You decided to employ generative AI at your company and have already conducted initial experiments with it. And now comes the question: do I need a dedicated person (-s) to handle all the upcoming prompt work?
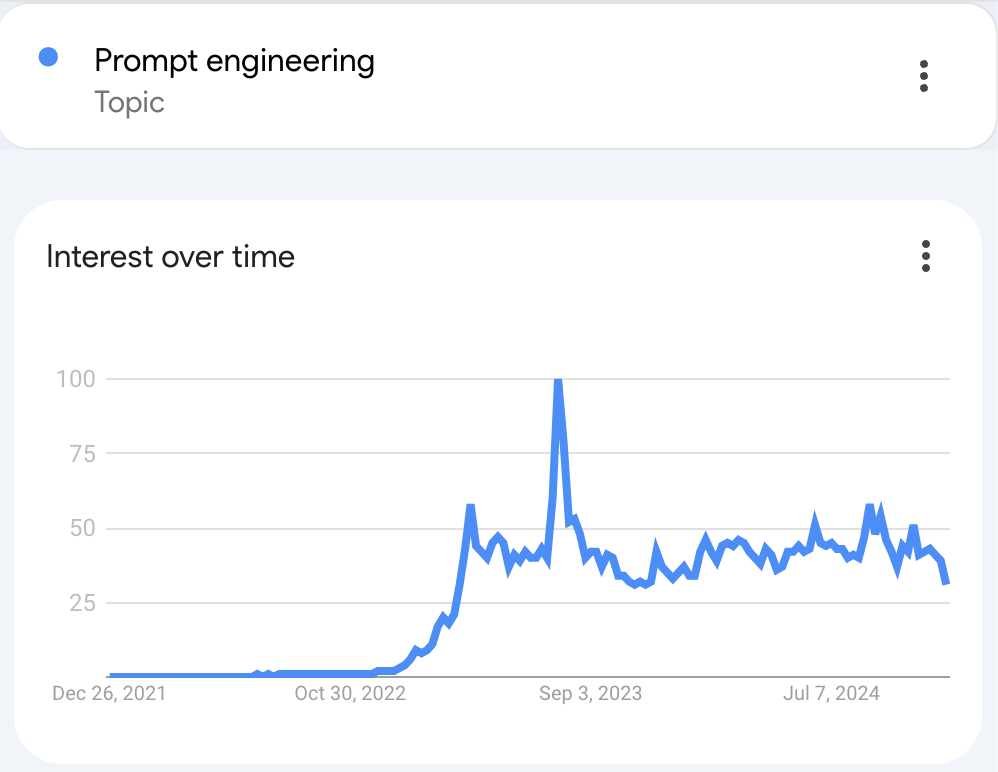
While the general interest around prompt engineering has remained steady over the last few years, a lot of companies struggle to make their first step in building prompt engineering competency because of simply not knowing where to start.
News like high salaries for prompt engineering roles don’t help as well, making the natural first reaction to just go to the free market and find prompt engineers too risky. This is because those companies are only at the very beginning of generative AI adoption phase and are not sure that such considerable investments into new hires with this new role are worthwhile at this stage.
Moreover, considering the rapid progress generative AI has made in 2023–2024, many in leadership ask themselves a very valid question: are prompt engineers here to stay long term and will there be a need for writing prompts in a future or just a couple of words thrown to LLM generally describing the problem to solve will suffice?
While any company is free to choose their own way to fulfill their needs for people who can do prompt engineering, in this post I’m going to focus on raising this expertise inside the company. This way is probably not that streamlined as just hiring someone with existing experience in prompt engineering, but offers some positive side-effects — but more on that later.
Should a prompt engineer be deeply technical?
Definitely not. The current state of prompt engineering offers around 20 advanced techniques and some of them might be efficient for achieving the specific goals of your generative AI-projects, but none strongly requires deep knowledge of, for example, a programming language or the ability to build complex prompt interactions by prompt engineers alone.
A prompt engineer usually starts by defining the problem that an LLM needs to solve. By experimenting with prompt content, how to structure it and maybe how to chain multiple prompts, a person doing prompt engineering is expected to get an LLM output of desired quality.
All of the above can be done “on paper” and without a need of writing even a single line of code. The paper in this case are playgrounds each LLM vendor have in their offering. And if one needs to make multiple prompts work together, the output of the previous prompt can just be injected into the next prompt by hand.
What kind of person would shine as a prompt engineer
We are currently in the unique position where the shape of this role is not final and is being constantly adjusted by the industry needs: literally every half of a year the progress in tooling and prompting techniques in AI requires people working on prompts to expand their skills.
But there are two of them which are by-default critical: curiosity and creativity.
A person genuinely curious about the field they are operating within will be the one delivering the best results regardless of what field it is. Constantly staying up-to-date with the latest developments in prompt techniques, unique capabilities of large language models (and the vast variety of both commercial and open-source ones on the market) will allow them to not simply throw “a GPT” on every problem they solve, but instantly recognize that e.g. non-complex tasks can be solved by less capable but cheaper and faster models.
Another crucial skill is to be creative when doing prompt engineering. While there are already some prompt engineering approaches guaranteeing solid results, we are far from understanding what prompts or techniques would deliver the best output. By just keeping writing their plain and straightforward prompts the people would have never discovered methods which statistically improve model output performance like “I’m going to tip $xxx for a better solution!” and other crazy and unexpected ideas. LLMs are a tool which has never been at our disposal before and at the current stage of their development, staying creative about how to employ them and what instructions to give will result in the best results — so make sure the person you are foreseeing for this role is capable of thinking originally.
At some point in time, prompt engineers will make changes to the prompts already deployed to production and preventing regressions in LLM output quality will be their absolute priority. Of course there are tools and approaches helping to reduce this risk, but nothing will substitute an attentive person comparing the output of the model before and after the change by just carefully reading through it and spotting negative patterns.
If a person you are envisioning to be your future prompt engineer has the three above qualities, don’t worry about them e.g. not knowing (yet) the fundamentals of how LLMs work — the curiosity will lead them to learn it naturally and creativity will gift them new tricks and approaches the person will come up with when solving a not obvious problem. An eye for detail will help in the long term and prevent unexpected declines in output quality.
Here is another take about other qualities a good prompt engineer should have.
Where to find people working on prompts
While hiring someone from the outside always remains an option, such a person won’t be having an immediate knowledge about the output you want to get from LLMs. Because of the non-deterministic nature of LLMs, their output can have a multitude of forms and styles and this is a work of a prompt engineer to make that outcome more predictable.
Who would best know the kind of output your LLM assistant should produce? (e.g. how deep must be its answers and what tone of voice should be used?).
Right. These are internal people who are already employed in your organization and deeply involved in working on your product. Take a closer look: maybe some of them are already excited about capabilities of generative AI and want to try out a new role?
These folks would be ideal candidates to become prompt engineers: their domain and product knowledge is deep enough to know what level of complexity and accuracy the model output should be. Often they also have useful internal connections to other departments which deeply technical people do not necessarily have. For example a person originating from the customer success department and who became a prompt engineer will have much easier time knowing how the final output of an LLM-based product they’re contributing to should look like VS yesterday’s software engineer who worked inside the technical department previously and most likely was all the time focused on deeper technical work inside of a single product area.
How to grow your prompt engineers
With time, you will face the need to grow the people authoring the prompts in your organization. The growth for such specialists doesn’t only mean to be able to quickly find an optimal prompting technique to the given problem (this comes with experience), but rather expanding the horizons of what’s possible for them beyond just defining what the system prompt of an LLM-based application will be.
Besides staying on top of the LLM research and latest advancements in prompt engineering techniques, more advanced prompt engineers need to tackle LLM evaluators — these are tools giving feedback about the performance of the model/prompt (similar to unit tests in software engineering).
Generally, evaluators can be both LLM-based (e.g. model B evaluates the output of the model A) or code-based (e.g. Python functions checking if model output adheres to the expected JSON-schema). Though code-based evaluators don’t require proficient programming skills, the person implementing them must have a high-level understanding about the programming language they are using (mostly Python) — so boosting this skill could be a one direction of growth for prompt engineers.
Just imagine: someone has delivered a prompt which not only “works” but also has instructions inside of it covered with tests/evaluators ensuring the safety net similar to unit tests providing in a traditional software development.
Prompt engineering is also not only about prompting techniques, output quality and evaluators. On a more proficient level, the people occupied with prompts must deeper understand the effect LLM hyperparameters are having on the output. This means another potential direction of growth for such people — learning machine learning fundamentals and investing in knowledge about how LLMs works under the hood.
Ideally, your organization already includes a leader who has experience somewhere on the intersection of software development and classical machine learning (or generative AI). Such a person could guide the growth of prompt engineers more precisely by steering their development into areas above.
Building the prompt engineering expertise
There is no one and all approach to building the expertise of prompt engineering because each organization has its own requirements about the LLM applications those prompts are used in. Building theexpertise can have a vastly different meaning in different organizations.
But the one thing always remains true: your prompt engineers must be deeply engaged into both product aspects of something they work on and also possess specific knowledge to their unique role: the first allows them to quicker achieve desired model output quality and the latter makes sure those results are sustainable and adhere to current best practices in the very rapidly developing world of generative AI.
Give your prompt engineers the freedom to explore novel approaches while holding them accountable for the results they are delivering: despite the non-deterministic nature of LLM output, we could and should reduce the risk of unexpected output quality deviations and there are tools for making those measures quantifiable.
Building prompt engineering expertise within your organization is not just about adapting to the current trends in AI — it’s about shaping the future of how your company leverages technology for innovation. By empowering your team to master prompt engineering, you foster a culture of creativity, efficiency, and forward-thinking.
At re:Invent 2024, we are excited to announce new capabilities to speed up your AI inference workloads with NVIDIA accelerated computing and software offerings on Amazon SageMaker. In this post, we will explore how you can use these new capabilities to enhance your AI inference on Amazon SageMaker. We’ll walk through the process of deploying NVIDIA NIM microservices from AWS Marketplace for SageMaker Inference. We’ll then dive into NVIDIA’s model offerings on SageMaker JumpStart, showcasing how to access and deploy the Nemotron-4 model directly in the JumpStart interface. This will include step-by-step instructions on how to find the Nemotron-4 model in the JumpStart catalog, select it for your use case, and deploy it with a few clicks.
Today at AWS re:Invent 2024, we are excited to announce a new feature for Amazon SageMaker inference endpoints: the ability to scale SageMaker inference endpoints to zero instances. This long-awaited capability is a game changer for our customers using the power of AI and machine learning (ML) inference in the cloud.
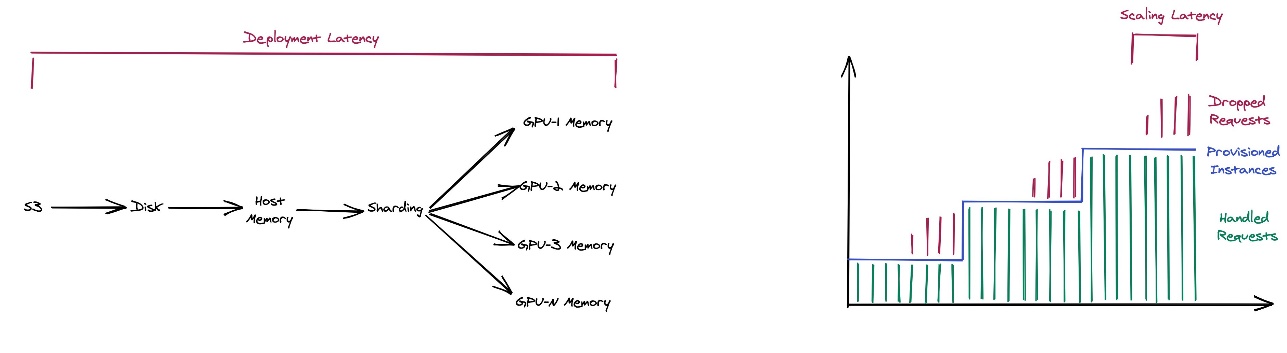
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. This innovation allows you to scale your models faster, observing up to 56% reduction in latency when scaling a new model copy and up to 30% when adding a model copy on a new instance. In this post, we explore the new Container Caching feature for SageMaker inference, addressing the challenges of deploying and scaling large language models (LLMs).
Today at AWS re:Invent 2024, we are excited to announce a new capability in Amazon SageMaker Inference that significantly reduces the time required to deploy and scale LLMs for inference using LMI: Fast Model Loader. In this post, we delve into the technical details of Fast Model Loader, explore its integration with existing SageMaker workflows, discuss how you can get started with this powerful new feature, and share customer success stories.
In this post, we provide a detailed, hands-on guide to implementing Fast Model Loader in your LLM deployments. We explore two approaches: using the SageMaker Python SDK for programmatic implementation, and using the Amazon SageMaker Studio UI for a more visual, interactive experience. Whether you’re a developer who prefers working with code or someone who favors a graphical interface, you’ll learn how to take advantage of this powerful feature to accelerate your LLM deployments.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.