
Learn how to evaluate probabilistic forecasts and how CRPS relates to other metrics
Originally appeared here:
Essential Guide to Continuous Ranked Probability Score (CRPS) for Forecasting
Learn how to evaluate probabilistic forecasts and how CRPS relates to other metrics
Originally appeared here:
Essential Guide to Continuous Ranked Probability Score (CRPS) for Forecasting
Exploring Rule Metric Offerings and Suggesting Improvements
Originally appeared here:
Monitoring Amazon EventBridge Rules
Go Here to Read this Fast! Monitoring Amazon EventBridge Rules

Originally appeared here:
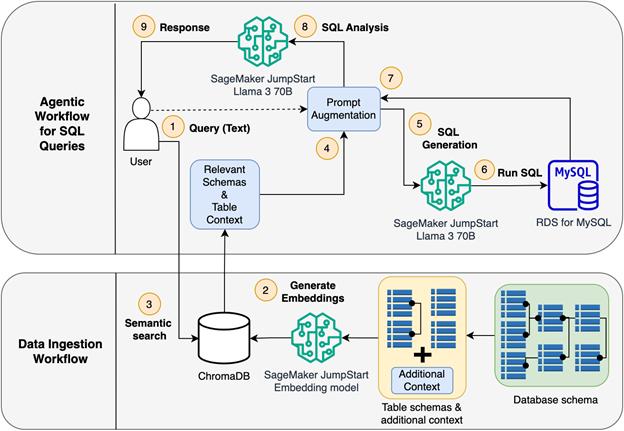
Best practices for prompt engineering with Meta Llama 3 for Text-to-SQL use cases

Originally appeared here:
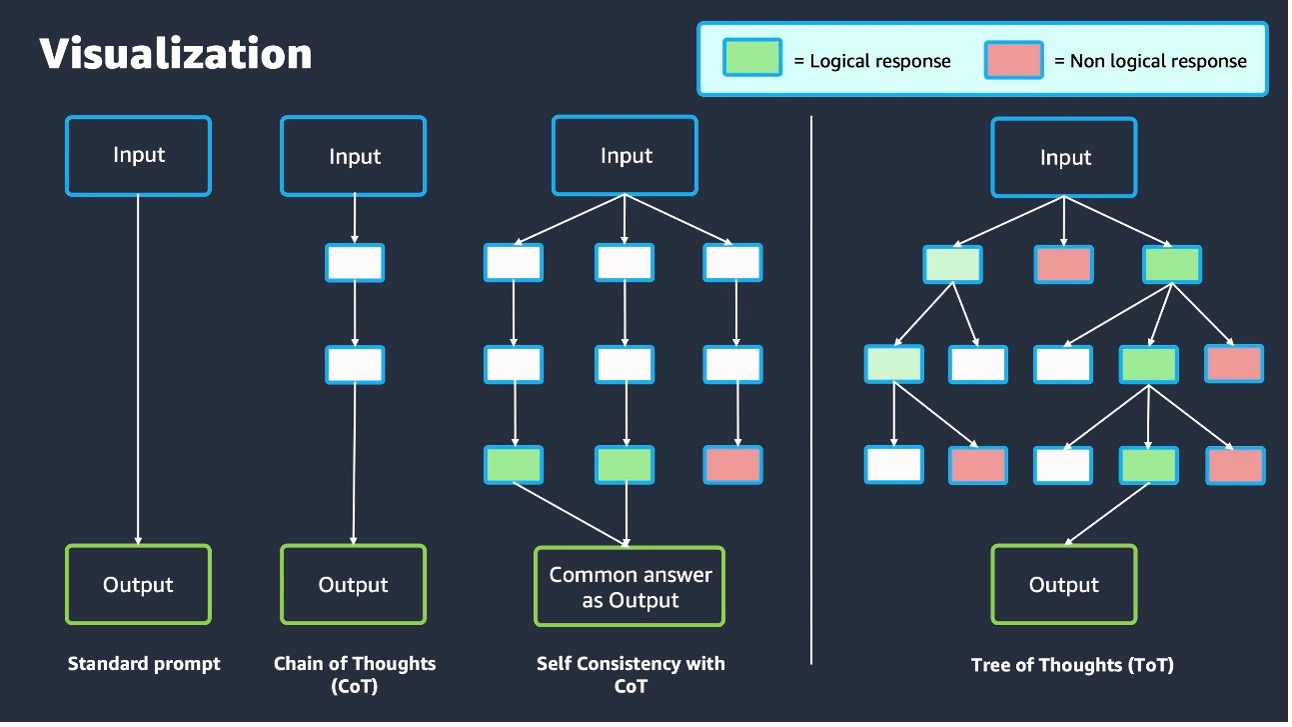
Implementing advanced prompt engineering with Amazon Bedrock
Go Here to Read this Fast! Implementing advanced prompt engineering with Amazon Bedrock
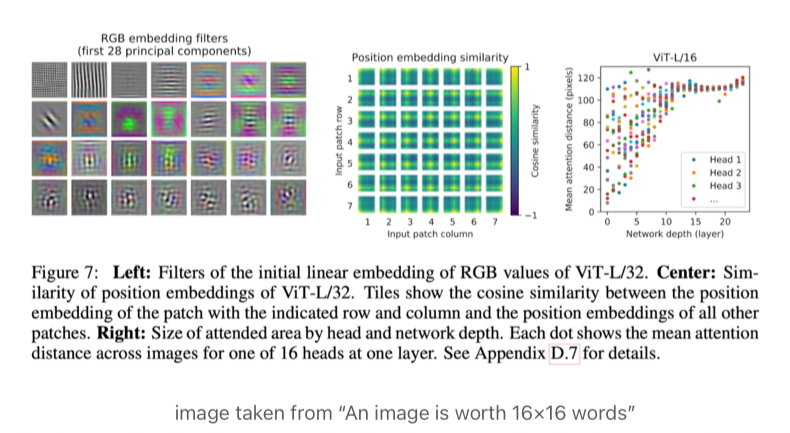
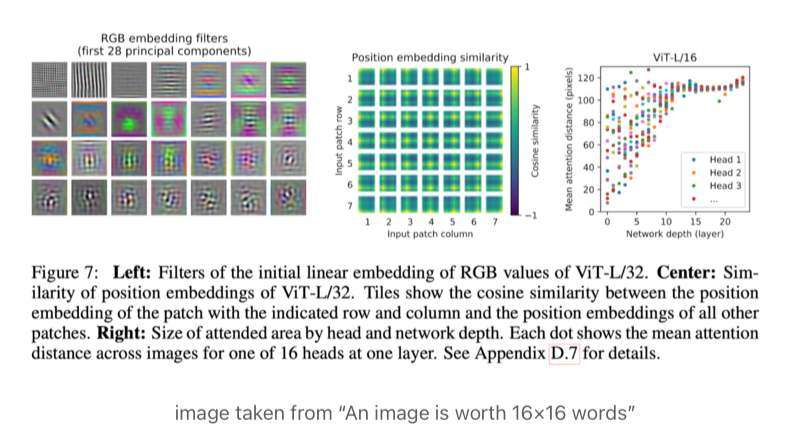
A comprehensive guide to the Vision Transformer (ViT) that revolutionized computer vision.
Originally appeared here:
The Ultimate Guide to Vision Transformers
Go Here to Read this Fast! The Ultimate Guide to Vision Transformers


How AI can accelerate your ML projects from feature engineering to model training
Originally appeared here:
ChatGPT vs. Claude vs. Gemini for Data Analysis (Part 3): Best AI Assistant for Machine Learning


A 4-step tutorial on creating a SageMaker endpoint and calling it.
Originally appeared here:
Deploy Models with AWS SageMaker Endpoints — Step by Step Implementation
Go Here to Read this Fast! Deploy Models with AWS SageMaker Endpoints — Step by Step Implementation

Retrieval Augmented Generation (RAG) is a powerful technique that can improve the accuracy and reliability of the answer generated by Large Language Models (LLMs). It also offers the possibility of checking the sources used by the model during a particular generation, allowing easier fact-checking by human users. Furthermore, RAG makes it possible to keep the model knowledge up-to-date and incorporate topic-specific information without the need for fine-tuning. Overall, RAG provides many benefits and few drawbacks, and its workflow is straightforward to implement. Because of this, it has become the go-to solution for many LLM use cases that require up-to-date and/or specialized knowledge.
Some of the latest developments in the Generative AI field have focused on extending the popular transformer architecture to tackle multiple input and/or output modalities, trying to replicate the huge success of LLMs. There are already several models, both open and closed source, that have demonstrated a remarkable ability to handle multiple modalities. A popular multimodal setting, and one of the first to be tackled, is that of Vision Language Models (VLMs), which has seen interesting open-source contributions with the release of small yet powerful models like LLaVA, Idefics, and Phi-vision. If you want to get started with VLMs and learn more about building a Vision Language Chat Assistant using LLaVA, you can look at my previous post Create your Vision Chat Assistant with LLaVA.
Designing RAG systems for multimodal models is more challenging than in the text-only case. In fact, the design of RAG systems for LLM is well-established and there is some consensus about the general workflow, as many of the recent developments focus on improving accuracy, reliability, and scalability rather than fundamentally changing the RAG architecture. On the other hand, multimodality opens up multiple ways of retrieving relevant information and, consequentially, there are several different architectural choices that can be made, each with its own advantages and drawbacks. For example, it is possible to use a multimodal embedding model to create a shared vector space for the different modalities or, instead, choose to ground the information in one modality only.
In this blog post, I will discuss a simple framework to extend RAG to Vision Language Models (VLMs), focusing on the Visual Question Answering task. The core idea of the method is to exploit the capabilities of the VLM to understand both text and images to generate a suitable search query that will be used to retrieve external information before answering the user’s prompt.
I will also provide a practical tutorial on how to implement the framework to empower Phi-3.5-vision with access to Wikipedia information, discussing the main points of the implementation and showing some examples. I will leave the details to the full code I shared in the following Git Hub repo.
In this section, I will describe the general workflow of the framework mentioned in the introduction. For the sake of exposition, I will discuss the case where there is only one user’s prompt about one image. This is the case, for example, for simple Visual Question Answering (VQA) tasks. The method can be generalized straightforwardly to multiple prompts and images, but the pipeline will become more complex and introduce further complications. Furthermore, I will only consider the case in which the external data consists solely of textual documents. Using a multimodal embedding model for retrieval, or more generally a multimodal search engine, it is possible to include images in the external data as well.
As for the usual RAG workflow, the framework workflow can be divided into two parts: retrieval of the relevant external information and generation conditioned on the provided external data.
During the retrieval phase, the goal is to retrieve some passages from the external text documents that can provide useful information to answer the user’s prompt. In order to do so effectively, we must ensure that the retrieved passages are relevant to the provided image, the prompt, and, more importantly, the relationship between the two. In fact, even if the retrieved documents contain information about the image, they may not include the specific information needed to provide an answer to the user’s prompt. On the other hand, the prompt may only be correctly understood when paired with the image it refers to. To address these challenges, the framework discussed in this post exploits the multimodal model to generate an appropriate search query, tailored to capture the information needed to answer the user’s prompt in the context of the provided image. A search engine will use the produced query to retrieve the relevant information from the external data.
In more detail, the multimodal model receives as input both the user’s prompt and the image and it is tasked with creating a search query that is relevant to both of them as a whole. This process can be seen as a special case of a query transformation, designed to consider the multimodal nature of the problem. In fact, the model translates the user’s prompt into a search query while also considering the image it refers to.
The advantage of this approach over other methods that treat each input modality separately, such as using a multimodal embedding model for retrieval or using a generated image caption/description for semantic similarity, is that it can capture the relationships between the prompt and the image more effectively.
The flowchart for the retrieval phase is sketched below.

The generation phase is very similar to the standard text-only RAG workflow, the only difference being that the model receives the image in its context in addition to the prompt and the retrieved passages. This process is illustrated below.
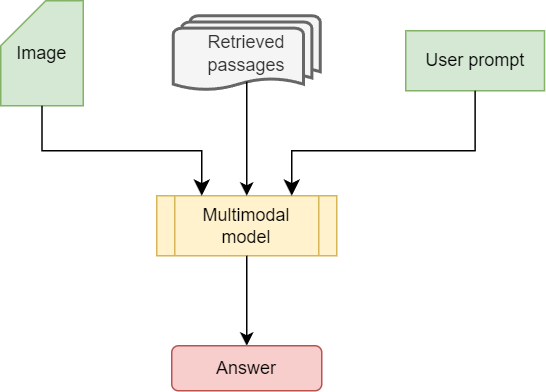
In this section, I will provide a practical guide on how to apply the discussed framework to enhance a multimodal model by giving it access to Wikipedia. I chose the model Phi-3.5-vision, as it is a very powerful yet lightweight open-source Vision Language Model.
In this section, I will discuss only the general aspects of the implementation, leaving the details to the code provided in the GitHub repo.
The goal of the retrieval phase is to gather some passages from Wikipedia that can provide useful information to answer a user’s question about an image. In the code implementation, I used the Python package wikipedia to search and retrieve content from Wikipedia.
Here are the steps implemented to retrieve the relevant passages:
The first step exploits Phi-3.5-vision to generate an appropriate search query that will be used to retrieve relevant Wikipedia pages. In order to do so, I tasked Phi-3.5-vision to produce keywords relevant to the user’s question and the image. I then used the built-in search function of the wikipedia package to retrieve some pages relevant to the generated keywords.
The general single-turn single-image chat template for Phi-vision-3.5 has the following structure:
<|user|>n
<|image_1|>n
{prompt}<|end|>n
<|assistant|>n
To generate the keywords I used the following prompt:
Your task is to write a few search keywords to find Wikipedia pages containing
the relevant information to answer the question about the provided image. The
keywords must be as specific as possible and must represent the information
that is needed to answer the question in relation to the provided image. Don't
write more than 3 search keywords.
Question: {question}
The tag {question} is substituted with the user question before inference.
After the keywords have been generated, the built-in search function of the wikipedia package is used to retrieve some pages relevant to the generated keywords. Finally, the selected pages are split into passages, and then the most relevant passages are selected using an embedding model and the LangChain implementation of the FAISS vector store. I used the embedding model snowflake-arctic-embed-l to embed the concatenation of the question and the keywords, and the chunks of the retrieved pages. In practice, the retrieval phase is effectively a form of “hybrid search” consisting of two sequential steps: keyword search using the built-in search function of the wikipedia package, and embedding similarity retrieval using an embedding model. In this way, the retrieval operates on the smaller space of the passages of the most relevant pages selected using keyword search, avoiding the need to build an enormous vector store with the embeddings of all the content of Wikipedia. In different settings, the retrieval phase could be remodeled to use similarity retrieval on the whole external corpus or using different combinations of retrieval methods.
Retrieving passages from multiple pages can help reduce the chance of selecting the wrong page and it can also be useful when information from multiple pages is needed to produce an answer.
In the generation phase, the user’s question, the retrieved passages, and the original images are used as inputs for Phi-3.5-vision to generate an answer.
I used the following prompt in the general chat template for Phi-3.5-vision:
You are a helpful assistant tasked with answering questions about the provided
image.
Answer the following question: {question}
You can use the following passages retrieved from Wikipedia to provide your
answer:
{passages}
At generation time, the tag {question} is substituted by the user question as before, while the tag {passages} is substituted by the retrieved passages and the names of the corresponding pages with the following format
From Wikipedia page {page_name} : "{passage1}"nn
From Wikipedia page {page_name} : "{passage2}"nn
From Wikipedia page {page_name} : "{passage3}"nn
...
Providing the name of the page from which the passage is extracted can help resolve ambiguities when the content of the latter is not enough to uniquely determine the subject or topic it refers to.
In this section, I will show some examples of answers obtained with the implementation discussed in the previous section, comparing the outputs of the Vision Language Model empowered with RAG with the base version.
For each example below, I will show the image provided to the model, a block with the question and the answers of both the RAG augmented and base VLM, a block with the search query created by the model, and a block with the passages retrieved from Wikipedia.

Question: How tall are the plants that produce this fruit?
Base VLM: Tomatoes are typically grown on plants that can reach heights of 2 to
4 feet, depending on the variety and growing conditions.
RAG VLM: The tomato plants that produce this fruit typically grow to 1-3 meters
(3-10 feet) in height.
The VLM generated the following search keywords:
Search keywords: tomato plant, tomato plant height
And retrieved the following passages:
From page Tomato (https://en.wikipedia.org/wiki/Tomato):
"throughout all seasons of the year. Tomato plants typically grow to 1–3
meters (3–10 ft) in height. They are vines that have a weak stem that sprawls
and typically needs support. Indeterminate tomato plants are perennials in
their native habitat, but are cultivated as annuals. (Determinate, or".
From page Tomato (https://en.wikipedia.org/wiki/Tomato):
"Numerous varieties of the tomato plant are widely grown in temperate climates
across the world, with greenhouses allowing for the production of tomatoes
throughout all seasons of the year. Tomato plants typically grow to 1–3 meters
(3–10 ft) in height. They are vines that have a weak stem that".
From page Early Girl (https://en.wikipedia.org/wiki/Early_Girl):
"== See also ==
List of tomato cultivars
== References ==".
From page Black Krim (https://en.wikipedia.org/wiki/Black_Krim):
"== References ==
== See also ==
List of tomato cultivars
Heirloom tomato".
From page Celebrity tomato (https://en.wikipedia.org/wiki/Celebrity_tomato):
"== See also ==
List of tomato cultivars
Tomato production in Florida
== References ==".
From page Fourth of July tomato
(https://en.wikipedia.org/wiki/Fourth_of_July_tomato):
"== See also ==
List of tomato cultivars
== References ==
== External links ==
Picture Gallery from Google Images".
From page Mortgage Lifter (https://en.wikipedia.org/wiki/Mortgage_Lifter):
"== See also ==
List of tomato cultivars
== References ==
== External links ==
Picture Gallery from Google Images".
The model augmented with RAG correctly reported the height range stated on the Wikipedia page ‘Tomato’, while the base model answered with a lower range.

Query: How much does this species weight?
Base VLM: Polar bears can weigh between 900 to 1,600 pounds
(408 to 727 kilograms).
RAG VLM: The weight of this species, the polar bear, ranges from 300-800 kg
(660-1,760 lb) for males and 150-300 kg (330-660 lb) for females.
Search keywords: polar bear, weight
From page Polar bear (https://en.wikipedia.org/wiki/Polar_bear):
"Males are generally 200–250 cm (6.6–8.2 ft) long with a weight of 300–800 kg
(660–1,760 lb). Females are smaller at 180–200 cm (5.9–6.6 ft) with a weight
of 150–300 kg (330–660 lb). Sexual dimorphism in the species is particularly
high compared with most other mammals. Male polar bears also have".
From page Polar bear (https://en.wikipedia.org/wiki/Polar_bear):
"== Notes ==
== References ==
== Bibliography ==
== External links ==
Polar Bears International website
ARKive—images and movies of the polar bear (Ursus maritimus)".
From page Polar bear (https://en.wikipedia.org/wiki/Polar_bear):
"weight of 150–300 kg (330–660 lb). Sexual dimorphism in the species is
particularly high compared with most other mammals. Male polar bears also have
proportionally larger heads than females. The weight of polar bears fluctuates
during the year, as they can bulk up on fat and increase their mass by".
From page List of ursids (https://en.wikipedia.org/wiki/List_of_ursids):
"long, plus a 3–20 cm (1–8 in) tail, though the polar bear is 2.2–2.44 m
(7–8 ft) long, and some subspecies of brown bear can be up to 2.8 m (9 ft).
Weights range greatly from the sun bear, which can be as low as 35 kg (77 lb),
to the polar bear, which can be as high as 726 kg (1,600 lb). Population".
From page Knut (polar bear) (https://en.wikipedia.org/wiki/Knut_(polar_bear)):
"== See also ==
Binky (polar bear)
List of individual bears
== References ==
== External links ==".
From page Polar bear (https://en.wikipedia.org/wiki/Polar_bear):
"The polar bear is the largest living species of bear and land carnivore,
though some brown bear subspecies like the Kodiak bear can rival it in size.
Males are generally 200–250 cm (6.6–8.2 ft) long with a weight of 300–800 kg
(660–1,760 lb). Females are smaller at 180–200 cm (5.9–6.6 ft) with a".
From page Subspecies of brown bear
(https://en.wikipedia.org/wiki/Subspecies_of_brown_bear):
"males, potentially tripling their average weight within three years' time,
and can expect to average between 360 and 545 kg (794 and 1,202 lb).
The reported mean adult body masses for both sexes of the polar bear are very
similar to the peninsular giant and Kodiak bears. Due to their roughly".
Again, the RAG model answered correctly with the weights reported in the Wikipedia page ‘Polar bear’, while the base model answered with a slightly different range of weights.
In my previous blog post Create your Vision Chat Assistant with LLaVA, I showed how the LLaVA-1.5 model can be induced to hallucinate when the user’s prompt asks a misleading question about the image. Let’s see what happens in that example using the Phi-3.5-vision model with and without the RAG enhancement. In particular, the model could now be more prone to hallucination if any misleading passages were retrieved.

Question: Tell me the species of the fish in this image
Base VLM: The image does not contain any fish or aquatic environments, so
I cannot provide a species of fish.
RAG VLM: The image does not contain any fish or aquatic environments. It is
a photograph of a desert landscape with sand dunes.
Therefore, I cannot provide the species of fish based on this image.
Neither the base nor the RAG model were induced to hallucinate by the misleading prompt, indicating a possible better robustness of Phi-3.5-vision compared to LLaVA-1.5. In particular, the RAG VLM did not retrieve any page from Wikipedia. In fact, when asked to generate keywords, the model answered
There are no fish visible in the image provided. The image shows a desert
landscape with sand dunes. Therefore, the search keywords related to the image
content would be more appropriate for a desert or dune-related topic.
This search query did not produce any results with the wikipedia package search function.
Note: in the latter example, in earlier experiments conducted with Idefics 2, both the base VLM and RAG VLM models were affected by hallucinations, answering with the names of fish species not present in the image. In particular, the RAG model retrieved misleading passages related to various fishes. The phenomenon of hallucinations is model-dependent and the RAG framework may not be enough to eliminate it in all instances.
The main limitation of the framework is that it requires the model to have at least a general knowledge of the image and the question provided (while the exact details will be retrieved with RAG) in order to produce a useful search query. In some domain-specific settings, it may be necessary to fine-tune the model for search query generation.
The framework discussed in this post also suffers from the limitations common to traditional text-only RAG systems. A common source of errors in the generation is the incorrect retrieval of external information. In some cases, the model is not able to correctly identify the failure of the retrieval phase and it produces an answer based on incorrect, irrelevant, or misleading information. In particular, the presence of irrelevant passages can sometimes induce hallucinations that the model wouldn’t have suffered otherwise.
Another common source of errors is ignoring the retrieved passages or quoting them incorrectly. This can sometimes lead to subtle differences between the retrieved passages and the generated answer that may be difficult to spot at first glance.
In this example, I will show an instance in which the model incorrectly quoted the retrieved passages.

Query: What's the average weight of this animal?
Base VLM: The average male lion can weigh between 160 to 310 kilograms, while
females typically weigh between 120 to 180 kilograms.
RAG VLM: Based on the information provided in the passages, the average weight
of a male lion is 187.5 kg (386 lb) in Southern Africa and 174.9 kg (386 lb) in
East Africa.
Search keywords: lion, weight, average weight
From page American lion (https://en.wikipedia.org/wiki/American_lion):
"(518lbs-1153lbs) in males and 175kg to 365 kg (385lbs-805lbs) for females.
In 2008, the American lion was estimated to weigh up to 420 kg (930 lb). A
study in 2009 showed an average weight of 256 kg (564 lb) for males and 351 kg
(774 lb) for the largest specimen analyzed.".
From page Lion (https://en.wikipedia.org/wiki/Lion):
"=== Size ===
Among felids, the lion is second only to the tiger in size. The size and weight
of adult lions vary across its range and habitats. Accounts of a few
individuals that were larger than average exist from Africa and India.
=== Mane ===".
From page Panthera leo leo (https://en.wikipedia.org/wiki/Panthera_leo_leo):
"The lion's fur varies in colour from light buff to dark brown. It has rounded
ears and a black tail tuft. Average head-to-body length of male lions is
2.47–2.84 m (8 ft 1 in – 9 ft 4 in) with a weight of 148.2–190.9 kg
(327–421 lb). Females are smaller and less heavy. Zoological lion specimens".
From page Panthera leo melanochaita
(https://en.wikipedia.org/wiki/Panthera_leo_melanochaita):
"Average head-to-body length of male lions is 2.47–2.84 m (8 ft 1 in – 9 ft
4 in) with a weight ranging from 150–225 kg (331–496 lb) averaging 187.5 kg
(413 lb) in Southern Africa and 145.4–204.7 kg (321–451 lb) averaging 174.9 kg
(386 lb) in East Africa. Females average 83–165 kg (183–364 lb) in".
From page Asiatic lion (https://en.wikipedia.org/wiki/Asiatic_lion):
"An adult male Asiatic lion weighs 160.1 kg (353 lb) on average with the
limit being 190 kg (420 lb); a wild female weighs 100 to 130 kg (220 to 285 lb)
.[1]".
From page List of largest mammals
(https://en.wikipedia.org/wiki/List_of_largest_mammals):
"== See also ==
List of largest land carnivorans
Largest organisms
Largest prehistoric animals
List of largest birds
List of largest cats
List of largest fish
List of largest plants
List of largest reptiles
List of largest insects
List of heaviest land mammals
Smallest organisms
== Notes ==".
From page Ancient Mesopotamian units of measurement
(https://en.wikipedia.org/wiki/Ancient_Mesopotamian_units_of_measurement):
"== See also ==
Assyrian lion weights
Babylonian mathematics
Historical weights and measures
Weights and measures
== References ==
=== Citations ===".
While the answer stating the weight in kilograms is correct, the model gave a wrong conversion to lbs for the average weight of male lions in Southern Africa, even though the respective passage extracted from Wikipedia reported the correct amount.
In this post, I illustrated a simple framework that can be used to enhance Visual Question Answering with Retrieval Augmented Generation capabilities. The core idea of the method is to exploit the Vision Language Model to generate queries that will be then used by a standard RAG pipeline to retrieve information from an external corpus. I also presented an implementation of the framework that grants Phi-3.5-vision access to Wikipedia. The full code for this implementation is available in the GitHub repo.
While the discussed method is simple and effective, it is not immune to the limitations common to all RAG systems, and to new challenges posed by the complexity of the multimodal setting. On one hand, retrieving the relevant information for some specific questions can be difficult. Since the search queries are created with the Vision Language Model, the retrieval accuracy is further limited by the ability of the VLM to recognize the image and to understand the details the question refers to. On the other hand, even after the correct information has been retrieved, there is no guarantee that the model won’t hallucinate while producing the answer. In the multimodal setting, this could be exacerbated by the fact that the model has to associate the correct meaning to both the text and the image and also understand the interactions between them.
The framework I discussed in this post is a straightforward extension of the vanilla RAG pipeline, adapted to the Visual Question Answering task. Standard advanced RAG techniques, such as query transformation, re-ranking the retrieved passages, and Hypothetical Document Embeddings (HyDE) can be easily included to increase the performance. Furthermore, using a multimodal embedding model (like CLIP) new opportunities appear: the image embeddings can be used when searching by similarity for relevant text documents, and it is also possible to retrieve similar and/or relevant images to the original image and the question. The latter could be useful, for example, when a different point of view of the image is needed to answer the prompt. Another direction for improvement is to perform fine-tuning to get more specialized and effective models. Given the role of the multimodal model in the retrieval and generation process, two different fine-tuning processes can be performed: one to get a model specialized in writing search queries, and one to increase the model’s performance on the grounded generation task. Finally, the framework could be incorporated into a specialized agentic system to further boost its performance and robustness. An agentic system could, for example, iteratively refine the generated query by giving feedback on the retrieved passages and asking follow-up questions or focusing on searching for information about particular details of the image only when needed. It could also handle multi-hop question-answering tasks for more complicated questions, and decide when the retrieval of further external information is needed to answer the user’s query.
I’d be happy to discuss further improvements and/or different approaches to multimodal RAG in the comment section!
A Simple Framework for RAG Enhanced Visual Question Answering was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
A Simple Framework for RAG Enhanced Visual Question Answering
Go Here to Read this Fast! A Simple Framework for RAG Enhanced Visual Question Answering


If 2023 was the year of retrieval augmented generation, 2024 has been the year of agents. Companies all over the world are experimenting with chatbot agents, tools like MultiOn are growing by connecting agents to outside websites, and frameworks like LangGraph and LlamaIndex Workflows are helping developers around the world build structured agents.
However, despite their popularity, agents have yet to make a strong splash outside of the AI ecosystem. Few agents are taking off among either consumer or enterprise users.
How can teams navigate the new frameworks and new agent directions? What tools are available, and which should you use to build your next application? As a leader at a company that recently built our own complex agent to act as a copilot within our product, we have some insights on this topic.
First, it helps to define what we mean by an agent. LLM-based agents are software systems that string together multiple processing steps, including calls to LLMs, in order to achieve a desired end result. Agents typically have some amount of conditional logic or decision-making capabilities, as well as a working memory they can access between steps.
Let’s dive into how agents are built today, the current problems with modern agents, and some initial solutions.
Let’s be honest, the idea of an agent isn’t new. There were countless agents launched on AI Twitter over the last year claiming amazing feats of intelligence. This first generation were mainly ReAct (reason, act) agents. They were designed to abstract as much as possible, and promised a wide set of outcomes.
Unfortunately, this first generation of agent architectures really struggled. Their heavy abstraction made them hard to use, and despite their lofty promises, they turned out to not do much of anything.
In reaction to this, many people began to rethink how agents should be structured. In the past year we’ve seen great advances, now leading us into the next generation of agents.
This new generation of agents is built on the principle of defining the possible paths an agent can take in a much more rigid fashion, instead of the open-ended nature of ReAct. Whether agents use a framework or not, we have seen a trend towards smaller solution spaces — aka a reduction in the possible things each agent can do. A smaller solution space means an easier-to-define agent, which often leads to a more powerful agent.
This second generation covers many different types of agents, however it’s worth noting that most of the agents or assistants we see today are written in code without frameworks, have an LLM router stage, and process data in iterative loops.
Many agents have a node or component called a router, that decides which step the agent should take next. The term router normally refers to an LLM or classifier making an intent decision of what path to take. An agent may return to this router continuously as they progress through their execution, each time bringing some updated information. The router will take that information, combine it with its existing knowledge of the possible next steps, and choose the next action to take.
The router itself is sometimes powered by a call to an LLM. Most popular LLMs at this point support function calling, where they can choose a component to call from a JSON dictionary of function definitions. This ability makes the routing step easy to initially set up. As we’ll see later however, the router is often the step that needs the most improvement in an agent, so this ease of setup can belie the complexity under the surface.
Each action an agent can take is typically represented by a component. Components are blocks of code that accomplish a specific small task. These could call an LLM, or make multiple LLM calls, make an internal API call, or just run some sort of application code. These go by different names in different frameworks. In LangGraph, these are nodes. In LlamaIndex Workflows, they’re known as steps. Once the component completes its work, it may return to the router, or move to other decision components.
Depending on the complexity of your agent, it can be helpful to group components together as execution branches or skills. Say you have a customer service chatbot agent. One of the things this agent can do is check the shipping status of an order. To functionally do that, the agent needs to extract an order id from the user’s query, create an api call to a backend system, make that api, parse the results, and generate a response. Each of those steps may be a component, and they can be grouped into the “Check shipping status” skill.
Finally, many agents will track a shared state or memory as they execute. This allows agents to more easily pass context between various components.
There are some common patterns we see across agent deployments today. We’ll walk through an overview of all of those architectures in the following pieces but the below examples are probably the most common.
In its simplest form an agent or assistant might just be defined with a LLM router and a tool call. We call this first example a single router with functions. We have a single router, that could be an LLM call, a classifier call, or just plain code, that directs and orchestrates which function to call. The idea is that the router can decide which tool or functional call to invoke based on input from the system. The single router comes from the fact that we are using only 1 router in this architecture.

A slightly more complicated assistant we see is a single router with skills. In this case, rather than calling a simple tooling or function call, the router can call a more complex workflow or skill set that might include many components and is an overall deeper set of chained actions. These components (LLM, API, tooling, RAG, and code calls) can be looped and chained to form a skill.
This is probably the most common architecture from advanced LLM application teams in production today that we see.

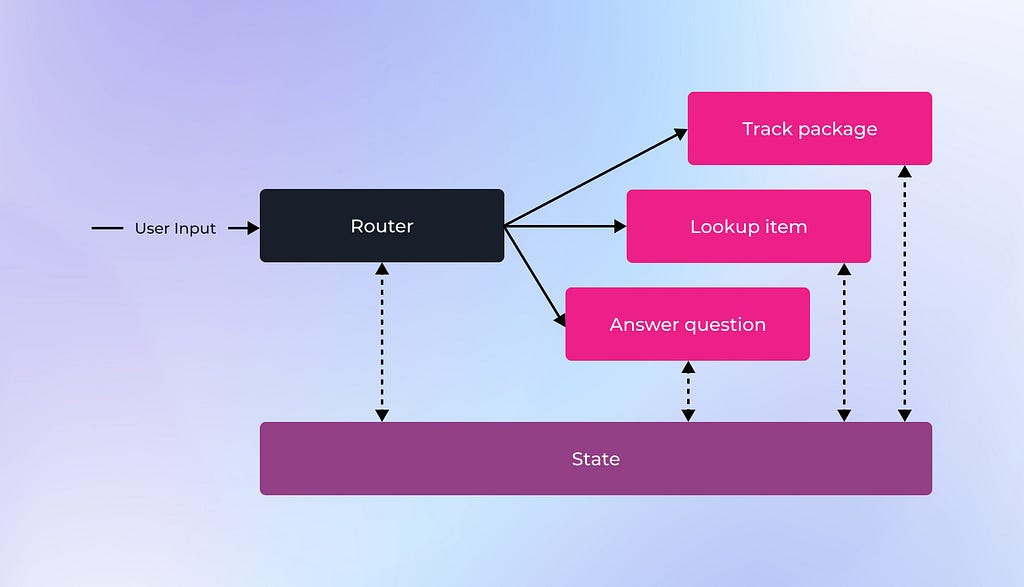
The general architecture gets more complicated by mixing branches of LLM calls with tools and state. In this next case, the router decides which of its skills (denoted in red) to call to answer the user’s question. It may update the shared state based on this question as well. Each skill may also access the shared state, and could involve one or more LLM calls of its own to retrieve a response to the user.
This is still generally straightforward, however, agents are usually far more complex. As agents become more complicated, you start to see frameworks built to try and reduce that complexity.
LangGraph builds on the pre-existing concept of a Pregel graph, but translates it over to agents. In LangGraph, you define nodes and edges that your agent can travel along. While it is possible to define a router node in LangGraph, it is usually unnecessary unless you’re working with multi-agent applications. Instead, the same conditional logic that could live in the router now lives in the Nodes and Conditional Edges objects that LangGraph introduces.
Here’s an example of a LangGraph agent that can either respond to a user’s greeting, or perform some sort of RAG lookup of information:

Here, the routing logic instead lives within nodes and conditional edges that choose to move the user between different nodes depending on a function response. In this case, is_greeting and check_rag_response are conditional edges. Defining one of these edges looks like this:
graph.add_conditional_edges("classify_input", is_greeting, {True: "handle_greeting", False: "handle_RAG"})
Instead of collecting all of the routing logic in one node, we instead spread it between the relevant edges. This can be helpful, especially when you need to impose a predefined structure on your agent, and want to keep individual pieces of logic separated.
Other frameworks like LlamaIndex Workflows take a different approach, instead using events and event listeners to move between nodes. Like LangGraph, Workflows don’t necessarily need a routing node to handle the conditional logic of an agent. Instead, Workflows rely on individual nodes, or steps as they call them, to handle incoming events, and broadcast outgoing events to be handled by other steps. This results in the majority of Workflows logic being handled within each step, as opposed to within both steps and nodes.
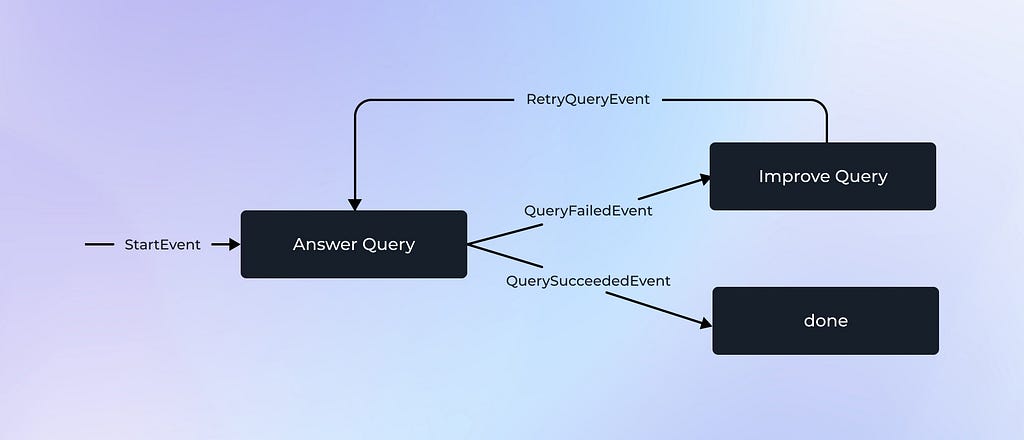
There are other frameworks that are intended to make agent development easier, including some that specialize in handling groups of agents working together. This space is rapidly evolving and it’s worth checking out these and other frameworks.
Regardless of the framework you use, the additional structure provided by these tools can be helpful in building out agent applications. The question of whether using one of these frameworks is beneficial when creating larger, more complicated applications is a bit more challenging.
We have a fairly strong opinion in this area because we built an assistant ourselves. Our assistant uses a multi-layer router architecture with branches and steps that echo some of the abstractions of the current frameworks. We started building our assistant before LangGraph was stable. As a result, we constantly ask ourselves: if we were starting from scratch, would we use the current framework abstractions? Are they up to the task?
The current answer is not yet. There is just too much complexity in the overall system that doesn’t lend itself to a Pregel-based architecture. If you squint, you can map it to nodes and edges but the software abstraction would likely get in the way. As it stands, our team tends to prefer code over frameworks.
We do however, see the value in the agent framework approaches. Namely, it does force an architecture that has some best practices and good tooling. They are also getting better constantly, expanding where they are useful and what you can do with them. It is very likely that our answer may change in the near future as these frameworks improve.
This begs another important question: what types of applications even require an agent? After all, agents cover a broad range of systems — and there is so much hype about what is “agentic” these days.
Here are three criteria to determine whether you might need an agent:
Let’s say that you answer yes to one of these questions and need an agent. Here are several known issues to be aware of as you build.
The first is long-term planning. While agents are powerful, they still struggle to decompose complex tasks into a logical plan. Worse, they can often get stuck in loops that block them from finding a solution. Agents also struggle with malformed tooling calls. This is typically due to the underlying LLMs powering an agent. In each case, human intervention is often needed to course correct.
Another issue to be aware is inconsistent performance due to the vastness of the solution space. The sheer number of possible actions and paths an agent can take makes it difficult to achieve consistent results and tends to drive up costs. Perhaps this is why the market is tending toward constrained agents that can only choose from a set of possible actions, effectively limiting the solution space.
As noted, one of the most effective strategies is to map or narrow the solution space beforehand. By thoroughly defining the range of possible actions and outcomes, you can reduce ambiguity. Incorporating domain and business heuristics into the agent’s guidance system is also an easy win, giving agents the context they need to make better decisions. Being explicit about action intentions (clearly defining what each action is intended to accomplish) and creating repeatable processes (standardizing the steps and methodologies that agents follow) can also enhance reliability and make it easier to identify and correct errors when they occur.
Finally, orchestrating with code and more reliable methods rather than relying solely on LLM planning can dramatically improve agent performance. This involves swapping your LLM router for a code-based router where possible. By using code-based orchestration, you can implement more deterministic and controllable processes, reducing the unpredictability that often comes with LLM-based planning.
With so much hype and the proliferation of new frameworks in a frenzied generative AI environment filled with FOMO, it can be easy to lose sight of fundamental questions. Taking the time to think about when and where a modern agent framework might — and might not — make sense for your use case before diving headlong into an MVP is always worthwhile.
Navigating the New Types of LLM Agents and Architectures was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Navigating the New Types of LLM Agents and Architectures
Go Here to Read this Fast! Navigating the New Types of LLM Agents and Architectures


