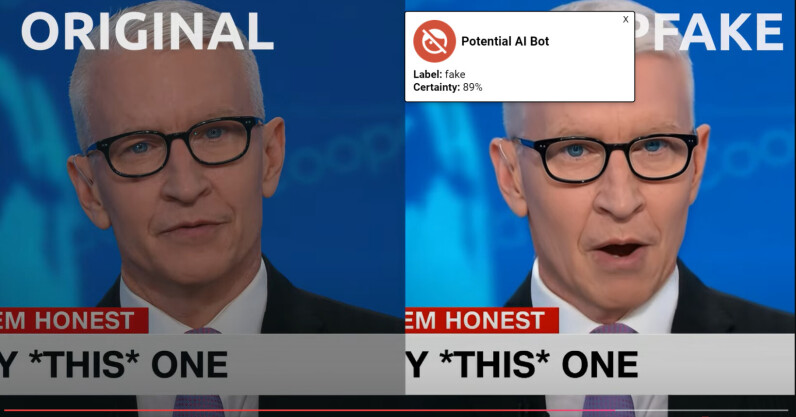
UK startup Surf Security has launched a beta version of what it claims is the world’s first browser with a built-in feature designed to spot AI-generated deepfakes. The tool, available through Surf’s browser or as an extension, can detect with up to 98% accuracy whether the person you’re interacting with online is a real human or an AI imitation, the company said. The London-based cybersecurity upstart uses “military-grade” neural network technology to detect deepfakes. The system uses State Space Models, which detect AI-generated clones across languages and accents by analysing audio frames for inconsistencies. “To maximise its effectiveness, we focused…
Apple has argued in court that the Department of Justice’s case against it is baseless, while the DOJ says prove it at trial.
The Department of Justice case will hang over Apple for years
As expected, Apple made its case to US District Judge Julien Neals in Newark, New Jersey, on Wednesday, November 21, 2024. Its lawyers are seeking a dismissal of the antitrust accusations that it has consistently decried since the Department of Justice (DOJ) brought it in March 2024.
Now according to Bloomberg, both sides have presented their argument over whether the case should continue. Apple attorney Devora Allon said:
Amazon’s official Black Friday Deals Week event starts now and we have live coverage of today’s best Apple deals, including new low prices on M4 Macs, the 2024 iPad mini 7, current Apple Watch models and more.
Amazon’s Black Friday deals on Apple start now.
Black Friday is happening now at both Amazon and Best Buy, and we’re monitoring the Apple space closely so you can save the most money on your holiday shopping. From M4 MacBook and Mac mini discounts to the cheapest Apple Watch Series 10 prices we’ve seen this season, there are a number of bargains worth considering when choosing gifts for loved ones.
If you want the Apple Studio Display, you should consider getting it now, as it’s currently available at a massive $300 discount.
Save $300 on the Apple Studio Display
The Apple Studio Display offers consumers an Apple-designed screen for their Mac, without necessarily paying the high price of the Pro Display XDR. If you’re quick, that price can be even less.
Nearly half of Gen AI adopters want it open source – here’s why
Originally appeared here:
Nearly half of Gen AI adopters want it open source – here’s why
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.