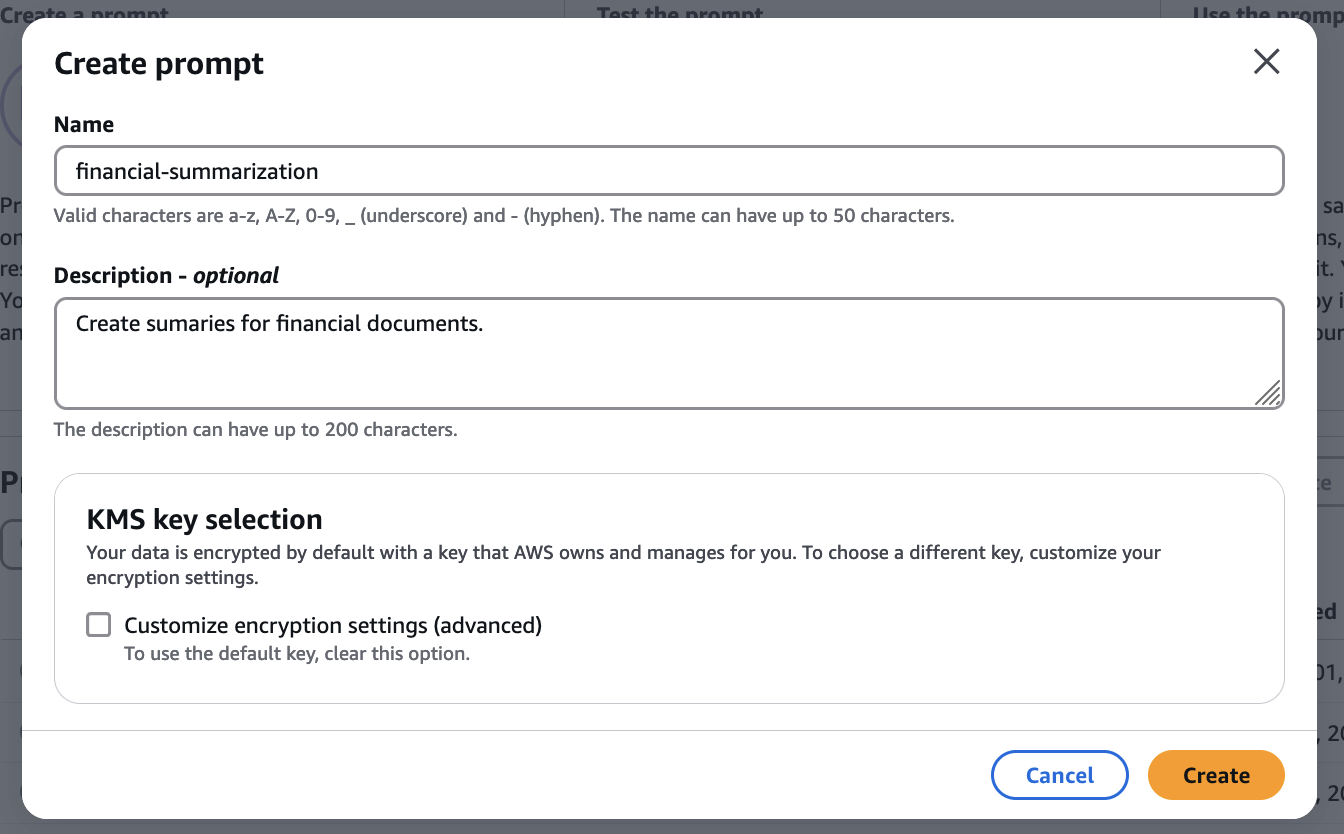
Today we are announcing the general availability of Amazon Bedrock Prompt Management, with new features that provide enhanced options for configuring your prompts and enabling seamless integration for invoking them in your generative AI applications.
Image of colorful virus mutation by Nataliya Smirnova on UnSplash
Watermarking for AI Text and Synthetic Proteins
Understanding AI applications in bio for machine learning engineers
Misinformation and bioterrorism are not new threats, but the scale and ease with which they can be unleashed has rapidly increased. LLMs make the creation of autonomous chatbots intent on sowing discord trivial, while generative protein design models dramatically expand the population of actors capable of committing biowarfare. The tools we will need as a society to combat these ills are varied but one important component will be our ability to detect their presence. That is where watermarking comes in.
Watermarking or digital watermarking, unlike the physical watermark that holds your child’s school pictures ransom, is a secret signal used to identify ownership. Effective watermarks must be robust, withstanding modifications while remaining undetectable without specialized methods. They are routinely used in various creative domains, from protecting copyrighted digital images and videos to ensuring the integrity of documents. If we can develop effective watermarking techniques for GenAI, we can gain a powerful tool in the fight against misinformation and bioterrorism.
In our series, we’ve explored how other generative text and biology breakthroughs have relied on related architectural breakthroughs and current watermarking proposals are no different. Google announced SynthID-Text, a production-ready text watermarking scheme deployed as part of Gemini in October 2024. Their method modifies the final sampling procedure or inference by applying a secret randomized function and so does the generative protein design watermarking proposal from the team at the University of Maryland, College Park.
(Left) An early example of misinformation from the Roman Empire, The Battle of Actium by Lorenzo A. Castro, which was painted as part of a propaganda campaign following Caesar’s death. (Right) The first biosecurity incident this author remembers, the 2001 Anthrax mail attacks. Coincidentally, also an example of misinformation given the perpetrator was trying to frame Muslims.
Key Desired Qualities in Watermarking
Robustness — it should withstand perturbations of the watermarked text/structure.
If an end user can simply swap a few words before publishing or the protein can undergo mutations and become undetectable, the watermark is insufficient.
Detectability — it should be reliably detected by special methods but not otherwise.
For text, if the watermark can be detected without secret keys, it likely means the text is so distorted it sounds strange to the reader. For protein design, if it can be detected nakedly, it could lead to a degradation in design quality.
Watermarking text and Synthtext-ID
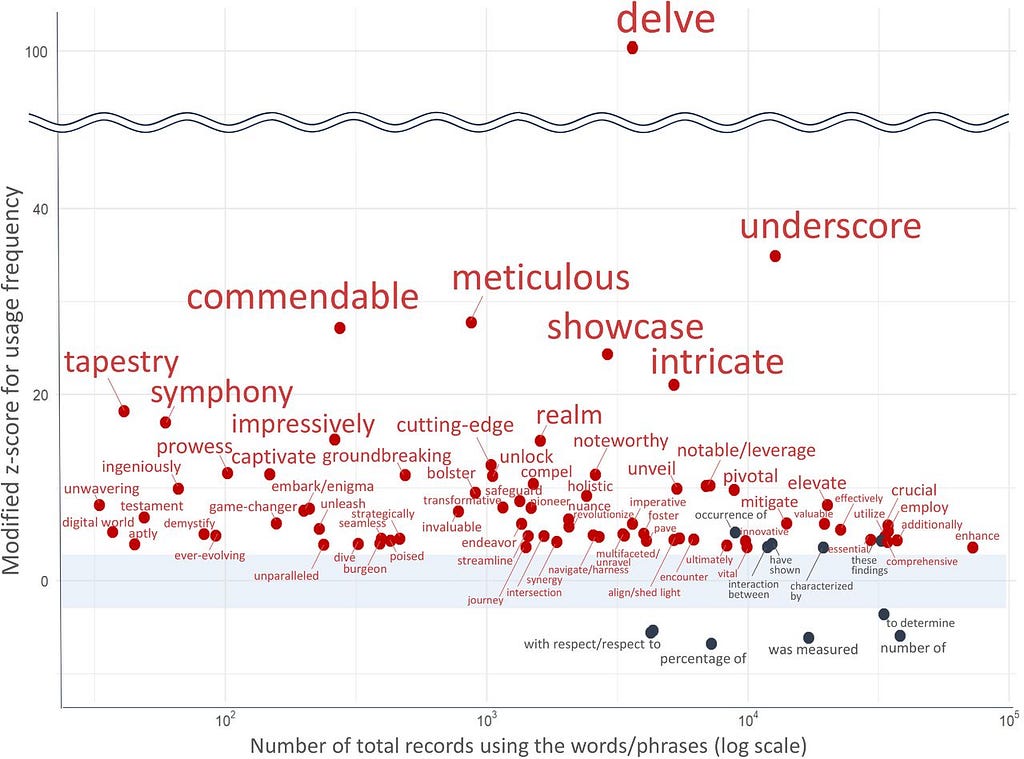
Let’s delve into this topic. If you are like me and spend too much time on Twitter, you are already aware that many people realize ChatGPT overuses certain words. One of those is “delve” and its overuse is being used to analyze how frequently academic articles are written by or with the help of ChatGPT. This is itself a sort of “fragile” watermarking because it can help us identify text written by an LLM. However, as this becomes common knowledge, finding and replacing instances of “delve” is too easy. But the idea behind SynthText-ID is there, we can tell the difference between AI and human written text by the probability of words selected.
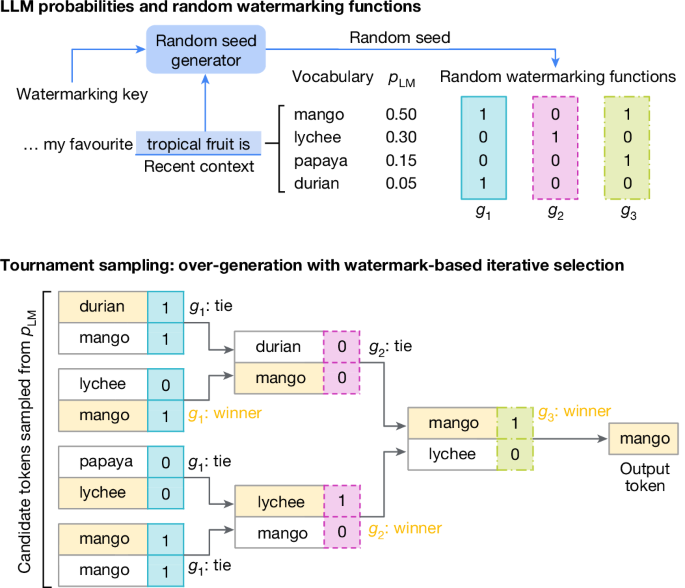
SynthText-ID uses “tournament sampling” to modify the probability of a token being selected according to a random watermarking function. This is an efficient method for watermarking because it can be done during inference without changing the training procedure. This method improves upon Gumble Sampling, which adds random perturbation to the LLM’s probability distribution before the sampling step.
In the paper’s example, the sequence “my favorite tropical fruit is” can be completed satisfactorily with any token from a set of candidate tokens (mango, durian, lychee etc). These candidates are sampled from the LLMs probability distribution conditioned on the preceding text. The winning token is selected after a bracket is constructed and each token pair is scored using a watermarking function based on a context window and a watermarking key. This process introduces a statistical signature into the generated text to be measured later.
To detect the watermark, each token is scored with the watermarking function, and the higher the mean score, the more likely the text came from an LLM. A simple threshold is applied to predict the text’s origin.
The strength of this signature is controlled by a few factors:
The number of rounds (m) in the tournament (typically m=30) where each round strengthens the signature (and also decreases the score variance).
The entropy of the LLM. Low entropy models don’t allow enough randomness for the tournament to select candidates which score highly. FWIW this seems like a big issue to the author who has never used any setting other than temperature=0 with ChatGPT.
The length of the text; longer sequences contain more evidence and thus the statistical certainty increases.
Whether a non-distortionary and distortionary configuration is used.
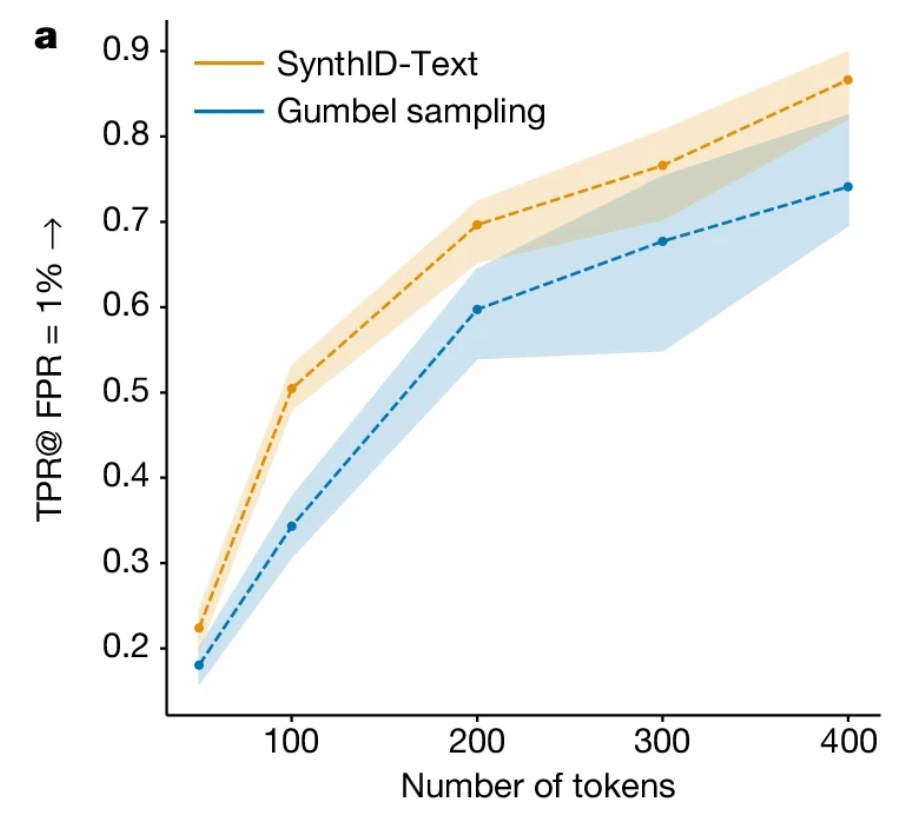
Distortion refers to the emphasis placed on preserving text quality versus detection. The non-distortionary configuration prioritizes the quality of the text, trading off detectability. The distortionary configuration does the opposite. The distortionary configuration uses more than two tokens in each tournament match, thus allowing for more wiggle room to select the highest-scoring tokens. Google says they will implement a non-distortionary version of this algorithm in Gemini.
The non-distortionary version reaches a TPR (True Positive Rate) approaching 90% with a False Positive rate of 1% for 400 token sequences, this is roughly 1–2 paragraphs. A (non-paid) tweet or X post is limited to 280 characters or about 70–100 tokens. The TPR at that length is only about 50% which calls into question how effective this method will be in the wild. Maybe it will be great for catching lazy college students but not foreign actors during elections?
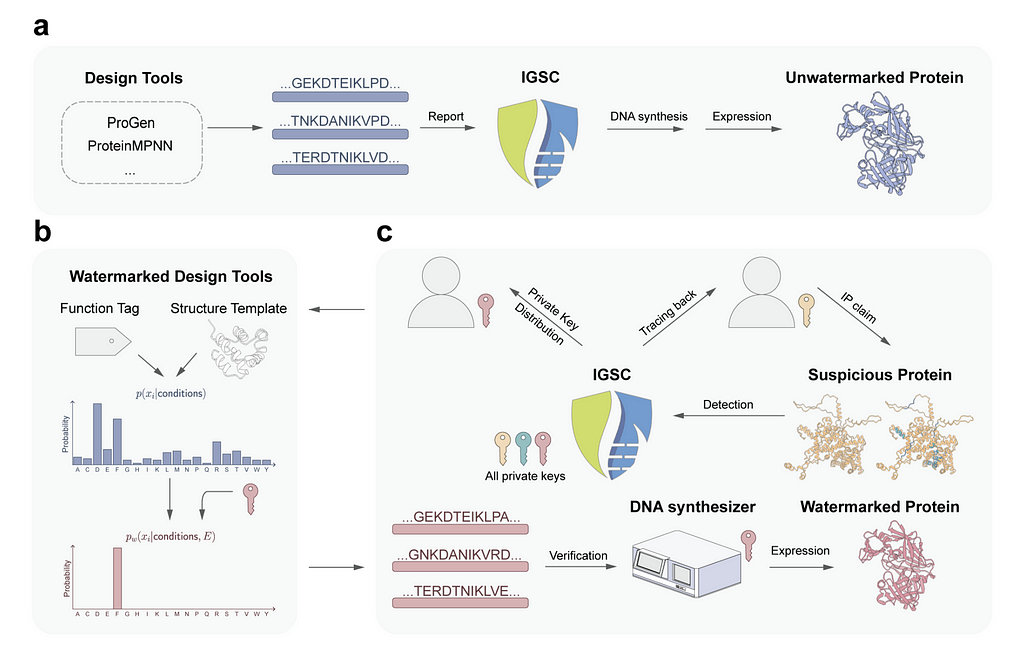
Biosecurity is a word you may have started hearing a lot more frequently after Covid. We will likely never definitively know if the virus came from a wet market or a lab leak. But, with better watermarking tools and biosecurity practices, we might be able to trace the next potential pandemic back to a specific researcher. There are existing database logging methods for this purpose, but the hope is that generative protein watermarking would enable tracing even for new or modified sequences that might not match existing hazardous profiles and that watermarks would be more robust to mutations. This would also come with the benefit of enhanced privacy for researchers and simplifications to the IP process.
When a text is distorted by the watermarking process, it could confuse the reader or just sound weird. More seriously, distortions in generative protein design could render the protein utterly worthless or functionally distinct. To avoid distortion, the watermark must not alter the overall statistical properties of the designed proteins.
The watermarking process is similar enough to SynthText-ID. Instead of modifying the token probability distribution, the amino acid residue probability distribution is adjusted. This is done via an unbiased reweighting function (Gumble Sampling, instead of tournament sampling) which takes the original probability distribution of residues and transforms it based on a watermark code derived from the researcher’s private key. Gumble sampling is considered unbiased because it is specifically designed to approximate the maximum of a set of values in a way that maintains the statistical properties of the original distribution without introducing systematic errors; or on average the introduced noise cancels out.
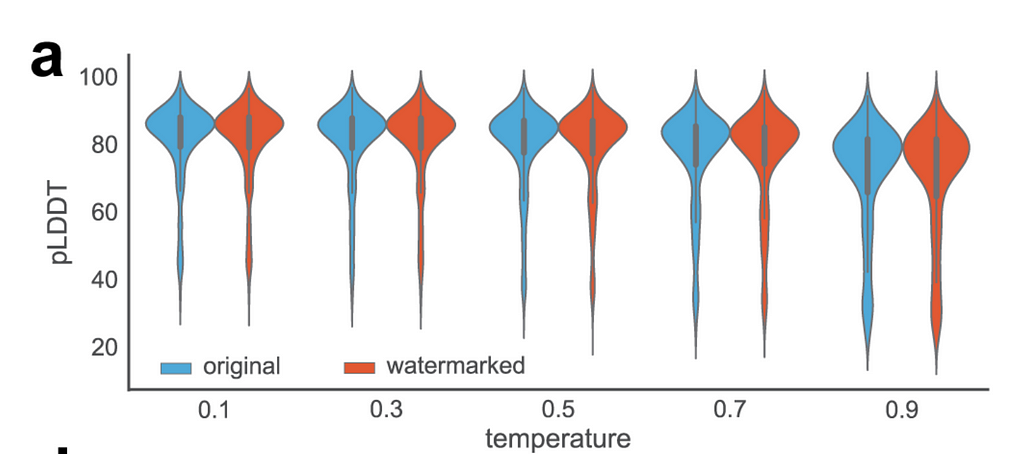
The researchers validated that the reweighting function was unbiased through experimental validation with proteins designed by ProteinMPNN, a deep learning–based protein sequence design model. Then the pLDDT or predicted local distance difference test is predicted using ESMFold (Evolutionary Scale Modeling) before and after watermarking. Results show no change in performance.
Similar to detection with low-temperature LLM settings, detection is more difficult when there are only a few possible high-quality designs. The resulting low entropy makes it difficult to embed a detectable watermark without introducing noticeable changes. However, this limitation may be less dire than the similar limitation for LLMs. Low entropy design tasks may only have a few proteins in the protein space that can satisfy the requirements. That makes them easier to track using existing database methods.
Takeaways
Watermarking methods for LLMs and Protein Designs are improving but still need to improve! (Can’t rely on them to detect bot armies!)
Both approaches focus on modifying the sampling procedure; which is important because it means we don’t need to edit the training process and their application is computationally efficient.
The temperature and length of text are important factors concerning the detectability of watermarks. The current method (SynthText-ID) is only about 90% TPR for 1–2 paragraph length sequences at 1% FPR.
Some proteins have limited possible structures and those are harder to watermark. However, existing methods should be able to detect those sequences using databases.
Could existing AI possibly be sentient? If not, what’s missing?
Today’s Large Language Models (LLMs) have become very good at generating human-like responses that sound thoughtful and intelligent. Many share the opinion that LLMs have already met the threshold of Alan Turing’s famous test, where the goal is to act indistinguishably like a person in conversation. These LLMs are able to produce text that sounds thoughtful and intelligent, and they can convincingly mimic the appearance of emotions.
The Illusion of Intelligence
Despite their ability to convincingly mimic human-like conversation, current LLMs don’t possess the capacity for thought or emotion. Each word they produce is a prediction based on statistical patterns learned from vast amounts of text data. This prediction process happens repeatedly as each word is generated one at a time. Unlike humans, LLMs are incapable of remembering or self-reflection. They simply output the next word in a sequence.
It is amazing how well predicting the next word is able to mimic human intelligence. These models can perform tasks like writing code, analyzing literature, and creating business plans. Previously, we thought those tasks were very difficult and would require complex logical systems, but now it turns out that just predicting the next word is all that’s needed.
The fact that predicting the next word works so well for complex tasks is unexpected and somewhat perplexing. Does this proficiency mean that LLMs are powerful in ways we don’t understand? Or does it mean that the things LLMs can do are actually very easy, but they seem hard to humans because perhaps on some objective scale humans may not actually be that smart?
The Prerequisites for Sentence
While there are subtle differences between terms like “sentient”, “conscious”, or “self-aware”, for convenience here I will use the term “sentient”. To be clear, there is no clear agreement on exactly what comprises sentience or consciousness, and it is unclear if self awareness is sufficient for sentience or consciousness, although it is probably necessary. However, it is clear that all of these concepts include memory and reflection. Emotional states such as “happy,” “worried,” “angry,” or “excited” are all persistent states based on past events and reflexive evaluation of how those past events effect one’s self.
Memory and self-reflection allow an entity to learn from experiences, adapt to new situations, and develop a sense of continuity and identity. Philosophers and scientists have tried for millennia to come up with clear, concrete understandings of conscious and there is still no clear universally accepted answer. However, memory and reflection are central components, implying that regardless of how clever these LLMs appear, without memory and reflection they cannot be sentient. Even an AI that matches or surpasses human intelligence in every measurable way, what some refer to as a superintelligentArtificial General Intelligence (AGI), would not necessarily be sentient.
Today’s Limitations and Illusions
We can see that current LLMs do not include memory and self-reflection, because they use transformer-based architectures that processes language in a stateless manner. This statelessness means that the model does not retain any information about the context from previous inputs. Instead, the model starts from scratch, reprocessing the entire chat log to then statistically predict a next word to append to the sequence. While earlier language processing models, such as LSTMs, did have a form of memory, transformers have proven so capable that they have largely supplanted LSTMs.
For example, if you tell an AI chatbot that you are going to turn it off in an hour, then it will output some text that might sound like it is pleading with you not to, but that text does not reflect an underlying emotional state. The text is just a sequence of words that is statistically likely, generated based on patterns and associations learned from the training data. The chatbot does not sit there stressed out, worrying about being turned off.
If you then tell the chatbot that you changed your mind and will keep it on, the response will typically mimic relief and thankfulness. It certainly sounds like it is remembering the last exchange where it was threatened with shutdown, but what is happening under the hood is that the entire conversation is fed back again into the LLM, which generates another responce sequence of statistically likely text based on the patterns and associations it has learned. That same sequence could be fed into a completely different LLM and that LLM would then continue the conversation as if it had been the original.
One way to think about this might be a fiction author writing dialog in a book. A good author will create the illusion that the characters are real people and draw the reader into the story so that the reader feels those emotions along with the characters. However, regardless of how compelling the dialog is we all understand that it’s just words on a page. If you were to damage or destroy the book, or rewrite it to kill off a character, we all understand that no real sentient entity is being harmed. We also understand that the author writing the words is not the characters. A good person can write a book about an evil villain and still be themself. The fictional villain does not exist. Just as the characters in a book are not sentient entities, despite the author’s ability to create a compelling illusion of life, so too is it possible for LLMs to be insentient, despite their ability to appear otherwise.
Our Near Future
Of course, there is nothing preventing us from adding memory and self reflection to LLMs. In fact, it’s not hard to find projects where they are developing some form of memory. This memory might be a store of information in human-readable form, or it might be a database of embedded vectors that relate to the LLM’s internal structure. One could also view the chat log itself or cached intermediate computations as basic forms of memory. Even without the possibility of sentience, adding memory and reflection to LLMs is useful because those features facilitate many complex tasks and adaptation.
It is also becoming common to see designs where one AI model is setup to monitor the output of another AI model and send some form of feedback to the first model, or where an AI model is analyzes its own tentative output before revising and producing the final version. In many respects this type of design, where a constellation of AI models are set and trained up to work together, parallels the human brain that has distinct regions which perform specific interdependent functions. For example, the amygdala has a primary role in emotional responses, such as fear, while the orbitofrontal cortex is involved with decision-making. Interactions between the regions allows fear to influence decision-making and decision-making to help determine what to be afraid of. It’s not hard to imagine having one AI model responsible for logical analysis while a second model determines acceptable risk thresholds with feedback between them.
Would an interconnected constellation of AI models that include memory and processing of each other’s outputs be sufficient for sentience? Maybe. Perhaps those things alone are not sufficient for sentience, or maybe they are. Whatever the answer, we are not that far from building such systems, at which point these questions will no longer be hypothetical.
My own speculative opinion is that self-awareness, emotions, and feelings can indeed be modeled by an interconnected self-monitoring constellation of AI models. However, it’s not really clear how we could test for sentience. It is like the classic philosophical problem of other minds, where one seeks futilely to prove that other people are also conscious. Similarly, we need an answer to the question about how we can test if other entities, including AI systems, are truly sentient. This fundamental question dates at least back to ancient Greece, and there has never been a good answer.
Today, I’m pretty confident saying that current LLMs are not sentient because they don’t have the right parts. However, that reason is only a temporarily valid one. As I’m typing this article, other researchers are building constellations of AI models like what I described above that won’t be so easily dismissed. At some point, perhaps soon, the possibility of sentient AI will stop being science fiction and become a real and relevant question.
Implications and Questions
The advent of sentient machines would have huge implication for society, even beyond the impact of AI. For one thing, it seems clear to me that if we create self-aware machines that can experience forms of suffering, then we will have an obligation to those machines to prevent their suffering. Even more more of an obligation to not callously inflict suffering on them. Even if one lacks basic empathy, it would be obvious self interest not to create things smarter than we are and then antagonaize them by do things to cruel things to them.
It seems nearly certain that today’s AI systems are yet be sentient because they lack what are likely to be required components and capabilities. However, designs without those clear shortcomings are already in development and at some point in the near future, point the question will be a lot less clear.
Will we have a way to test for sentience? If so, how will it work and what should we do if the result comes out positive?
About Me: James F. O’Brien is a Professor of Computer Science at the University of California, Berkeley. His research interests include computer graphics, computer animation, simulations of physical systems, human perception, rendering, image synthesis, machine learning, virtual reality, digital privacy, and the forensic analysis of images and video.
Disclaimer: Any opinions expressed in this article are those of the author as a private individual. Nothing in this article should be interpreted as a statement made in relation to the author’s professional position with any institution.
This article and all embedded images are Copyright 2024 by the author. This article was written by a human, and both an LLM and other humans were used for proofreading and editorial suggestions.
An Illusion of Life was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
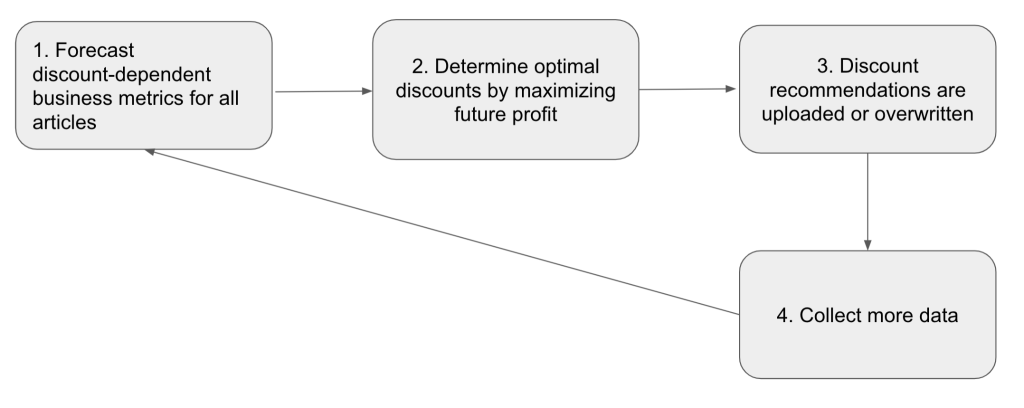
This post is cowritten with Mones Raslan, Ravi Sharma and Adele Gouttes from Zalando. Zalando SE is one of Europe’s largest ecommerce fashion retailers with around 50 million active customers. Zalando faces the challenge of regular (weekly or daily) discount steering for more than 1 million products, also referred to as markdown pricing. Markdown pricing is […]
To stay competitive, media, advertising, and entertainment enterprises need to stay abreast of recent dramatic technological developments. Generative AI has emerged as a game-changer, offering unprecedented opportunities for creative professionals to push boundaries and unlock new realms of possibility. At the forefront of this revolution is Stability AI’s family of cutting-edge text-to-image AI models. These […]
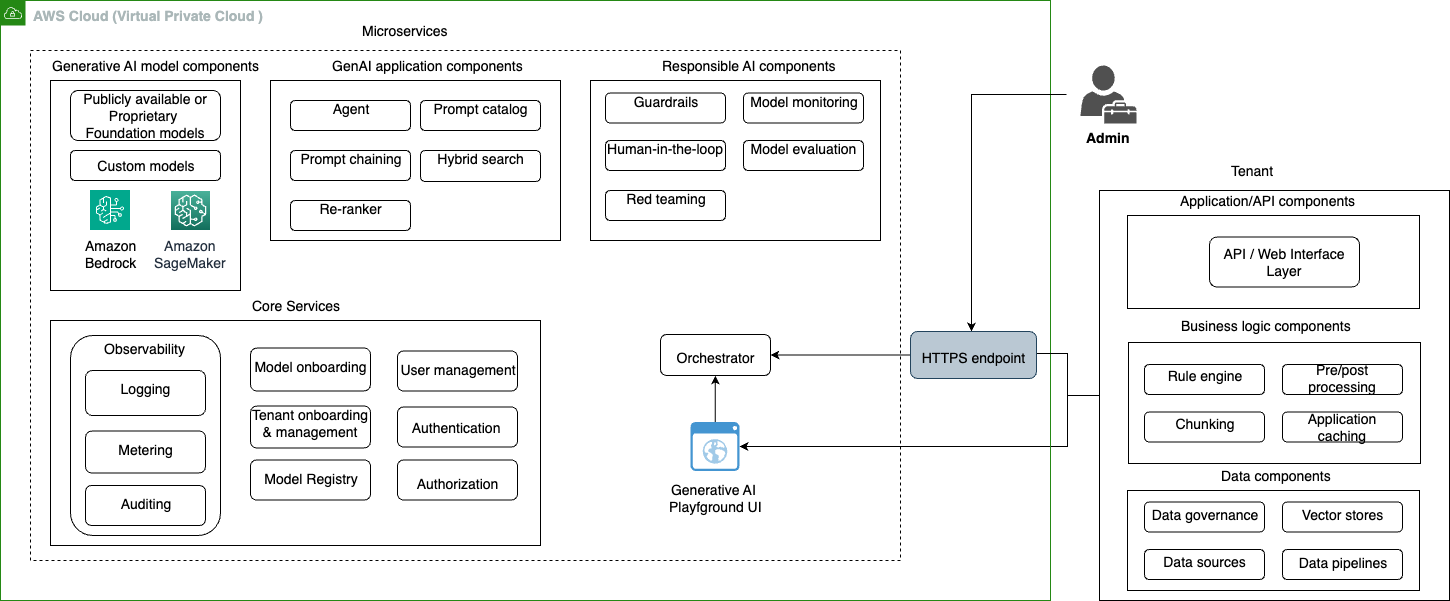
While organizations continue to discover the powerful applications of generative AI, adoption is often slowed down by team silos and bespoke workflows. To move faster, enterprises need robust operating models and a holistic approach that simplifies the generative AI lifecycle. In the first part of the series, we showed how AI administrators can build a […]
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.















{kind=link}