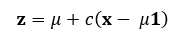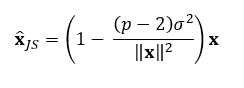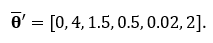Developing an oceanographic application for big game fishing
I’m going to tell a science story, just for fun, because I’m retired, and I have time, and it is interesting. It’s not a technical story about how I built our Fishing Maps product. It’s about my journey from being a fisheries scientist with no interest in industry, to becoming an unlikely entrepreneur selling a high tech mapping product to fishers, with a huge range of different technical abilities and knowledge. It is not a story about wild success, far from it, but it’s not about failure of a startup either. It is a tale about fish, which should amuse my colleagues who know that I don’t really like fish, even though I’m a fisheries oceanographer (see Confessions of an Oceanographer). I’m more of a plankton guy.
When I started out as a brash oceanography grad student in the early 1980s I had no interest in working for industry. I thought I’d be a university professor (that didn’t happen). When the phone rang in the biological oceanography lab at Dalhousie we used to joke that it was Scripps calling to offer one of us a job. That call never came, but we all graduated anyway and went our separate ways. My path led me down a long series of postdocs and research associateships, and then into “permanent” jobs as a government scientist in New Zealand, Australia and California. I did eventually work for 11 years as the NOAA lead for the CalCOFI program, at the SWFSC on the UCSD Scripps campus in San Diego.
While travelling down that road, I watched with amazement, and sometimes with admiration, how some of my colleagues applied their skills to becoming science entrepreneurs. Some were successful, and some were not. One got into remote sensing and then into instrument development, becoming very successful quite quickly. Another struggled to keep a deep-sea camera business going. Some turned their modelling skills from government stock assessment to private consultancy. Others set up an acoustic survey company. One developed a tracking system for fish that has become famous. Their efforts fascinated me, but the entrepreneurial track never appealed. I was too busy writing research papers. It never occurred to me that I’d take that path one day.
Fast forward 37 years (1985 to 2022). During my career as a fisheries oceanographer I learned about three things that fueled entry into entrepreneurship: programming, remote sensing, and fishers. When I was a student, spreadsheets on a luggable computer were a revelation. I spent so much time looking at a green screen that the chalk on a blackboard turned pink. Later on, when I got into fisheries acoustics, spreadsheets lost their allure as the data exceeded 10,000 rows and hundreds of columns. I had to learn to code my analyses. I’d already written thousands of lines of Turbo Pascal to control an experimental system that I designed during my first postdoc, so coding wasn’t new to me. It took me a while though. I learned R in my 40s, NCL in my 50s and Python in my 60s. I learned the languages the way a lot of scientists do, by using them to code analyses for discrete projects that led to publications. Eventually I learned to stitch the scripts together using shell scripting to create reproducible workflows combining R and Python. I took on becoming a Linux user, and worked with open source software. I became an avid proponent of open-acess data, open source software, and reproducible open science.
I’d always been fascinated by satellite remote sensing, which literally exploded on the science scene during my career. I quickly went from using a few remote sensing images in my papers to requesting data from NASA. I was bemused and excited to receive a box of CDs full of data from the Coastal Zone Color Scanner and later, from other sensors. Handling these data was a puzzle. Each CD had dozens of very large files, as HDFs, or some other inscrutable format. What to do with it all? My software couldn’t open the files. The CDs sat on my office shelves for years, a monument to my frustration. Was NASA really sending CDs to everyone who requested data? I didn’t know, but I suspect that they were. I progressed to using the different GUIs that NASA and NOAA fielded. They were great for viewing a few images, but clumsy for research purposes. I experimented with FTP, but never made much much progress until systems were developed to permit the data to be accessed, and subset directly from your analysis code without massive download redundancy. Accessing remote sensing data became easy, efficient, and scriptable using R and Python.
After I moved from plankton research into applied fisheries research, I came into contact with fishers and representatives of fishing companies as part of my work. I sat through endless planning sessions, stock assessment meetings, and program reviews where commercial fishers and upper level industry managers were present. I attended meetings where we presented scientific results to fishers, NGO representatives and other stakeholders. I realised that commercial fishers have a degree of respect for the scientific assessment process, but that they are also deeply suspicious of the scientific results. Their views are rooted in their experience, and can be difficult to shift in the face of scientific evidence that is often incomplete. They often don’t trust the process and resent it when the government fisheries managers have the whip hand. Their livelihoods are at stake, and that’s a fierce motivator. They sometimes don’t see the government scientists as objective, and there are often chronic differences in interpretation of evidence concerning status of the stocks. I found the meetings stressful, but it did give me some insight into the way that fishers think. That would prove useful later when I began selling remote sensing maps to recreational big game fishers.
I retired from NOAA Fisheries and the CalCOFI program in 2018 and returned to New Zealand. It was quite liberating not to have to attend meetings, but I couldn’t bring myself to leave science behind. I began to learn Python and started toying with an idea that I had to make satellite remote sensing maps for recreational big game fishers.
There were several false starts and dead ends along the way before I developed a robust working product. The idea was to use my oceanographic knowledge create maps of Sea Surface Temperature (SST) and other ocean variables like chlorophyll and currents that could be used to guide sport fishers to locations where they would be most likely to catch a marlin or a tuna. The concept changed radically along the way. Initially I had planned to sell individual maps for a very small fee with the idea that it would be a low value, high volume product. We would sell maps online for less than the price of a cup of coffee. This concept failed miserably, and proved hard to implement from the technical side as well. I had also intended to provide maps for any region of the world, but soon realised that this too was problematic, not just in terms of computing time required, but also because I wanted to be familiar with the oceanography of the region that we were offering maps for. We began to make some headway by offering a package of maps for regions focused on the game fishing ports of New Zealand, California and Baja California, which are regions that I know well from my work as an oceanographer.
The next challenge was how to become known as a fishing map provider. There are established companies already in the market so the challenge was not just to become visible, but also to get a market share. I started posting on a Facebook group page for recreational fishers in New Zealand and attracted the attention of a couple of fishers who had a science background. They approached me and offered invaluable advice on what they would like to see in the maps from a fishers perspective. Then we were approached by the company that manages the New Zealand Big Game Fishing Facebook group. We entered a profit sharing agreement with them, but dissolved the relationship after 6 months because, despite the best intentions, the arrangement was not working in our favour. We were able to grow the business significantly in the first year with virtually all of our early subscribers from New Zealand. Breaking into the California/ Baja market is proving more difficult because there is more established competition.
Four days of SST off Whangamata, North Island New Zealand. (maps by the authour Fishing Maps)Copy of a geolocated map showing chlorophyll off Whangamata, New Zealand. (maps by the authour Fishing Maps)
Big game fishing is very seasonal, so one of the challenges is to maintain motivation when subscriptions drop off after the summer fishing season. Another challenge is to manage anxiety about whether the subscribers will return the following year. A new startup like this is definitely not a profit making business in the early stages. Revenue got ploughed back into new computer equipment, website development, and marketing costs. My partner in Fishing Maps (my wife) is an accountant and auditor who tracks the finances and keeps us within reasonable bounds for expenditure relative to revenue. It was audacious to enter this market where there are established competitors, but one thing I realised is that the other companies are also run by very small teams, in some cases by one one or two people, just like us. One of the distinguishing features of our product is our detailed blogs and articles, explaining oceanography for game fishing accurately in plain language. We set out to fill a perceived gap in a niche market, bringing high quality satellite maps backed by oceanographic knowledge to a regionally-focused potential market. The development process for the maps continues to develop. Receiving feedback from fishers can be challenging, but it leads to improvements. Seeing the product from the outside can be as confronting and demotivating as receiving a negative review on a scientific paper. On the other hand it is an opportunity to focus improvements in very effective ways. Nevertheless it’s impossible to balance the hours invested in development against the financial yields in a startup like ours.
We are now part of the new wave of digital entrepreneurs, working from home with negligible overheads, a fast Internet connection, and the knowledge to create a high-tech product. The science is fun and always evolving. The marketing is less appealing. Writing the blogs and articles for non-specialists is a huge change from writing scientific articles, but it can be rewarding. The view from my study over the beautiful Waitakere Ranges to the heads of the Manukau Harbour here in New Zealand reminds me that anything is possible when you have open data, open source software, programming skills, the time, and the will to try something audacious.
I can’t believe it has already been 9 months since I have been working as a freelance data scientist! I originally wrote about making the leap after I was 3 months in. Getting started my husband and I agreed that we would try it for 3 months and that we would know after 3 months if it was going to work. I am very pleased (and fortunate) to say that we knew after about a month that it looked like freelancing was going to work for us.
My original post garnered a lot of public and private questions from people facing layoffs, return-to-office mandates (which are typically layoffs in disguise), and burn out. I also have learned a lot more in the past 6 months about how to make this work. I also made some key mistakes and have learned from them on some things not to do. So I thought it was time to post an update to the original post.
I do recommend that you read my original post first because there are some important things in there that I will not cover here. Like last time, I would also like to give a shout out to Brett Trainor who has created on online community (it is mostly Gen X-ers, but applicable to most people) called The Corporate Escapees dedicated to helping people free themselves from corporate work. He also has a great presence on TikTok. Brett and the “Escapees” have been great to bounce ideas off of and provide a wealth of information on getting started and flourishing while working as a freelancer, fractional, consultant, or solopreneur.
More things I love about having gone solo
In my original post I had laid out several things I love about having gone out on my own. These things included stuff like working on what I work on when I want to work on it and making my own rules for my company. In the past 6 months I have discovered some new ones and learned more about the ones I already knew. So I thought I would briefly describe them here.
First, I (still) get to work from home. I have been working from home since 2017, which has given me the freedom to live where I want. I am a mountain creature and so the idea of moving to some random city away from all of the outdoor activities I love is not at all appealing to me. (In fact, I left the field of my PhD so that I could take a remote job…something that was not possible in that field.) More importantly, we are seeing many companies that went remote with the pandemic issue return to office (RTO) mandates. It is well documented that many of these are layoffs in disguise. So in reality, I have more job stability as a freelancer! And those companies that are laying off still have work that needs to be done. They just don’t have the positions to do it because they have laid people off. This means that freelancing is actually going to be more stable over the long run, because these companies will need to bring in someone to do the work!
Next — and this is no small one — is that I no longer am subjected to the huge waste of time that is a performance review. I have watched coworkers turn themselves inside out writing their self assessments fretting over every single punctuation mark only to have them essentially ignored. I have written many self assessments that included jokes and laughable things that managers have never commented on or noticed because they never read them! The process of performance reviews is broken. And what is the point when the majority of the time “meets expectations” lands you a so-called raise that is less than the increase in the cost of living?
This is not to say that as a freelancer your performance doesn’t matter. It is just that you don’t have to get all anxious and waste your time listening to your boss rattle back to you some list of accomplishments, tell you that you are doing a good job, and not give you too much reward for it. Instead, the reward for a freelancer (or the management of a poorly-performing one) is done through repeat business. Does a client choose to renew or extend your contract? Are they giving your name out to their friends as a referral? If so, job well done!
One that should not be overlooked is the fact that I have control over how my company-of-one runs. This has a lot of different impacts. First, I do not have to go ask numerous managers permission to work on a thing. If I want to work on something, I work on it. Ideally, there are others who need that type of work done that I can help. Second, I determine the finances of the company and don’t need to ask permission to attend a conference, take a class, travel to meet with a prospective client, or buy a new software tool. While it might sound silly, I actually am giddy (in a geeky kind of way) that I get to pick my own computer. I greatly dislike being forced to use Windows or Mac (Pop_OS FTW!!!) or being tied into a particular type of hardware. If I think it would benefit my business by me attending or speaking at a particular conference, I go and don’t need to play “Mother May I?” to get permission to go. If I decide I need to buy a particular book for my continuing education, I don’t need to ask someone. There is great freedom in this! (And, by the way, these things are tax deductible as well!)
Networking (Image created by author using DALL-E)
On the importance of networking
Definitely the most common questions I have received since writing my initial post 6 months ago have to do with networking. When you are working as a freelancer, the old saying goes: “your network is your net worth.” There are a lot of implications to this statement and not all of them are pretty. So I am going to share some hard truths here.
First, networks are established over time. Good networks include people who tend fall into one of a few categories:
People you have worked with in the past and are familiar with your work
Other people in your field who know of your experience, skills, and interests
People who work for companies that have problems that you can solve
(Note that this is not an exhaustive list, but you get the point.)
When you are freelancer you are selling a brand and that brand is you. Think about it like buying a car. You are not going to buy a car that is a brand you have never heard of. Further, you are not going to buy a brand that has not made a car before just because they have an assortment of parts. People buy things they trust.
What this means is that it is really hard to be a successful freelancer — in data science or otherwise — if you have not already been working as a data scientist for some period of time. When clients hire freelancers they are trying to solve a problem. They want to know that the freelancer they are hiring knows how to solve it and has experience in doing so. This means that it is very difficult to be a successful data science freelancer as your first job out of school. Even graduate school. Real-world experience is highly valued by those who look to hire freelancers.
The good news is that the act of getting that so-called real-world experience is already a key step in developing your network (i.e. the group in the first bullet point above). Many freelancers I know have their previous employers as some of their first clients. This is also why it is really important to avoid burning bridges with those you have worked with in the past, because you never know could be your client in the future!
In my previous post I suggested things like conference attendance and speaking as ways to grow your network further. I still hold to that. However, it is also important to recognize that not everyone does well at conferences. There are some neurodivergent people who find conferences to be difficult. And that is OK! There are ways to build your network beyond conferences, especially including things like blogging here and elsewhere! What you are looking to do, whether at conferences or blogging, is to grow your brand and brand awareness. When people think of you as a data scientist, what types of things do you want them to think of? Maybe you are a whiz at forecasting. Blog about it! Maybe you really enjoy writing code to solve a certain type of problem. Create a YouTube video about it!
Increasing your brand awareness (and network) through a good portfolio
The important thing here is about creating that brand awareness of the brand that is you. This, of course, means that people need to be able to find your brand and learn about it. Particularly if your network is not large, this means that people need to be able to see your work. Here is where creating a really awesome portfolio can help. Getting your portfolio in front of people in the last category above can help you grow your network and land jobs.
There is a ton of content out there about how to create a good data science portfolio. I will just summarize some key points here.
First, your portfolio should use an interesting data set. Do not use any data set from educational forums such as the Titanic data set, MNIST, cat versus dog via imagery, etc. Kaggle, while a great learning tool, does not always reflect the real work. You want the data to be as realistic as possible. It should be noisy and messy because this is how real-world data is. It should answer an interesting question (bonus points if it is an interesting question that could make a company money or solve a big problem). And it should also be data on a subject you are interested in and knowledgeable about so you can personally identify if the answers make sense and talk people through it like a subject matter expert.
Second, you need to tell a complete story for each project in your portfolio. Do not just put up a bunch of code with no explanation for how to use it. Do not provide results from some model without an explanation of what is going on with the model and the data and what conclusions should be drawn. A good portfolio project is as much about the explanations of your work as it is about the code. Your explanations should be extensive. You need to demonstrate that you not only know how to code, but know how to walk the reader through the full start-to-finish story of problem to solution.
Your portfolio projects, when possible, should be interactive. You want people to be able to see that the code runs. I personally am a big fan of setting up an inexpensive virtual machine somewhere and running Streamlit dashboards for interactivity.
Because your portfolio is about brand awareness, think about what your brand is. For example, if you are wanting to advertise yourself as being really good with recommendation engines, don’t waste time demonstrating solutions in image analysis. You are going to be showing your future clients the types of problems you can solve for them. The more obvious you make that, the better.
Finally, whenever you make an update to your portfolio, you need to get the word out there. Make a blog post or YouTube video to go with it. Make the code publicly available on GitHub or GitLab. Post on LinkedIn links to the portfolio and point out the new content. Post another link once the blog post is published.
Image created by author with DALL-E
Be as much of a generalist as you can
I love being a specialist. Many people do. I have some pretty deep knowledge in some pretty specific domains. However, being a freelancer is about solving a problem. Frequently (and especially with startups that don’t have many employees) you will be expected to know how to do more than create the small, superb solution to the problem. You will need to know how to solve the problem from beginning to end. This means that you will need to work beyond that small, niche skill.
For me, this has meant that I have been learning (an ongoing process) many skills that go beyond my favorite areas of graphs, NLP, LLMs, etc. I have had to learn a fair bit more about data engineering, MLOps/LLMOps, and cloud architecture. I am paying to take classes and go to conferences on these subjects (see above…my management approved it 😉 ). These are investments in me, which means they are investments in my business. The more I can offer clients, the more clients whose problems I can solve. It is important as a freelancer that you be able to offer as much as possible!
Image created by author with DALL-E
Why diversity of clients is important
Early on in my freelancing I was thinking about who my dream client is. Those who know me know that work culture really matters to me. The places I have seen with the work culture that most closely resembles my values tend to be startups. I also know the types of data science problems I like to work on (graphs, natural languages processing, generative AI, geospatial). So I initially figured that I would look just for startups with those types of problems.
I was then exposed to a great book called “The Freelancer’s Bible: Everything You Need to Know to Have the Career of Your Dreams―On Your Terms” by Sara Horowitz. This opened my eyes to a different way of looking at clients with an eye towards creating a diverse pool of current and prospective clients.
If you get into this book, you will learn that the best financial stability while freelancing comes from having a variety of types of clients ranging from major clients who are steady and consistent to those who might be profitable after some work with them to those who might be long shots. It is worth noting in my case that startups, by the very fact that they are startups and especially true of early-stage startups, might not necessarily be considered “steady and consistent.” If you rely only on them then you need to be prepared for your work to be cancelled or your hours cut due to fluctuations in the cash flow and budget. And it is a bad idea to compensate for that by taking on a lot of startups (see below on taking on too much work). This also means that you need to have a good financial cushion such that if hours dry up a bit for a period of time you can still pay your bills.
In practice, it is better to have an even mix of clients from companies that have been around for some time to startups and those in between. This will make your freelancing business more resilient to when contracts end or clients have to cut back your hours. Remember the goal: steady, predictable income.
If you came here looking to talk about health insurance in the United States as freelancer, I would direct you to the “Mistakes I have made so far section below.” Don’t worry, I will cover that topic. But let’s hit a few other insurance topics first.
By far, one of the biggest changes in going solo has been the fact that I no longer have company-provided benefits. This has a few implications that you need to factor in as you are determining your finances for going solo. This section might be fairly US-centric since other countries offer different benefits. But it is definitely something to educate yourself on, regardless of where you live.
First, when you are working for a company it is unlikely that they are going to sue you if you do a bad job (with a few exceptions, of course). However, when you are working as a solopreneur that is not a guarantee. When I was just getting started, I didn’t really think about these things. I just figured that my clients and I would have a contract with a solid statement of work, good communication, and clear deliverables and that would take care of that. I have not been sued (and hope that I never am!), but it is naive to think that it couldn’t happen at some point in the future.
This is what professional liability insurance is for. It covers both businesses and individuals for claims that might arise out of allegations of mistakes, missed deliveries, or breach of contract. In fact, some larger organizations that you might contract with actually require that you carry it. So best to plan for this in advance. It is really easy to get online and reasonable plans cost less than $200/month.
Another insurance I had not initially considered was long-term disability insurance. Many people have disability insurance, both short- and long-term, as part of their corporate benefits package and don’t even think about it. In my specific case, I am the sole bread winner for my family for a big portion of the year (my spouse works a seasonal job). If something were to happen to me and I couldn’t work, this would be a devastating blow to my family, one we could not afford. Therefore, getting disability insurance is something you should really think about.
Generally speaking “long term” means beyond 3 months. If you sit down and price it out, you will find that the price of short-term and long-term is about the same. Therefore, we decided not to get short-term disability insurance since it is so expensive, which implies that we will make sure that we are financially able to cover 3 months of living without an income should something happen to me.
Another big benefit that corporate employers offer (at least in the United States) is that they contribute something to your retirement. Typically, this is in the form of a 401k matching contribution. As a freelancer, you can still contribute to your retirement, but you need to make the conscious decision to do so since you will no longer have an employer automatically deducting it from your paycheck. Here is where I strongly recommend you talk with a financial advisor on the best ways to save for retirement.
Image created by author with DALL-E
Mistakes I have made so far
I have likely made the idea of working freelance sound a bit like rainbows, puppies, and unicorns. In a way, that is how I feel. But I also have made some pretty big mistakes. So please learn from me and my mistakes and go into your decision-making process with better information than I had!
Health insurance
At least in the United States this is the 800 pound gorilla in the room that keeps people tied to corporate work. There is no reasonably-priced way to get health insurance when you are working for yourself. Yes, there is the open market (AKA Obamacare), so at least that option exists (a brief moment of tribute to the freelancers who went out there before Obamacare).
As I previously said, my spouse works seasonally but is offered health insurance during the season. So it made sense that we would go on is health insurance when I left corporate. This left us trying to figure out what we would do when the season was over. We had the option of COBRA (the ability to keep your health insurance through your existing, corporate plan while paying the full monthly premiums) or to go on the open market. Because I was having surgery while he was still working, we decided to do COBRA since I would be reaching my maximum out-of-pocket (OOP) and we could then take advantage of not having to pay anything for the rest of the year.
This. Was. A. Mistake.
The problem was that we didn’t fully realize how much COBRA costs. We knew it was expensive, but we completely underestimated. For our family of 3, it came out to $3000/month. Yes, really. Yet I now know that I can get comparable packages on the open market for half that. It is still not cheap and it is tax deductible either way. If I sat down and really calculated out how much we were saving by reaching max OOP, it still would have been cheaper to go on the open market. A lesson we will not repeat next year.
Taking on too much work
I will admit that I frequently worry that I will not have enough billable hours. In the beginning of the freelancing journey, you worry that you will not make enough money, so you take on a ton of work to make sure you do. Later in the journey, you will have a contract come to and end (sometimes prematurely) or a client throttle back your hours.
My anxiety sometimes gets the better of me. In an effort to make sure that I never dip below what I made in my corporate work, I have a tendency to overcompensate and take on too many clients or too many hours. I am very fortunate to be in the situation where I can do so. Some have suggested taht I bring on additional employees into my company so I can accommodate this work load. However, this is a double-edged sword. The moment you take on additional employees you are responsible for getting them work. If I am constantly nervous one month to the next about whether I will meet my income requirements, adding additional employees to that mix is only going to make that feeling worse.
One final note on that anxiety has to do with your financial planning. In my original article I talked a fair bit about this. However, I would like to add that you can help alleviate some of that anxiety by having a good amount of savings before going into freelancing. That way, should work be light for a particular month you know that you are not going to be immediately in trouble. One bit of advice I was given was to be able to support yourself without any paying work at all for 6 months. This might sound rather extreme, but having set aside money for when the work is light is very, very important.
On the complexities of working with larger organizations
It is great to be able to work with client organizations of all sizes. As I have previous stated, I really enjoy working with smaller startups. However, like I said before, diversity of clients is also important. Thus, it is a good idea to have some larger companies that you are supporting.
This is not without its complexities though. The larger the organization, the larger the bureaucracy. What this means for the freelancer is that it takes much more time and is much harder to get them under contract. They frequently have requirements for things like proof of liability insurance (see above), registration as an entity in complicated systems, and even drug and background tests. Sometimes they expect that you will pay for those things out of pocket before they can work with you.
It is important to keep all of this in mind should you wish to work with them. Not only will your time assembling these things not be compensated (and, in fact, will cost you money since it is taking time away from other paying clients), but you might also have to spend money in the form of fees for drug and background tests, signing up for liability insurance, etc. It is up to you to decide if it is worth it. Again, I refer you to the points about diversity of clients.
The importance of a support network when you go out on your own cannot be overstated. When you work in a corporate setting, you can always meet up (in person or virtually) with a coworker for a gripe session, to bounce ideas off of, or just for general socialization. As a freelancer, you do not have that as easily and it can get lonely.
I have been able to make my freelancing work so far due to the support of a group of people. First and foremost, without the support of my husband this would not have been possible. In fact, I think going solo without the support of your significant other if you have one is a supremely bad idea. There is nothing certain or guaranteed about freelancing and that can be challenging on a family.
Similarly, it is important to have people to bounce ideas off of who are not your clients. There are many groups of solopreneurs available online, such as The Corporate Escapees I referred to before, who are like-situated individuals. Many are not data scientists themselves, but they possess a wealth of information on the business side of things. I strongly recommend finding a group that you resonate with.
I am very fortunate that 9 months in things are going strong! In my original post I talked about feeling much more secure not being in the corporate world. That is even more true today. With all of the layoffs in the tech world, I hear from friends and former colleagues all the time about how hard of a time they are having at finding a new job. This is really, really sad and I truly feel for them.
I also stated in the original article that my definition of success is whether I can sustain this model long term. I have experienced having my hours throttled and clients coming and going, but each time it seems that things have worked out since I have other work that comes up to take its place. So that seems very positive to me.
My next steps, which I hope to report back on 6 months from now, involve creating diversity of income streams. Working on an hourly basis as a freelancer is nice, but now I am looking to create other types of work, whether through retainers or creation of sellable products, that will generate revenue beyond simply billing hours. Stay tuned!
In this post, we provide a step-by-step approach of fine-tuning a Mistral model using SageMaker and import it into Amazon Bedrock using the Custom Import Model feature.
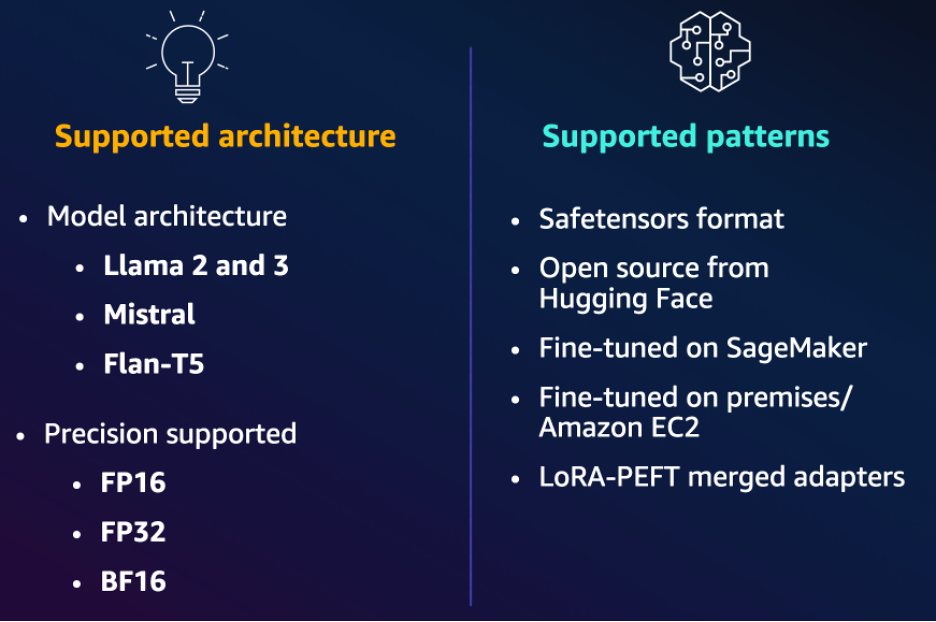
In this blog post, we will show you how to leverage AI21 Labs’ Task-Specific Models (TSMs) on AWS to enhance your business operations. You will learn the steps to subscribe to AI21 Labs in the AWS Marketplace, set up a domain in Amazon SageMaker, and utilize AI21 TSMs via SageMaker JumpStart.
Averaging is one of the most fundamental tools in statistics, second only to counting. While its simplicity might make it seem intuitive, averaging plays a central role in many mathematical concepts because of its robust properties. Major results in probability, such as the Law of Large Numbers and the Central Limit Theorem, emphasize that averaging isn’t just convenient — it’s often optimal for estimating parameters. Core statistical methods, like Maximum Likelihood Estimators and Minimum Variance Unbiased Estimators (MVUE), reinforce this notion.
However, this long-held belief was upended in 1956[1] when Charles Stein made a breakthrough that challenged over 150 years of estimation theory.
History
Averaging has traditionally been seen as an effective method for estimating the central tendency of a random variable’s distribution, particularly in the case of a normal distribution. The normal (or Gaussian) distribution is characterized by its bell-shaped curve and two key parameters: the mean (θ) and the standard deviation (σ). The mean indicates the center of the curve, while the standard deviation reflects the spread of the data.
Statisticians often work backward, inferring these parameters from observed data. Gauss demonstrated that the sample mean maximizes the likelihood of observing the data, making it an unbiased estimator — meaning it doesn’t systematically overestimate or underestimate the true mean (θ).
Further developments in statistical theory confirmed the utility of the sample mean, which minimizes the expected squared error when compared to other linear unbiased estimators. Researchers like R.A. Fisher and Jerzy Neyman expanded on these ideas by introducing risk functions, which measure the average squared error for different values of θ. They found that while both the mean and the median have constant risk, the mean consistently delivers lower risk, confirming its superiority.
However, Stein’s theorem showed that when estimating three or more parameters simultaneously, the sample mean becomes inadmissible. In these cases, biased estimators can outperform the sample mean by offering lower overall risk. Stein’s work revolutionized statistical inference, improving accuracy in multi-parameter estimation.
The James-Stein Estimator
The James-Stein[2] estimator is a key tool in the paradox discovered by Charles Stein. It challenges the notion that the sample mean is always the best estimator, particularly when estimating multiple parameters simultaneously. The idea behind the James-Stein estimator is to “shrink” individual sample means toward a central value (the grand mean), which reduces the overall estimation error.
To clarify this, let’s start by considering a vector x representing the sample means of several variables (not necessarily independent). If we take the average of all these means, we get a single value, denoted by μ, which we refer to as the grand mean. The James-Stein estimator works by moving each sample mean closer to this grand mean, reducing their variance.
The general formula[3] for the James-Stein estimator is:
Where:
x is the sample mean vector.
μ is the grand mean (the average of the sample means).
c is a shrinkage factor that lies between 0 and 1. It determines how much we pull the individual means toward the grand mean.
The goal here is to reduce the distance between the individual sample means and the grand mean. For example, if one sample mean is far from the grand mean, the estimator will shrink it toward the center, smoothing out the variation in the data.
The value of c, the shrinkage factor, depends on the data and what is being estimated. A sample mean vector follows a multivariate normal distribution, so if this is what we are trying to estimate, the formula becomes:
Where:
p is the number of parameters being estimated (the length of x).
σ² is the variance of the sample mean vector x.
The term (p — 2)/||x||² adjusts the amount of shrinkage based on the data’s variance and the number of parameters.
Key Assumptions and Adjustments
One key assumption for using the James-Stein estimator is that the variance σ² is the same for all variables, which is often not realistic in real-world data. However, this assumption can be mitigated by standardizing the data, so all variables have the same variance. Alternatively, you can average the individual variances into one pooled estimate. This approach works especially well with larger datasets, where the variance differences tend to diminish as sample size increases.
Once the data is standardized or pooled, the shrinkage factor can be applied to adjust each sample mean appropriately.
Choosing the Shrinkage Factor
The shrinkage factor c is crucial because it controls how much the sample means are pulled toward the grand mean. A value of c close to 1 means little to no shrinkage, which resembles the behavior of the regular sample mean. Conversely, a c close to 0 means significant shrinkage, pulling the sample means almost entirely toward the grand mean.
The optimal value of c depends on the specific data and the parameters being estimated, but the general guideline is that the more parameters there are (i.e., larger p), the more shrinkage is beneficial, as this reduces the risk of over fitting to noisy data.
Implementing the James-Stein Estimator in Code
Here are the James-Stein estimator functions in R, Python, and Julia:
## Julia ## function james_stein_estimator(Xbar, sigma2=1) p = length(Xbar) norm_X2 = sum(Xbar.^2) shrinkage_factor = max(0, 1 - (p - 2) * mean(sigma2) / norm_X2) return shrinkage_factor * Xbar end
Example
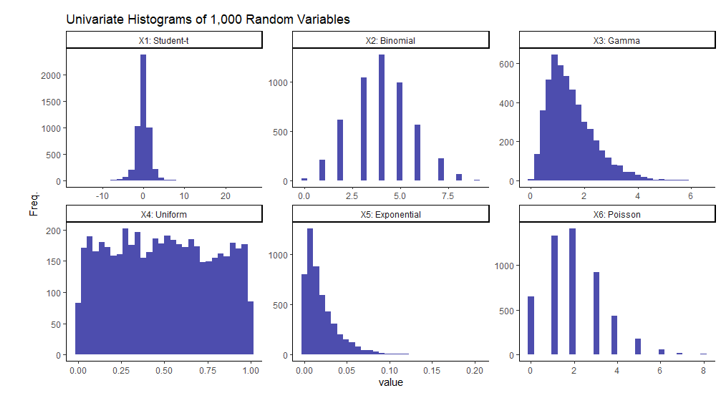
To demonstrate the versatility of this technique, I will generate a 6-dimensional data set with each column containing numerical data from various random distributions. Here are the specific distributions and parameters of each I will be using:
Note each column in this data set contains independent variables, in that no column should be correlated with another since they were created independently. This is not a requirement to use this method. It was done this way simply for simplicity and to demonstrate the paradoxical nature of this result. If you’re not entirely familiar with any or all of these distributions, I’ll include a simple visual of each of the univariate columns of the randomly generated data. This is simply one iteration of 1,000 generated random variables from each of the aforementioned distributions.
It should be clear from the histograms above that not all of these variables follow a normal distribution implying the dataset as a whole is not multivariate normal.
Since the true distributions of each are known, we know the true averages of each. The average of this multivariate dataset can be expressed in vector form with each row entry representing the average of the variable respectively. In this example,
Knowing the true averages of each variable will allow us to be able to measure how close the sample mean, or James Stein estimator gets implying the closer the better. Below is the experiment I ran in R code which generated each of the 6 random variables and tested against the true averages using the Mean Squared Error. This experiment was then ran 10,000 times using four different sample sizes: 5, 50, 500, and 5,000.
set.seed(42) ## Function to calculate Mean Squared Error ## mse <- function(x, true_value) return( mean( (x - true_value)^2 ) ) ## True Average ## mu <- c(0, 4, 1.5, 0.5, 0.02, 2) ## Store Average and J.S. Estimator Errors ## Xbar.MSE <- list(); JS.MSE <- list() for(n in c(5, 50, 500, 5000)){ # Testing sample sizes of 5, 30, 200, and 5,000 for(i in 1:1e4){ # Performing 10,000 iterations
From all 40,000 trails, the total average MSE of each sample size is computed by running the last two lines. The results of each can be seen in the table below.
The results of this of this simulation show that the James-Stein estimator is consistently better than the sample mean using the MSE, but that this difference decreases as the sample size increases.
Conclusion
The James-Stein estimator demonstrates a paradox in estimation: it is possible to improve estimates by incorporating information from seemingly independent variables. While the difference in MSE might be negligible for large sample sizes, this result sparked much debate when it was first introduced. The discovery marked a key turning point in statistical theory, and it remains relevant today for multi-parameter estimation.
[2] Stein, C. (1961). Estimation with quadratic loss. In S. S. Gupta & J. O. Berger (Eds.), Statistical Decision Theory and Related Topics (Vol. 1, pp. 361–379). Academic Press.
Stein’s Paradox was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Fundamental choices impacting integration and deployment at scale of GenAI into businesses
Before a company or a developer adopts generative artificial intelligence (GenAI), they often wonder how to get business value from the integration of AI into their business. With this in mind, a fundamental question arises: Which approach will deliver the best value on investment — a large all-encompassing proprietary model or an open source AI model that can be molded and fine-tuned for a company’s needs? AI adoption strategies fall within a wide spectrum, from accessing a cloud service from a large proprietary frontier model like OpenAI’s GPT-4o to building an internal solution in the company’s compute environment with an open source small model using indexed company data for a targeted set of tasks. Current AI solutions go well beyond the model itself, with a whole ecosystem of retrieval systems, agents, and other functional components such as AI accelerators, which are beneficial for both large and small models. Emergence of cross-industry collaborations like the Open Platform for Enterprise AI (OPEA) further the promise of streamlining the access and structuring of end-to-end open source solutions.
This basic choice between the open source ecosystem and a proprietary setting impacts countless business and technical decisions, making it “the AI developer’s dilemma.” I believe that for most enterprise and other business deployments, it makes sense to initially use proprietary models to learn about AI’s potential and minimize early capital expenditure (CapEx). However, for broad sustained deployment, in many cases companies would use ecosystem-based open source targeted solutions, which allows for a cost-effective, adaptable strategy that aligns with evolving business needs and industry trends.
GenAI Transition from Consumer to Business Deployment
When GenAI burst onto the scene in late 2022 with Open AI’s GPT-3 and ChatGPT 3.5, it mainly garnered consumer interest. As businesses began investigating GenAI, two approaches to deploying GenAI quickly emerged in 2023 — using giant frontier models like ChatGPT vs. the newly introduced small, open source models originally inspired by Meta’s LLaMa model. By early 2024, two basic approaches have solidified, as shown in the columns in Figure 1. With the proprietary AI approach, the company relies on a large closed model to provide all the needed technology value. For example, taking GPT-4o as a proxy for the left column, AI developers would use OpenAI technology for the model, data, security, and compute. With the open source ecosystem AI approach, the company or developer may opt for the right-sized open source model, using corporate or private data, customized functionality, and the necessary compute and security.
Both directions are valid and have advantages and disadvantages. It is not an absolute partition and developers can choose components from either approach, but taking either a proprietary or ecosystem-based open source AI path provides the company with a strategy with high internal consistency. While it is expected that both approaches will be broadly deployed, I believe that after an initial learning and transition period, most companies will follow the open source approach. Depending on the usage and setting, open source internal AI may provide significant benefits, including the ability to fine-tune the model and drive deployment using the company’s current infrastructure to run the model at the edge, on the client, in the data center, or as a dedicated service. With new AI fine-tuning tools, deep expertise is less of a barrier.
Figure 1. Base approaches to the AI developer’s dilemma. Image credit: Intel Labs.
Across all industries, AI developers are using GenAI for a variety of applications. An October 2023 poll by Gartner found that 55% of organizations reported increasing investment in GenAI since early 2023, and many companies are in pilot or production mode for the growing technology. As of the time of the survey, companies were mainly investing in using GenAI for software development, followed closely by marketing and customer service functions. Clearly, the range of AI applications is growing rapidly.
Large Proprietary Models vs. Small and Large Open Source Models
Figure 2: Advantages of large proprietary models, and small and large open source models. For business considerations, see Figure 7 for CapEx and OpEx aspects. Image credit: Intel Labs.
In my blog Survival of the Fittest: Compact Generative AI Models Are the Future for Cost-Effective AI at Scale, I provide a detailed evaluation of large models vs. small models. In essence, following the introduction of Meta’s LLaMa open source model in February 2023, there has been a virtuous cycle of innovation and rapid improvement where the academia and broad-base ecosystem are creating highly effective models that are 10x to 100x smaller than the large frontier models. A crop of small models, which in 2024 were mostly less than 30 billion parameters, could closely match the capabilities of ChatGPT-style large models containing well over 100B parameters, especially when targeted for particular domains. While GenAI is already being deployed throughout industries for a wide range of business usages, the use of compact models is rising.
In addition, open source models are mostly lagging only six to 12 months behind the performance of proprietary models. Using the broad language benchmark MMLU, the improvement pace of the open source models is faster and the gap seems to be closing with proprietary models. For example, OpenAI’s GPT-4o came out this year on May 13 with major multimodal features while Microsoft’s small open source Phi-3-vision was introduced just a week later on May 21. In rudimentary comparisons done on visual recognition and understanding, the models showed some similar competencies, with several tests even favoring the Phi-3-vision model. Initial evaluations of Meta’s Llama 3.2 open source release suggest that its “vision models are competitive with leading foundation models, Claude 3 Haiku and GPT4o-mini on image recognition and a range of visual understanding tasks.”
Large models have incredible all-in-one versatility. Developers can choose from a variety of large commercially available proprietary GenAI models, including OpenAI’s GPT-4o multimodal model. Google’s Gemini 1.5 natively multimodal model is available in four sizes: Nano for mobile device app development, Flash small model for specific tasks, Pro for a wide range of tasks, and Ultra for highly complex tasks. And Anthropic’s Claude 3 Opus, rumored to have approximately 2 trillion parameters, has a 200K token context window, allowing users to upload large amounts of information. There’s also another category of out-of-the-box large GenAI models that businesses can use for employee productivity and creative development. Microsoft 365 Copilot integrates the Microsoft 365 Apps suite, Microsoft Graph (content and context from emails, files, meetings, chats, calendars, and contacts), and GPT-4.
Most large and small open source models are often more transparent about application frameworks, tool ecosystem, training data, and evaluation platforms. Model architecture, hyperparameters, response quality, input modalities, context window size, and inference cost are partially or fully disclosed. These models often provide information on the dataset so that developers can determine if it meets copyright or quality expectations. This transparency allows developers to easily interchange models for future versions. Among the growing number of small commercially available open source models, Meta’s Llama 3 and 3.1 are based on transformer architecture and available in 8B, 70B, and 405B parameters. Llama 3.2 multimodal model has 11B and 90B, with smaller versions at 1B and 3B parameters. Built in collaboration with NVIDIA, Mistral AI’s Mistral NeMo is a 12B model that features a large 128k context window while Microsoft’s Phi-3 (3.8B, 7B, and 14B) offers Transformer models for reasoning and language understanding tasks. Microsoft highlights Phi models as an example of “the surprising power of small language models” while investing heavily in OpenAI’s very large models. Microsoft’s diverse interest in GenAI indicates that it’s not a one-size-fits-all market.
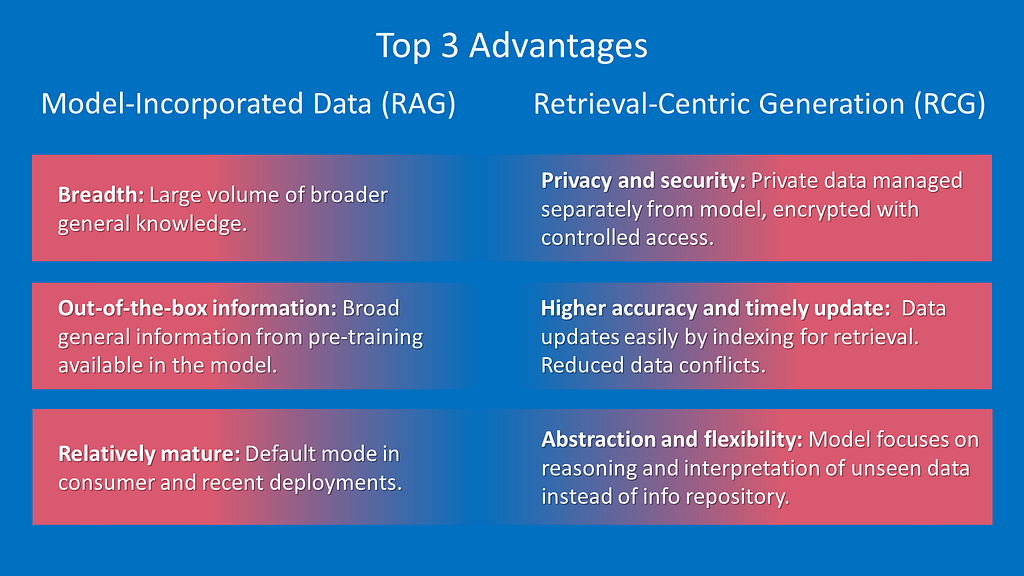
Model-Incorporated Data (with RAG) vs. Retrieval-Centric Generation (RCG)
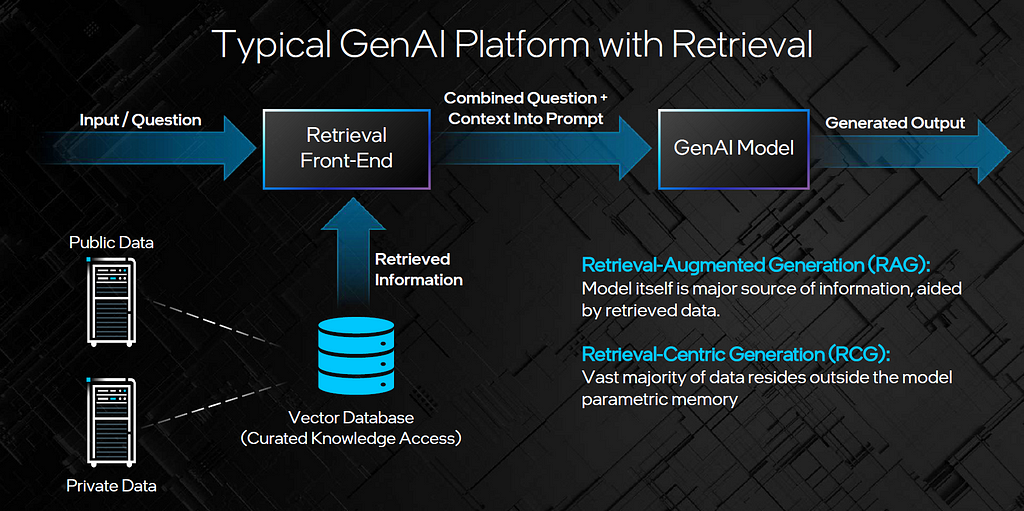
The next key question that AI developers need to address is where to find the data used during inference — within the model parametric memory or outside the model (accessible by retrieval). It might be hard to believe, but the first ChatGPT launched in November 2022 did not have any access to data outside the model. It was trained on September 21, 2022 and notoriously had no inclination of events and data past its training date. This major oversight was addressed in 2023 when retrieval plug-ins where added. Today, most models are coupled with a retrieval front-end with exceptions in cases where there is no expectation of accessing large or continuously updating information, such as dedicated programming models.
Current models have made significant progress on this issue by enhancing the solution platforms with a retrieval-augmented generation (RAG) front-end to allow for extracting information external to the model. An efficient and secure RAG is a requirement in enterprise GenAI deployment, as shown by Microsoft’s introduction of GPT-RAG in late 2023. Furthermore, in the blog Knowledge Retrieval Takes Center Stage, I cover how in the transition from consumer to business deployment for GenAI, solutions should be built primarily around information external to the model using retrieval-centric generation (RCG).
Figure 3. Advantage of RAG vs. RCG. Image credit: Intel Labs.
RCG models can be defined as a special case of RAG GenAI solutions designed for systems where the vast majority of data resides outside the model parametric memory and is mostly not seen in pre-training or fine-tuning. With RCG, the primary role of the GenAI model is to interpret rich retrieved information from a company’s indexed data corpus or other curated content. Rather than memorizing data, the model focuses on fine-tuning for targeted constructs, relationships, and functionality. The quality of data in generated output is expected to approach 100% accuracy and timeliness.
Figure 4. How retrieval works in GenAI platforms. Image credit: Intel Labs.
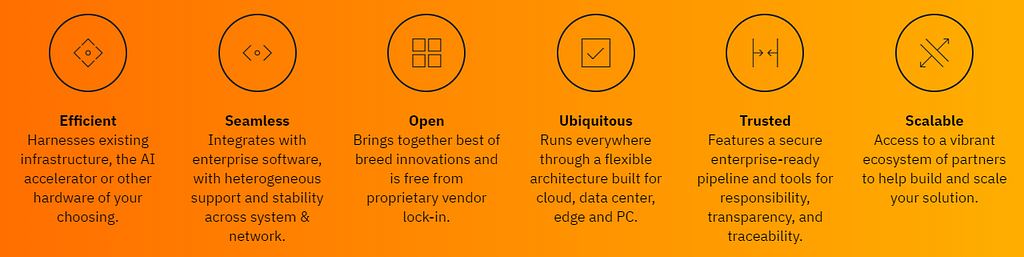
OPEA is a cross-ecosystem effort to ease the adoption and tuning of GenAI systems. Using this composable framework, developers can create and evaluate “open, multi-provider, robust, and composable GenAI solutions that harness the best innovation across the ecosystem.” OPEA is expected to simplify the implementation of enterprise-grade composite GenAI solutions, including RAG, agents, and memory systems.
Figure 5. OPEA core principles for GenAI implementation.Image credit: OPEA.
All-in-One General Purpose vs. Targeted Customized Models
Models like GPT-4o, Claude 3, and Gemini 1.5 are general purpose all-in-one foundation models. They are designed to perform a broad range of GenAI from coding to chat to summarization. The latest models have rapidly expanded to perform vision/image tasks, changing their function from just large language models to large multimodal models or vision language models (VLMs). Open source foundation models are headed in the same direction as integrated multimodalities.
Figure 6. Advantages of general purpose vs. targeted customized models. Image credit: Intel Labs.
However, rather than adopting the first wave of consumer-oriented GenAI models in this general-purpose form, most businesses are electing to use some form of specialization. When a healthcare company deploys GenAI technology, they would not use one general model for managing the supply chain, coding in the IT department, and deep medical analytics for managing patient care. Businesses deploy more specialized versions of the technology for each use case. There are several different ways that companies can build specialized GenAI solutions, including domain-specific models, targeted models, customized models, and optimized models.
Domain-specific models are specialized for a particular field of business or an area of interest. There are both proprietary and open source domain-specific models. For example, BloombergGPT, a 50B parameter proprietary large language model specialized for finance, beats the larger GPT-3 175B parameter model on various financial benchmarks. However, small open source domain-specific models can provide an excellent alternative, as demonstrated by FinGPT, which provides accessible and transparent resources to develop FinLLMs. FinGPT 3.3 uses Llama 2 13B as a base model targeted for the financial sector. In recent benchmarks, FinGPT surpassed BloombergGPT on a variety of tasks and beat GPT-4 handily on financial benchmark tasks like FPB, FiQA-SA, and TFNS. To understand the tremendous potential of this small open source model, it should be noted that FinGPT can be fine-tuned to incorporate new data for less than $300 per fine-tuning.
Targeted models specialize in a family of tasks or functions, such as separate targeted models for coding, image generation, question answering, or sentiment analysis. A recent example of a targeted model is SetFit from Intel Labs, Hugging Face, and the UKP Lab. This few-shot text classification approach for fine-tuning Sentence Transformers is faster at inference and training, achieving high accuracy with a small number of labeled training data, such as only eight labeled examples per class on the Customer Reviews (CR) sentiment dataset. This small 355M parameter model can best the GPT-3 175B parameter model on the diverse RAFT benchmark.
It’s important to note that targeted models are independent from domain-specific models. For example, a sentiment analysis solution like SetFitABSA has targeted functionality and can be applied to various domains like industrial, entertainment, or hospitality. However, models that are both targeted and domain specialized can be more effective.
Customized models are further fine-tuned and refined to meet particular needs and preferences of companies, organizations, or individuals. By indexing particular content for retrieval, the resulting system becomes highly specific and effective on tasks related to this data (private or public). The open source field offers an array of options to customize the model. For example, Intel Labs used direct preference optimization (DPO) to improve on a Mistral 7B model to create the open source Intel NeuralChat. Developers also can fine-tune and customize models by using low-rank adaptation of large language (LoRA) models and its more memory-efficient version, QLoRA.
Optimization capabilities are available for open source models. The objective of optimization is to retain the functionality and accuracy of a model while substantially reducing its execution footprint, which can significantly improve cost, latency, and optimal execution of an intended platform. Some techniques used for model optimization include distillation, pruning, compression, and quantization (to 8-bit and even 4-bit). Some methods like mixture of experts (MoE) and speculative decoding can be considered as forms of execution optimization. For example, GPT-4 is reportedly comprised of eight smaller MoE models with 220B parameters. The execution only activates parts of the model, allowing for much more economical inference.
Generative-as-a-Service Cloud Execution vs. Managed Execution Environment for Inference
Figure 7. Advantages of GaaS vs. managed execution. Image credit: Intel Labs.
Another key choice for developers to consider is the execution environment. If the company chooses a proprietary model direction, inference execution is done through API or query calls to an abstracted and obscured image of the model running in the cloud. The size of the model and other implementation details are insignificant, except when translated to availability and the cost charged by some key (per token, per query, or unlimited compute license). This approach, sometimes referred to as a generative-as-a-service (GaaS) cloud offering, is the principle way for companies to consume very large proprietary models like GPT-4o, Gemini Ultra, and Claude 3. However, GaaS can also be offered for smaller models like Llama 3.2.
There are clear positive aspects to using GaaS for the outsourced intelligence approach. For example, the access is usually instantaneous and easy to use out-of-the-box, alleviating in-house development efforts. There is also the implied promise that when the models or their environment get upgraded, the AI solution developers have access to the latest updates without substantial effort or changes to their setup. Also, the costs are almost entirely operational expenditures (OpEx), which is preferred if the workload is initial or limited. For early-stage adoption and intermittent use, GaaS offers more support.
In contrast, when companies choose an internal intelligence approach, the model inference cycle is incorporated and managed within the compute environment and the existing business software setting. This is a viable solution for relatively small models (approximately 30B parameters or less in 2024) and potentially even medium models (50B to 70B parameters in 2024) on a client device, network, on-prem data center, or on-cloud cycles in an environment set with a service provider such as a virtual private cloud (VPC).
Models like Llama 3.1 8B or similar can run on the developer’s local machine (Mac or PC). Using optimization techniques like quantization, the needed user experience can be achieved while operating within the local setting. Using a tool and framework like Ollama, developers can manage inference execution locally. Inference cycles can be run on legacy GPUs, Intel Xeon, or Intel Gaudi AI accelerators in the company’s data center. If inference is run on the model at a service provider, it will be billed as infrastructure-as-a-service (IaaS), using the company’s own setting and execution choices.
When inference execution is done in the company compute environment (client, edge, on-prem, or IaaS), there is a higher requirement for CapEx for ownership of the computer equipment if it goes beyond adding a workload to existing hardware. While the comparison of OpEx vs. CapEx is complex and depends on many variables, CapEx is preferable when deployment requires broad, continuous, stable usage. This is especially true as smaller models and optimization technologies allow for running advanced open source models on mainstream devices and processors and even local notebooks/desktops.
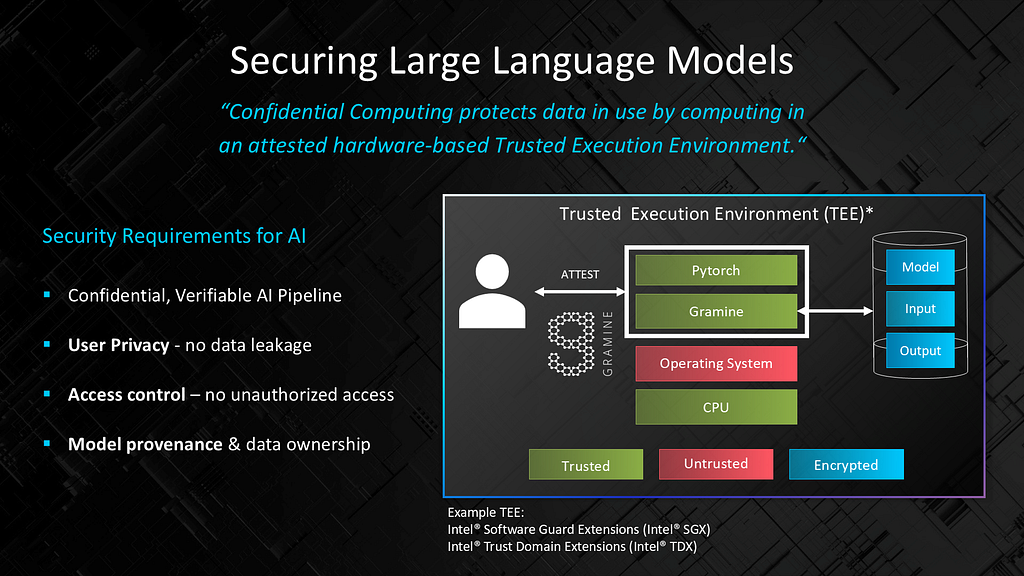
Running inference in the company compute environment allows for tighter control over aspects of security and privacy. Reducing data movement and exposure can be valuable in preserving privacy. Furthermore, a retrieval-based AI solution run in a local setting can be supported with fine controls to address potential privacy concerns by giving user-controlled access to information. Security is frequently mentioned as one of the top concerns of companies deploying GenAI and confidential computing is a primary ask. Confidential computing protects data in use by computing in an attested hardware-based Trusted Execution Environment (TEE).
Smaller, open source models can run within a company’s most secure application setting. For example, a model running on Xeon can be fully executed within a TEE with limited overhead. As shown in Figure 8, encrypted data remains protected while not in compute. The model is checked for provenance and integrity to protect against tampering. The actual execution is protected from any breach, including by the operating system or other applications, preventing viewing or alteration by untrusted entities.
Figure 8. Security requirements for GenAI. Image credit: Intel Labs.
Summary
Generative AI is a transformative technology now under evaluation or active adoption by most companies across all industries and sectors. As AI developers consider their options for the best solution, one of the most important questions they need to address is whether to use external proprietary models or rely on the open source ecosystem. One path is to rely on a large proprietary black-box GaaS solution using RAG, such as GPT-4o or Gemini Ultra. The other path uses a more adaptive and integrative approach — small, selected, and exchanged as needed from a large open source model pool, mainly utilizing company information, customized and optimized based on particular needs, and executed within the existing infrastructure of the company. As mentioned, there could be a combination of choices within these two base strategies.
I believe that as numerous AI solution developers face this essential dilemma, most will eventually (after a learning period) choose to embed open source GenAI models in their internal compute environment, data, and business setting. They will ride the incredible advancement of the open source and broad ecosystem virtuous cycle of AI innovation, while maintaining control over their costs and destiny.
Let’s give AI the final word in solving the AI developer’s dilemma. In a staged AI debate, OpenAI’s GPT-4 argued with Microsoft’s open source Orca 2 13B on the merits of using proprietary vs. open source GenAI for future development. Using GPT-4 Turbo as the judge, open source GenAI won the debate. The winning argument? Orca 2 called for a “more distributed, open, collaborative future of AI development that leverages worldwide talent and aims for collective advancements. This model promises to accelerate innovation and democratize access to AI, and ensure ethical and transparent practices through community governance.”
Matthew Berman. (2024, June 2). Open-Source Vision AI — Surprising Results! (Phi3 Vision vs LLaMA 3 Vision vs GPT4o) [Video]. YouTube. https://www.youtube.com/watch?v=PZaNL6igONU
Wu, S., Irsoy, O., Lu, S., Dabravolski, V., Dredze, M., Gehrmann, S., Kambadur, P., Rosenberg, D., & Mann, G. (2023, March 30). BloombergGPT: A large language model for finance. arXiv.org. https://arxiv.org/abs/2303.17564
Yang, H., Liu, X., & Wang, C. D. (2023, June 9). FINGPT: Open-Source Financial Large Language Models. arXiv.org. https://arxiv.org/abs/2306.06031
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021, June 17). LORA: Low-Rank adaptation of Large Language Models. arXiv.org. https://arxiv.org/abs/2106.09685
Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023, May 23). QLORA: Efficient Finetuning of Quantized LLMS. arXiv.org. https://arxiv.org/abs/2305.14314
Leviathan, Y., Kalman, M., & Matias, Y. (2022, November 30). Fast Inference from Transformers via Speculative Decoding. arXiv.org. https://arxiv.org/abs/2211.17192
Data Centric. (2023, November 30). Surprising Debate Showdown: GPT-4 Turbo vs. Orca-2–13B — Programmed with AutoGen! [Video]. YouTube. https://www.youtube.com/watch?v=JuwJLeVlB-w
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.