Pushing quantization to its limits by performing it at the feature level with ft-Quantization (ft-Q)
***To understand this article, knowledge of embeddings and basic quantization is required. The implementation of this algorithm has been released on GitHub and is fully open-source.
Since the dawn of LLMs, quantization has become one of the most popular memory-saving techniques for production-ready applications. Not long after, it has been popularized across vector databases, which have started using the same technology for compressing not only models but also vectors for retrieval purposes.
In this article, I will showcase the limitations of the current quantization algorithms and propose a new quantization approach (ft-Q) to address them.
What is Quantization and how does it work?
Quantization is a memory-saving algorithm that lets us store numbers (both in-memory and in-disk) using a lower amount of bits. By default, when we store any number in memory, we use float32: this means that this number is stored using a combination of 32-bits (binary elements).
For example, the integer 40 is stored as follows in a 32-bit object:
storing the number 40 in a 32-bit object, image by Author
However, we could decide to store the same number using fewer bits (cutting by half the memory usage), with a 16-bit object:
storing the number 40 in a 16-bit object, image by Author
By quantization, we mean to store data using a lower number of bits (ex. 32 -> 16, or 32 -> 4), this is also known as casting. If we were to store 1GB of numbers (by default stored as 32-bit objects), if we decided to store them using 16-bit objects (hence, applying a quantization), the size of our data would be halved, resulting in 0.5GB.
Is there a catch to quantization?
Saving this amount of storage looks incredible (as you understood, we could keep cutting until we reach the minimum amount of bits: 1-bit, also known as binary quantization. Our database size will be reduced by 32 times, from 1GB to 31.25MB!), but as you might have already understood, there is a catch.
Any number can be stored up to the limits allowed by all the possible combinations of bits. With a 32-bit quantization, you can store a maximum of 2³² numbers. There are so many possible combinations that we decided to include decimals when using 32-bits. For example, if we were to add a decimal to our initial number and store 40.12 in 32-bits, it would be using this combination of 1 and 0:
01000010 00100000 01111010 11100001
We have understood that with a 32-bit storage (given its large combination of possible values) we can pretty much encode each number, including its decimal points (to clarify, if you are new to quantization, the real number and decimal are not separated, 40.12 is converted as a whole into a combination of 32 binary numbers).
If we keep diminishing the number of bits, all the possible combinations diminish exponentially. For example, 4-bit storage has a limit of 2⁴ combinations: we can only store 16 numbers (this does not leave much room to store decimals). With 1-bit storage, we can only store a single number, either a 1 or a 0.
To put this into context, storing our initials 32-bit numbers into binary code would force us to convert all our numbers, such as 40.12 into either 0 or 1. In this scenario, this compression does not look very good.
How to make the best out of Quantization
We have seen how quantization results in an information loss. So, how can we make use of it, after all? When you look at the quantization of a single number (40.12 converted into 1), it seems there is no value that can derive from such an extreme level of quantization, there is simply too much loss.
However, when we apply this technique to a set of data such as vectors, the information loss is not as drastic as when applied to a single number. Vector search is a perfect example of where to apply quantization in a useful manner.
When we use an encoder, such as all-MiniLM-L6-v2, we store each sample (which was originally in the form of raw text) as a vector: a sequence of 384 numbers. The storage of millions of similar sequences, as you might have understood, is prohibitive, and we can use quantization to substantially diminish the size of the original vectors by a huge margin.
Perhaps, quantizing our vectors from 32-bit to 16-bit is not this big of a loss. But how about 4-bit or even binary quantization? Because our sets are relatively large (384 numbers each), this considerable complexity lets us reach a higher level of compression without resulting in excessive retrieval loss.
4-bit quantization
The way we execute quantization is by looking at the data distribution of our flattened vector and choosing to map an equivalent interval with a lower number of bits. My favorite example is 4-bit quantization. With this degree of complexity, we can store 2⁴ = 16 numbers. But, as explained, all the numbers in our vectors are complex, each with several decimal points:
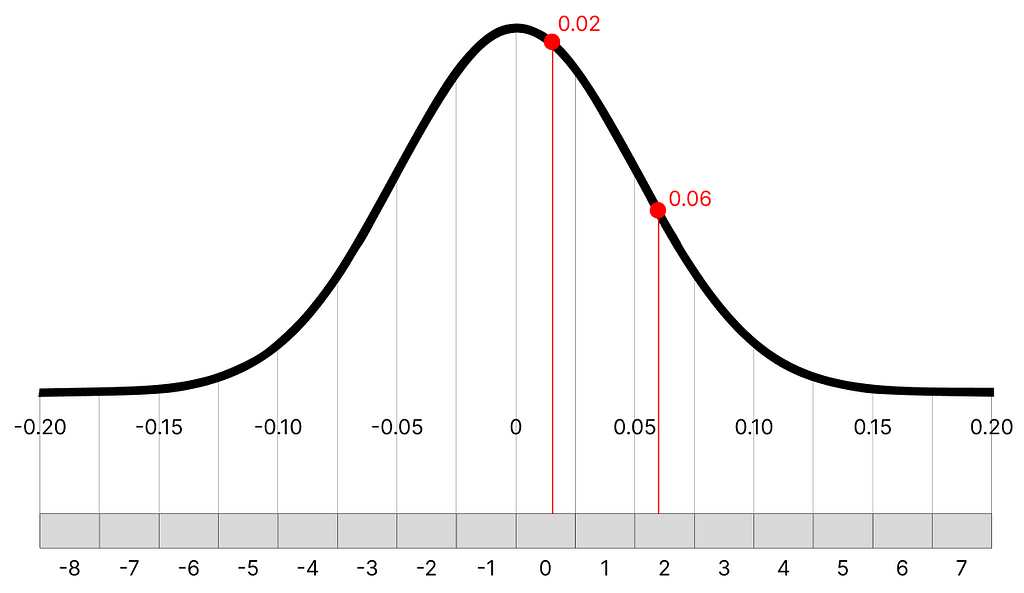
What we can do is map each of our numbers in the distribution into an interval that spans between [-8, 7] (16 possible numbers). To define the extreme of the interval, we can use the minimum and maximum values of the distribution we are quantizing.
4-bit quantization: the grey area is an interval of integers between [-8, 7], don’t confuse it with bits. Any number of this interval will be later converted into a 4-bit object, image by Author
For example, the minimum/maximum of the distribution is [-0.2, 0.2]. This means that -0.2 will be converted to -8, and 0.2 to 7. Each number in the distribution will have a quantized equivalent in the interval (ex. the first number 0.02436554 will be quantized to -1).
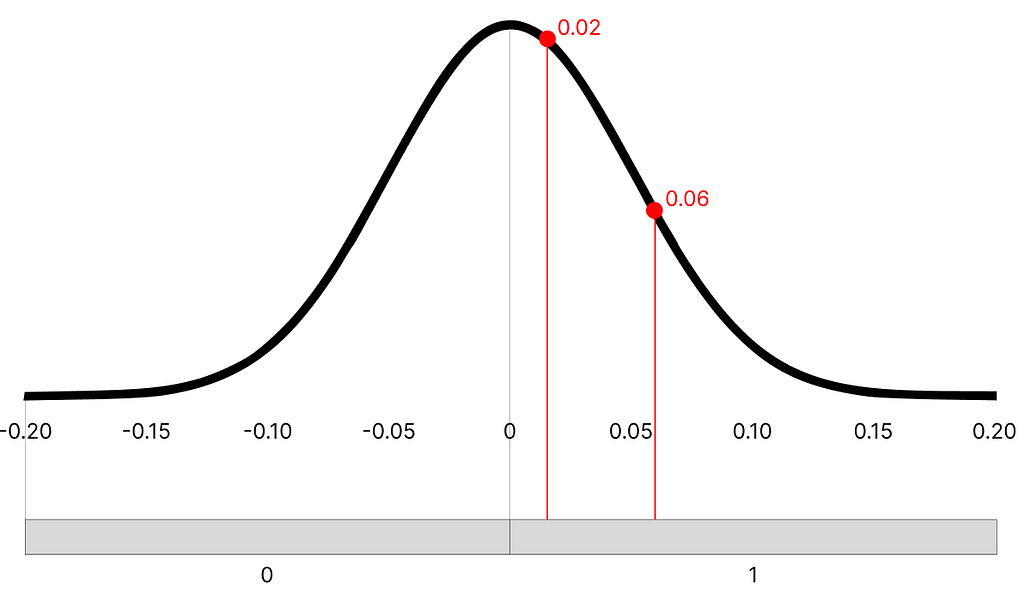
The same principle applies to binary quantization but is much simpler. The rule is the following: each number of the distribution < 0 becomes 0, and each number > 0 becomes 1.
1-bit quantization, image by Author
Not all embeddings are built the same
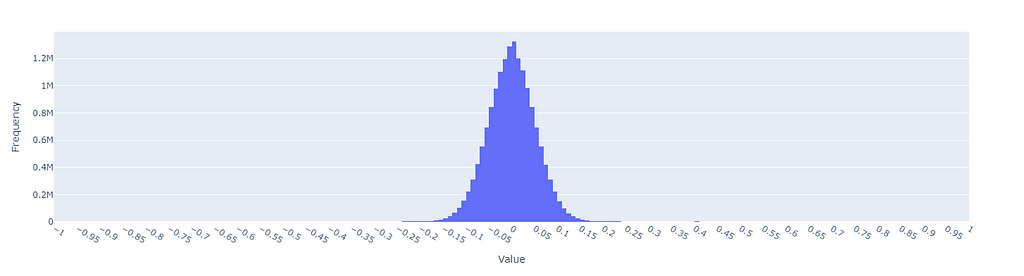
The principal issue with current quantization techniques is that they live on the assumption that all our values are based on a single distribution. That is why, when we use thresholds to define intervals (ex. minimum and maximum), we only use a single set derived from the totality of our data (which is modeled on a single distribution).
distribution of all individual samples from a flattened encoded dataset, image by Author
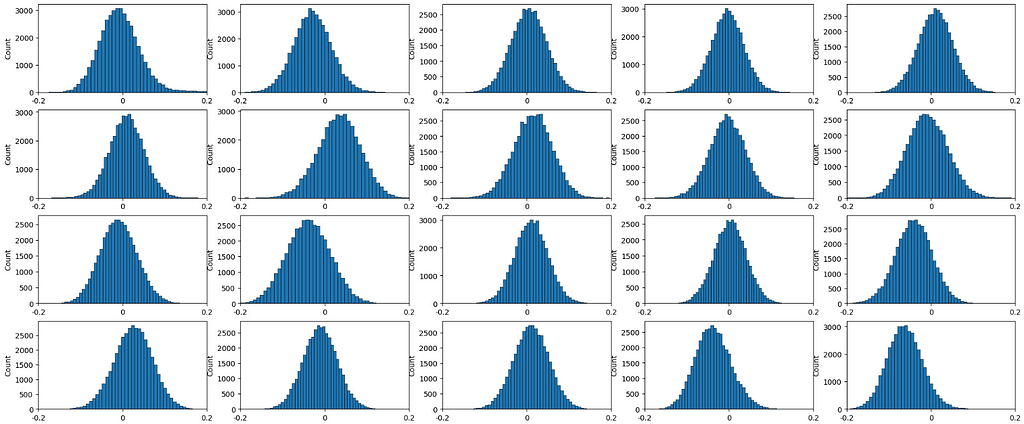
In an experiment, I have encoded 40.000 game descriptions into vectors. By looking at the data distributions of each feature, we can see that despite the efforts, there is no feature which is perfectly normalized: its mean could deviate from the target 0.
distributions of 20 random features of the encoded dataset, image by Author
In a few words, each feature can be modeled with a dedicated distribution. Because the data does not follow a single giant distribution, we can leverage the many ways this is organized by applying a quantization at the feature level. In addition, embeddings tend to encode each feature using similar values (otherwise, the mean will constantly be 0), which means there is a minimal chance of drift when encoding additional data.
To better explain the math, let us define two sets of values: S = all the individual samples from the encoded dataset (41936 * 384) Fₙ = all the individual samples from the encoded dataset belonging to a single feature (41936 * 1)
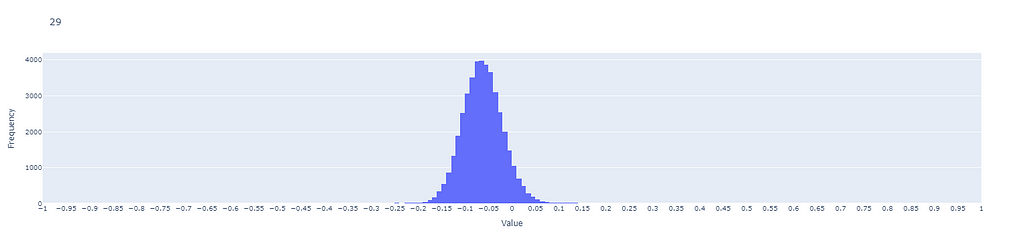
Feature 29: The Ugly Duckling
In our sample dataset, each vector counts 384 features. However, by exploring the data one feature at a time, we can notice that some are not perfectly normalized but substantially skewed. Let us take F₂₉as an example: the following plot shows the distribution of F₂₉ (41936) across our entire encoded dataset.
F₂₉ distribution, image by Author
As we can see from the plot, its distribution mean is around -0.07, and its edges are (-0.2, 0.05). I am confident, knowing how encoders behave, that no matter the amount of extra data we are going to feed the model, F₂₉ will always remain an Ugly Duckling, with its distribution untouched. The distribution only counts a few positive values.
Regular Quantization
Now, let us apply binary quantization to the book, but only to F₂₉. I am choosing a binary approach because most of the information is lost, meaning there can be room for improvement using a different approach.
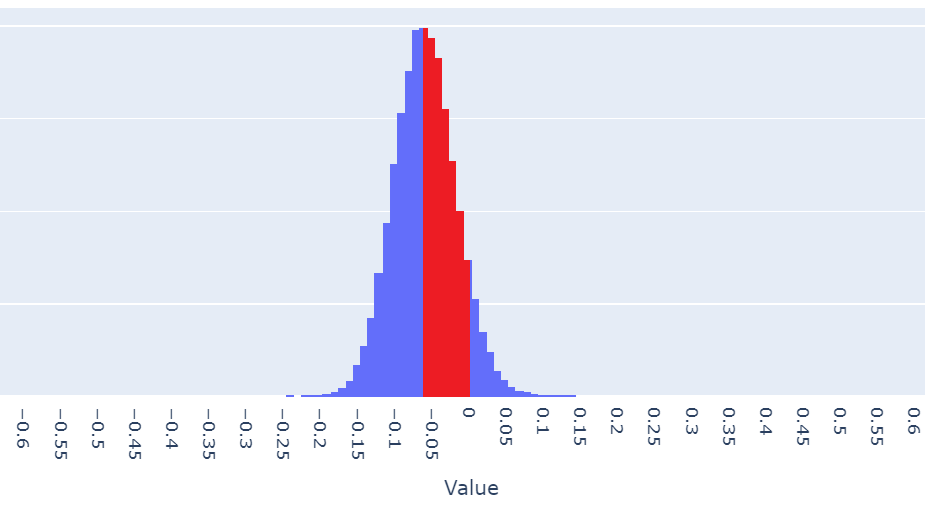
To quantize values in a binary fashion we need to pick a single value that will work as a threshold when converting values to either 0 or 1. The easiest way is to pick 0 (~ the distribution mean of S). When working on the values of F₂₉, because most of them are negative, the majority will be quantized to 0, and only a few will be quantized to 1.
samples whose quantized value should be 1, but quantized as 0: 44% of F₂₉, image by Author
Let us explore the data further: 94% of the F₂₉ have been converted to 0, while our target in a perfectly normalized distribution is 50%. This means that 44% of F₂₉ (red area of the density distribution) has not been properly quantized.
# we count the number of 0 over the total number of values >>> 1-quantized_regular[:, 29].sum()/sample_vectors[:, 29].size 0.9424122472338802
ft-Quantization
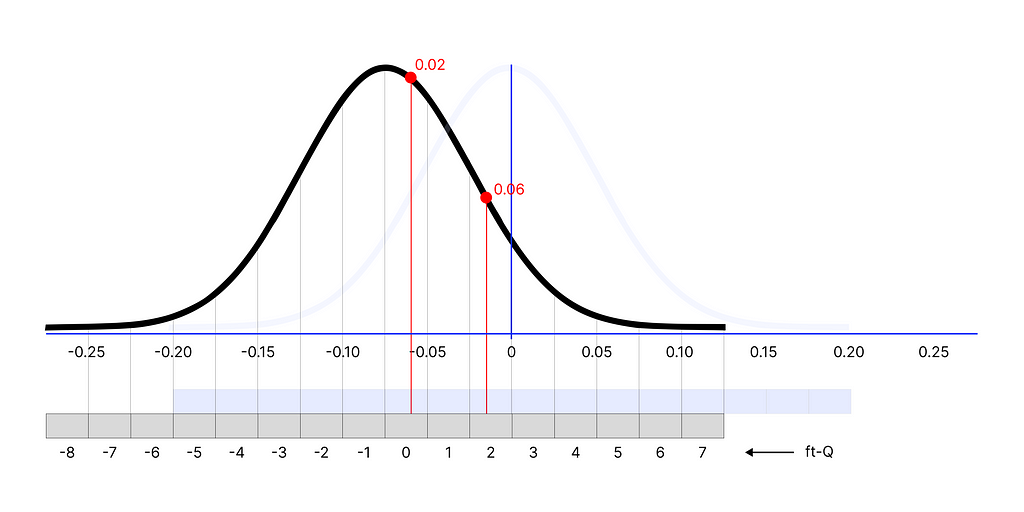
What if, instead of using 0 as a threshold (extracted from S) we were to use the F₂₉ distribution as a benchmark? Looking at F₂₉ distribution again, instead of 0, we would be using its mean ~ -0.07 and its extremes as the minimum/maximum of the interval ~ [-0.25, 0.15]. In simple words, ft-Q shifts the position of the reference quantization interval to better fit the real distribution of the data.
visualization of ft-Q, the interval is adapted to the feature distribution, image by Author
***Through the following article I am trying to introduce a new algorithm that, to the extent of my knowledge, I have been unable to find elsewhere. Note that the algorithm is different from FQ (feature quantization) that is used for training neural networks, this is algorithm is supposed to be used post-training. I am open to criticism and welcome any feedback.
After applying binary quantization to F₂₉, because the threshold has been updated, we can see how half the times the data will be quantized to 0, and the other half to 1, resulting in a more realistic representation of the data. By comparing the quantization results, ft-Q has converted 47% of the F₂₉ into 0, resulting in only 3% of values not being properly quantized.
# we count the number of 0 over the total number of values >>> 1-quantized_tfQ[:, 29].sum()/sample_vectors[:, 29].size 0.46809423884013734
To summarize, ft-Q (or ft-Quantization) encodes each feature individually, minimizing errors that can occur from non-normalized distributions.
When to use ft-Quantization
Realistically, no embedding is perfectly normalized, and there is a variance (despite it being minimal) across the feature distribution. However, now that we have identified the misplaced values, we can adjust them using ft-Q.
Can ft-Q be applied to regular embeddings?
When ft-Q is applied to regular embeddings we are not looking at a substantial enhancement.
In the case of all-MiniLM-L6-v2 we have reached a 1.2% improvement (not remarkable, but still an upgrade).
Where ft-Q shines: processed embeddings
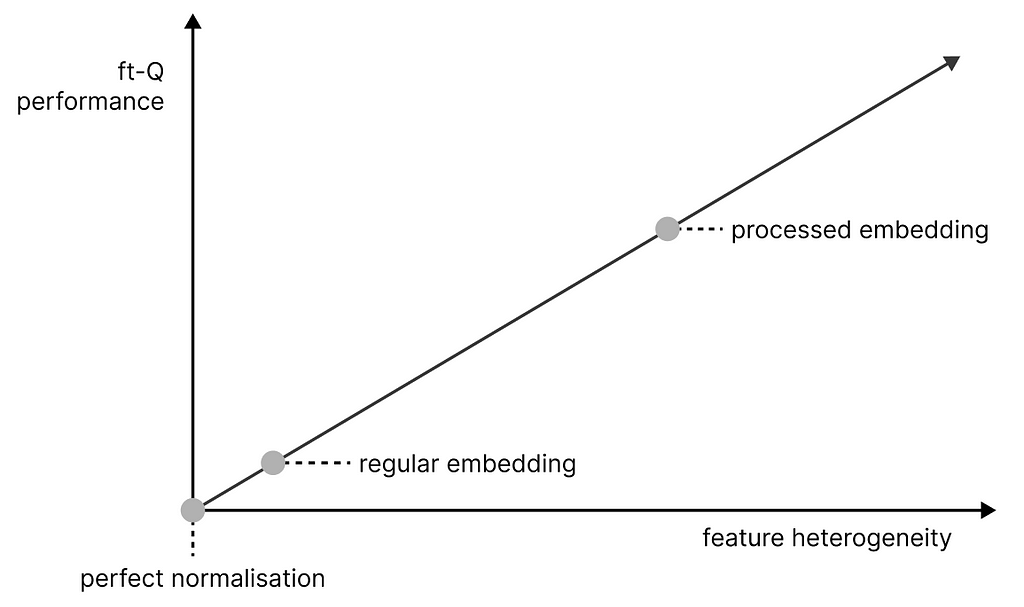
However, embeddings are not always used in their normalized form. Sometimes, there are use cases where encoding requires the embedding to be processed (ex. in the case of covariate encoding). We can use the following theoretical diagram as a way to understand in which cases ft-Q can be better utilized:
the more the feature skew from a perfect normalisation, the more ft-Q is effective, image by Author
The vectors that are the result of an extra processing step are not necessarily normalized: we could normalize them again and only then apply quantization, but we can cast two birds with one stone by using ft-Q as a single operation (in addition to its small improvement even after a non-perfect normalization).
Conclusion
In conclusion, this article attempts to propose a more granular approach to quantization. Originally, the reason for developing this algorithm was to solve performance issues of processed embeddings, but after proper experimentation, it has proved useful even in a regular scenario.
After the popularization of LLM and more complex vector databases, memory management and performance improvements are becoming increasingly relevant in the space of information retrieval, hence it is our responsibility to familiarize ourselves with them and propose new and better solutions.
Time will tell if new and smarter data compression approaches will join the scene. For now, you can make the best use of this algorithm.
We’re excited to announce the availability of Meta Llama 3.1 8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. Trainium and Inferentia, enabled by the AWS Neuron software development kit (SDK), offer high performance and lower the cost of deploying Meta Llama 3.1 by up to 50%. In this post, we demonstrate how to deploy Meta Llama 3.1 on Trainium and Inferentia instances in SageMaker JumpStart.
Amazon Web Services (AWS) is excited to be the first major cloud service provider to announce ISO/IEC 42001 accredited certification for the following AI services: Amazon Bedrock, Amazon Q Business, Amazon Textract, and Amazon Transcribe. ISO/IEC 42001 is an international management system standard that outlines requirements and controls for organizations to promote the responsible development and use of AI systems.
NuCS is a Python library for solving Constraint Satisfaction and Optimisation Problems (CSP and COP) that I am developing as a side project. Because it is 100% written in Python, NuCS is easy to install and allows to model complex problems in a few lines of code. The NuCS solver is also very fast because it is powered by Numpy and Numba.
Many problems can be formulated as CSPs. This is why a constraint library such as NuCS can benefit a lot of developers or data scientists.
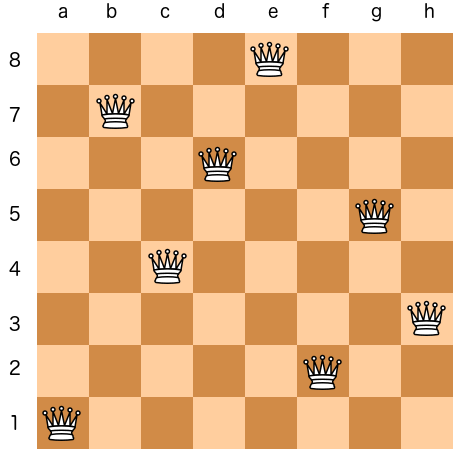
Let’s consider the famous N-queens problem which consists in placing N queens on a N x N chessboard such that the queens don’t threaten each other.
A solution to the 8-queens problem. Source: Yue Guo
The 14200 solutions to the 12-queens problems are found in less than 2s on a MacBook Pro M2 running:
Constraint programming is a paradigm for solving combinatorial problems. In constraint programming, users declaratively state the constraints on the feasible solutions for a set of decision variables. Constraints specify the properties of a solution to be found. The solver combines constraint propagation and backtracking to find the solutions.
As an example, here is a model for the Magic Sequence Problem (find a sequence x_0, … x_n-1 such that, for each i in [0, n-1],x_i is the number of occurrences of i in the sequence) using NuCS:
class MagicSequenceProblem(Problem): def __init__(self, n: int): super().__init__([(0, n)] * n) for i in range(n): self.add_propagator((list(range(n)) + [i], ALG_COUNT_EQ, [i])) # redundant constraints self.add_propagator((list(range(n)), ALG_AFFINE_EQ, [1] * n + [n])) self.add_propagator((list(range(n)), ALG_AFFINE_EQ, list(range(n)) + [n]))
In NuCS, a constraint is named a propagator.
The propagator (here ALG_COUNT_EQ) simply states that x_i is the number of occurrences of i in the sequence. The following two ALG_AFFINE_EQ propagators are redundant, meaning that they are not necessary for NuCS to find the solution but they speed up the resolution process.
See the documentation for a complete list of propagator supported by NuCS. Note that most propagators in NuCS are global (aka n-ary) and implement state-of-art propagation algorithms.
Python
Python is the language of choice for data scientists: it has a simple syntax, a growing community and a great number of data science and machine learning libraries.
But on the other hand, Python is known to be a slow language : maybe 50 to 100 times slower than C depending on the benchmarks.
The choice of Python for developing a high performance constraint programming library was not so obvious but we will see that the combined use of Numpy (high performance computing package) and Numba (Just-In-Time compilation for Python) helps a lot.
Many attempts have been made to write constraint solvers in Python, but these are either slow or are only wrappers and depend on external solvers written in Java or C/C++.
Numpy
NumPy brings the computational power of languages like C and Fortran to Python.
Thanks to Numpy and Numba, NuCS achieves performance similar to that of solvers written in Java or C/C++.
Note that, since the Python code is compiled and the result cached, performance will always be significantly better when you run your program a second time.
Examples
NuCS comes with many models for classic constraint programming problems such as:
some crypto-arithmetic puzzles: Alpha, Donald,
the Balanced Incomplete Block Design problem,
the Golomb ruler problem,
the knapsack problem,
the magic sequence problem,
the magic square problem,
the quasigroup problem,
the n-queens problem,
the Schur lemma problem,
the sports tournament scheduling problem,
the Sudoku problem.
Some of these examples require some advanced techniques:
redundant constraints,
custom heuristics,
custom consistency algorithms
Most of these models are also available in CSPLib, the bible for anything CSP related.
Statistics and Logging
When solutions are searched for, NuCS also aggregates some statistics:
In conclusion, NuCS is a constraint solver library with a lot of features. Although it is written entirely in Python, it is very fast and can be used for a wide range of applications: research, teaching and production.
Don’t hesitate to contact me on Github if you’d like to take part in NuCS development!
The Economics of Artificial Intelligence — What Does Automation Mean for Workers?
Despite tremendous progress in AI, the economic implications of AI remain inadequately understood, with unsatisfactory insights from AI practitioners and economists
Generative AI has rapidly swept across society, with revolutionary tools like ChatGPT, Claude, and Midjourney amassing millions of users at an unprecedented rate. Numerous software applications, ranging from the sleep tracker app Sleep Cycle (that I personally use), to office productivity tools such as Slack and Teams, are racing to integrate AI capabilities.
The technology behind AI has advanced at a remarkable pace. The intelligence of leading models is evolving at breakneck speed — GPT-2 (2019) was struggled to form coherent sentences. Just 4 years later, GPT-4 has surpassed the capabilities of most high-schoolers across tasks from competition math to AP exams¹. Furthermore, the cost ofrunning AI models is plummeting by orders of magnitude — GPT-4o mini, which OpenAI unveiled in July 2024, achieves performance comparable to the original GPT-4 released in March 2023, at 1/200th of the cost². And there is no sign of this progress stopping.³
As a result, there is a growing recognition that AI will fundamentally reshape society and the economy in profound, unprecedented ways.
But what impact will AI have on the economy? Unfortunately, this is a significant question that, in my view, remains unanswered in any satisfactory manner.
The current focus of the AI community is on designing new architectures and developing cutting-edge products. AI practitioners and builders concentrate on improving model performance, only considering economic factors when it concerns potential users and the market for their innovations.
Economists, on the other hand, develop rigorous models and theories on automation, substitution, and complementarity. Yet, as they often operate outside the AI space, they are out of sync with the latest AI advancements and how organisations are adopting these technologies. This disconnect can lead to fundamental misunderstandings of AI’s potential, resulting in pessimistic assessments: 2024 Nobel Prize winner Daron Acemoglu recently estimated that AI would increase productivity by merely 0.7% cumulatively over the next decade⁴.
Meanwhile, think tanks and consultants arguably suffer the worst of both worlds. They release headline-grabbing reports, with bold claims like “60% of jobs in advanced economies may be impacted by AI” ⁵ or “AI will contribute $15 trillion to the economy” ⁶. However, these reports rarely provide clarity on what terms like “impacted jobs” or “contributing to the economy” mean concretely, nor do they stay current with the latest AI releases and their implications.
I believe that my position at the intersection of economics and AI offers a unique perspective. As a research economist focusing on productivity, innovation, and macro-modeling — and as an AI builder and enthusiast who has created multiple AI tools while keeping abreast of the latest industry trends, I see a need for a deeper understanding of AI’s economic implications. The recent appointment of Dr. Ronnie Chatterjee as OpenAI’s first chief economist⁷ underscores the growing acknowledgment within the AI industry of the critical role that economics plays in shaping its trajectory.
This is the first of, hopefully, a series of articles exploring the economic impacts of AI. In this piece, I will investigate the impact of AI on jobs through the lens of a widely-used economic framework by David Autor and Daron Acemoglu, while introducing a novel extension that incorporates the latest findings from the AI field.
Future articles will explore AI’s effects on: 1) the production of inputs for AI (such as chips and energy), 2) innovation and R&D, and 3) macroeconomic outcomes like productivity growth. Together, these explorations aim to provide a comprehensive and nuanced view of AI from an economist’s lens.
Introduction to Economic Model
To ground our discussion in an economic framework, let me explain the task-based framework that Acemoglu & Restrepo (2018)⁸ introduced, which has since been popularised in the economics literature⁹. Once you’re done reading this article, you can now consider yourself an emerging economist, having engaged with a rigorous and seminal economic paper!
Source: Acemoglu & Autor (2022)
The economy consists of firms producing output. A firm’s output (ye) is produced by combining various tasks (x) in the production process, each with a different importance (a(x)) in contributing to the final output.
Turning to the task-specific production function on the right, we see that a task can be produced using these factors of production: human labor (le), by AI (ae), or a combination of the two.
Workers are employed in different occupations, with each occupation involved in one or more tasks in the production process.
Labour and AI each have a term denoting factor-specific productivity. For labour, this refers to human capital — e.g., a more experienced economist can write better papers, faster, than a junior one. For AI, this incorporates technological change — e.g., a more powerful computer can conduct simulations twice the speed of the previous generation.
The term sigma determines the degree of substitutability between labour and AI. The higher the value of sigma, the higher the substitutability between labour and AI in the task.
· If sigma is infinity, labour and AI are perfectly substitutable within a task. For example, human cashiers and self-checkout counters in supermarkets are substitutable, for the task of checking out simple customer purchases.
· In other cases, labour and AI are complementary, or both necessary to complete the task. For example, for an econometric study to be completed, an economist has to use computer software to run regressions and do data analysis. However, the computer cannot do the study himself, as the economist needs to collect the data, interpret the regression results and write a paper presenting the findings.
Impact of an Advancement in AI
Now, suppose a new AI innovation has been released. For example, OpenAI releases Sora¹⁰, an AI video generation tool that can make realistic videos in minutes. Let’s analyse the impact of this innovation on a firm that helps businesses create marketing videos. This firm’s production process involves two tasks: creating and editing videos (Task A) and customer service with clients (Task B).
An AI innovation increases the productivity of AI, in Task A of generating videos, increasing the Marginal Product of AI. What is the impact on employment? As I hinted earlier, it depends on how substitutable labour and AI are for this task, or the value of sigma.
Employment decreases if labour and AI are highly substitutable. In this case, because producing a given video has become relatively cheaper for AI as compared to labour, firms will replace labour with AI in that task’s production. Hence, the share of labour in the production of Task A declines, and the share of AI increases. In general, this means that more tasks become completely automated (i.e., wholly using AI as input). Holding the production structure (i.e., share of each task in the final output) constant, the quantity of labour demanded decreases (e.g., cashiers being replaced by self-checkout counters in supermarkets).
So, is this all doom and gloom for workers? Not so fast. There are several potential mechanisms which could lead to an increase in employment.
There could be strong complementarities between labour and AI within the same task. Taking the case of the economist, perhaps computer software becomes more efficient and produces 10 times as many economic simulations at the same cost. This means that more economists will be needed to interpret and publish the increased number of results¹¹. Other examples of jobs that have strong complementarities include knowledge workers such as consultants, doctors and lawyers.
Additionally, the increased Marginal Product of AI will reduce costs of production. This allows the firm to produce more output, also known as the productivity effect¹². Hence, even if a task has been automated, the productivity effect leads to increased hiring in non-automated tasks. In situations which output increases substantially, due to high elasticity of demand(I will elaborate on this in a later section), then overall employment could indeed increase.
Source: Autor (2024)
Lastly, there is the reinstatement effect,or the creation of new tasks that humans specialise in. Using the video-generation example, perhaps Task C will be created: previous video editors will turn into creative consultants advising clients on their brand’s creative direction. Autor (2024)¹³ analysed job titles across decades using NLP and found that 60% of the jobs in 2018 did not exist in 1940. Since 1940, the bulk of new jobs has shifted from middle-class production and clerical jobs to high-paid professional jobs and low-paid service jobs.
Which workers will be automated or augmented?
From the model above, we can see that the impact of AI on labour will depend on whether labour is automatable, i.e., specializing in tasks which AI has automated (such as Task A), or non-automatable, i.e., specializing in a non-AI-automated task (such as Task B). Automatable labour will end up being displaced due to AI advancements, leading to lower wages and unemployment. However, non-automatable labour will be retained, and may see increases in their productivity and wages.
Thus, the key question to answer now is how to identify which labor is automatable and which labor is non-automatable.
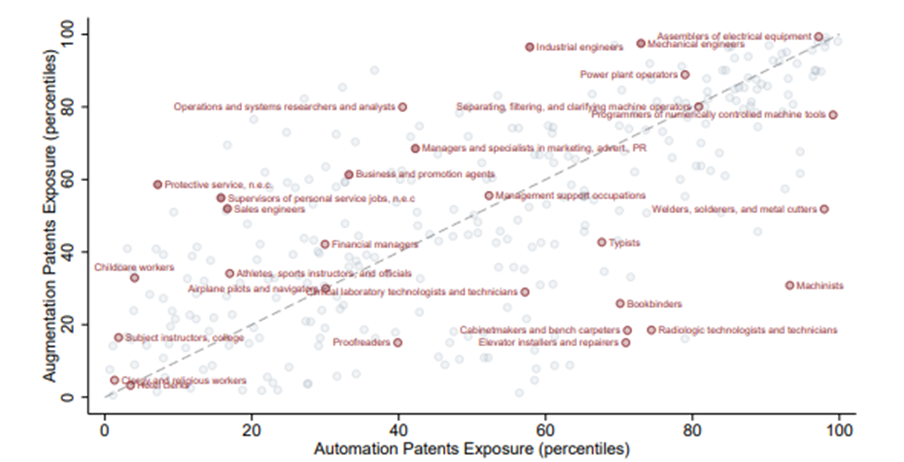
The relationship between exposure to Automation and Augmentation Patents at Occupation Level, 1980–2018 Average. Source: Autor (2024)
It’s worth pausing here to highlight an alternative perspective in the literature, notably from Autor (2024), which classifies the technology, rather than labour, as labour-augmenting or labour-automating. Autor uses the text of patents to classify innovations as such: a patent is considered an augmentation innovation if its content is aligned with occupational outputs, while a patent is considered an automation innovation if its content is similar to tasks that workers perform in specific occupations.
While this approach has been adopted by subsequent papers building on Autor’s framework, I find it problematic for several reasons.
Firstly, predicting the impact of an innovation at the time of its release is inherently uncertain. On the day OpenAI Sora was released in February 2024, I was listening to a leading AI podcast, The AI Daily Brief, describing what a monumental breakthrough Sora was¹⁴. However, the host Nathaniel Whittemore recognised that he had completely no clue about whether Sora will displace or augment video creators, and that we had to “wait and see”.
Secondly, classifying technology as augmenting or automating assumes a uniform effect across all workers, which oversimplifies the reality of heterogeneous workers. Workers differ in skills, experiences, and productivity levels. Hence, it is more likely that a certain technology will augment some types of labour and automate others.
My framework: AI performance relative to humans
Most of the economic literature assumes that labour is homogenous. Some try to account for labour heterogeneity, by assuming two types of labour: high-skilled and low-skilled, which is still quite reductionist. Homogeneity of labour is a necessary assumption to solve for workers’ wages at equilibrium and ‘solve’ the theoretical model.
However, this is at odds with the labour market in reality, in which there is huge dispersion of productivity and skill levels between workers. Within a single task, different workers have varying levels of productivity (e.g., some people can edit videos much faster than others). Additionally, workers possess uniquecombinations of skills across multiple tasks (e.g., some workers can both edit videos and market their video editing services to customers, while others can only edit videos).
This reminds me of the stats assigned to soccer players in FIFA (shooting, positioning, finishing, penalties etc.) These all contribute to a wide dispersion of overall scores (think productivity), and hence wages across workers even within the same occupation.
This underscores a common critique of economists: the tendency to construct models based on what is analytically tractable and gives ‘clean’ findings, rather than the realism of the modelling assumptions. Hence, their results are elegant and theoretically rigorous under strict conditions, but risk becoming disconnected from reality, offering limited utility for understanding real-world issues.
It is at this time that I introduce my framework for classifying labour into augmented or automated, recognising the heterogeneity of workers yet fitting tractably in the task-based economic framework.
The core principle underlying my framework is straightforward: whether labour is augmented or automated depends on the relative performance of AI compared to worker in a given task. An AI technology automates labour in a certain task if labour performs worse than AI in the task, while it augments labour if labour performs better than AI in the task.
For example, if OpenAI’s Sora model can generate videos at the 75th percentile of video editors in productivity (loosely defined as quality relative to inputs of time and money), then it would displaceany video editor worse than the 75th percentile (assuming its marginal cost of AI is lower than the cost of employing a 75th percentile video editor). However, for the 90th percentile video editor, Sora becomes a tool for augmenting. This editor could use Sora to instantly get a first draft with quality equivalent to a 75th percentile video editor, and then leverage their superior skills to refine the draft into a higher-quality final product.
Measuring AI’s performance relative to humans
The elegance of this approach lies on its reliance on readily-available, up-to-date data of AI performance relative to humans on a wide range of tasks.
This is because AI model creators test their models’ performance by evaluating them against human-curated benchmarks on a multitude of different tasks. Some examples of benchmarks are MATH (a compilation of high-school competition math problems), GPQA (PhD-level questions written by domain experts in biology, physics and chemistry), and SWE-bench (a collection of real-world software issues from GitHub).
This practice ensures that every new AI model or product release comes with publicly shared performance metrics, providing a timely and detailed understanding of AI capabilities.
In contrast, traditional economic indicators for tracking the progress and impact of technology, such as patent data or wage and employment statistics, are inherently lagging. Patent data often omits key innovations, since many AI firms do not patent their new products. Wage and employment data, while useful, are available only with a significant delay and are inherently ex-post, limiting their ability to forecast the future impacts of cutting-edge AI on the workforce.
Looking at the graph in the tweet above¹⁵, we can see how rapidly AI has progressed. It has exceeded human performance in narrow tasks such as image recognition in the 2010s, driven by breakthroughs in deep learning. In natural language processing (NLP), transformers (introduced in 2017) revolutionised the field, scaling from models like BERT to successive versions of GPT. Currently, frontier AI models are rapidly improving at more complex tasks, such as code generation, advanced mathematics, and reasoning and logic. Current trends suggest that AI will rival or surpass human experts in these domains within the next few years.
Additionally, AI models have their performance benchmarked on standardised exams (APs, SAT, GRE, and even competitive math from AIME to IMO)¹⁶. Since standardised exams provide a well-documented distribution of student scores across time as well as cross-sectionally, this data can leveraged to approximate the skill distribution of the workforce.
By correlating AI performance data with occupational task descriptions and comparing it to the estimated skill distribution of workers in each occupation, we can thus construct a metric of AI’s relative performance compared to humans in each occupation, and hence, the displacement or augmentation potential of workers in each occupation. I believe that this is possible — OECD’s PIAAC is the premier internationally-comparable database of adult skills, I myself having used it on an economics project on adult skills and ageing. OECD has also measured AI’s ability to solve PIAAC’s literacy and numeracy tests¹⁷.
Hence, if AI performance is equivalent to the 75th percentile of workers in a given occupation, this metric can be interpreted as AI potentially displacing the bottom 75% of workers in this occupation, and augmenting the top 25% of workers in this occupation. This gives distributional, within-occupation insights about the heterogeneous impact of AI.
High-skilled vs low-skilled workers — who benefits from AI?
My framework can offer insights on the current debate on whether AI will benefit higher-skilled or lower-skilled workers more. This question has significant implications for inequality — an important issue affecting social cohesion and satisfaction with the economic system.
While thought leaders and early empirical evidence remain divided, I hope that a deeper analysis using my framework can help reconcile some of the apparent contradictions.
On one hand, some early empirical evidence suggests that lower-skilled workers benefit more.
· Brynjolfsson et al. (2023)¹⁸: In one of the first experiments to investigate the impact of generative AI on work, the authors found that customer support agents using AI experienced a 14% increase in productivity on average. Crucially, less experienced or lower-skilled workers saw the greatest productivity gains of 35%, while the most experienced workers saw minimal gains.
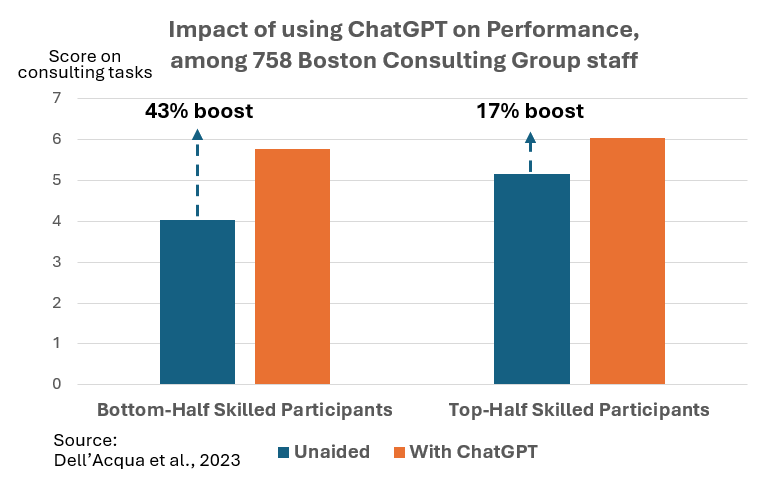
Using ChatGPT benefitted lower-skilled than higher-skilled consultants, according to a study by Dell’Acqua et al., 2023. Image by author.
· Dell’Acqua et al. (2023)¹⁹ ²⁰: A field experiment with Boston Consulting Group (BCG) consultants revealed a similar pattern. Lower-performing consultants who were given access to GPT-4 achieved a 43% productivity increase, compared to only 17% for higher-performing consultants.
· Hoffman et al. (2024)²¹: Studying 187,000 developers using GitHub Copilot, the authors found that Copilot enabled software developers to shift task allocation, towards their core coding activities and away from non-core project management tasks, and that lower-ability ²² coders experienced greater effects.
At first glance, these findings may seem to contradict my framework, which posits that worse workers would be displaced and worse-off. Let me explain using my framework and the example of a video-creating firm again.
In this scenario, the occupation of video editor comprises two complementary tasks: Task A (video editing) and Task B (customer service). Even though Task A has been automated, Task B is non-automatable, as it requires human negotiation and discussion with clients. If Task B takes up the bulk of the time, a worker’s overall productivity will be constrained by the inefficiencies in Task B. For example:
· A worker at the 5th percentile in Task A can use AI to achieve the productivity level of the 75th percentile, significantly boosting their overall output.
· Conversely, a 75th-percentile worker may see little improvement from AI, as their bottleneck lies in Task B, where no gains are made.
In economics terminology, there are strong complementarities between the automated Task A and inefficient Task B. The inefficiency of Task B effectively caps overall productivity gains, creating what Michael Webb describes ²³ as a performance ceiling: a limit beyond which further improvements in Task A lead to diminishing returns. Hence, AI helps low-skilled workers to narrow the gap to high-skilled workers, with both converging upon the performance ceiling.
However, this dynamic may change as firms and AI technologies evolve. Perhaps the firm will engage in task specialisation, decoupling Task A and Task B and hiring separate workers for each. Hence, workers poor in Task A would be displaced, as they are no longer needed for Task B. Alternatively, further AI advancements can automate Task B as well (e.g., OpenAI Realtime improves to automate all simple customer service calls). Perhaps then you would see the top-quality customer assistants (e.g. those offering personalised counselling/coaching or emotional guidance) being augmented, while all the lower-quality ones will be automated.
On the other hand, some argue that higher-skilled individuals will benefit more from AI augmentation.
Firstly, my framework leads to the obvious implication that higher-skilled workers are more likely to be augmented rather than automated in a given task. As Michael Webb noted in his 2023 interview on the 80,000 Hours podcast, top software engineering leads can now design the architecture for and implement 100 apps with AI assistance, a task that previously required hiring numerous junior software engineers. This illustrates how AI can amplify the productivity of highly-skilled workers, rather than replace them.
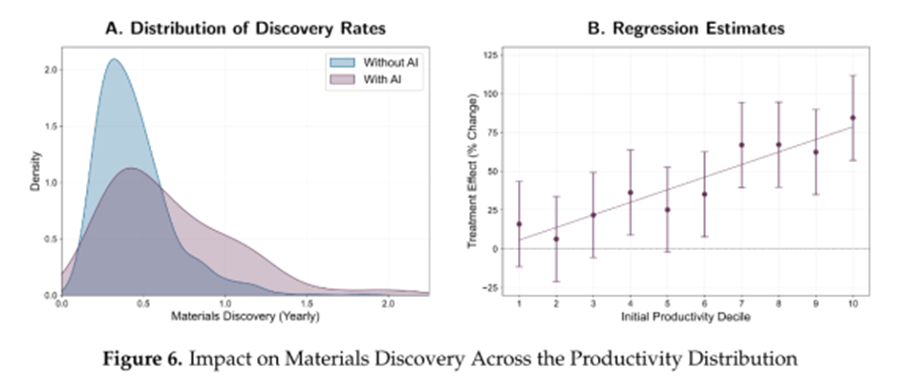
Source: Toner-Rodgers, A. (2024). Artificial Intelligence, Scientific Discovery, and Product Innovation.
Another recent study by Toner-Rodgers (2024)²⁴, which has garnered attention for its positive findings on AI and scientific innovation, found that when researchers gained access to an AI-assisted materials discovery tool, the output of top researchers doubled, while the bottom third of scientists saw little benefit. The authors attribute this disparity to the complementarity between AI and human expertise in the innovation process. Top scientists leveraged their domain knowledge to prioritise promising AI suggestions, whereas others wasted substantial resources testing false positives.
Furthermore, as individuals gain experience and skills on the job, they often take on roles involving leadership and management — areas where AI remains relatively weak. These roles require strategic thinking, emotional intelligence and interpersonal skills, which complement AI rather than substitute it. The positive correlation between experience and AI complementarity suggests that higher-skilled, more experienced workers are more likely to thrive an AI-enhanced labour market.
Acemoglu (2024)²⁵ suggests another channel that could lead to lower-skilled workers losing out. Even if AI enables a productivity increase for lower-skilled workers in a certain task (let me bring back Task A of video-editing again), higher-skilled workers could be reallocated to other tasks, and the commoditisation of Task A (more abundant supply of Task A due to AI advancement) could lead to the price of task A declining (i.e., fall in a), leading to wages of workers specialising in Task A (the lower-skilled workers) stagnating.
The dynamic effects are even more concerning for lower-skilled workers. As AI outpaces their abilities in tasks that they specialise in, job opportunities for these individuals may diminish significantly. This leads to the most valuable skill-building occurs on the job, but without entry-level roles, lower-skilled workers might find it nearly impossible to acquire the skills they need to remain economically viable.
This concern was highlighted to me by my god-brother, an ardent film critic. We were discussing the Hollywood actors’ strike in 2023 in opposition to film studios using AI voiceovers to replace minor roles, among other grievances. He pointed out that many prolific film directors had honed their craft through years of doing low-level tasks in Hollywood. Christopher Nolan, for instance, worked as a script reader and camera operator in his early years[26]. He might never have become who he is today if studios had replaced these opportunities in favour of AI. AI is like a tsunami — those who fail to make it to “higher ground” during the short window of opportunity pre-automation may be irreversibly devastated when the wave of automation hits. This dynamic risks driving irreversible polarisation between the skilled and the unskilled.
Evidence of this phenomenon is already emerging in the tech industry, where job openings for entry-level software developer roles are plummeting.
While there is compelling evidence supporting both sides of the debate, I personally believe that AI will eventually widen, rather than close, disparities between workers. This underscores the urgency of addressing the socioeconomic challenges posed by AI.
More about the Productivity Effect
Let’s dig deeper into the productivity effect I mentioned earlier, which underpins much of the optimism about AI having a positive impact on jobs. Understanding this would shed light into which occupations are most likely to remain future-proof from AI, and even benefit from AI advancements (I will cover my framework of which occupations are good in the final section!)
The key insight here is that automation-driven cost reductions and productivity improvements can lead to a substantial increase in demand for the final output, leading to an increase in employment for non-automatable tasks that potentially outweigh the employment decline due to the first task’s automation.
How do we determine the types of products that are likely to see this effect?
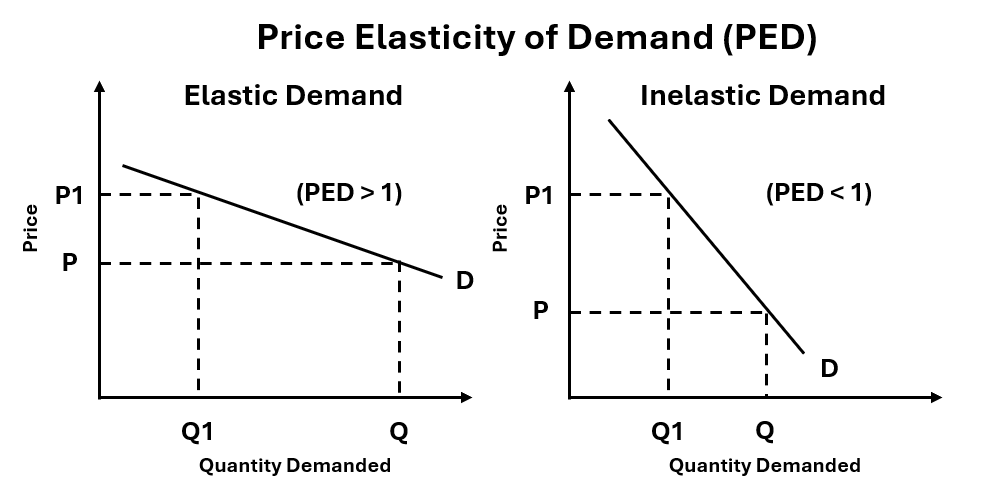
Primer on Price Elasticity of Demand. Image by author.
This is the point in which I invoke a concept from introductory microeconomics — price elasticity of demand. To refresh your memory, a product has price-elastic demand, if a price decrease leads to a more than proportionate increase in quantity demanded, ultimately leading to an increase in total value of output demanded.
To explain simply, for price-elastic products, consumers would actually demand much more of these products, but are constrained by the current price point.
One reason for this is if there is potential for new markets to be unlocked when cost declines — if the existing product has a low market penetration.
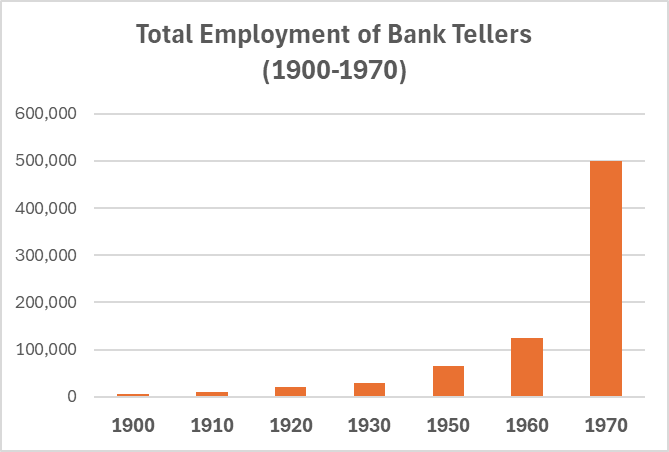
Despite the rise of ATMs post-WW2, the total employment of bank tellers rose significantly by the 1970s, illustrating the new markets unlocked by the cost declines of running a bank branch. Image by author.
An example that is often cited by proponents of automation is ATMs and bank tellers ²⁸. In the post-WW2 era, demand for banking services surged, and human tellers were critical for routine tasks like cashing checks and depositing money. When ATMs became ubiquitous in the 1990s, they automated many of these routine tasks, significantly reducing the cost of operating bank branches. As a result, banks could open many more branches nationwide, serving a much wider population. Consequently, teller employment increased, with their roles evolving from manual tasks to a focus on customer service, sales and specialised client requests.
Other examples of increasing affordability making products much more accessible were cars and televisions in the 20th century, and now, perhaps new tech products such as drones, augmented reality home cinemas, which are becoming more accessible to average consumers due to continuous improvements in quality and reductions in cost.
Additionally, network effects can amplify the effect of cost reductions, as the value of the product increases as more people use it. For example, platforms like Slack, Google Docs and Zoom, which have reduced the complexity and hence cost of remote collaboration, driving adoption. As more users gain, the utility of these platforms only increases, creating a virtuous cycle of increased adoption and value.
Perhaps this is also why TikTok is very interested in developing AI tools to simplify video-making. It recently launched Symphony ²⁹, a new suite of AI-powered creative solutions. By reducing the time and effort needed to make TikTok videos, this would massively increase the number of users to create and share videos on TikTok, further enhancing the platform’s virality and engagement.
Thirdly, products that enable innovation, or spur the creation of further products, would also exhibit price-elastic demand. The best example is semiconductors. Initially used only in military applications due to high costs, semiconductors became exponentially cheaper and more powerful, enabling a cascade of innovations — from personal computers to smart devices (such as fridges and TVs). Today, this fact is true more than ever, (as we will cover more in the next article), as semiconductors are in insatiable demand by Big Tech companies, powering the development and deployment of advanced AI models. Despite the performance of semiconductors doubling every 2 years (Moore’s law), demand for semiconductors is still skyrocketing, with GPU production projected to double annually through 2030 ³⁰.
On the flip side, some products exhibit price-inelastic demand, meaning that demand will not increase even if costs dramatically decrease. These products are characterised by market saturation and low potential to create new applications.
One example is tax-filing software. Consumers and businesses will not suddenly file 10x more taxes if the price of tax filing software drops by 90%. For these cases, automation in the tax-filing process would likely lead to a decline in employment, as demand would not increase.
Another example is fast food, which has reached market saturation in the Western world. People are limited by the amount they can eat, with affordability of fast food rarely a limiting factor. Even if fast food were to become 10x cheaper, due to the automation of 90% of the service staff in fast food restaurants, I don’t think that the demand for fast food would increase by nearly enough to prevent service staff from being displaced. (though Americans’ desire for fast food may well surprise me!)
AI as a General Purpose Technology
This year, rising cynicism has emerged regarding the actual economic benefits of AI. Despite rising business adoption of AI products, companies are not seeing the substantial advances in productivity that proponents of AI had promised.
However, I posit that this is because we are early in the adoption cycle of a General Purpose Technology, and organisational mindsets mean that we are in the price-inelastic, AI = cost-cutting state of the world right now.
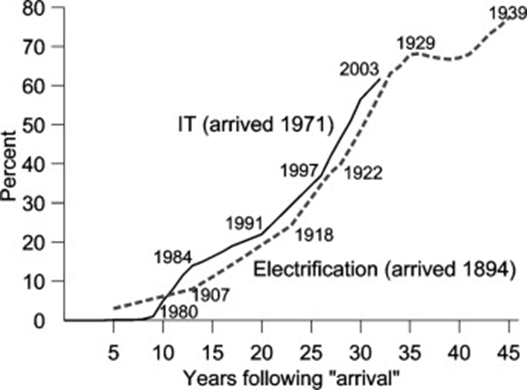
AI is considered by many to be a General Purpose Technology (coincidentally also abbreviated as GPT), which is defined as a technology that affects the entire economy and has the potential to drastically alter economic and societal structures. Historical examples were the steam engine (late 18th century), electricity (late 19th century), and information technology (late 20th and early 21st century).
Ajay Agrawal argues, in his 2022 book on the disruptive economics of AI ³², that AI is likely to follow a similar trajectory to previous GPTs, such as electricity during the late 19th and early 20th centuries.
The slow adoption rates of General Purpose Technologies plotted against years following ‘arrival’ of the technology. Source: Jovanovic & Rosseau (2005)
At that time, steam power had driven the economy through the Industrial Revolution, and the initial adoption of electricity was seen primarily as a drop-in replacement. For example, electric motors were used to replace steam engines in cars and elevators. However, these isolated applications failed to significantly increase power usage or unlock electricity’s transformative potential.
The true promise of electricity emerged over time ³³, with the realisation that it offered fractionalised power — small, portable units of energy that could operate independently of a central generation system. This capability enabled factories to break free from the rigid layouts dictated by the central steam shaft. Industrialists like Henry Ford capitalised on this flexibility, pioneering novel production line designs that revolutionised manufacturing and drove unprecedented efficiency gains in the early 20th century.
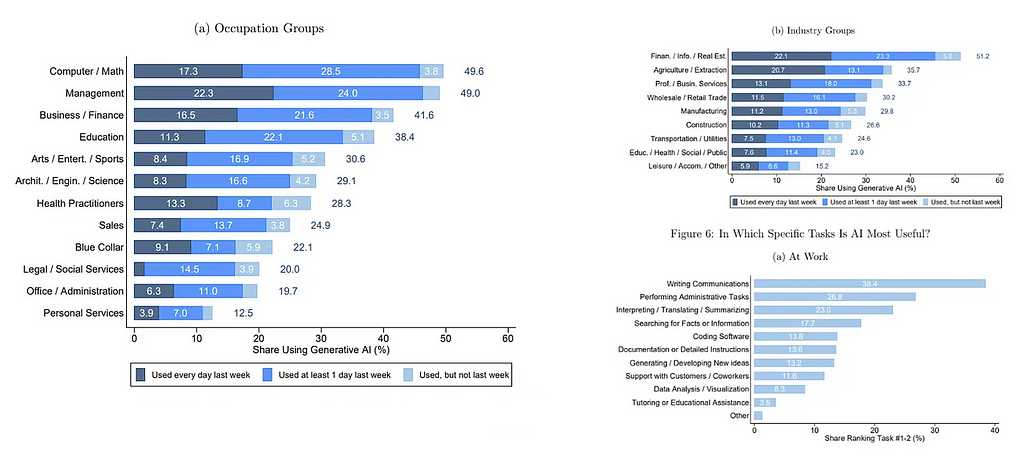
AI has been rapidly adopted across different occupations, industries and for a range of tasks. Source: Bick (2024)
Ethan Mollick agrees with this assessment, arguing that currently, AI is being predominantly used as a drop-in replacement for efficiency purposes, rather than driving a fundamental overhaul of production systems. As long as businesses view AI primarily as an information technology for cost savings, they will focus on substituting humans with AI in existing tasks, rather than reimagining their production functions. This approach, naturally, leads to labour displacement rather than transformative economic gains.
In the long-term, enterprises will shift from viewing AI as a simple efficiency tool to integrating it as a core feature of entirely new production models. Some examples could be autonomous supply chains, or AI personal assistants coordinating between knowledge workers. This shift will also give rise to a new class of AI-first products, potentially driving massive productivity improvements and prompting a reimagination of labour’s role in these systems, or a mega version of the reinstatement effect. Perhaps workers will now all be ‘quality control experts’, checking AI-generated outputs for errors or customising them for niche user needs.
Linking this with our framework, we know that price-elasticity tends to increase in the long-term, precisely because firms can adapt their production processes. As AI advances, firms are likely to move beyond using it primarily as a cost-cutting, labour-displacing tool. Instead, they would leverage AI to overhaul production systems, develop entirely new products, and tap into new markets, capturing significantly greater demand. This evolution could ultimately lead to the productivity and reinstatement effects dominating, bringing substantial benefits to both workers and consumers.
So what are the best jobs?
Let me consolidate the insights from the article thus far and provide guidance on identifying the desirable jobs to be in during this period of AI advancement. Unlike other papers, I don’t have a list of occupations ranked by their score to recommend you, because this would require deeper analysis and research using my proposed framework. Instead, I will outline the key criteria for identifying “AI-proof” roles.
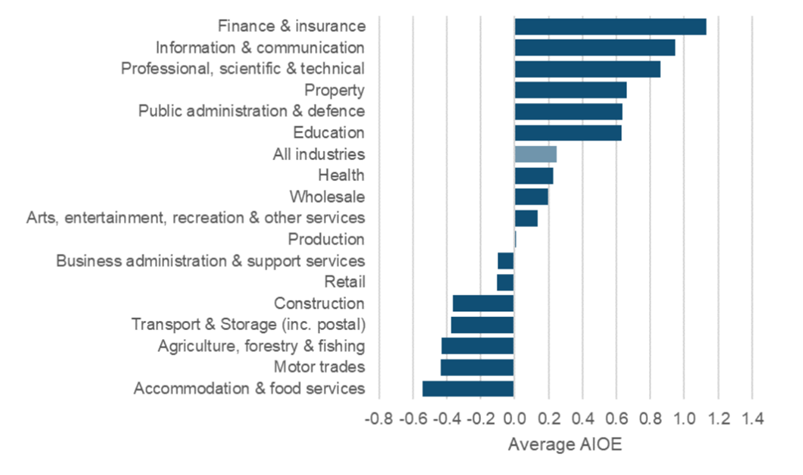
AI Occupational Exposure Scores. Source: UK Department of Education (2023)
The naive recommendation is to say that the least AI-exposed occupations are the best, taking the measures of AI exposure from recent papers³⁶ ³⁷. But that is flawed. Take a look at the table of least AI exposed fields — nursing, elementary education. I will add in cleaning and domestic work. However, these jobs are poorly paid and are unlikely to see much improvements in productivity or demand in the future, hence there are few opportunities for economic advancement.
More than the level of AI exposure, we should also look at the rate of change. Once again, charts showing the rate of progress of AI models on different tasks are very informative.
My criteria for a desirable job: the job contains mostly non-automatable tasks, but also a non-trivial amount of automatable tasks where AI is improving rapidly in. This will support productivity growth of that job. Furthermore, the job must be in an innovative field where productivity improvements will likely lead to significant demand increases.
One example I have in mind is a tech product manager (PM). A PM’s core responsibilities — understanding of the product, industry and users, as well as facilitating communication and collaboration between engineers and business teams — are fundamentally non-automatable. However, a PM’s role also includes automatable tasks (e.g. meeting scheduling, making mock-ups on Figma, prototyping, producing pitch decks, monitoring user activity and developers’ progress), which AI is making rapid progress in (AI agents to schedule meetings, Figma’s text-to-design, text-to-PPT, and more AI-powered monitoring dashboards). This enables a PM’s productivity to increase significantly, allowing him to focus more time on his core skillsets, manage larger teams and/or design and rollout new features and products more effectively. Moreover, there is literally no end of problems that good software products can solve — the demand for software is virtually unlimited. Hence, productivity improvements will lead PMs to be able to do more, rather than have fewer PMs do the same work. These arguments also apply to tech entrepreneurs.
Ideally, you should also look at jobs allowing you to gain ownership of capital which is driving automation. Gaining equity (common in tech companies) or rising to executive positions in firms increasing using AI will enable you to reap a portion of the gains from automation in capital income, instead of relying on your wages which could be a shrinking pie.
By focusing on roles that balance human ingenuity with AI-driven productivity gains, and by seeking ownership in automation capital, we can navigate this era of transformation not just with resilience but with the potential for growth and impact.
Is AI automation all that bad?
Lastly, I also wanted to challenge the notion that AI automating jobs is purely doom and gloom. Just because machines can perform certain tasks better than humans does not eliminate all value from such activities or the skills associated with them.
For instance, the invention of cars, cameras, and speakers did not diminish the value of running, painting, or playing music. Sure, it means that the people who specialised in running, painting and making music as their primary means of income needed to adapt, but many humans still enjoy these activities as leisure activities and hobbies. In fact, being able to engage in such pursuits for their own sake, untainted by the pressures of commercialisation, is far more enjoyable.
This vision aligns with the utopian ideal depicted in popular culture, such as Isaac Asimov’s I, Robot, where AI automates all economic work, freeing humans to focus on intellectual and leisure pursuits unburdened by the need to make a living. In such a world, if you are skilled in an automated task, you could in fact still finding purpose and income by teaching other people these skills for leisure (e.g. running coaches, art instructors and music teachers). Ultimately, humans would gravitate toward the one truly non-automatable product by definition: activities deriving their value from human connection, such as personalised coaching, fostering human relationships, and emotional engagement.
However, I am not naïve to think that such a world is the likely outcome. Realising this vision hinges on whether humanity can redistribute the gains from AI equitably, so that those whose economic value has been automated away can still be given their fair share of resources to live a meaningful life. This is obviously a huge challenge, given the unequal and commercialised world of today. While exploring this is beyond the scope of this article, I hope to address how AI might reshape the broader economic system in future pieces.
Conclusion
In conclusion, AI will undoubtedly have profound impacts on the economy, with performance improving and costs diminishing rapidly. Using an economically grounded framework, I explain why some workers will be displaced while some will be augmented by AI, with AI’s impact on workers hinging on a critical metric: whether AI performs better than the worker in tasks relevant to his occupation. Whether high-skilled or low-skilled workers benefit more depends on the nature of firm’s production. However, the way AI is currently used is not a good indicator for its economic promise, as it is a General Purpose Technology and will create new systems, products and drive significant productivity gains in the long-term.
I close the discussion by stating certain characteristics of occupations that are desirable to be in. I encourage more economists to leverage AI model benchmarks to create timely and granular assessments of the automation potential of workers in different occupations, to determine quantitatively what the desirable occupations are.
Ultimately, AI, just like any technology, is inherently neutral, and its societal impact will be determined by the choices we make. It is imperative for AI practitioners, economists, and policymakers to work together to ensure that AI will positively impact the economy and society, through redistribution mechanisms and thoughtful regulation that strike a balance between fostering innovation and ensuring equity. Only then can AI, as Anthropic CEO Dario Amodei said in this recent essay ³⁸, become “machines of loving grace”, transforming the world for the better.
Executive Summary
The pace of AI advancements is unprecedented, with significant improvements in both model capabilities and cost efficiency. However, the economic implications of AI remain inadequately understood, with unsatisfactory insights from AI practitioners, economists and think-tanks. Economists often underestimate AI’s potential impact due to limited engagement with cutting-edge developments.
Acemoglu and Restrepo (2018)’s task-based framework is commonly used in the economics literature to analyse the impact of automation.
Automation: AI displaces labor in tasks where it is highly substitutable, reducing employment in those areas (e.g., cashiers replaced by self-checkout).
Complementarity: AI can augment labor in tasks where human expertise is still essential (e.g., economists interpreting data generated by advanced software).
Productivity Effect: Lower costs from AI can increase demand for non-automated tasks, potentially raising employment overall.
Reinstatement Effect: New tasks may emerge as AI automates existing ones, creating roles that require uniquely human skills.
I introduce my framework: AI augments or automates labor based on its performance relative to workers in a given task. If AI is better than labour, labour is automated, but if labour is better than AI, AI augments labour. These information is readily available — AI models are benchmarked against human performance in various tasks, providing timely insights into their relative capabilities. These benchmarks can be mapped to workforce skill distributions (e.g., using OECD PIAAC data) to assess which workers are most at risk of automation or likely to be augmented.
Whether AI will benefit high or low-skilled workers remains uncertain. Early empirical evidence on customer support agents, consultants and software developers suggest that lower-skilled workers benefit more. Economically, this is due to strong complementarities between automated tasks, and other non-automated, inefficient tasks, leading to performance ceiling hindering productivity gains.
However, I personally believe that higher-skilled workers benefit more because: i) within a task, they are more likely to be augmented than automated, ii) AI can be complementary to human expertise in the innovation process, as shown by Toner-Rodgers (2024), iii) there is a positive correlation between experience and AI complementarity of tasks, as workers take on management roles as they advance, iv) the commoditisation of automated tasks can lower task prices, even if skill gaps shrink due to AI, v) lower-skilled jobs face declining job opportunities due to AI, depriving them of opportunities to gain skills on the job, creating a vicious cycle.
Products with price-elastic demand (e.g., semiconductors, consumer tech products) see significant demand increases when AI reduces costs, increasing employment in complementary tasks. This can happen when: i) new markets are unlocked by cost decreases, ii) there are network effects, iii) the products enable innovation. On the other hand, products with price-inelastic demand (e.g., tax software, fast food), due to i) market saturation and ii) low potential for new applications, lead to job displacement as demand does not increase due to cost decreases.
AI is a General Purpose Technology with the potential to reshape economic structures, similar to electricity and the steam engine. In the current early stage, firms use AI for cost-cutting, limiting AI’s impact to displacing labour. Long-term integration could lead to new systems and products, offering significant productivity gains.
The best jobs are those with a mix of non-automatable tasks and automatable tasks where AI is rapidly advancing, in fields with high potential for productivity-driven demand growth (e.g., tech product managers). Workers should seek roles offering capital ownership (e.g., equity in tech companies) to benefit from AI-driven productivity gains.
Automated activities can be pursued forleisure and are still valuable, similar to running, music and art, and this could be more enjoyable due to the lack of profit motive. However, achieving equitable redistribution of AI’s benefits is critical to ensuring AI delivers broad-based benefits for all.
Try out some AI apps I’ve built: Podsmart, which transcribes and summarises podcasts and YouTube videos, and aiRead, an AI-first PDF reader and notepad app
Follow me on Twitter/X — I post more on economics and AI! And LinkedIn as well
[2] OpenAI GPT-4 was initially released costing $30 per million input tokens. GPT-4o mini, which currently ranks above the originally released GPT-4 in performance, according to LMSYS, costs $0.15 per million input tokens.
[8] Source: Acemoglu, D., & Restrepo, P. (2018). The race between man and machine: Implications of technology for growth, factor shares, and employment. American economic review, 108(6), 1488–1542.
[9] The specific version of the task-based model that I introduce this paper is from Acemoglu and Autor (2022).
[11] This assumes that the computing improvements only affect the speed of the statistical software. In reality, the improvement of computer performance leads to the development of AI systems like ChatGPT Advanced Data Analysis which automate more previously manual roles of an economist.
[12] The strong complementaries and productivity effect are actually similar arguments, it just depends on how broadly or specifically you define the task. If you define Task Z to comprise both Task A (which is now automated), and Task B (which has experienced an increase in employment due to the productivity effect), then you could say that the employment required for Task Z increased, implying strong complementarities between labour and AI in Task Z
[13] Source: Autor, D., Chin, C., Salomons, A., & Seegmiller, B. (2024). New frontiers: The origins and content of new work, 1940–2018. The Quarterly Journal of Economics, qjae008.
[18] Source: Brynjolfsson, E., Li, D., & Raymond, L. R. (2023). Generative AI at work (No. w31161). National Bureau of Economic Research.
[19] Source: Dell’Acqua, F., McFowland III, E., Mollick, E. R., Lifshitz-Assaf, H., Kellogg, K., Rajendran, S., … & Lakhani, K. R. (2023). Navigating the jagged technological frontier: Field experimental evidence of the effects of AI on knowledge worker productivity and quality. Harvard Business School Technology & Operations Mgt. Unit Working Paper, (24–013).
[21] Source: Hoffmann, M., Boysel, S., Nagle, F., Peng, S., & Xu, K. (2024). Generative AI and the Nature of Work. Harvard Business School Strategy Unit Working Paper, (25–021), 25–021.
[22] Ability was proxied using GitHub achievements, follower count, tenure on GitHub, and centrality across ranked repositories.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.












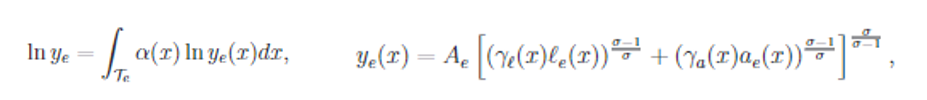

{kind=link}