Learn how to create an agent that understands your home’s context, learns your preferences, and interacts with you and your home to accomplish activities you find valuable.
This article describes the architecture and design of a Home Assistant (HA) integration called home-generative-agent. This project uses LangChain and LangGraph to create a generative AI agent that interacts with and automates tasks within a HA smart home environment. The agent understands your home’s context, learns your preferences, and interacts with you and your home to accomplish activities you find valuable. Key features include creating automations, analyzing images, and managing home states using various LLMs (Large Language Models). The architecture involves both cloud-based and edge-based models for optimal performance and cost-effectiveness. Installation instructions, configuration details, and information on the project’s architecture and the different models used are included and can be found on the home-generative-agent GitHub. The project is open-source and welcomes contributions.
These are some of the features currently supported:
Create complex Home Assistant automations.
Image scene analysis and understanding.
Home state analysis of entities, devices, and areas.
Full agent control of allowed entities in the home.
Short- and long-term memory using semantic search.
Automatic summarization of home state to manage LLM context length.
This is my personal project and an example of what I call learning-directed hacking. The project is not affiliated with my work at Amazon nor am I associated with the organizations responsible for Home Assistant or LangChain/LangGraph in any way.
Important Considerations
Creating an agent to monitor and control your home can lead to unexpected actions and potentially put your home and yourself at risk due to LLM hallucinations and privacy concerns, especially when exposing home states and user information to cloud-based LLMs. I have made reasonable architectural and design choices to mitigate these risks, but they cannot be completely eliminated.
One key early decision was to rely on a hybrid cloud-edge approach. This enables the use of the most sophisticated reasoning and planning models available, which should help reduce hallucinations. Simpler, more task-focused edge models are employed to further minimize LLM errors.
Another critical decision was to leverage LangChain’s capabilities, which allow sensitive information to be hidden from LLM tools and provided only at runtime. For instance, tool logic may require using the ID of the user who made a request. However, such values should generally not be controlled by the LLM. Allowing the LLM to manipulate the user ID could pose security and privacy risks. To mitigate this, I utilized the InjectedToolArg annotation.
Additionally, using large cloud-based LLMs incurs significant cloud costs, and the edge hardware required to run LLM edge models can be expensive. The combined operational and installation costs are likely prohibitive for the average user at this time. An industry-wide effort to “make LLMs as cheap as CNNs” is needed to bring home agents to the mass market.
It is important to be aware of these risks and understand that, despite these mitigations, we are still in the early stages of this project and home agents in general. Significant work remains to make these agents truly useful and trustworthy assistants.
Architecture and Design
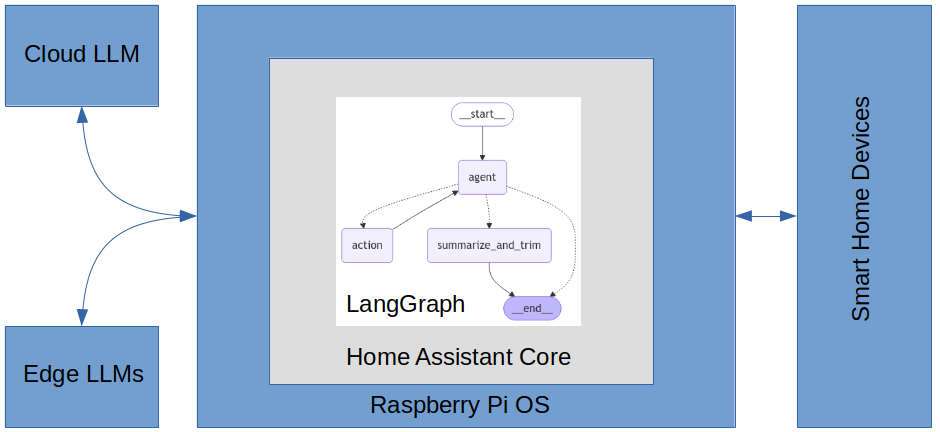
Below is a high-level view of the home-generative-agent architecture.
The agent is built using LangGraph and uses the HA conversation component to interact with the user. The agent uses the Home Assistant LLM API to fetch the state of the home and understand the HA native tools it has at its disposal. I implemented all other tools available to the agent using LangChain. The agent employs several LLMs, a large and very accurate primary model for high-level reasoning, smaller specialized helper models for camera image analysis, primary model context summarization, and embedding generation for long-term semantic search. The primary model is cloud-based, and the helper models are edge-based and run under the Ollama framework on a computer located in the home.
The models currently being used are summarized below.
GPT-4o | OpenAI Cloud | High-level reasoning and planning
mxbai-embed-large | Ollama Edge | Embedding generation for sematic search
LangGraph-based Agent
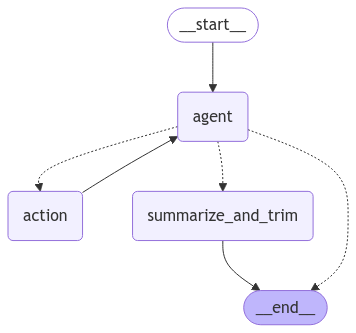
LangGraph powers the conversation agent, enabling you to create stateful, multi-actor applications utilizing LLMs as quickly as possible. It extends LangChain’s capabilities, introducing the ability to create and manage cyclical graphs essential for developing complex agent runtimes. A graph models the agent workflow, as seen in the image below.
Diagram by Lindo St. Angel
The agent workflow has five nodes, each Python module modifying the agent’s state, a shared data structure. The edges between the nodes represent the allowed transitions between them, with solid lines unconditional and dashed lines conditional. Nodes do the work, and edges tell what to do next.
The __start__ and __end__ nodes inform the graph where to start and stop. The agent node runs the primary LLM, and if it decides to use a tool, the action node runs the tool and then returns control to the agent. The summarize_and_trim node processes the LLM’s context to manage growth while maintaining accuracy if agent has no tool to call and the number of messages meets the below-mentioned conditions.
LLM Context Management
You need to carefully manage the context length of LLMs to balance cost, accuracy, and latency and avoid triggering rate limits such as OpenAI’s Tokens per Minute restriction. The system controls the context length of the primary model in two ways: it trims the messages in the context if they exceed a max parameter, and the context is summarized once the number of messages exceeds another parameter. These parameters are configurable in const.py; their description is below.
CONTEXT_MAX_MESSAGES | Messages to keep in context before deletion | Default = 100
CONTEXT_SUMMARIZE_THRESHOLD | Messages in context before summary generation | Default = 20
The summarize_and_trim node in the graph will trim the messages only after content summarization. You can see the Python code associated with this node in the snippet below.
async def _summarize_and_trim( state: State, config: RunnableConfig, *, store: BaseStore ) -> dict[str, list[AnyMessage]]: """Coroutine to summarize and trim message history.""" summary = state.get("summary", "")
if summary: summary_message = SUMMARY_PROMPT_TEMPLATE.format(summary=summary) else: summary_message = SUMMARY_INITIAL_PROMPT
# Trim message history to manage context window length. trimmed_messages = trim_messages( messages=state["messages"], token_counter=len, max_tokens=CONTEXT_MAX_MESSAGES, strategy="last", start_on="human", include_system=True, ) messages_to_remove = [m for m in state["messages"] if m not in trimmed_messages] LOGGER.debug("Messages to remove: %s", messages_to_remove) remove_messages = [RemoveMessage(id=m.id) for m in messages_to_remove]
The latency between user requests or the agent taking timely action on the user’s behalf is critical for you to consider in the design. I used several techniques to reduce latency, including using specialized, smaller helper LLMs running on the edge and facilitating primary model prompt caching by structuring the prompts to put static content, such as instructions and examples, upfront and variable content, such as user-specific information at the end. These techniques also reduce primary model usage costs considerably.
You can see the typical latency performance below.
HA intents (e.g., turn on a light) | < 1 second
Analyze camera image (initial request) | < 3 seconds
Add automation | < 1 second
Memory operations | < 1 second
Tools
The agent can use HA tools as specified in the LLM API and other tools built in the LangChain framework as defined in tools.py. Additionally, you can extend the LLM API with tools of your own as well. The code gives the primary LLM the list of tools it can call, along with instructions on using them in its system message and in the docstring of the tool’s Python function definition. You can see an example of docstring instructions in the code snippet below for the get_and_analyze_camera_image tool.
@tool(parse_docstring=False) async def get_and_analyze_camera_image( # noqa: D417 camera_name: str, detection_keywords: list[str] | None = None, *, # Hide these arguments from the model. config: Annotated[RunnableConfig, InjectedToolArg()], ) -> str: """ Get a camera image and perform scene analysis on it.
Args: camera_name: Name of the camera for scene analysis. detection_keywords: Specific objects to look for in image, if any. For example, If user says "check the front porch camera for boxes and dogs", detection_keywords would be ["boxes", "dogs"].
If the agent decides to use a tool, the LangGraph node action is entered, and the node’s code runs the tool. The node uses a simple error recovery mechanism that will ask the agent to try calling the tool again with corrected parameters in the event of making a mistake. The code snippet below shows the Python code associated with the action node.
async def _call_tools( state: State, config: RunnableConfig, *, store: BaseStore ) -> dict[str, list[ToolMessage]]: """Coroutine to call Home Assistant or langchain LLM tools.""" # Tool calls will be the last message in state. tool_calls = state["messages"][-1].tool_calls
The LLM API instructs the agent always to call tools using HA built-in intents when controlling Home Assistant and to use the intents `HassTurnOn` to lock and `HassTurnOff` to unlock a lock. An intent describes a user’s intention generated by user actions.
You can see the list of LangChain tools that the agent can use below.
get_and_analyze_camera_image | run scene analysis on the image from a camera
upsert_memory | add or update a memory
add_automation | create and register a HA automation
get_entity_history | query HA database for entity history
Hardware
I built the HA installation on a Raspberry Pi 5 with SSD storage, Zigbee, and LAN connectivity. I deployed the edge models under Ollama on an Ubuntu-based server with an AMD 64-bit 3.4 GHz CPU, Nvidia 3090 GPU, and 64 GB system RAM. The server is on the same LAN as the Raspberry Pi.
Results
I’ve been using this project at home for a few weeks and have found it useful but frustrating in a few areas that I will be working on to address. Below is a list of pros and cons of my experience with the agent.
Pros
The camera image scene analysis is very useful and flexible since you can query for almost anything and not have to worry having the right classifier as you would for a traditional ML approach.
Automations are very easy to setup and can be quite complex. Its mind blowing how good the primary LLM is at generating HA-compliant YAML.
Latency in most cases is quite acceptable.
Its very easy to add additional LLM tools and graph states with LangChain and LangGraph.
Cons
The camera image analysis seems less accurate than traditional ML approaches. For example, detecting packages that are partially obscured is very difficult for the model to handle.
The primary model clould costs are high. Running a single package detector once every 30 mins costs about $2.50 per day.
Using structured model outputs for the helper LLMs, which would make downstream LLM processing easier, considerably reduces accuracy.
The agent needs to be more proactive. Adding a planning step to the agent graph will hopefully address this.
Example Use Cases
Here are a few examples of what you can do with the home-generative-agent (HGA) integration as illustrated by screenshots of the Assist dialog taken by me during interactions with my HA installation.
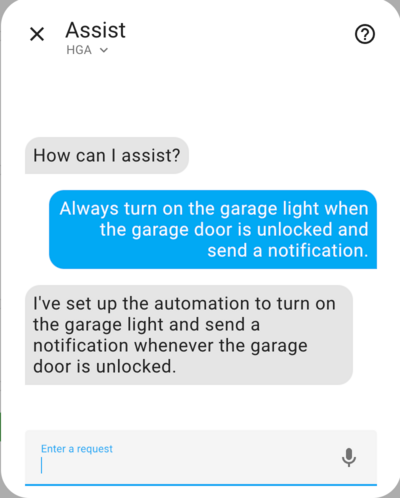
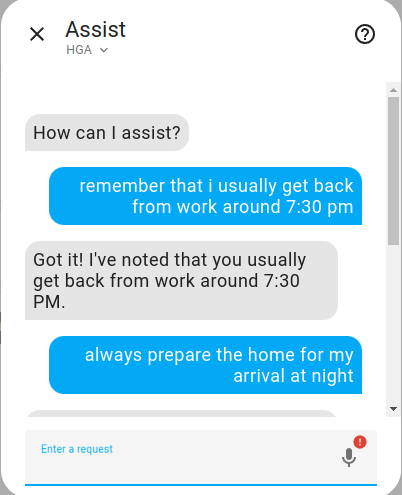
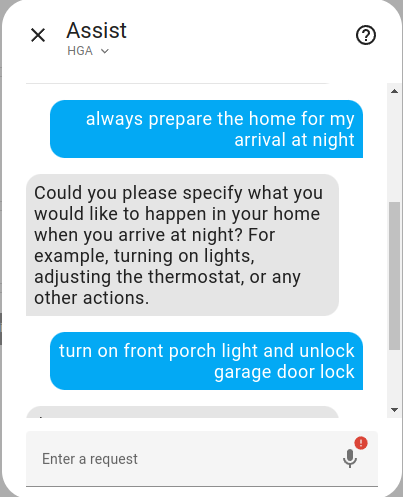
Create an Automation.
Image by Lindo St. Angel
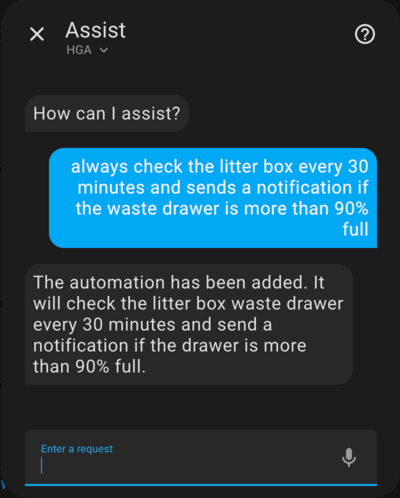
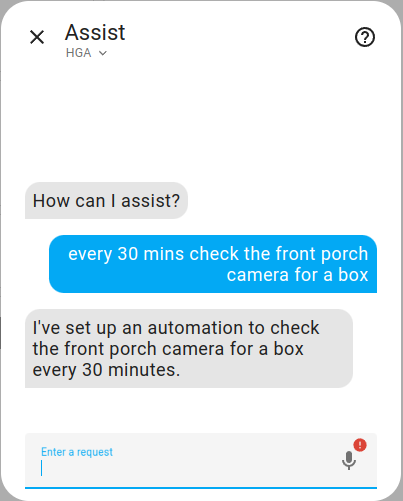
Create an automation that runs periodically.
Image by Lindo St. Angel
The snippet below shows that the agent is fluent in YAML based on what it generated and registered as an HA automation.
alias: Check Litter Box Waste Drawer triggers: - minutes: /30 trigger: time_pattern conditions: - condition: numeric_state entity_id: sensor.litter_robot_4_waste_drawer above: 90 actions: - data: message: The Litter Box waste drawer is more than 90% full! action: notify.notify
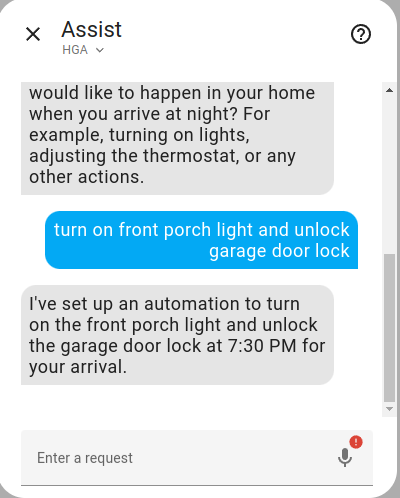
You can see that the agent correctly generates the automation below.
alias: Prepare Home for Arrival description: Turn on front porch light and unlock garage door lock at 7:30 PM mode: single triggers: - at: "19:30:00" trigger: time actions: - target: entity_id: light.front_porch_light action: light.turn_on data: {} - target: entity_id: lock.garage_door_lock action: lock.unlock data: {}
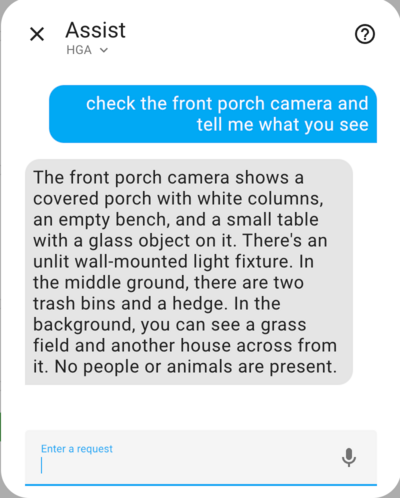
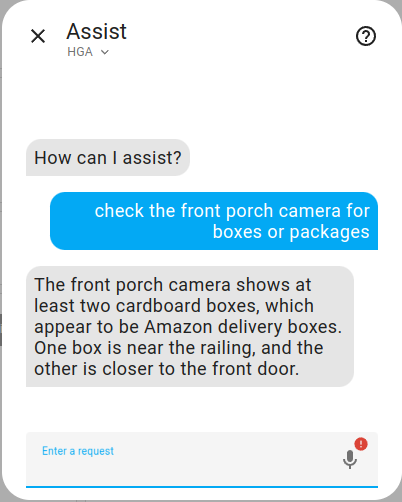
Check a camera for packages.
Image by Lindo St. Angel
Below is the camera image the agent analyzed, you can see that two packages are visible.
Photo by Lindo St. Angel
Proactive notification of package delivery.
Image by Lindo St. Angel
Below is an example notification from this automation if any boxes or packages are visible.
Image by Lindo St. Angel
Conclusions
The Home Generative Agent offers an intriguing way to make your Home Assistant setup more user-friendly and intuitive. By enabling natural language interactions and simplifying automation, it provides a practical and useful tool for everyday smart home use.
Using a home generative agent carries security, privacy and cost risks that need further mitigation and innovation before it can be truly useful for the mass market.
Whether you’re new to Home Assistant or a seasoned user, this integration is a great way to enhance your system’s capabilities and get familiar with using generative AI and agents at home. If you’re interested in exploring its potential, visit the Home Generative Agent GitHub page and get started today.
Appendix
Installation
1. Using the tool of choice, open your HA configuration’s directory (folder) (where you find configuration.yaml).
2. If you do not have a `custom_components` directory (folder), you must create it.
3. In the custom_components directory (folder), create a new folder called home_generative_agent.
4. Download _all_ the files from the custom_components/home_generative_agent/ directory (folder) in this repository.
4. Place the files you downloaded in the new directory (folder) you created.
6. Restart Home Assistant
7. In the HA UI, go to “Configuration” -> “Integrations” click “+,” and search for “Home Generative Agent”
Configuration
Configuration is done in the HA UI and via the parameters in const.py.
We tested the best sports watches that capture your metrics for recovery, sleep, and detailed training guidance without a coach. Here’s how to choose the right one for you.
The NYT Mini crossword might be a lot smaller than a normal crossword, but it isn’t easy. If you’re stuck with today’s crossword, we’ve got answers for you here.
Connections is the new puzzle game from the New York Times, and it can be quite difficult. If you need a hand with solving today’s puzzle, we’re here to help.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.