Genmoji are custom emojis you can create if you’ve installed the iOS 18.2 or iPadOS 18.2 update. They are the emojis of your imagination, made real with help from Apple Intelligence — you describe what emoji you want to see, like a sad cowboy or an octopus DJ, and Apple’s AI will do its best to generate it. You can even create custom emojis of people you know if you have a photo of them in your library. Once you’ve made Genmoji, they’ll be stored in your keyboard so you can use them in Apple apps that support emojis. They can be sent as part of messages, as standalone stickers or as Tapback reactions.
How to create Genmoji
To create a Genmoji, you’ll need a device that is up to date with iOS 18.2/iPadOS 18.2 or later and compatible with Apple Intelligence. That includes every iPhone 16 model, iPhone 15 Pro and iPhone 15 Pro Max, as well as iPad models with the M1 chip or later, and iPad mini (A17 Pro). At the moment, you can only create Genmoji on iPhone and iPad, though Apple says the feature will be coming to Mac down the line. The steps to create a Genmoji are the same for iPhone and iPad.
Apple
First, open a conversation and tap the text field to bring up the keyboard. Then tap either the smiley icon or the globe icon, depending on which you have. After doing that, you should now see a multicolored smiley icon with a plus sign on it at the top right of the keyboard. Tap that and a text bar will appear prompting you to describe the emoji you’d like to create. Enter the description, then tap “Done.”
If you’re making a Genmoji of a specific person, make sure you’ve already labeled them in your Photos app. Then, enter your description and tap the “Choose a Person” option above the text field. You’ll be shown who it has identified from your photos, and a few style options as a starting point. Click the one you like, and it’ll create the Genmoji using that character.
Apple
The results might not be to your liking the first try, and if that’s the case, just try tweaking your description until you get better results. Once you’ve made Genmoji, you’ll be able to find them in your keyboard either by swiping right through all the emoji options or by tapping the sticker icon. You can also add them to Tapback by pressing and holding a message, and clicking the smiley with a plus sign icon to search the emoji keyboard.
How to delete Genmoji
If you made a Genmoji and later decide you aren’t into it anymore, you can always delete it after the fact. To do this, head back into the emoji keyboard and either swipe right through all the pages or just tap the sticker icon. From there, find the Genmoji you want to get rid of, press and hold it, then tap Remove once the option pops up.
This article originally appeared on Engadget at https://www.engadget.com/mobile/how-to-use-genmoji-to-make-your-own-custom-emojis-225907928.html?src=rss
Hackers behind a cyberattack that targeted Rhode Island’s public benefits system were able to get the sensitive data — including Social Security numbers and some banking information — of hundreds of thousands of people, and they have threatened to release it as soon as this week if they aren’t paid a ransom, Rhode Island governor Dan McKee said in a press conference on Saturday night. The Rhode Island government opened a toll-free hotline on Sunday (833-918-6603) to provide information on the breach and how residents can protect themselves, but you won’t be able to find out for sure if your data was stolen by calling in. People who may have been affected will be notified by mail.
The attack targeted the RIBridges system, maintained by Deloitte, which is used to apply for Medicaid, Supplemental Nutrition Assistance Program (SNAP), Temporary Assistance for Needy Families (TANF), Child Care Assistance Program (CCAP), HealthSource RI healthcare coverage and other public benefits available to Rhode Islanders. A press release from McKee’s office notes that “any individual who has received or applied for health coverage and/or health and human services programs or benefits could be impacted by this leak.”
It’s thought the hackers were able to get information including names, addresses, dates of birth, Social Security numbers and “certain banking information.” Deloitte first detected the breach and notified state officials on December 5, and determined on the 11th that there was “a high probability that the implicated folders contain personal identifiable data from RIBridges.” It confirmed the presence of malicious code on December 13 and subsequently shut the system down, before officials announced the attack to the public the same day.
The system is now offline while Deloitte works to secure it, which means that anyone who needs to apply for one of the affected programs will have to do so by mail, and people who are currently enrolled won’t be able to access the online portal or app. The state said it so far hasn’t detected any identity theft or fraud relating to the attack, but it will be offering free credit monitoring to anyone affected by the breach.
This article originally appeared on Engadget at https://www.engadget.com/cybersecurity/hackers-may-have-accessed-hundreds-of-thousands-of-rhode-islanders-sensitive-info-in-ribridges-cyberattack-194621262.html?src=rss
The Magic Mouse has gone a long time without any major changes to its design beyond things like dropping the AA batteries and gaining a USB-C port, but Apple is now reportedly planning an overhaul. In the Power On newsletter, Mark Gurman reports that Apple has started working on prototypes for a more modern version of the Magic Mouse, which was first released way back in 2009.
While some users have loved the Magic Mouse for its gesture controls, other aspects like its nonergonomic design and its underside charging port have been the subject of complaints for years. We don’t know what exactly the redesign will bring, but it’d be great to see those things finally addressed. And it sounds like we will. According to Gurman, “Apple is looking to create something that’s more relevant, while also fixing longstanding complaints — yes, including the charging port issue.” It could still be a while before we see the new Magic Mouse, though. Gurman notes that it could take another year to 18 months to get it ready for market.
The newsletter also gives us a bit more info on the rumored new AirTag that Apple reportedly has in the works for release next year. Building on his previous reports about a next-gen AirTag with a better chip and more tamperproof design, Gurman now reports that the new tracker will have “a new ultrawide band chip on par with the one introduced in the iPhone 15,” which he says could triple its detectable range with Precision Finding.
This article originally appeared on Engadget at https://www.engadget.com/computing/accessories/apples-magic-mouse-may-be-getting-a-big-makeover-in-the-next-year-or-so-174255032.html?src=rss
Credit card fraud detection is a plague that all financial institutions are at risk with. In general fraud detection is very challenging because fraudsters are coming up with new and innovative ways of detecting fraud, so it is difficult to find a pattern that we can detect. For example, in the diagram all the icons look the same, but there one icon that is slightly different from the rest and we have pick that one. Can you spot it?
Here it is:
Image by Author
With this background let me provide a plan for today and what you will learn in the context of our use case ‘Credit Card Fraud Detection’:
1. What is data imbalance
2. Possible causes of data Imbalance
3. Why is class imbalance a problem in machine learning
4. Quick Refresher on Random Forest Algorithm
5. Different sampling methods to deal with data Imbalance
6. Comparison of which method works well in our context with a practical Demonstration with Python
7. Business insight on which model to choose and why?
In most cases, because the number of fraudulent transactions is not a huge number, we have to work with a data that typically has a lot of non-frauds compared to Fraud cases. In technical terms such a dataset is called an ‘imbalanced data’. But, it is still essential to detect the fraud cases, because only 1 fraudulent transaction can cause millions of losses to banks/financial institutions. Now, let us delve deeper into what is data imbalance.
Formally this means that the distribution of samples across different classes is unequal. In our case of binary classification problem, there are 2 classes
a) Majority class—the non-fraudulent/genuine transactions
b) Minority class—the fraudulent transactions
In the dataset considered, the class distribution is as follows (Table 1):
Table 1: Class Distribution (By Author)
As we can observe, the dataset is highly imbalanced with only 0.17% of the observations being in the Fraudulent category.
2. Possible causes of Data Imbalance
There can be 2 main causes of data imbalance:
a) Biased Sampling/Measurement errors: This is due to collection of samples only from one class or from a particular region or samples being mis-classified. This can be resolved by improving the sampling methods
b) Use case/domain characteristic: A more pertinent problem as in our case might be due to the problem of prediction of a rare event, which automatically introduces skewness towards majority class because the occurrence of minor class is practice is not often.
3. Why is class imbalance a problem in machine-learning?
This is a problem because most of the algorithms in machine learning focus on learning from the occurrences that occur frequently i.e. the majority class. This is called the frequency bias. So in cases of imbalanced dataset, these algorithms might not work well. Typically few techniques that will work well are tree based algorithms or anomaly detection algorithms. Traditionally, in fraud detection problems business rule based methods are often used. Tree-based methods work well because a tree creates rule-based hierarchy that can separate both the classes. Decision trees tend to over-fit the data and to eliminate this possibility we will go with an ensemble method. For our use case, we will use the Random Forest Algorithm today.
4. A quick Refresher on Random Forest Algorithm
Random Forest works by building multiple decision tree predictors and the mode of the classes of these individual decision trees is the final selected class or output. It is like voting for the most popular class. For example: If 2 trees predict that Rule 1 indicates Fraud while another tree indicates that Rule 1 predicts Non-fraud, then according to Random forest algorithm the final prediction will be Fraud.
Formal Definition: A random forest is a classifier consisting of a collection of tree-structured classifiers {h(x,Θk ), k=1, …} where the {Θk} are independent identically distributed random vectors and each tree casts a unit vote for the most popular class at input x . (Source)
Each tree depends on a random vector that is independently sampled and all trees have a similar distribution. The generalization error converges as the number of trees increases. In its splitting criteria, Random forest searches for the best feature among a random subset of features and we can also compute variable importance and accordingly do feature selection. The trees can be grown using bagging technique where observations can be random selected (without replacement) from the training set. The other method can be random split selection where a random split is selected from K-best splits at each node.
We will now illustrate 3 sampling methods that can take care of data imbalance.
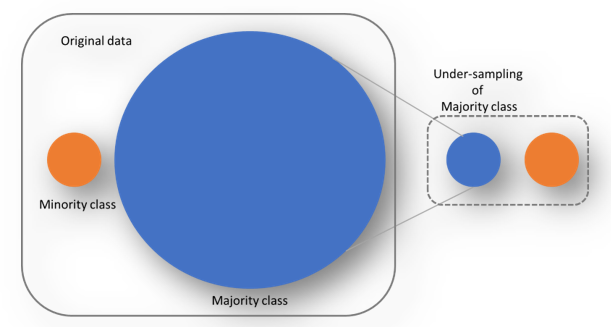
a) Random Under-sampling: Random draws are taken from the non-fraud observations i.e the majority class to match it with the Fraud observations ie the minority class. This means, we are throwing away some information from the dataset which might not be ideal always.
Fig 1: Random Under-sampling (Image By Author)
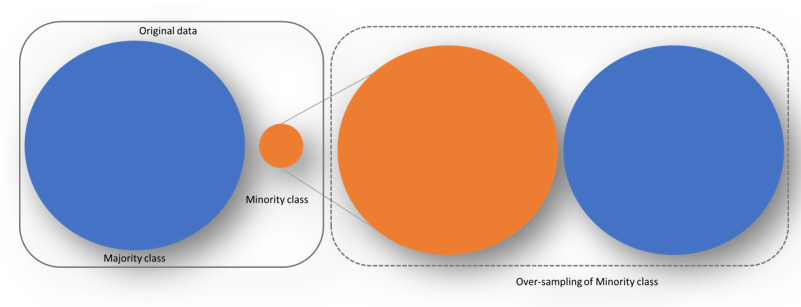
b) Random Over-sampling: In this case, we do exact opposite of under-sampling i.e duplicate the minority class i.e Fraud observations at random to increase the number of the minority class till we get a balanced dataset. Possible limitation is we are creating a lot of duplicates with this method.
Fig 2: Random Over-sampling (Image By Author)
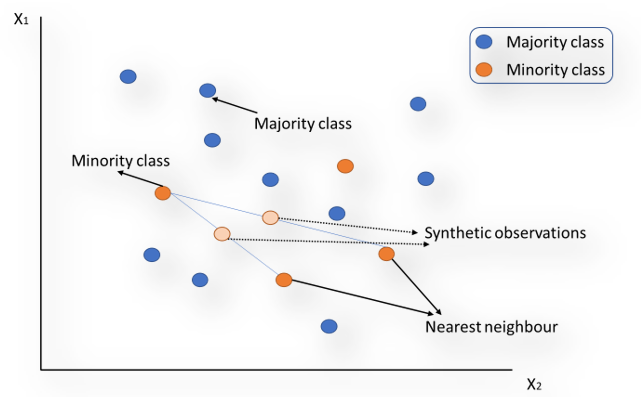
c) SMOTE: (Synthetic Minority Over-sampling technique) is another method that uses synthetic data with KNN instead of using duplicate data. Each minority class example along with their k-nearest neighbours is considered. Then along the line segments that join any/all the minority class examples and k-nearest neighbours synthetic examples are created. This is illustrated in the Fig 3 below:
Fig 3: SMOTE (Image By Author)
With only over-sampling, the decision boundary becomes smaller while with SMOTE we can create larger decision regions thereby improving the chance of capturing the minority class better.
One possible limitation is, if the minority class i.e fraudulent observations is spread throughout the data and not distinct then using nearest neighbours to create more fraud cases, introduces noise into the data and this can lead to mis-classification.
6. Quick refresher on Accuracy, Recall, Precision
Some of the metrics that is useful for judging the performance of a model are listed below. These metrics provide a view how well/how accurately the model is able to predict/classify the target variable/s:
Fig 3: Classification Matrix (Image By Author)
· TP (True positive)/TN (True negative) are the cases of correct predictions i.e predicting Fraud cases as Fraud (TP) and predicting non-fraud cases as non-fraud (TN)
· FP (False positive) are those cases that are actually non-fraud but model predicts as Fraud
· FN (False negative) are those cases that are actually fraud but model predicted as non-Fraud
Precision = TP / (TP + FP): Precision measures how accurately model is able to capture fraud i.e out of the total predicted fraud cases, how many actually turned out to be fraud.
Recall = TP/ (TP+FN): Recall measures out of all the actual fraud cases, how many the model could predict correctly as fraud. This is an important metric here.
Accuracy = (TP +TN)/(TP+FP+FN+TN): Measures how many majority as well as minority classes could be correctly classified.
F-score = 2*TP/ (2*TP + FP +FN) = 2* Precision *Recall/ (Precision *Recall) ; This is a balance between precision and recall. Note that precision and recall are inversely related, hence F-score is a good measure to achieve a balance between the two.
7. Comparison of which method works well with a practical demonstration with Python
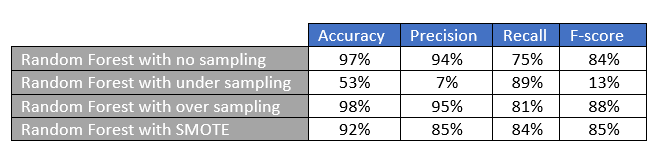
First, we will train the random forest model with some default features. Please note optimizing the model with feature selection or cross validation has been kept out-of-scope here for sake of simplicity. Post that we train the model using under-sampling, oversampling and then SMOTE. The table below illustrates the confusion matrix along with the precision, recall and accuracy metrics for each method.
Table 2: Model results comparison (By Author)
a) No sampling result interpretation: Without any sampling we are able to capture 76 fraudulent transactions. Though the overall accuracy is 97%, the recall is 75%. This means that there are quite a few fraudulent transactions that our model is not able to capture.
Below is the code that can be used :
# Training the model from sklearn.ensemble import RandomForestClassifier classifier = RandomForestClassifier(n_estimators=10,criterion='entropy', random_state=0) classifier.fit(x_train,y_train)
# Predict Y on the test set y_pred = classifier.predict(x_test)
# Obtain the results from the classification report and confusion matrix from sklearn.metrics import classification_report, confusion_matrix
b) Under-sampling result interpretation: With under-sampling , though the model is able to capture 90 fraud cases with significant improvement in recall, the accuracy and precision falls drastically. This is because the false positives have increased phenomenally and the model is penalizing a lot of genuine transactions.
Under-sampling code snippet:
# This is the pipeline module we need from imblearn from imblearn.under_sampling import RandomUnderSampler from imblearn.pipeline import Pipeline
# Define which resampling method and which ML model to use in the pipeline resampling = RandomUnderSampler() model = RandomForestClassifier(n_estimators=10,criterion='entropy', random_state=0)
# Define the pipeline,and combine sampling method with the RF model pipeline = Pipeline([('RandomUnderSampler', resampling), ('RF', model)])
# Obtain the results from the classification report and confusion matrix print('Classifcation report:n', classification_report(y_test, predicted)) conf_mat = confusion_matrix(y_true=y_test, y_pred=predicted) print('Confusion matrix:n', conf_mat)
c) Over-sampling result interpretation: Over-sampling method has the highest precision and accuracy and the recall is also good at 81%. We are able to capture 6 more fraud cases and the false positives is pretty low as well. Overall, from the perspective of all the parameters, this model is a good model.
Oversampling code snippet:
# This is the pipeline module we need from imblearn from imblearn.over_sampling import RandomOverSampler
# Define which resampling method and which ML model to use in the pipeline resampling = RandomOverSampler() model = RandomForestClassifier(n_estimators=10,criterion='entropy', random_state=0)
# Define the pipeline,and combine sampling method with the RF model pipeline = Pipeline([('RandomOverSampler', resampling), ('RF', model)])
# Obtain the results from the classification report and confusion matrix print('Classifcation report:n', classification_report(y_test, predicted)) conf_mat = confusion_matrix(y_true=y_test, y_pred=predicted) print('Confusion matrix:n', conf_mat)
d) SMOTE: Smote further improves the over-sampling method with 3 more frauds caught in the net and though false positives increase a bit the recall is pretty healthy at 84%.
SMOTE code snippet:
# This is the pipeline module we need from imblearn
from imblearn.over_sampling import SMOTE
# Define which resampling method and which ML model to use in the pipeline resampling = SMOTE(sampling_strategy='auto',random_state=0) model = RandomForestClassifier(n_estimators=10,criterion='entropy', random_state=0)
# Define the pipeline, tell it to combine SMOTE with the RF model pipeline = Pipeline([('SMOTE', resampling), ('RF', model)])
# Obtain the results from the classification report and confusion matrix print('Classifcation report:n', classification_report(y_test, predicted)) conf_mat = confusion_matrix(y_true=y_test, y_pred=predicted) print('Confusion matrix:n', conf_mat)
Summary:
In our use case of fraud detection, the one metric that is most important is recall. This is because the banks/financial institutions are more concerned about catching most of the fraud cases because fraud is expensive and they might lose a lot of money over this. Hence, even if there are few false positives i.e flagging of genuine customers as fraud it might not be too cumbersome because this only means blocking some transactions. However, blocking too many genuine transactions is also not a feasible solution, hence depending on the risk appetite of the financial institution we can go with either simple over-sampling method or SMOTE. We can also tune the parameters of the model, to further enhance the model results using grid search.
For details on the code refer to this link on Github.
Apple’s third-generation Apple Watch Ultra is expected sometime in 2025, and is rumored to include satellite messaging, along with some form of hypertension monitoring.
The Apple Watch Ultra third-gen should arrive in 2025 with new features.
The upgrade to self-contained satellite communication would enable users to rely less on their iPhones for messaging and emergency calls in remote areas, potentially lightening the load for outdoor enthusiasts. The feature is likely to be exclusive to the third-gen Apple Watch Ultra, the current generation of which retails for $799.
To be clear, the addition of satellite communication and geolocation features in the Apple Watch Ultra would assist with emergency situations, but not replace the overall usefulness of the iPhone. It would, however, make it easier to summon help quickly, if needed, by having the device already available on one’s wrist, rather than packed away.
Future Apple Watch Ultra rumored to get satellite communications & hypertension detection
Originally appeared here:
Future Apple Watch Ultra rumored to get satellite communications & hypertension detection
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.