Nintendo Black Friday deals are now live, and they’re worth paying attention to if you want to pick up some big games on sale. In addition to video games, you can pick up a few Nintendo Switch bundles on sale as well, including options for the standard Switch, the OLED model and the Switch Lite. The deals are available at retailers like Best Buy and Target, and of course, direct from Nintendo.
Perhaps the jewel in Black Friday’s crown is a big discount on The Legend of Zelda: Tears of the Kingdom. Normally $70, Nintendo has the game for $50, but we’re seeing even steeper price drops at GameStop ($45), Target ($40) and Best Buy ($40) at the moment. The game is an absolute blast and builds on all of the good stuff originally introduced in Breath of the Wild. This time, however, new abilities allow for even more unique solutions to puzzles.
There are a few deals on an actual Switch console bundles, too. The Nintendo Switch Lite: Hyrule Edition has dropped to $210, but it comes with some serious perks. This bundle ships with the gold-colored console and a full year of Nintendo Switch Online + Expansion Pack. This provides access to all kinds of retro games, from the NES all the way to the N64. Elsewhere at Target and Best Buy, a bundle with the Nintendo Switch OLED edition and Mario Kart 8 Deluxe is down to $275. The standard Switch is also on sale bundled with the same game for $225.
There’s a caveat here. The Nintendo Switch isn’t long for this world, as a sequel is imminent. Adults may want to wait for the new console, but a Switch Lite is still a great gift for a kid. However, nobody has any idea what Trump’s promised tariffs will do to console prices, so maybe even the Switch Lite will cost $600 next year. Who the heck knows anymore.
This article originally appeared on Engadget at https://www.engadget.com/deals/nintendo-black-friday-deals-are-live-get-the-legend-of-zelda-tears-of-the-kingdom-for-a-record-low-price-194609876.html?src=rss
Black Friday doesn’t just mean discounts on “stuff,” it also means big price cuts on services — and VPNs are no exception. ExpressVPN, a mainstay on our list of best VPNs, is currently offering an attractive discount for all new customers: Up to 61 percent off. US-based customers can choose between two plans with huge discounts over ExpressVPN’s standard rate. The “1-year plan” (actually 16 months) costs $6.25 per month, billed at a total of $100, and the 2-year plan (actually 30 months) costs just $4.99 per month, billed at a total of $150. Those rates compare to a default price of $12.95 per month.
Engadget deemed ExpressVPN the best for streaming services, frequent travel and gaming. Its biggest drawback is generally considered to be the price — higher than most rivals in the space — so this is a great time to get it at a discount. (There’s a 7-day trial period and a 30-day money back guarantee, so you can make sure it meets your needs before committing.) And since we conducted our review, ExpressVPN has added some additional features making it more of a full-service suite, including a password manager and ad blocker. More recently, it’s added ID alerts (with a $1 million identity theft insurance package), as well as a data removal service (to counteract the preponderance of online data brokers).
Some notable caveats: The data removal service is only available on the 30-month plan, and the ID alerts, insurance and data removal features are only applicable to subscribers in the US. Furthermore, these discounts are applicable only to new ExpressVPN customers. And the service will automatically renew at the standard rate after the initial discount period expires.
It goes without saying that ExpressVPN is compatible with nearly all major operating systems, with support for connecting 8 devices at a time. And its no-logs policy means your online activity is as anonymous as can be. If you’re looking for a dependable VPN that now has a bevy of additional privacy features, ExpressVPN is worth checking out. But don’t delay: This offer is only good through December 6.
This article originally appeared on Engadget at https://www.engadget.com/deals/expressvpns-black-friday-deal-saves-you-up-to-61-percent-120441528.html?src=rss
It’s hard to beat the promise of a big box for one-stop shopping. Target is one of my favorites if I just want to browse with no agenda, because I’ll inevitably stumble on something fun or on sale. Or in the case of this Black Friday deal, both. Target is currently selling a Meta Quest 3S for $300, as is Amazon. That’s the usual price tag for this virtual reality headset, but both retailers include a $75 gift card along with the tech (On Amazon, use the code QUEST75 to get it.) That covers a lot of impulse buys.
There’s a lot to recommend the Meta Quest 3S for a virtual reality fan. In fact, it’s our pick for the best budget VR set. Even if you’re investing in a lower-range VR headset, you’ll want to have plenty of software to run on it. The Quest 3S has a large app library and it can be used to stream games from a PC. While some headsets can be unpleasant to wear for very long, reviewer Devindra Hardawar found that wasn’t an issue with the Quest 3S. And although it has made some sacrifices on the screen and lenses to keep the costs down, this set still delivers a strong, immersive virtual reality experience.
The content included with any Quest headset purchase will help you get started in VR. Batman: Arkham Shadow is one of the most notable exclusive games for Meta’s Quest 3 and Quest 3S, continuing the lineage of the Arkham game universe initially developed by Rocksteady Studios. You’ll also get three months’ subscription to the Meta Quest+ catalog of games. Keeping the subscription after the trial period will cost $8 a month. Or use that gift card and pick up a title to keep.
This article originally appeared on Engadget at https://www.engadget.com/deals/this-black-friday-meta-quest-deal-includes-a-free-75-gift-card-when-you-buy-the-quest-3s-115856500.html?src=rss
LLMs alone suffer from not being able to access external or real-time data. Learn how to build your personal assistant using LangChain agents and Gemini by grounding it in external sources.
Summary:
The problem with LLMs
What are Agents, Tools and Chains ?
Creating a simple chat without Tools
Adding Tools to our chat: The Google way with Function Calling
Adding Tools to our chat : The Langchain way with Agents
Adding Memory to our Agent
Creating a Chain with a Human Validation step
Using search tools
1. The problem with LLMs
So you have your favorite chatbot, and you use it for your daily job to boost your productivity. It can translate text, write nice emails, tell jokes, etc. And then comes the day when your colleague comes to you and asks :
“Do you know the current exchange rate between USD and EUR ? I wonder if I should sell my EUR…”
You ask your favorite chatbot, and the answer pops :
I am sorry, I cannot fulfill this request. I do not have access to real-time information, including financial data like exchange rates.
What is the problem here ?
The problem is that you have stumbled on one of the shortcomings of LLMs. Large Language Models (LLMs) are powerful at solving many types of problems, such as problem solving, text summarization, generation, etc.
However, they are constrained by the following limitations:
They are frozen after training, leading to stale knowledge.
They can’t query or modify external data.
Same way as we are using search engines every day, reading books and documents or querying databases, we would ideally want to provide this knowledge to our LLM to make it more efficient.
Fortunately, there is a way to do that: Tools and Agents.
Foundational models, despite their impressive text and image generation, remain constrained by their inability to interact with the outside world. Tools bridge this gap, empowering agents to interact with external data and services while unlocking a wider range of actions beyond that of the underlying model alone
(source : Google Agents whitepaper)
Using agents and tools, we could then be able to, from our chat interface:
retrieve data from our own documents
read / send emails
interact with internal databases
perform real time Google searches
etc.
2. What are Agents, Tools and Chains ?
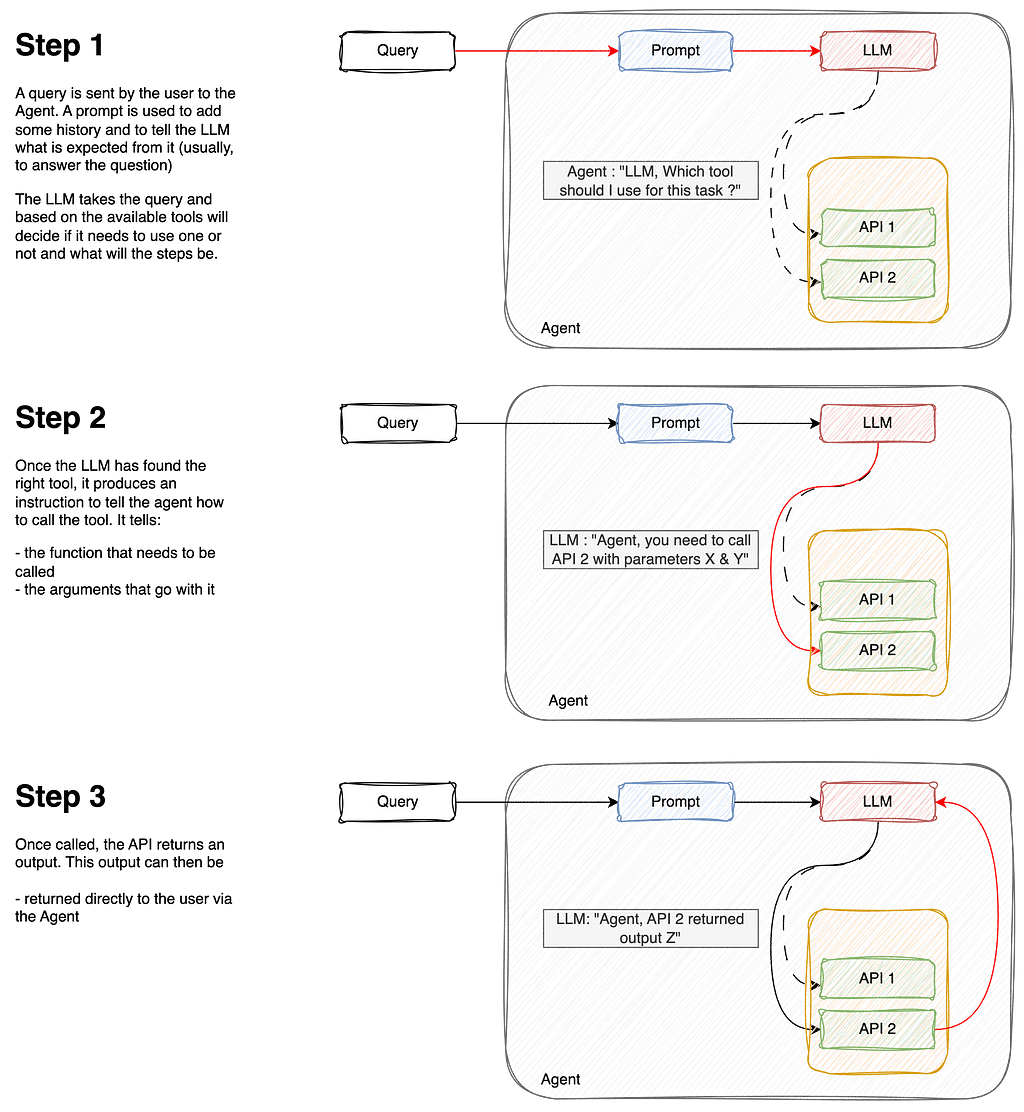
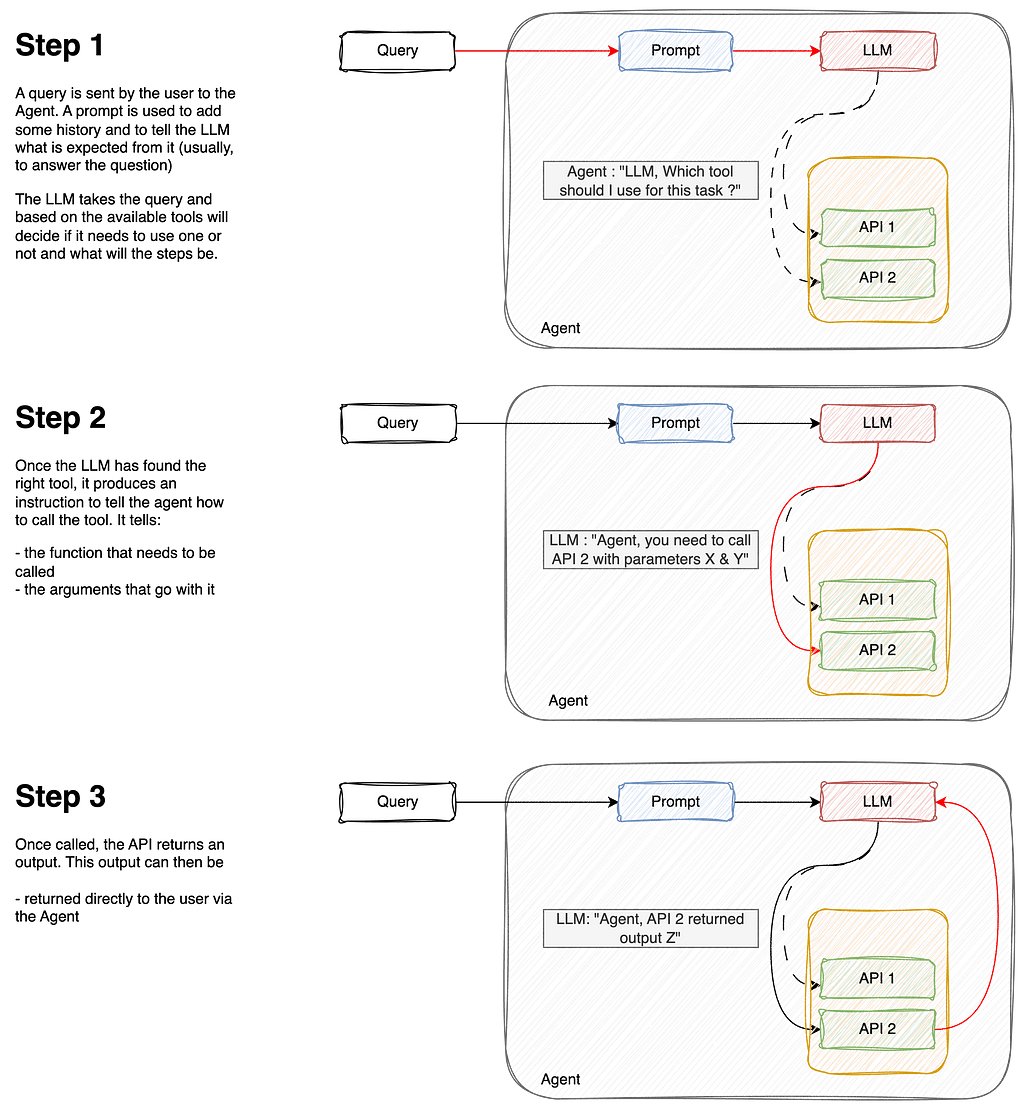
An agent is an application which attempts to achieve a goal (or a task) by having at its disposal a set of tools and taking decisions based on its observations of the environment.
A good example of an agent could be you, for example: if you need to compute a complex mathematical operation (goal), you could use a calculator (tool #1), or a programming language (tool #2). Maybe you would choose the calculator to do a simple addition, but choose tool #2 for more complex algorithms.
Agents are therefore made of :
A model : The brain in our agent is the LLM. It will understand the query (the goal), and browse through its tools available to select the best.
One or more tools : These are functions, or APIs, that are responsible for performing a specific action (ie: retrieving the current currency rate for USD vs EUR, adding numbers, etc.)
An orchestration process: this is how the model will behave when asked to solve a task. It is a cognitive process that defines how the model will analyze the problem, refine inputs, choose a tool, etc. Examples of such processes are ReAct, CoT (Chain of Thought), ToT (Tree-of-Thought)
Here is below a workflow explanation
image by author
Chains are somehow different. Whereas agents can ‘decide’ by themselves what to do and which steps to take, chains are just a sequence of predefined steps. They can still rely on tools though, meaning that they can include a step in which they need to select from available tools. We’ll cover that later.
3. Creating a simple chat without Tools
To illustrate our point, we will first of all see how our LLM performs as-is, without any help.
If you run this simple chat and ask a question about the current exchange rate, you might probably get a similar answer:
response = chat.send_message("What is the current exchange rate for USD vs EUR ?") answer = response.candidates[0].content.parts[0].text
--- OUTPUT --- "I am sorry, I cannot fulfill this request. I do not have access to real-time information, including financial data like exchange rates."
Not surprising, as we know LLMs do not have access to real-time data.
Let’s add a tool for that. Our tool will be little function that calls an API to retrieve exchange rate data in real time.
# Try it out ! get_exchange_rate_from_api({'currency_from': 'USD', 'currency_to': 'EUR'}) --- '{"amount":1.0,"base":"USD","date":"2024-11-20","rates":{"EUR":0.94679}}'
Now we know how our tools works, we would like to tell our chat LLM to use this function to answer our question. We will therefore create a mono-tool agent. To do that, we have several options which I will list here:
Use Google’s Gemini chat API with Function Calling
Use LangChain’s API with Agents and Tools
Both have their advantages and drawbacks. The purpose of this article is also to show you the possibilities and let you decide which one you prefer.
4. Adding Tools to our chat: The Google way with Function Calling
There are basically two ways of creating a tool out of a function.
The 1st one is a “dictionary” approach where you specify inputs and description of the function in the Tool. The imporant parameters are:
Name of the function (be explicit)
Description : be verbose here, as a solid and exhaustive description will help the LLM select the right tool
Parameters : this is where you specify your arguments (type and description). Again, be verbose in the description of your arguments to help the LLM know how to pass value to your function
import requests
from vertexai.generative_models import FunctionDeclaration
get_exchange_rate_func = FunctionDeclaration( name="get_exchange_rate", description="Get the exchange rate for currencies between countries", parameters={ "type": "object", "properties": { "currency_from": { "type": "string", "description": "The currency to convert from in ISO 4217 format" }, "currency_to": { "type": "string", "description": "The currency to convert to in ISO 4217 format" } }, "required": [ "currency_from", "currency_to", ] }, )
The 2nd way of adding a tool using Google’s SDK is with a from_func instantiation. This requires editing our original function to be more explicit, with a docstring, etc. Instead of being verbose in the Tool creation, we are being verbose in the function creation.
# Edit our function def get_exchange_rate_from_api(currency_from: str, currency_to: str): """ Get the exchange rate for currencies
Args: currency_from (str): The currency to convert from in ISO 4217 format currency_to (str): The currency to convert to in ISO 4217 format """ url = f"https://api.frankfurter.app/latest?from={currency_from}&to={currency_to}" api_response = requests.get(url) return api_response.text
# Create the tool get_exchange_rate_func = FunctionDeclaration.from_func( get_exchange_rate_from_api )
The next step is really about creating the tool. For that, we will add our FunctionDeclaration to a list to create our Tool object:
from vertexai.generative_models import Tool as VertexTool
tool = VertexTool( function_declarations=[ get_exchange_rate_func, # add more functions here ! ] )
Let’s now pass that to our chat and see if it now can answer our query about exchange rates ! Remember, without tools, our chat answered:
Let’s try Google’s Function calling tool and see if this helps ! First, let’s send our query to the chat:
from vertexai.generative_models import GenerativeModel
gemini_model = GenerativeModel( "gemini-1.5-flash", generation_config=GenerationConfig(temperature=0), tools=[tool] #We add the tool here ! ) chat = gemini_model.start_chat()
response = chat.send_message(prompt)
# Extract the function call response response.candidates[0].content.parts[0].function_call
The LLM correctly guessed it needed to use the get_exchange_rate function, and also correctly guessed the 2 parameters were USD and EUR .
But this is not enough. What we want now is to actually run this function to get our results!
# mapping dictionnary to map function names and function function_handler = { "get_exchange_rate": get_exchange_rate_from_api, }
# Extract the function call name function_name = function_call.name print("#### Predicted function name") print(function_name, "n")
# Extract the function call parameters params = {key: value for key, value in function_call.args.items()} print("#### Predicted function parameters") print(params, "n")
function_api_response = function_handler[function_name](params) print("#### API response") print(function_api_response) response = chat.send_message( Part.from_function_response( name=function_name, response={"content": function_api_response}, ), ) print("n#### Final Answer") print(response.candidates[0].content.parts[0].text)
--- OUTPUT --- """ #### Predicted function name get_exchange_rate
#### Predicted function parameters {'currency_from': 'USD', 'currency_date': 'latest', 'currency_to': 'EUR'}
#### API response {"amount":1.0,"base":"USD","date":"2024-11-20","rates":{"EUR":0.94679}}
#### Final Answer The current exchange rate for USD vs EUR is 0.94679. This means that 1 USD is equal to 0.94679 EUR. """
We can now see our chat is able to answer our question! It:
Correctly guessed to function to call, get_exchange_rate
Correctly assigned the parameters to call the function {‘currency_from’: ‘USD’, ‘currency_to’: ‘EUR’}
Got results from the API
And nicely formatted the answer to be human-readable!
Let’s now see another way of doing with LangChain.
5. Adding Tools to our chat: The Langchain way with Agents
LangChain is a composable framework to build with LLMs. It is the orchestration framework for controllable agentic workflows.
Similar to what we did before the “Google” way, we will build tools in the Langchain way. Let’s begin with defining our functions. Same as for Google, we need to be exhaustive and verbose in the docstrings:
In order to spice things up, I will add another tool which can list tables in a BigQuery dataset. Here is the code:
@tool def list_tables(project: str, dataset_id: str) -> list: """ Return a list of Bigquery tables Args: project: GCP project id dataset_id: ID of the dataset """ client = bigquery.Client(project=project) try: response = client.list_tables(dataset_id) return [table.table_id for table in response] except Exception as e: return f"The dataset {params['dataset_id']} is not found in the {params['project']} project, please specify the dataset and project"
Add once done, we add our functions to our LangChain toolbox !
To build our agent, we will use the AgentExecutorobject from LangChain. This object will basically take 3 components, which are the ones we defined earlier :
Then we create a prompt to manage the conversation:
prompt = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful assistant"), ("human", "{input}"), # Placeholders fill up a **list** of messages ("placeholder", "{agent_scratchpad}"), ] )
And finally, we create the AgentExecutor and run a query:
agent = create_tool_calling_agent(gemini_llm, langchain_tools, prompt) agent_executor = AgentExecutor(agent=agent, tools=langchain_tools) agent_executor.invoke({ "input": "Which tables are available in the thelook_ecommerce dataset ?" })
--- OUTPUT --- """ {'input': 'Which tables are available in the thelook_ecommerce dataset ?', 'output': 'The dataset `thelook_ecommerce` is not found in the `gcp-project-id` project. Please specify the correct dataset and project. n'} """
Hmmm. Seems like the agent is missing one argument, or at least asking for more information…Let’s reply by giving this information:
agent_executor.invoke({"input": f"Project id is bigquery-public-data"})
--- OUPTUT --- """ {'input': 'Project id is bigquery-public-data', 'output': 'OK. What else can I do for you? n'} """
Well, seems we’re back to square one. The LLM has been told the project id but forgot about the question. Our agent seems to be lacking memory to remember previous questions and answers. Maybe we should think of…
6. Adding Memory to our Agent
Memory is another concept in Agents, which basically helps the system to remember the conversation history and avoid endless loops like above. Think of memory as being a notepad where the LLM keeps track of previous questions and answers to build context around the conversation.
We will modify our prompt (instructions) to the model to include memory:
from langchain_core.chat_history import InMemoryChatMessageHistory from langchain_core.runnables.history import RunnableWithMessageHistory
# Different types of memory can be found in Langchain memory = InMemoryChatMessageHistory(session_id="foo")
prompt = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful assistant."), # First put the history ("placeholder", "{chat_history}"), # Then the new input ("human", "{input}"), # Finally the scratchpad ("placeholder", "{agent_scratchpad}"), ] )
# We add the memory part and the chat history agent_with_chat_history = RunnableWithMessageHistory( agent_executor, lambda session_id: memory, #<-- NEW input_messages_key="input", history_messages_key="chat_history", #<-- NEW )
config = {"configurable": {"session_id": "foo"}}
We will now rerun our query from the beginning:
agent_with_chat_history.invoke({ "input": "Which tables are available in the thelook_ecommerce dataset ?" }, config )
--- OUTPUT --- """ {'input': 'Which tables are available in the thelook_ecommerce dataset ?', 'chat_history': [], 'output': 'The dataset `thelook_ecommerce` is not found in the `gcp-project-id` project. Please specify the correct dataset and project. n'} """
With an empty chat history, the model still asks for the project id. Pretty consistent with what we had before with a memoryless agent. Let’s reply to the agent and add the missing information:
reply = "Project id is bigquery-public-data" agent_with_chat_history.invoke({"input": reply}, config)
--- OUTPUT --- """ {'input': 'Project id is bigquery-public-data', 'chat_history': [HumanMessage(content='Which tables are available in the thelook_ecommerce dataset ?'), AIMessage(content='The dataset `thelook_ecommerce` is not found in the `gcp-project-id` project. Please specify the correct dataset and project. n')], 'output': 'The following tables are available in the `thelook_ecommerce` dataset:n- distribution_centersn- eventsn- inventory_itemsn- order_itemsn- ordersn- productsn- users n'} """
Notice how, in the output:
The `chat history` keeps track of the previous Q&A
The output now returns the list of the tables!
'output': 'The following tables are available in the `thelook_ecommerce` dataset:n- distribution_centersn- eventsn- inventory_itemsn- order_itemsn- ordersn- productsn- users n'}
In some use cases however, certain actions might require special attention because of their nature (ie deleting an entry in a database, editing information, sending an email, etc.). Full automation without control might leads to situations where the agent takes wrong decisions and creates damage.
One way to secure our workflows is to add a human-in-the-loop step.
7. Creating a Chain with a Human Validation step
A chain is somehow different from an agent. Whereas the agent can decide to use or not to use tools, a chain is more static. It is a sequence of steps, for which we can still include a step where the LLM will choose from a set of tools.
To build chains in LangChain, we use LCEL. LangChain Expression Language, or LCEL, is a declarative way to easily compose chains together. Chains in LangChain use the pipe `|` operator to indicate the orders in which steps have to be executed, such as step 1 | step 2 | step 3 etc. The difference with Agents is that Chains will always follow those steps, whereas Agents can “decide” by themselves and are autonomous in their decision-making process.
In our case, we will proceed as follows to build a simple prompt | llm chain.
# define the prompt with memory prompt = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful assistant."), # First put the history ("placeholder", "{chat_history}"), # Then the new input ("human", "{input}"), # Finally the scratchpad ("placeholder", "{agent_scratchpad}"), ] )
# bind the tools to the LLM gemini_with_tools = gemini_llm.bind_tools(langchain_tool)
# build the chain chain = prompt | gemini_with_tools
Remember how in the previous step we passed an agent to our `RunnableWithMessageHistory`? Well, we will do the same here, but…
Unlike the agent, a chain does not provide the answer unless we tell it to. In our case, it stopped at the step where the LLM returns the function that needs to be called.
We need to add an extra step to actually call the tool. Let’s add another function to call the tools:
from langchain_core.messages import AIMessage
def call_tools(msg: AIMessage) -> list[dict]: """Simple sequential tool calling helper.""" tool_map = {tool.name: tool for tool in langchain_tool} tool_calls = msg.tool_calls.copy() for tool_call in tool_calls: tool_call["output"] = tool_map[tool_call["name"]].invoke(tool_call["args"]) return tool_calls
chain = prompt | gemini_with_tools | call_tools #<-- Extra step
Now we understood how to chain steps, let’s add our human-in-the-loop step ! We want this step to check that the LLM has understood our requests and will make the right call to an API. If the LLM has misunderstood the request or will use the function incorrectly, we can decide to interrupt the process.
def human_approval(msg: AIMessage) -> AIMessage: """Responsible for passing through its input or raising an exception.
Args: msg: output from the chat model
Returns: msg: original output from the msg """ for tool_call in msg.tool_calls: print(f"I want to use function [{tool_call.get('name')}] with the following parameters :") for k,v in tool_call.get('args').items(): print(" {} = {}".format(k, v))
print("") input_msg = ( f"Do you approve (Y|y)?nn" ">>>" ) resp = input(input_msg) if resp.lower() not in ("yes", "y"): raise NotApproved(f"Tool invocations not approved:nn{tool_strs}") return msg
Next, add this step to the chain before the function call:
chain_with_history.invoke({"input": "What is the current CHF EUR exchange rate ?"}, config)
You will then be asked to confirm that the LLM understood correctly:
This human-in-the-loop step can be very helpful for critical workflows where a misinterpretation from the LLM could have dramatic consequences.
8. Using search tools
One of the most convenient tools to retrieve information in real-time are search engines . One way to do that is to use GoogleSerperAPIWrapper (you will need to register to get an API key in order to use it), which provides a nice interface to query Google Search and get results quickly.
Luckily, LangChain already provides a tool for you, so we won’t have to write the function ourselves.
Let’s therefore try to ask a question on yesterday’s event (Nov 20th) and see if our agent can answer. Our question is about Rafael Nadal’s last official game (which he lost to van de Zandschulp).
agent_with_chat_history.invoke( {"input": "What was the result of Rafael Nadal's latest game ?"}, config)
--- OUTPUT --- """ {'input': "What was the result of Rafael Nadal's latest game ?", 'chat_history': [], 'output': "I do not have access to real-time information, including sports results. To get the latest information on Rafael Nadal's game, I recommend checking a reliable sports website or news source. n"} """
Without being able to access Google Search, our model is unable to answer because this information was not available at the time it was trained.
Let’s now add our Serper tool to our toolbox and see if our model can use Google Search to find the information:
from langchain_community.utilities import GoogleSerperAPIWrapper
# Create our new search tool here search = GoogleSerperAPIWrapper(serper_api_key="...")
@tool def google_search(query: str): """ Perform a search on Google Args: query: the information to be retrieved with google search """ return search.run(query)
# Add it to our existing tools langchain_tool = [ list_datasets, list_tables, get_exchange_rate_from_api, google_search ]
agent_with_chat_history.invoke({"input": "What was the result of Rafael Nadal's latest game ?"}, config)
--- OUTPUT --- """ {'input': "What was the result of Rafael Nadal's latest game ?", 'chat_history': [], 'output': "Rafael Nadal's last match was a loss to Botic van de Zandschulp in the Davis Cup. Spain was eliminated by the Netherlands. n"} """
Conclusion
LLMs alone often hit a blocker when it comes to using personal, corporate, private or real-data. Indeed, such information is generally not available at training time. Agents and tools are a powerful way to augment these models by allowing them to interact with systems and APIs, and orchestrate workflows to boost productivity.
Why you’re wrong about AI art, according to the Ai-Da robot that just made a $1 million painting
Originally appeared here:
Why you’re wrong about AI art, according to the Ai-Da robot that just made a $1 million painting
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.