Ellie’s story in The Last of Us world isn’t over yet, and a third game is no doubt in the works. Here is everything we know so far about The Last of Us Part 3.
Noble Audio just announced pending availability of its most advanced earbuds yet. The FoKus Rex5 earbuds manage to cram a whole lot of tech into a small package, with a $450 price tag to prove it.
First of all, Noble has installed five drivers into each earbud. This is likely the first time that’s ever been done, as the idea of cramming multiple drivers into a tiny earbud is a relatively new concept. Noble’s own FoKus Prestige earbuds include three drivers, but certainly not five.
Noble Audio
The FoKus Rex5 earbuds include a dynamic driver, a planar driver and three balanced armature drivers to extend the frequency range. The company says this particular combination creates “an impressive soundstage that effortlessly delivers rich, full bass, detailed mid-tones, and crystal-clear highs across an extended frequency range of 20Hz to 40kHz.”
For the uninitiated, planar drivers provide a more accurate signal through the treble and mid ranges. Dynamic drivers have the power to move a whole lot of air, resulting in an improved bass response. The company’s recently-released FoKus Apollo headphones also combine these two types of drivers.
These earbuds integrate with a proprietary app and Audiodo’s personalization software. This lets people create a custom EQ setting based on their hearing, which is then actually uploaded to the earbuds. Of course, the Rex5 buds offer active noise cancellation and multiple transparency modes.
Noble Audio
As for connectivity, the Rex5 earbuds use Bluetooth 5.4 with Multipoint. They’re also equipped with both aptX Adaptive and LDAC hi-res codecs, along with AAC and SBC. The company says customers should expect five hours of use per charge with ANC on and seven hours when it’s off. The earbuds come with a charging case that can power an additional 40 hours of use, with a quick charge feature. The case is also green to match the buds.
Noble Audio’s FoKus Rex5 earbuds are available for preorder right now, with shipments beginning on November 29. As previously mentioned, they cost $450, which is $200 more than Apple’s top-of-the-line AirPods Pro 2.
This article originally appeared on Engadget at https://www.engadget.com/audio/headphones/noble-audio-announces-its-most-advanced-earbuds-yet-with-five-drivers-per-ear-193352556.html?src=rss
When it comes to new tech, $50 doesn’t get you a lot— except perhaps during Black Friday sales. Surprisingly, quite a few of the smaller electronics and accessories we recommend are currently on sale for less than $50. These deals include picks from our guides to accessories, portable batteries, budget earbuds and smart speakers. There are also quite a few streaming subscription deals that fall within that price range, too.
Everything on this list has earned the Engadget seal of approval — be it from official reviews, buying guides, personal use or devices from brands we know to be reputable — so you don’t have to guess whether these Black Friday tech deals are worth your (less than) $50.
Amazon Echo Pop (2023) for $18 ($22 off): Amazon’s smallest Echo will fit in any room in your home, so Alexa can add things to your shopping list, set a timer, or answer questions (like “What’s a bomb cyclone?” or “Who is Penelope Cruz married to?”) from anywhere.
Anker Nano Charger 30W USB-C for $13 ($7 off): This compact 30-watt wall charger is smaller than others of its wattage and can speedily juice up an iPhone or Android handset. Anker is one of Engadget’s most recommended accessory brands and this is the model we picked for our fast charger guide. Get the same deal at Anker with an auto-applied code.
Amazon Smart Plug for $13 ($12 off): If you rely on Alexa as your smart home assistant, this is an affordable and reliable way to control your lamps, fans and Christmas lights. It was one of the more reliable and fuss-free plugs I tested.
Anker Nano II 713 Charger (45W) for $20 ($20 off): This 45-watt charger has a single USB-C port and will let you take advantage of the faster charging speeds newer devices offer (just make sure you have an equally robust cable). It’s one of the picks in our iPad accessories guide. Also at Anker with an auto-applied code.
Chipolo ONE for $20 ($5 off): Our favorite Bluetooth tracker overall is loud, compact and readily tells you when you’ve left your keys (or whatever else you attach them to) behind. If you’re looking for a finding network to locate things you’ve lost out in the wild, this isn’t the one to get, but for everyday locating misplaced keys in the house, this is great.
WAVLINK USB-C hub for $13 ($13 off): The budget pick in our guide to USB-C hubs has an HDMI port, three USB connections (two type-A and one type-C) plus a generous 10-inch cable to give you more options when plugging into your laptop or tablet.
Anker USB-C 240W Bio-Braided cable for $12 ($5 off): A fast charger won’t do much if the cable isn’t rated to handle the wattage. This 240W Anker cable is pulled from our list of the best iPhone accessories and will charge those devices (or any other rechargeable item with a USB-C port) as quickly as the brick and device will allow.
Peak Design Packable Tote for $16 ($4 off): We recommend this handy bag in our gift guide for travelers. We like that it zips shut, is water resistant and has a padded shoulder/hand strap. Plus it packs into itself and takes up just a little more room than a deck of cards.
The Best Black Friday subscription deals under $20
Max / Engadget
Max subscription for $18 (6-month) ($42 off): You can get six months of Max with Ads for $2.99 monthly instead of the usual $9.99. The subscription will automatically renew at that rate each month until the end of the promo period, when it’ll automatically renew for the full $10. New and returning subscribers are eligible through Max.com, Roku, Apple and other streaming ecosystems, but is only open to new subscribers via Amazon Fire TV.
Paramount+ Showtime (two months) for $6 ($20 off): New and former subscribers can get two months of Paramount+ Essential (with ads, usually $8 monthly) or Paramount+ with Showtime (ad-free, usually $13 monthly) for just $3 per month. It’s one of our favorite streaming services and the best place to watch as much Star Trek as you want. As with all subscriptions, remember the standard pricing will auto-renew after two months.
Peacock (one year) for $20 for ($75 off): New and returning subscribers can get a full year of Peacock for just $20. It’s also one of our favorite streamings services and has some excellent shows like Mrs. Davis,Poker Face and Killing It. Note this is the ad-supported tier, it is only available through Peacock’s website and will auto renew after the year is up.
Audible Premium Plus (3-month) for $1 ($29 off): If you don’t currently subscribe to Audible you can get three months of the audiobook service’s Premium Plus plan for $1. The service is usually $15 per month after a 30-day free trial. Premium Plus gives you access to the Audible Plus library, and lets you keep one title from a curated selection of audiobooks each month.
Amazon Kindle Unlimited for $0 for one month ($12 off): Amazon’s ebook subscription service gives you access to a selected catalog of thousands titles for unlimited reading as well as some Audible audiobooks and magazines. Prime members can get two months for only $5.
Black Friday tech deals under $30
Photo by Amy Skorheim / Engadget
Samsung Galaxy SmartTag2 for $21 ($9 off): If you have a Samsung smartphone, this is the tracker we recommend. The finding network isn’t as vast as Apple’s, but in our tests, the accuracy was good and the physical design is one of the best of its kind.
Roku Streaming Stick 4K for $29 ($21 off): On our list of the best streaming devices we named the Roku Streaming Stick 4K the best pick for those wanting an ocean of free and live content. By combining Roku’s own free channels with content from other FAST apps this simple stick turns any screen into a portal to a near-infinite amount of movies and shows that you won’t pay a dime for. Also at Target and direct from Roku for $1 more.
Anker Soundcore 2 Portable Bluetooth Speaker for $28 ($12 off): Anker’s Soundcore brand proves the accessory brand can make some excellent electronics and we named a number of Soundcore audio devices to our buying guides. This is one of the smaller and more affordable models from Anker and it’s currently back to one of its lowest prices yet.
EarFun Free 2S wireless earbuds for $25 ($15 off): These don’t sound as sharp as other budget earbuds we recommend and there’s no noise cancellation or transparency mode, but if you need a pair of earbuds under $50 (or under $30 now) these are decently comfortable with a sound that’s a bit richer than others in its price range.
Amazon Echo Buds for $25 ($25 off): Our favorite budget earbuds with an open ear design are made by Amazon. They don’t go all the way in your ear so you’ll hear more of what’s going on around you. The sound is decently separated, though we recommend tweaking the EQ in the Alexa app to bring down the treble a touch.
Anker USB-C Hub 341 for $25 ($10 off): Anker’s seven-port hub lets you use a range of extras with your tablet, which is why we named it one of the best accessories for an iPad. In addition to extra USB connections, you also get a microSD and standard SD card slots.
Mysterium Board Game for $30 ($25 off): Our own Valentina Palladino recommends this game to anyone who loves a good mystery. It takes Clue to the next level and is best played with friends and family on a dark and stormy night.
Settlers of Catan board game for $26 ($18 off): It’s hard to find anyone into board games who hasn’t yet played Catan, but this trading and settling game is a classic for a reason. Get it and prepare for some lively sheep bartering.
Black Friday tech deals under $40
Engadget
Anker 525 charging station for $36 ($30 off): This is one of the handy items that makes working from home easier, as we recommend in our WFH gift guide. It offers four USB ports up front (both Type-A and Type-C) and three extra AC plugs in the back.
Blink Mini 2 (two-pack) for $35 ($35 off): The newest Blink Mini wired security camera came out earlier this year and it supports 1080p video recordings, a wider field of view than the previous model and improved low-light performance. It may be wired, but you can use it outside with the $10 weather-resistant adapter.
JBL Go 4 for $40 ($10 off): JBL’s smallest portable speaker has up to seven hours of battery life on a charge, has an IP67 waterproof rating and has a tiny built-in carry strap so you can bring it wherever you go. Also at JBL and Best Buy.
Headspace annual plan for $35 ($35 off): Our top pick for the best meditation app has tons of courses that address specific anxieties and worries, a good in-app search engine that makes it easy to find the right meditation you need, and additional yoga routines, podcasts and music sessions to try out.
Amazon Fire TV Stick 4K Max for $33 ($27 off): Amazon’s most powerful dongle supports 4K streaming with Dolby Vision, Wi-Fi 6E and live picture-in-picture mode so you can see security camera feeds directly on your TV as you’re watching a show or movie. In addition to being a solid streamer, it also makes a good retro gaming device.
Anker 633 Magnetic Battery for $40 ($15 off): Choose from a MagSafe option or the 20W Power Delivery port via a USB-C cable (which charges things faster). The handy kickstand means you can look at your phone while it charges and that port lets you charge non-MagSafe devices too.
Blink Outdoor 4 (2023) $38 ($52 off): Amazon’s latest outdoor Blink camera works well (and only) with Alexa, letting you check on your surroundings using the app or a compatible display (like an Echo Show or a Fire TV.
Govee Smart LED Light Bars for $35 ($15 off): We like Govee’s playful smart lights and recommend the brand in our guide to smart bulbs. These light bars made the list in our stocking stuffer gift guide thanks to their versatility (they can stand up, lay flat or be mounted) and there’s no end to the multiple colors and sequences you can program.
Moft Tripod iPhone Wallet for $40 ($10 off with Prime): Moft’s origami-inspired accessories tend to be clever and surprisingly useful. This one is no different, combining a single-card wallet with a dual-height stand. I was impressed with the sturdiness of the stand in such a thin package. If you don’t need to carry a single card, the wallet-less version is $32 right now.
JBL Clip 5 for $49.95 ($30 off): JBL makes a good number of the winners in our guide to the best Bluetooth speakers. We didn’t review this one formally for our guide, but it’s one of the more affordable models the brand makes and the clip plus dunkable water resistance makes it easy to bring JBL’s signature dynamic range just about anywhere. Also at Walmart and direct from JBL.
Amazon Echo Show 5 (2023) for $45 ($45 off): The newest Echo Show 5 made our list of the best smart displays because it doubles as a “stellar alarm clock” with the auto-dimming screen, tap-to-snooze feature and a sunrise alarm. Plus the tiny, five-inch screen is perfect for a nightstand. Also, oddly, at Best Buy.
Amazon Echo Spot (2024) $45 ($35 off): The mini display just shows simple data like the time, weather or song that’s playing while the other half of the circle plays music. It’s an updated version of a model Amazon discontinued a couple of years ago and now it’s back.
Elecom Nestout power bank 15,000mAh for $48 ($12 off): For outdoor charging, this is one of the few portable batteries that can handle a dunk in water (as long as you’ve remembered to screw on the port covers). We recommend it in our guide and particularly like the handy accessories like a tripod stand and light that you can buy to go on it. Also at Nestout for $1 more.
Tribit StormBox Micro 2 for $42 ($38 off with coupon): This is the smallest speaker in our guide and it can go with you anywhere with the built-in strap. It pumps out impressive volume for its size and can go for 12 hours on a charge. The audio isn’t the highest fidelity, but this is more about bringing the vibes than emitting flawless musical clarity. Also directly from Tribit (see price in cart).
Thermacell Mosquito Repeller for $43 ($8 off): The mosquitos may be gone for the winter, but we all know they’ll be back next year. This is one of the few mosquito-repelling products we recommend, so grab one now for a less irritating summer next year.
Japan’s Fair Trade Commission has conducted a raid on Amazon over antitrust concerns. “There is a suspicion that Amazon Japan is forcing sellers to cut prices in an irrational way,” an unnamed source told Reuters.
Amazon Japan received an on-site inspection by the regulator today to explore whether the retailer gives better product placement in search results to sellers who offer lower prices. Additional reporting in The Japan Times suggested that this inquiry is focused on Amazon’s Buy Box program, which puts recommended items more prominently in front of online shoppers. The publication said that in addition to demanding “competitive pricing,” sellers were allegedly required to use Amazon’s in-house services, such as those for logistics and payment collection, to qualify for Buy Box placement.
The Japanese FTC has not released an official statement about the inquiry. We’ve reached out to Amazon for a comment.
Amazon has also been questioned about anti-competitive behavior around the world. Stateside, both the Fair Trade Commission and the Attorney General of Washington DC have raised similar concerns about Amazon’s practices. The company is also expected to face an antitrust investigation in the European Union next year.
This article originally appeared on Engadget at https://www.engadget.com/big-tech/amazon-japan-hit-with-a-raid-over-antitrust-concerns-191558080.html?src=rss
Whether you want a new streaming device to upgrade an aging TV or you want to outfit a new projector with one, Black Friday deals can make it so you spend less on that new set-top box or dongle. One of the best deals we’ve seen on streaming gear is on the latest Roku Ultra, which is on sale for $79, or $21 off its usual rate. That’s an all-time-low price on the 2024 version.
Roku unveiled the 2024 Ultra in September. It claims that the device is at least 30 percent faster than any of its other players. As such, apps should load quickly and moving around the user interface should feel zippy.
The previous version is our pick for the best set-top streaming box (we’re currently testing the 2024 model). The Roku Ultra offers 4K streaming with HDR10+ and Dolby Vision, as well as Dolby Atmos audio. It supports Wi-Fi 6 connectivity and you can plug in an Ethernet cable as well.
This model comes with a second-gen Voice Remote Pro, which boasts backlit buttons and USB-C charging, though Roku says it should run for up to three months on a single charge. Other features include hands-free voice control and a lost remote finder function. Roku ditched the headphone jack for wired listening this time around, unfortunately, but you can still connect wireless headphones to the Roku Ultra via Bluetooth.
The Roku Channel offers more than 400 free, ad-supported streaming channels, along with on-demand shows and movies. The Roku Ultra is also compatible with Alexa, Google Assistant, Apple HomeKit and AirPlay.
In addition to the latest Ultra, you can save on a number of other Roku devices for Black Friday. The most affordable of the bunch is the Roku Express HD, which is down to only $18, and the Roku Streambar SE is on sale for $69 — only $10 more than its record low.
This article originally appeared on Engadget at https://www.engadget.com/deals/black-friday-deals-bring-the-2024-roku-ultra-down-to-79-181528064.html?src=rss
Are you eagerly anticipating the next crop of games from Devolver Digital? Well, you’re going to have to wait a little longer. The indie game studio will unveil the nominees and winners of its annual Devolver Delayed Awards at 1 PM Eastern Wednesday on its official YouTube page. Devolver’s tongue-in-cheek awards show aims to honor “the brightest, best indie games you can’t play yet” and yes, Skate Storyis still in that category.
It’s all part of Devolver’s satirical marketing strategy — like calling the event the “15th annual” despite the fact that last year’s Delayed Awards was the “first-ever showcase celebrating brands that are courageously moving into 2024,” according to a press release.
Devolver will at least tide us over with more footage from some of these unplayable games. Titles might include the minimalist brawler Stick It to the Stickmen, the story driven walking simBaby Stepsand the long-awaited ragdoll puzzler Human Fall Flat 2. The studio also hinted that there may be a glimpse of “something new” for 2025.
This article originally appeared on Engadget at https://www.engadget.com/gaming/devolver-digitals-delayed-awards-returns-wednesday-185754203.html?src=rss
As generative AI (genAI) models grow in both popularity and scale, so do the computational demands and costs associated with their training and deployment. Optimizing these models is crucial for enhancing their runtime performance and reducing their operational expenses. At the heart of modern genAI systems is the Transformer architecture and its attention mechanism, which is notably compute-intensive.
In a previous post, we demonstrated how using optimized attention kernels can significantly accelerate the performance of Transformer models. In this post, we continue our exploration by addressing the challenge of variable-length input sequences — an inherent property of real-world data, including documents, code, time-series, and more.
The Challenge of Batching Variable-Length Input
In a typical deep learning workload, individual samples are grouped into batches before being copied to the GPU and fed to the AI model. Batching improves computational efficiency and often aids model convergence during training. Usually, batching involves stacking all of the sample tensors along a new dimension — the batch dimension. However, torch.stack requires that all tensors to have the same shape, which is not the case with variable-length sequences.
Padding and its Inefficiencies
The traditional way to address this challenge is to pad the input sequences to a fixed length and then perform stacking. This solution requires appropriate masking within the model so that the output is not affected by the irrelevant tensor elements. In the case of attention layers, a padding mask indicates which tokens are padding and should not be attended to (e.g., see PyTorch MultiheadAttention). However, padding can waste considerable GPU resources, increasing costs and slowing development. This is especially true for large-scale AI models.
Don’t Pad, Concatenate
One way to avoid padding is to concatenate sequences along an existing dimension instead of stacking them along a new dimension. Contrary to torch.stack, torch.cat allows inputs of different shapes. The output of concatenation is single sequence whose length equals the sum of the lengths of the individual sequences. For this solution to work, our single sequence would need to be supplemented by an attention mask that would ensure that each token only attends to other tokens in the same original sequence, in a process sometimes referred to as document masking. Denoting the sum of the lengths of all of the individual by N and adopting ”big O” notation, the size of this mask would need to be O(N²), as would the compute complexity of a standard attention layer, making this solution highly inefficient.
Attention Layer Optimization
The solution to this problem comes in the form of specialized attention layers. Contrary to the standard attention layer that performs the full set of O(N²) attention scores only to mask out the irrelevant ones, these optimized attention kernels are designed to calculate only the scores that matter. In this post we will explore several solutions, each with their own distinct characteristics. These include:
For teams working with pre-trained models, transitioning to these optimizations might seem challenging. We will demonstrate how HuggingFace’s APIs simplify this process, enabling developers to integrate these techniques with minimal code changes and effort.
Disclaimers
Please do not interpret our use of any platforms, libraries, or optimization techniques as an endorsement for their use. The best options for you will depend greatly on the specifics of your own use-case.
Some of the APIs discussed here are in prototype or beta stages and may change in the future.
The code examples provided are for demonstrative purposes only. We make no claims regarding their accuracy, optimality, or robustness.
To facilitate our discussion we will define a simple generative model (partially inspired by the GPT model defined here). For a more comprehensive guide on building language models, please see one of the many excellent tutorials available online (e.g., here).
Transformer Block
We begin by constructing a basic Transformer block, specifically designed to facilitate experimentation with different attention mechanisms and optimizations. While our block performs the same computation as standard Transformer blocks, we make slight modifications to the usual choice of operators in order to support the possibility of PyTorch NestedTensor inputs (as described here).
# general imports import time, functools
# torch imports import torch from torch.utils.data import Dataset, DataLoader import torch.nn as nn
# rather than first reformatting and then splitting the input # state, we first split and then reformat q, k, v in order to # support PyTorch Nested Tensors q, k, v = qkv.chunk(3, -1) q = self.reshape_and_permute(q, batch_size) k = self.reshape_and_permute(k, batch_size) v = self.reshape_and_permute(v, batch_size)
# call the attn_fn with the input attn_mask x = self.attn_fn(q, k, v, attn_mask=attn_mask)
# reformat output x = self.permute(x).reshape(batch_size, -1, self.dim) x = self.proj(x) x = x + x_in x = x + self.mlp(self.norm2(x)) return x
Transformer Decoder Model
Building on our programmable Transformer block, we construct a typical Transformer decoder model.
def embed_tokens(self, input_ids, position_ids=None): x = self.embedding(input_ids) if position_ids is None: position_ids = torch.arange(input_ids.shape[1], device=x.device) x = x + self.positional_embedding(position_ids) return x
def forward(self, input_ids, position_ids=None, attn_mask=None): # Embed tokens and add positional encoding x = self.embed_tokens(input_ids, position_ids) if self.pad_idx is not None: assert attn_mask is None # create a padding mask - we assume boolean masking attn_mask = (input_ids != self.pad_idx) attn_mask = attn_mask.view(BATCH_SIZE, 1, 1, -1) .expand(-1, self.num_heads, -1, -1)
for b in self.blocks: x = b(x, attn_mask)
logits = self.output(x) return logits
Variable Length Sequence Input
Next, we create a dataset containing sequences of variable lengths, where each sequence is made up of randomly generated tokens. For simplicity, we (arbitrarily) select a fixed distribution for the sequence lengths. In real-world scenarios, the distribution of sequence lengths typically reflects the nature of the data, such as the length of documents or audio segments. Note, that the distribution of lengths directly affects the computational inefficiencies caused by padding.
# Use random data class FakeDataset(Dataset): def __len__(self): return 1000000
def data_to_device(data, device): if isinstance(data, dict): return { key: data_to_device(val,device) for key, val in data.items() } elif isinstance(data, (list, tuple)): return type(data)( data_to_device(val, device) for val in data ) elif isinstance(data, torch.Tensor): return data.to(device=device, non_blocking=True) else: return data.to(device=device)
Training/Evaluation Loop
Lastly, we implement a main function that performs training/evaluation on input sequences of varying length.
for step, data in enumerate(data_loader): # Copy data to GPU data = data_to_device(data, device=device) step_fn(model, data['inputs'], data['targets'], position_ids=data.get('indices'), attn_mask=data.get('attn_mask'))
# Capture step time batch_time = time.perf_counter() - t0 if step > 20: # Skip first steps summ += batch_time count += 1 t0 = time.perf_counter() if step >= 100: break print(f'average step time: {summ / count}')
PyTorch SDPA with Padding
For our baseline experiments, we configure our Transformer block to utilize PyTorch’s SDPA mechanism. In our experiments, we run both training and evaluation, both with and without torch.compile. These were run on an NVIDIA H100 with CUDA 12.4 and PyTorch 2.5.1
from torch.nn.functional import scaled_dot_product_attention as sdpa block_fn = functools.partial(MyAttentionBlock, attn_fn=sdpa) causal_block_fn = functools.partial( MyAttentionBlock, attn_fn=functools.partial(sdpa, is_causal=True) )
for mode in ['eval', 'train']: for compile in [False, True]: block_func = causal_block_fn if mode == 'train' else block_fn print(f'{mode} with {collate}, ' f'{"compiled" if compile else "uncompiled"}') main(block_fn=block_func, pad_idx=PAD_ID, train=mode=='train', compile=compile)
Performance Results:
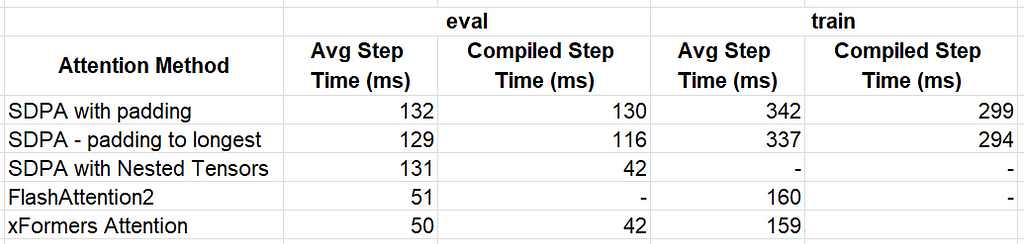
Evaluation: 132 milliseconds (ms) without torch.compile, 130 ms with torch.compile
Training: 342 ms without torch.compile, 299 ms with torch.compile
Optimizing for Variable Length Input
In this section, we will explore several optimization techniques for handling variable-length input sequences in Transformer models.
Padding Optimization
Our first optimization relates not to the attention kernel but to our padding mechanism. Rather than padding the sequences in each batch to a constant length, we pad to the length of the longest sequence in the batch. The following block of code consists of our revised collation function and updated experiments.
def collate_pad_to_longest(batch): padded_inputs = [] padded_targets = [] max_length = max([b[0].shape[0] for b in batch]) for b in batch: padded_inputs.append(pad_sequence(b[0], max_length, PAD_ID)) padded_targets.append(pad_sequence(b[1], max_length, PAD_ID)) padded_inputs = torch.stack(padded_inputs, dim=0) padded_targets = torch.stack(padded_targets, dim=0) return { 'inputs': padded_inputs, 'targets': padded_targets }
for mode in ['eval', 'train']: for compile in [False, True]: block_func = causal_block_fn if mode == 'train' else block_fn print(f'{mode} with {collate}, ' f'{"compiled" if compile else "uncompiled"}') main(block_fn=block_func, data_collate_fn=collate_pad_to_longest, pad_idx=PAD_ID, train=mode=='train', compile=compile)
Padding to the longest sequence in each batch results in a slight performance acceleration:
Evaluation: 129 ms without torch.compile, 116 ms with torch.compile
Training: 337 ms without torch.compile, 294 ms with torch.compile
SDPA with PyTorch NestedTensors
Next, we take advantage of the built-in support for PyTorch NestedTensors in SDPA in evaluation mode. Currently a prototype feature, PyTorch NestedTensors allows for grouping together tensors of varying length. These are sometimes referred to as jagged or ragged tensors. In the code block below, we define a collation function for grouping our sequences into NestedTensors. We also define an indices entry so that we can properly calculate the positional embeddings.
PyTorch NestedTensors are supported by a limited number of PyTorch ops. Working around these limitations can require some creativity. For example, addition between NestedTensors is only supported when they share precisely the same “jagged” shape. In the code below we use a workaround to ensure that the indices entry shares the same shape as the model inputs.
def nested_tensor_collate(batch): inputs = torch.nested.as_nested_tensor([b[0] for b in batch], layout=torch.jagged) targets = torch.nested.as_nested_tensor([b[1] for b in batch], layout=torch.jagged) indices = torch.concat([torch.arange(b[0].shape[0]) for b in batch])
# workaround for creating a NestedTensor with identical "jagged" shape xx = torch.empty_like(inputs) xx.data._values[:] = indices
return { 'inputs': inputs, 'targets': targets, 'indices': xx }
for compile in [False, True]: print(f'eval with nested tensors, ' f'{"compiled" if compile else "uncompiled"}') main( block_fn=block_fn, data_collate_fn=nested_tensor_collate, train=False, compile=compile )
Although, with torch.compile, the NestedTensor optimization results in a step time of 131 ms, similar to our baseline result, in compiled mode the step time drops to 42 ms for an impressive ~3x improvement.
FlashAttention2
In our previous post we demonstrated the use of FlashAttention and its impact on the performance of a transformer model. In this post we demonstrate the use of flash_attn_varlen_func from flash-attn (2.7.0), an API designed for use with variable-sized inputs. To use this function, we concatenate all of the sequences in the batch into a single sequence. We also create a cu_seqlens tensor that points to the indices within the concatenated tensor where each of the individual sequences start. The code block below includes our collation function followed by evaluation and training experiments. Note, that flash_attn_varlen_func does not support torch.compile (at the time of this writing).
def collate_concat(batch): inputs = torch.concat([b[0] for b in batch]).unsqueeze(0) targets = torch.concat([b[1] for b in batch]).unsqueeze(0) indices = torch.concat([torch.arange(b[0].shape[0]) for b in batch]) seqlens = torch.tensor([b[0].shape[0] for b in batch]) seqlens = torch.cumsum(seqlens, dim=0, dtype=torch.int32) cu_seqlens = torch.nn.functional.pad(seqlens, (1, 0))
The impact of this optimization is dramatic, 51 ms for evaluation and 160 ms for training, amounting to 2.6x and 2.1x performance boosts compared to our baseline experiment.
XFormers Memory Efficient Attention
In our previous post we demonstrated the use of the memory_efficient_attention operator from xFormers (0.0.28). Here we demonstrate the use of BlockDiagonalMask, specifically designed for input sequences of arbitrary length. The required collation function appears in the code block below followed by the evaluation and training experiments. Note, that torch.compile failed in training mode.
from xformers.ops import fmha from xformers.ops import memory_efficient_attention as mea
def collate_xformer(batch): inputs = torch.concat([b[0] for b in batch]).unsqueeze(0) targets = torch.concat([b[1] for b in batch]).unsqueeze(0) indices = torch.concat([torch.arange(b[0].shape[0]) for b in batch]) seqlens = [b[0].shape[0] for b in batch] batch_sizes = [1 for b in batch] block_diag = fmha.BlockDiagonalMask.from_seqlens(seqlens, device='cpu') block_diag._batch_sizes = batch_sizes
print(f'xFormer Attention ') for compile in [False, True]: print(f'eval with xFormer Attention, ' f'{"compiled" if compile else "uncompiled"}') main(block_fn=block_fn, train=False, data_collate_fn=collate_xformer, compile=compile)
print(f'train with xFormer Attention') main(block_fn=causal_block_fn, train=True, data_collate_fn=collate_xformer)
The resultant step time were 50 ms and 159 ms for evaluation and training without torch.compile. Evaluation with torch.compile resulted in a step time of 42 ms.
Results
The table below summarizes the results of our optimization methods.
Step time results for different optimization methods (lower is better) — by Author
The best performer for our toy model is xFormer’s memory_efficient_attention which delivered a ~3x performance for evaluation and ~2x performance for training. We caution against deriving any conclusions from these results as the performance impact of different attention functions can vary significantly depending on the specific model and use case.
Optimizing a HuggingFace Model for Variable-Length Input
The tools and techniques described above are easy to implement when creating a model from scratch. However, these days it is not uncommon for ML developers to adopt existing (pretrained) models and finetune them for their use case. While the optimizations we have described can be integrated without changing the set of model weights and without altering the model behavior, it is not entirely clear what the best way to do this is. In an ideal world, our ML framework would allow us to program the use of an attention mechanism that is optimized for variable-length inputs. In this section we demonstrate how to optimize HuggingFace models for variable-length inputs.
A Toy HuggingFace Model – GPT2LMHeadModel
To facilitate the discussion, we create a toy example in which we train a HuggingFace GPT2LMHead model on variable-length sequences. This requires adapting our random dataset and data-padding collation function according to HuggingFace’s input specifications.
from transformers import GPT2Config, GPT2LMHeadModel
# Use random data class HuggingFaceFakeDataset(Dataset): def __len__(self): return 1000000
for compile in [False, True]: print(f"HF GPT2 train with SDPA, compile={compile}") hf_main(config=config, compile=compile)
The resultant step times are 815 ms without torch.compile and 440 ms with torch.compile.
FlashAttention2
We now take advantage of HuggingFace’s built-in support for FlashAttention2, by setting the attn_implementation parameter to “flash_attention_2”. Behind the scenes, HuggingFace will unpad the padded data input and then pass them to the optimized flash_attn_varlen_func function we saw above:
print(f"HF GPT2 train with flash") hf_main(config=flash_config)
The resultant time step is 620 ms, amounting to a 30% boost (in uncompiled mode) with just a simple flick of a switch.
FlashAttention2 with Unpadded Input
Of course, padding the sequences in the collation function only to have them unpadded, hardly seems sensible. In a recent update to HuggingFace, support was added for passing in concatenated (unpadded) sequences to a select number of models. Unfortunately, (as of the time of this writing) our GPT2 model did not make the cut. However, adding support requires just five small line additions changes to modeling_gpt2.py in order to propagate the sequence position_idsto the flash-attention kernel. The full patch appears in the block below:
We define a collate function that concatenates our sequences and train our hugging face model on unpadded sequences. (Also see the built-in DataCollatorWithFlattening utility.)
def collate_flatten(batch): input_ids = torch.concat([b['input_ids'] for b in batch]).unsqueeze(0) labels = torch.concat([b['labels'] for b in batch]).unsqueeze(0) position_ids = [torch.arange(b['input_ids'].shape[0]) for b in batch] position_ids = torch.concat(position_ids)
print(f"HF GPT2 train with flash, no padding") hf_main(config=flash_config, collate_fn=collate_flatten)
The resulting step time is 323 ms, 90% faster than running flash-attention on the padded input.
Results
The results of our HuggingFace experiments are summarized below.
Step time results for different optimization methods (lower is better) — by Author
With little effort, we were able to boost our runtime performance by 2.5x when compared to the uncompiled baseline experiment, and by 36% when compared to the compiled version.
In this section, we demonstrated how the HuggingFace APIs allow us to leverage the optimized kernels in FlashAttention2, significantly boosting the training performance of existing models on sequences of varying length.
Summary
As AI models continue to grow in both popularity and complexity, optimizing their performance has become essential for reducing runtime and costs. This is especially true for compute-intensive components like attention layers. In this post, we have continued our exploration of attention layer optimization, and demonstrated new tools and techniques for enhancing Transformer model performance. For more insights on AI model optimization, be sure to check out the first post in this series as well as our many other posts on this topic.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.