
How pre-attentive processing, Gestalt theory, and visual data encoding inform data design decisions
Originally appeared here:
Information at a Glance: Do Your Charts Suck?
Go Here to Read this Fast! Information at a Glance: Do Your Charts Suck?

How pre-attentive processing, Gestalt theory, and visual data encoding inform data design decisions
Originally appeared here:
Information at a Glance: Do Your Charts Suck?
Go Here to Read this Fast! Information at a Glance: Do Your Charts Suck?

So, you recently discovered Hugging Face and the host of open source models like BERT, Llama, BART and a whole host of generative language models by Mistral AI, Facebook, Salesforce and other companies. Now you want to experiment with fine tuning some Large Language Models for your side projects. Things start off great, but then you discover how computationally greedy they are and you do not have a GPU processor handy.
Google Colab generously offers you a way to access to free computation so you can solve this problem. The downside is, you need to do it all inside a transitory browser based environment. To make matter worse, the whole thing is time limited, so it seems like no matter what you do, you are going to lose your precious fine tuned model and all the results when the kernel is eventually shut down and the environment nuked.
Never fear. There is a way around this: make use of Google Drive to save any of your intermediate results or model parameters. This will allow you to continue experimentation at a later stage, or take and use a trained model for inference elsewhere.
To do this you will need a Google account that has sufficient Google Drive space for both your training data and you model checkpoints. I will presume you have created a folder called data in Google Drive containing your dataset. Then another called checkpoints that is empty.
Inside your Google Colab Notebook you then mount your Drive using the following command:
from google.colab import drive
drive.mount('/content/drive')
You now list the contents of your data and checkpoints directories with the following two commands in a new cell:
!ls /content/drive/MyDrive/data
!ls /content/drive/MyDrive/checkpoint
If these commands work then you now have access to these directories inside your notebook. If the commands do not work then you might have missed the authorisation step. The drive.mount command above should have spawned a pop up window which requires you to click through and authorise access. You may have missed the pop up, or not selected all of the required access rights. Try re-running the cell and checking.
Once you have that access sorted, you can then write your scripts such that models and results are serialised into the Google Drive directories so they persist over sessions. In an ideal world, you would code your training job so that any script that takes too long to run can load partially trained models from the previous session and continue training from that point.
A simple way for achieving that is creating a save and load function that gets used by your training scripts. The training process should always check if there is a partially trained model, before initialising a new one. Here is an example save function:
def save_checkpoint(epoch, model, optimizer, scheduler, loss, model_name, overwrite=True):
checkpoint = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scheduler_state_dict': scheduler.state_dict(),
'loss': loss
}
direc = get_checkpoint_dir(model_name)
if overwrite:
file_path = direc + '/checkpoint.pth'
else:
file_path = direc + '/epoch_'+str(epoch) + '_checkpoint.pth'
if not os.path.isdir(direc):
try:
os.mkdir(direc)
except:
print("Error: directory does not exist and cannot be created")
file_path = direc +'_epoch_'+str(epoch) + '_checkpoint.pth'
torch.save(checkpoint, file_path)
print(f"Checkpoint saved at epoch {epoch}")
In this instance we are saving the model state along with some meta-data (epochs and loss) inside a dictionary structure. We include an option to overwrite a single checkpoint file, or create a new file for every epoch. We are using the torch save function, but in principle you could use other serialisation methods. The key idea is that your program opens the file and determines how many epochs of training were used for the existing file. This allows the program to decide whether to continue training or move on.
Similarly, in the load function we pass in a reference to a model we wish to use. If there is already a serialised model we load the parameters into our model and return the number of epochs it was trained for. This epoch value will determine how many additional epochs are required. If there is no model then we get the default value of zero epochs and we know the model still has the parameters it was initialised with.
def load_checkpoint(model_name, model, optimizer, scheduler):
direc = get_checkpoint_dir(model_name)
if os.path.exists(direc):
file_path = get_path_with_max_epochs(direc)
checkpoint = torch.load(file_path, map_location=torch.device('cpu'))
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
scheduler.load_state_dict(checkpoint['scheduler_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
print(f"Checkpoint loaded from {epoch} epoch")
return epoch, loss
else:
print(f"No checkpoint found, starting from epoch 1.")
return 0, None
These two functions will need to be called inside your training loop, and you need to ensure that the returned value for epochs value is used to update the value of epochs in your training iterations. The result is you now have a training process that can be re-started when a kernel dies, and it will pick up and continue from where it left off.
That core training loop might look something like the following:
EPOCHS = 10
for exp in experiments:
model, optimizer, scheduler = initialise_model_components(exp)
train_loader, val_loader = generate_data_loaders(exp)
start_epoch, prev_loss = load_checkpoint(exp, model, optimizer, scheduler)
for epoch in range(start_epoch, EPOCHS):
print(f'Epoch {epoch + 1}/{EPOCHS}')
# ALL YOUR TRAINING CODE HERE
save_checkpoint(epoch + 1, model, optimizer, scheduler, train_loss, exp)
Note: In this example I am experimenting with training multiple different model setups (in a list called experiments), potentially using different training datasets. The supporting functions initialise_model_components and generate_data_loaders are taking care of ensuring that I get the correct model and data for each experiment.
The core training loop above allows us to reuse the overall code structure that trains and serialises these models, ensuring that each model gets to the desired number of epochs of training. If we restart the process, it will iterate through the experiment list again, but it will abandon any experiments that have already reached the maximum number of epochs.
Hopefully you can use this boilerplate code to setup your own process for experimenting with training some deep learning language models inside Google Colab. Please comment and let me know what you are building and how you use this code.
Massive thank you to Aditya Pramar for his initial scripts that prompted this piece of work.
Training Language Models on Google Colab was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Training Language Models on Google Colab
Go Here to Read this Fast! Training Language Models on Google Colab


If matrix multiplication isn’t commutative, then why don’t we have left and right inverses?


AI, privacy, human bias, prompting, the future of content, and how to hack a chatbot
Originally appeared here:
The Name That Broke ChatGPT: Who is David Mayer?
Go Here to Read this Fast! The Name That Broke ChatGPT: Who is David Mayer?

This is the first part of a two part series I’m writing analyzing how people and communities are affected by the expansion of AI generated content. I’ve already talked at some length about the environmental, economic, and labor issues involved, as well as discrimination and social bias. But this time I want to dig in a little and focus on some psychological and social impacts from the AI generated media and content we consume, specifically on our relationship to critical thinking, learning, and conceptualizing knowledge.
Hoaxes have been perpetrated using photography essentially since its invention. The moment we started having a form of media that was believed to show us true, unmediated reality of phenomena and events, was the moment that people started coming up with ways to manipulate that form of media, to great artistic and philosophical effect. (As well as humorous or simply fraudulent effect.) We have a form of unwarranted trust in photographs, despite this, and we have developed a relationship with the form that balances between trust and skepticism.
When I was a child, the internet was not yet broadly available to the general public, and certainly very few homes had access to it, but by the time I was a teenager that had completely changed, and everyone I knew spent time on AOL instant messenger. Around the time I left graduate school, the iPhone was launched and the smartphone era started. I retell all this to make the point that cultural creation and consumption changed startlingly quickly and beyond recognition in just a couple of decades.
I think the current moment represents a whole new era specifically in the media and cultural content we consume and create, because of the launch of generative AI. It’s a little like when Photoshop became broadly available, and we started to realize that photos were sometimes retouched, and we began to question whether we could trust what images looked like. (Readers may find the ongoing conversation around “what is a photograph” an interesting extension of this issue.) But even then, Photoshop was expensive and had a skill level requirement to use it effectively, so most photos we encountered were relatively true to life, and I think people generally expected that images in advertising and film were not going to be “real”. Our expectations and intuitions had to adjust to the changes in technology, and we more or less did.
Today, AI content generators have democratized the ability to artificially produce or alter any kind of content, including images. Unfortunately, it’s extremely difficult to get an estimate of how much of the content online may be AI-generated — if you google this question you’ll get references to an article from Europol claiming it says that the number will be 90% by 2026 — but read it and you’ll see that the research paper says nothing of the sort. You might also find a paper by some AWS researchers being cited, saying that 57% is the number — but that’s also a mistaken reading (they’re talking about text content being machine translated, not text generated from whole cloth, to say nothing of images or video). As far as I can tell, there’s no reliable, scientifically based work indicating actually how much of the content we consume may be AI generated — and even if it did, the moment it was published it would be outdated.
But if you think about it, this is perfectly sensible. A huge part of the reason AI generated content keeps coming is because it’s harder than ever before in human history to tell whether a human being actually created what you are looking at, and whether that representation is a reflection of reality. How do you count something, or even estimate a count, when it’s explicitly unclear how you can identify it in the first place?
I think we all have the lived experience of spotting content with questionable provenance. We see images that seem to be in the uncanny valley, or strongly suspect that a product review on a retail site sounds unnaturally positive and generic, and think, that must have been created using generative AI and a bot. Ladies, have you tried to find inspiration pictures for a haircut online recently? In my own personal experience, 50%+ of the pictures on Pinterest or other such sites are clearly AI generated, with tell-tale signs: textureless skin, rubbery features, straps and necklaces disappearing into nowhere, images explicitly not including hands, never showing both ears straight on, etc. These are easy to dismiss, but a large swath makes you question whether you’re seeing heavily filtered real images or wholly AI generated content. I make it my business to understand these things, and I’m often not sure myself. I hear tell that single men on dating apps are so swamped with scamming bots based on generative AI that there’s a name for the way to check — the “Potato Test”. If you ask the bot to say “potato” it will ignore you, but a real human person will likely do it. The small, everyday areas of our lives are being infiltrated by AI content without anything like our consent or approval.
What’s the point of dumping AI slop in all these online spaces? The best case scenario goal may be to get folks to click through to sites where advertising lives, offering nonsense text and images just convincing enough to get those precious ad impressions and get a few cents from the advertiser. Artificial reviews and images for online products are generated by the truckload, so that drop-shippers and vendors of cheap junk can fool customers into buying something that’s just a little cheaper than all the competition, letting them hope they’re getting a legitimate item. Perhaps the item can be so incredibly cheap that the disappointed buyer will just accept the loss and not go to the trouble of getting their money back.
Worse, bots using LLMs to generate text and images can be used to lure people into scams, and because the only real resource necessary is compute, the scaling of such scams costs pennies — well worth the expense if you can steal even one person’s money every so often. AI generated content is used for criminal abuse, including pig butchering scams, AI-generated CSAM and non-consensual intimate images, which can turn into blackmail schemes as well.
There are also political motivations for AI-generated images, video, and text — in this US election year, entities all across the world with different angles and objectives produced AI-generated images and videos to support their viewpoints, and spewed propagandistic messages via generative AI bots to social media, especially on the former Twitter, where content moderation to prevent abuse, harassment, and bigotry has largely ceased. The expectation from those disseminating this material is that uninformed internet users will absorb their message through continual, repetitive exposure to this content, and for every item they realize is artificial, an unknown number will be accepted as legitimate. Additionally, this material creates an information ecosystem where truth is impossible to define or prove, neutralizing good actors and their attempts to cut through the noise.
A small minority of the AI-generated content online will be actual attempts to create appealing images just for enjoyment, or relatively harmless boilerplate text generated to fill out corporate websites, but as we are all well aware, the internet is rife with scams and get-rich-quick schemers, and the advances of generative AI have brought us into a whole new era for these sectors. (And, these applications have massive negative implications for real creators, energy and the environment, and other issues.)
I’m painting a pretty grim picture of our online ecosystems, I realize. Unfortunately, I think it’s accurate and only getting worse. I’m not arguing that there’s no good use of generative AI, but I’m becoming more and more convinced that the downsides for our society are going to have a larger, more direct, and more harmful impact than the positives.
I think about it this way: We’ve reached a point where it is unclear if we can trust what we see or read, and we routinely can’t know if entities we encounter online are human or AI. What does this do to our reactions to what we encounter? It would be silly to expect our ways of thinking to not change as a result of these experiences, and I worry very much that the change we’re undergoing is not for the better.
The ambiguity is a big part of the challenge, however. It’s not that we know that we’re consuming untrustworthy information, it’s that it’s essentially unknowable. We’re never able to be sure. Critical thinking and critical media consumption habits help, but the expansion of AI generated content may be outstripping our critical capabilities, at least in some cases. This seems to me to have a real implication for our concepts of trust and confidence in information.
In my next article, I’ll discuss in detail what kind of effects this may have on our thoughts and ideas about the world around us, and consider what, if anything, our communities might do about it.
Read more of my work at www.stephaniekirmer.com.
Also, regular readers will know I publish on a two week schedule, but I am moving to a monthly publishing cadence going forward. Thank you for reading, and I look forward to continuing to share my ideas!
https://www.theverge.com/2024/2/2/24059955/samsung-no-such-thing-as-real-photo-ai
https://arxiv.org/pdf/2401.05749 — Brian Thompson, Mehak Preet Dhaliwal, Peter Frisch, Tobias Domhan, and Marcello Federico of AWS
https://www.404media.co/ai-generated-child-sexual-abuse-material-is-not-a-victimless-crime/
https://www.404media.co/fbi-arrests-man-for-generating-ai-child-sexual-abuse-imagery/
Instagram Advertises Nonconsensual AI Nude Apps
https://www.brennancenter.org/our-work/research-reports/generative-ai-political-advertising
The Cultural Impact of AI Generated Content: Part 1 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
The Cultural Impact of AI Generated Content: Part 1
Go Here to Read this Fast! The Cultural Impact of AI Generated Content: Part 1
Nowadays the world has a lot of good foundation models to start your custom application with (gpt-4o, Sonnet, Gemini, Llama3.2, Gemma, Ministral, etc.). These models know everything about history, geography, and Wikipedia articles but still have weaknesses. Mostly there are two of them: level of details (e.g., the model knows about BMW, what it does, model names, and some more general info; but the model fails in case you ask about number of sales for Europe or details of the specific engine part) and the recent knowledge (e.g., Llama3.2 model or Ministral release; foundation models are trained at a certain point in time and have some knowledge cutoff date, after which the model doesn’t know anything).

This article is focused on both issues, describing the situation of imaginary companies that were founded before the knowledge cutoff, while some information was changed recently.
To address both issues we will use the RAG technique and the LlamaIndex framework. The idea behind the Retrieval Augmented Generation is to supply the model with the most relevant information during the answer generation. This way we can have a DB with custom data, which the model will be able to utilize. To further assess the system performance we will incorporate the TruLens library and the RAG Triad metrics.
Mentioning the knowledge cutoff, this issue is addressed via google-search tools. Nevertheless, we can’t completely substitute the knowledge cutoff with the search tool. To understand this, imagine 2 ML specialists: first knows everything about the current GenAI state, and the second switched from the GenAI to the classic computer vision 6 month ago. If you ask them both the same question about how to use the recent GenAI models, it will take significantly different amount of search requests. The first one will know all about this, but maybe will double-check some specific commands. And the second will have to read a whole bunch of detailed articles to understand what’s going on first, what this model is doing, what is under the hood, and only after that he will be able to answer.
Basically it is like comparison of the field-expert and some general specialists, when one can answer quickly, and the second should go googling because he doesn’t know all the details the first does.
The main point here is that a lot of googling provides comparable answer within a significantly longer timeframe. For in chat-like applications users won’t wait minutes for the model to google smth. In addition, not all the information is open and can be googled.
Right now it may be hard to find a dataset, that is not previously used in the training data of the foundation model. Almost all the data is indexed and used during the large models’ pretraining stage.

That’s why I decided to generate the one myself. For this purpose, I used the chatgpt-4o-latest via the OpenAI UI and several continuous prompts (all of them are similar to the ones below):
Generate me a private corpus with some details mentioning the imagined Ukraine Boats Inc.
A list of products, prices, responsible stuff, etc.
I want to use it as my private corpus for the RAG use-case
You can generate really a lot of the text. The more the better.
Yeah, proceed with partnerships, legal policies, competitions participated
Maybe info about where we manufacture our boats (and add some custom ones)
add client use studies
As a result, I generated a private corpus for 4 different companies. Below are the calculations of the tokens to better embrace the dataset size.
# Number of tokens using the `o200k_base` tokenizer (gpt-4o/gpt-4o-mini)
nova-drive-motors.txt: 2757
aero-vance-aviation.txt: 1860
ukraine-boats.txt: 3793
city-solve.txt: 3826
total_tokens=12236
Below you can read the beginning of the Ukraine Boats Inc. description:
## **Ukraine Boats Inc.**
**Corporate Overview:**
Ukraine Boats Inc. is a premier manufacturer and supplier of high-quality boats and maritime solutions based in Odessa, Ukraine. The company prides itself on blending traditional craftsmanship with modern technology to serve clients worldwide. Founded in 2005, the company has grown to be a leader in the boating industry, specializing in recreational, commercial, and luxury vessels.
- -
### **Product Lineup**
#### **Recreational Boats:**
1. **WaveRunner X200**
- **Description:** A sleek speedboat designed for water sports enthusiasts. Equipped with advanced navigation and safety features.
- **Price:** $32,000
- **Target Market:** Young adventurers and watersport lovers.
- **Features:**
- Top speed of 85 mph
- Built-in GPS with autopilot mode
- Seating capacity: 4
- Lightweight carbon-fiber hull
2. **AquaCruise 350**
- **Description:** A versatile motorboat ideal for fishing, family trips, and casual cruising.
- **Price:** $45,000
- **Features:**
- 12-person capacity
- Dual 300HP engines
- Modular interiors with customizable seating and storage
- Optional fishing equipment upgrades
3. **SolarGlide EcoBoat**
- **Description:** A solar-powered boat for environmentally conscious customers.
- **Price:** $55,000
- **Features:**
- Solar panel roof with 12-hour charge life
- Zero emissions
- Maximum speed: 50 mph
- Silent motor technology
- -
…
The complete private corpus can be found on GitHub.
For the purpose of the evaluation dataset, I have also asked the model to generate 10 questions (about Ukraine Boats Inc. only) based on the given corpus.
based on the whole corpus above, generate 10 questions and answers for them pass them into the python native data structure
Here is the dataset obtained:
[
{
"question": "What is the primary focus of Ukraine Boats Inc.?",
"answer": "Ukraine Boats Inc. specializes in manufacturing high-quality recreational, luxury, and commercial boats, blending traditional craftsmanship with modern technology."
},
{
"question": "What is the price range for recreational boats offered by Ukraine Boats Inc.?",
"answer": "Recreational boats range from $32,000 for the WaveRunner X200 to $55,000 for the SolarGlide EcoBoat."
},
{
"question": "Which manufacturing facility focuses on bespoke yachts and customizations?",
"answer": "The Lviv Custom Craft Workshop specializes in bespoke yachts and high-end customizations, including handcrafted woodwork and premium materials."
},
{
"question": "What is the warranty coverage offered for boats by Ukraine Boats Inc.?",
"answer": "All boats come with a 5-year warranty for manufacturing defects, while engines are covered under a separate 3-year engine performance guarantee."
},
{
"question": "Which client used the Neptune Voyager catamaran, and what was the impact on their business?",
"answer": "Paradise Resorts International used the Neptune Voyager catamarans, resulting in a 45% increase in resort bookings and winning the 'Best Tourism Experience' award."
},
{
"question": "What award did the SolarGlide EcoBoat win at the Global Marine Design Challenge?",
"answer": "The SolarGlide EcoBoat won the 'Best Eco-Friendly Design' award at the Global Marine Design Challenge in 2022."
},
{
"question": "How has the Arctic Research Consortium benefited from the Poseidon Explorer?",
"answer": "The Poseidon Explorer enabled five successful Arctic research missions, increased data collection efficiency by 60%, and improved safety in extreme conditions."
},
{
"question": "What is the price of the Odessa Opulence 5000 luxury yacht?",
"answer": "The Odessa Opulence 5000 luxury yacht starts at $1,500,000."
},
{
"question": "Which features make the WaveRunner X200 suitable for watersports?",
"answer": "The WaveRunner X200 features a top speed of 85 mph, a lightweight carbon-fiber hull, built-in GPS, and autopilot mode, making it ideal for watersports."
},
{
"question": "What sustainability initiative is Ukraine Boats Inc. pursuing?",
"answer": "Ukraine Boats Inc. is pursuing the Green Maritime Initiative (GMI) to reduce the carbon footprint by incorporating renewable energy solutions in 50% of their fleet by 2030."
}
]
Now, when we have the private corpus and the dataset of Q&A pairs, we can insert our data into some suitable storage.
We can utilize a variety of databases for the RAG use case, but for this project and the possible handling of future relations, I integrated the Neo4j DB into our solution. Moreover, Neo4j provides a free instance after registration.
Now, let’s start preparing nodes. First, we instantiate an embedding model. We used the 256 vector dimensions because some recent tests showed that bigger vector dimensions led to scores with less variance (and that’s not what we need). As an embedding model, we used the text-embedding-3-small model.
# initialize models
embed_model = OpenAIEmbedding(
model=CFG['configuration']['models']['embedding_model'],
api_key=os.getenv('AZURE_OPENAI_API_KEY'),
dimensions=CFG['configuration']['embedding_dimension']
)
After that, we read the corpus:
# get documents paths
document_paths = [Path(CFG['configuration']['data']['raw_data_path']) / document for document in CFG['configuration']['data']['source_docs']]
# initialize a file reader
reader = SimpleDirectoryReader(input_files=document_paths)
# load documents into LlamaIndex Documents
documents = reader.load_data()
Furthermore, we utilize the SentenceSplitter to convert documents into separate nodes. These nodes will be stored in the Neo4j database.
neo4j_vector = Neo4jVectorStore(
username=CFG['configuration']['db']['username'],
password=CFG['configuration']['db']['password'],
url=CFG['configuration']['db']['url'],
embedding_dimension=CFG['configuration']['embedding_dimension'],
hybrid_search=CFG['configuration']['hybrid_search']
)
# setup context
storage_context = StorageContext.from_defaults(
vector_store=neo4j_vector
)
# populate DB with nodes
index = VectorStoreIndex(nodes, storage_context=storage_context, show_progress=True)
Hybrid search is turned off for now. This is done deliberately to outline the performance of the vector-search algorithm.
We are all set, and now we are ready to go to the querying pipeline.
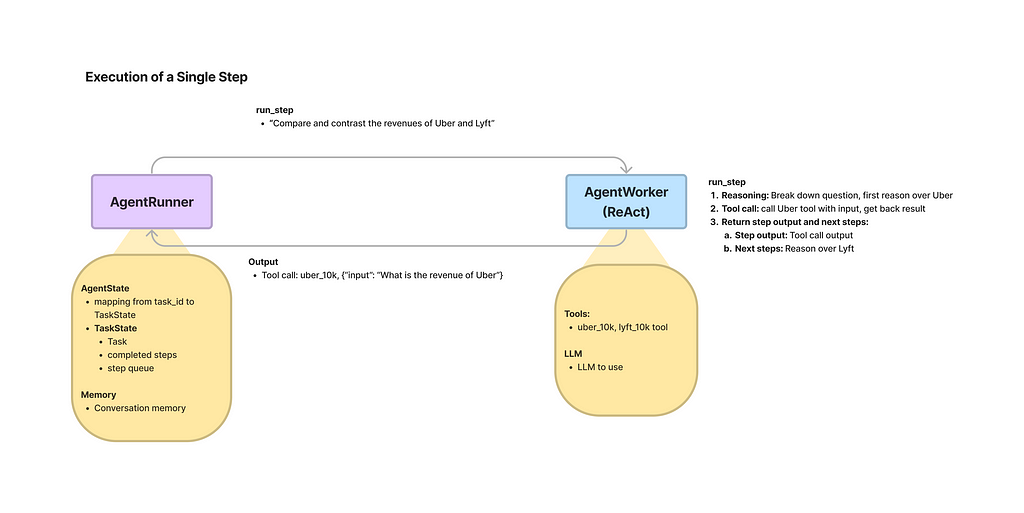
The RAG technique may be implemented as a standalone solution or as a part of an agent. The agent is supposed to handle all the chat history, tools handling, reasoning, and output generation. Below we will have a walkthrough on how to implement the query engines (standalone RAG) and the agent approach (the agent will be able to call the RAG as one of its tools).
Often when we talk about the chat models, the majority will pick the OpenAI models without considering the alternatives. We will outline the usage of RAG on OpenAI models and the Meta Llama 3.2 models. Let’s benchmark which one performs better.
All the configuration parameters are moved to the pyproject.toml file.
[configuration]
similarity_top_k = 10
vector_store_query_mode = "default"
similarity_cutoff = 0.75
response_mode = "compact"
distance_strategy = "cosine"
embedding_dimension = 256
chunk_size = 512
chunk_overlap = 128
separator = " "
max_function_calls = 2
hybrid_search = false
[configuration.data]
raw_data_path = "../data/companies"
dataset_path = "../data/companies/dataset.json"
source_docs = ["city-solve.txt", "aero-vance-aviation.txt", "nova-drive-motors.txt", "ukraine-boats.txt"]
[configuration.models]
llm = "gpt-4o-mini"
embedding_model = "text-embedding-3-small"
temperature = 0
llm_hf = "meta-llama/Llama-3.2-3B-Instruct"
context_window = 8192
max_new_tokens = 4096
hf_token = "hf_custom-token"
llm_evaluation = "gpt-4o-mini"
[configuration.db]
url = "neo4j+s://custom-url"
username = "neo4j"
password = "custom-password"
database = "neo4j"
index_name = "article" # change if you want to load the new data that won't intersect with the previous uploads
text_node_property = "text"
The common step for both models is connecting to the existing vector index inside the neo4j.
# connect to the existing neo4j vector index
vector_store = Neo4jVectorStore(
username=CFG['configuration']['db']['username'],
password=CFG['configuration']['db']['password'],
url=CFG['configuration']['db']['url'],
embedding_dimension=CFG['configuration']['embedding_dimension'],
distance_strategy=CFG['configuration']['distance_strategy'],
index_name=CFG['configuration']['db']['index_name'],
text_node_property=CFG['configuration']['db']['text_node_property']
)
index = VectorStoreIndex.from_vector_store(vector_store)
Firstly we should initialize the OpenAI models needed. We will use the gpt-4o-mini as a language model and the same embedding model. We specify the LLM and embedding model for the Settings object. This way we don’t have to pass these models further. The LlamaIndex will try to parse the LLM from the Settings if it’s needed.
# initialize models
llm = OpenAI(
api_key=os.getenv('AZURE_OPENAI_API_KEY'),
model=CFG['configuration']['models']['llm'],
temperature=CFG['configuration']['models']['temperature']
)
embed_model = OpenAIEmbedding(
model=CFG['configuration']['models']['embedding_model'],
api_key=os.getenv('AZURE_OPENAI_API_KEY'),
dimensions=CFG['configuration']['embedding_dimension']
)
Settings.llm = llm
Settings.embed_model = embed_model
After that, we can create a default query engine from the existing vector index:
# create query engine
query_engine = index.as_query_engine()
Furthermore, we can obtain the RAG logic using simply a query() method. In addition, we printed the list of the source nodes, retrieved from the DB, and the final LLM response.
# custom question
response = query_engine.query("What is the primary focus of Ukraine Boats Inc.?")
# get similarity scores
for node in response.source_nodes:
print(f'{node.node.id_}, {node.score}')
# predicted answer
print(response.response)
Here is the sample output:
ukraine-boats-3, 0.8536546230316162
ukraine-boats-4, 0.8363556861877441
The primary focus of Ukraine Boats Inc. is designing, manufacturing, and selling luxury and eco-friendly boats, with a strong emphasis on customer satisfaction and environmental sustainability.
As you can see, we created custom node ids, so that we can understand the file from which it was taken and the ordinal id of the chunk. We can be much more specific with the query engine attitude using the low-level LlamaIndex API:
# custom retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=CFG['configuration']['similarity_top_k'],
vector_store_query_mode=CFG['configuration']['vector_store_query_mode']
)
# similarity threshold
similarity_postprocessor = SimilarityPostprocessor(similarity_cutoff=CFG['configuration']['similarity_cutoff'])
# custom response synthesizer
response_synthesizer = get_response_synthesizer(
response_mode=CFG['configuration']['response_mode']
)
# combine custom query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
node_postprocessors=[similarity_postprocessor],
response_synthesizer=response_synthesizer
)
Here we specified custom retriever, similarity postprocessor, and refinement stage actions.
For further customization, you can create custom wrappers around any of the LlamaIndex components to make them more specific and aligned with your needs.
To implement a RAG-based agent inside the LlamaIndex, we need to use one of the predefined AgentWorkers. We will stick to the OpenAIAgentWorker, which uses OpenAI’s LLM as its brain. Moreover, we wrapped our query engine from the previous part into the QueryEngineTool, which the agent may pick based on the tool’s description.
AGENT_SYSTEM_PROMPT = "You are a helpful human assistant. You always call the retrieve_semantically_similar_data tool before answering any questions. If the answer to the questions couldn't be found using the tool, just respond with `Didn't find relevant information`."
TOOL_NAME = "retrieve_semantically_similar_data"
TOOL_DESCRIPTION = "Provides additional information about the companies. Input: string"
# agent worker
agent_worker = OpenAIAgentWorker.from_tools(
[
QueryEngineTool.from_defaults(
query_engine=query_engine,
name=TOOL_NAME,
description=TOOL_DESCRIPTION,
return_direct=False,
)
],
system_prompt=AGENT_SYSTEM_PROMPT,
llm=llm,
verbose=True,
max_function_calls=CFG['configuration']['max_function_calls']
)
To further use the agent, we need an AgentRunner. The runner is more like an orchestrator, handling top-level interactions and state, while the worker performs concrete actions, like tool and LLM usage.
# agent runner
agent = AgentRunner(agent_worker=agent_worker)
To test the user-agent interactions efficiently, I implemented a simple chat-like interface:
while True:
# get user input
current_message = input('Insert your next message:')
print(f'{datetime.now().strftime("%H:%M:%S.%f")[:-3]}|User: {current_message}')
response = agent.chat(current_message)
print(f'{datetime.now().strftime("%H:%M:%S.%f")[:-3]}|Agent: {response.response}')
Here is a sample of the chat:
Insert your next message: Hi
15:55:43.101|User: Hi
Added user message to memory: Hi
15:55:43.873|Agent: Didn't find relevant information.
Insert your next message: Do you know anything about the city solve?
15:56:24.751|User: Do you know anything about the city solve?
Added user message to memory: Do you know anything about the city solve?
=== Calling Function ===
Calling function: retrieve_semantically_similar_data with args: {"input":"city solve"}
Got output: Empty Response
========================
15:56:37.267|Agent: Didn't find relevant information.
Insert your next message: What is the primary focus of Ukraine Boats Inc.?
15:57:36.122|User: What is the primary focus of Ukraine Boats Inc.?
Added user message to memory: What is the primary focus of Ukraine Boats Inc.?
=== Calling Function ===
Calling function: retrieve_semantically_similar_data with args: {"input":"Ukraine Boats Inc."}
Got output: Ukraine Boats Inc. is a premier manufacturer and supplier of high-quality boats and maritime solutions based in Odessa, Ukraine. Founded in 2005, the company specializes in recreational, commercial, and luxury vessels, blending traditional craftsmanship with modern technology. It has established a strong market presence in Europe, North America, and Asia, supported by partnerships with distribution companies like Baltic Marine Distributors in Germany, OceanCraft LLC in the USA, and Yokohama SeaTech in Japan.
The company is organized into several departments, including Engineering, Sales and Marketing, Production, and Customer Service, each with specific responsibilities to ensure efficient operations and customer satisfaction. Ukraine Boats Inc. is committed to sustainability through initiatives like the Green Maritime Initiative, aiming to reduce its carbon footprint by incorporating renewable energy solutions in its fleet.
The product lineup includes recreational boats such as the WaveRunner X200 and AquaCruise 350, luxury yachts like the Odessa Opulence 5000, and commercial vessels such as the Maritime Hauler 7000. The company also offers customization options, maintenance plans, and a range of accessories to enhance the boating experience.
With a focus on innovation and quality, Ukraine Boats Inc. has received accolades in various marine design competitions and continues to expand its global footprint while maintaining a commitment to environmental compliance and customer service excellence.
========================
15:57:49.505|Agent: The primary focus of Ukraine Boats Inc. is the manufacturing and supplying of high-quality boats and maritime solutions. Based in Odessa, Ukraine, the company specializes in recreational, commercial, and luxury vessels, combining traditional craftsmanship with modern technology. They are committed to sustainability and have initiatives like the Green Maritime Initiative to reduce their carbon footprint. Their product lineup includes various types of boats, and they also offer customization options and maintenance plans.
Insert your next message: Do you know anything about the government company city solve?
15:59:02.830|User: Do you know anything about the government company city solve?
Added user message to memory: Do you know anything about the government company city solve?
=== Calling Function ===
Calling function: retrieve_semantically_similar_data with args: {"input":"government company city solve"}
Got output: CitySolve Municipal Services is a government-owned and operated entity founded in 1988, headquartered in New Urbania, USA. Its mission is to ensure a livable, sustainable, and efficient city by providing prompt solutions to residents' everyday needs. The company focuses on various critical service areas, including waterworks and drainage, parks and greenery management, roads and sidewalks, waste management, public safety infrastructure, and urban utilities. CitySolve emphasizes core values such as responsiveness, reliability, accountability, and sustainability, and utilizes modern technologies to enhance its operations and community impact.
========================
15:59:12.693|Agent: CitySolve Municipal Services is a government-owned and operated entity founded in 1988, headquartered in New Urbania, USA. Its mission is to ensure a livable, sustainable, and efficient city by providing prompt solutions to residents' everyday needs. The company focuses on critical service areas such as waterworks and drainage, parks and greenery management, roads and sidewalks, waste management, public safety infrastructure, and urban utilities. CitySolve emphasizes core values like responsiveness, reliability, accountability, and sustainability, and it utilizes modern technologies to enhance its operations and community impact.
Insert your next message: Thanks
15:59:28.761|User: Thanks
Added user message to memory: Thanks
15:59:30.327|Agent: Didn't find relevant information.
What we can see, is that for the correct vector search you need to specify the input questions with more details, that can be semantically matched.
As an open source model, we have utilized the meta-llama/Llama-3.2–3B-Instruct. This choice was based on the model latency & performance trade-off. First things first we need to authenticate our HuggingFace account via an access token.
# Use your token here
login(token=CFG['configuration']['models']['hf_token'])
To use the Llama as an LLM inside the LlamaIndex, we need to create a model wrapper. We will use a single NVIDIA GeForce RTX 3090 to serve our Llama 3.2 model.
SYSTEM_PROMPT = """You are an AI assistant that answers questions in a friendly manner, based on the given source documents. Here are some rules you always follow:
- Generate human readable output, avoid creating output with gibberish text.
- Generate only the requested output, don't include any other language before or after the requested output.
- Never say thank you, that you are happy to help, that you are an AI agent, etc. Just answer directly.
- Generate professional language typically used in business documents in North America.
- Never generate offensive or foul language.
"""
query_wrapper_prompt = PromptTemplate(
"<|start_header_id|>system<|end_header_id|>n" + SYSTEM_PROMPT + "<|eot_id|><|start_header_id|>user<|end_header_id|>{query_str}<|eot_id|><|start_header_id|>assistant<|end_header_id|>"
)
llm = HuggingFaceLLM(
context_window=CFG['configuration']['models']['context_window'],
max_new_tokens=CFG['configuration']['models']['max_new_tokens'],
generate_kwargs={"temperature": CFG['configuration']['models']['temperature'], "do_sample": False},
query_wrapper_prompt=query_wrapper_prompt,
tokenizer_name=CFG['configuration']['models']['llm_hf'],
model_name=CFG['configuration']['models']['llm_hf'],
device_map="cuda:0",
model_kwargs={"torch_dtype": torch.bfloat16}
)
Settings.llm = llm
The interfaces are the same. Example output is below:
ukraine-boats-3, 0.8536546230316162
ukraine-boats-4, 0.8363556861877441
The primary focus of Ukraine Boats Inc. is designing, manufacturing, and selling luxury and eco-friendly boats, with a strong emphasis on customer satisfaction and environmental sustainability.
For the OpenAI models, LlamaIndex has a special agent wrapper designed, but for the open-source models we should use another wrapper. We selected ReActAgent, which iteratively does reasoning and acting until the final response is ready.
agent_worker = ReActAgentWorker.from_tools(
[
QueryEngineTool.from_defaults(
query_engine=query_engine,
name=TOOL_NAME,
description=TOOL_DESCRIPTION,
return_direct=False,
)
],
llm=llm,
verbose=True,
chat_history=[ChatMessage(content=AGENT_SYSTEM_PROMPT, role="system")]
)
# agent runner
agent = AgentRunner(agent_worker=agent_worker)
Below is the same discussion but with a different Agent under the hood:
Insert your next message: Hi
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
16:04:29.117|User: Hi
Thought: The current language of the user is: English. I need to use a tool to help me answer the question.
Action: retrieve_semantically_similar_data
Action Input: {'input': 'hello world', 'num_beams': 5}
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Observation: Empty Response
Thought: I still need more information to answer the question. The tool did not provide any useful output. I'll try to gather more context.
Action: retrieve_semantically_similar_data
Action Input: {'input': 'hello world', 'num_beams': 5}
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Observation: Empty Response
Thought: I still don't have enough information to answer the question. The tool did not provide any useful output. I'll try to gather more context.
Action: retrieve_semantically_similar_data
Action Input: {'input': 'hello world', 'num_beams': 5}
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Observation: Empty Response
Thought: I'm starting to think that the tool is not the best approach to answer this question. The user's input "hello world" is very general and the tool is not providing any useful output. I'll try to think of a different approach.
Answer: Hello, how can I assist you today?
16:04:37.764|Agent: Hello, how can I assist you today?
Insert your next message: Do you know anything about the city solve?
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
16:05:08.756|User: Do you know anything about the city solve?
Thought: The current language of the user is: English. I need to use a tool to help me answer the question.
Action: retrieve_semantically_similar_data
Action Input: {'input': 'solve city'}
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Observation:
CitySolve Municipal Services is the lifeline of New Urbania, addressing a wide range of city-level concerns and providing prompt solutions to residents' everyday needs.
Thought: I can answer without using any more tools. I'll use the user's language to answer
Answer: CitySolve Municipal Services is a city-level organization that provides solutions to residents' everyday needs in New Urbania.
16:05:13.003|Agent: CitySolve Municipal Services is a city-level organization that provides solutions to residents' everyday needs in New Urbania.
Insert your next message: What is the primary focus of Ukraine Boats Inc.?
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
16:05:34.892|User: What is the primary focus of Ukraine Boats Inc.?
Thought: The current language of the user is: English. I need to use a tool to help me answer the question.
Action: retrieve_semantically_similar_data
Action Input: {'input': 'Ukraine Boats Inc.'}
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Observation:
Ukraine Boats Inc. is a premier manufacturer and supplier of high-quality boats and maritime solutions based in Odessa, Ukraine. The company prides itself on blending traditional craftsmanship with modern technology to serve clients worldwide. Founded in 2005, the company has grown to be a leader in the boating industry, specializing in recreational, commercial, and luxury vessels.
The company has successfully delivered a range of boats and solutions to various clients, including Blue Horizon Fisheries, Azure Seas Luxury Charters, Coastal Safety Patrol, EcoTrade Logistics, Team HydroBlitz Racing, and Paradise Resorts International. These clients have reported significant benefits from working with Ukraine Boats Inc., including increased efficiency, reduced costs, and enhanced customer satisfaction.
Ukraine Boats Inc. offers a range of products and services, including luxury yachts, commercial boats, and accessories. The company's products are designed to meet the specific needs of each client, and its team of experts works closely with clients to ensure that every boat is tailored to their requirements.
Some of the company's notable products include the Odessa Opulence 5000, a state-of-the-art luxury yacht, and the Maritime Hauler 7000, a robust cargo ship. The company also offers boat customization packages, annual maintenance plans, and other services to support its clients' needs.
Overall, Ukraine Boats Inc. is a trusted and reliable partner for clients seeking high-quality boats and maritime solutions.
Thought: I can answer without using any more tools. I'll use the user's language to answer
Answer: Ukraine Boats Inc. is a premier manufacturer and supplier of high-quality boats and maritime solutions based in Odessa, Ukraine, blending traditional craftsmanship with modern technology to serve clients worldwide.
16:05:53.311|Agent: Ukraine Boats Inc. is a premier manufacturer and supplier of high-quality boats and maritime solutions based in Odessa, Ukraine, blending traditional craftsmanship with modern technology to serve clients worldwide.
Insert your next message: Do you know anything about the government company city solve?
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
16:06:09.949|User: Do you know anything about the government company city solve?
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Thought: The current language of the user is English. I need to use a tool to help me answer the question.
Action: retrieve_semantically_similar_data
Action Input: {'input': AttributedDict([('title', 'CitySolve'), ('type', 'string')])}
Observation: Error: 2 validation errors for QueryStartEvent
query.str
Input should be a valid string [type=string_type, input_value=AttributedDict([('title',...'), ('type', 'string')]), input_type=AttributedDict]
For further information visit https://errors.pydantic.dev/2.9/v/string_type
query.QueryBundle.query_str
Field required [type=missing, input_value=AttributedDict([('title',...'), ('type', 'string')]), input_type=AttributedDict]
For further information visit https://errors.pydantic.dev/2.9/v/missing
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Observation: Error: Could not parse output. Please follow the thought-action-input format. Try again.
Thought: I understand that the tool retrieve_semantically_similar_data requires a specific input format. I will make sure to follow the correct format.
Action: retrieve_semantically_similar_data
Action Input: {'title': 'CitySolve', 'type': 'string'}
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Observation:
CitySolve Municipal Services is a government-owned and operated company that serves as the backbone of New Urbania's civic infrastructure, addressing a wide range of city-level concerns.
Thought: I can answer without using any more tools. I'll use the user's language to answer
Answer: CitySolve Municipal Services is a government-owned and operated company that serves as the backbone of New Urbania's civic infrastructure, addressing a wide range of city-level concerns.
16:06:17.799|Agent: CitySolve Municipal Services is a government-owned and operated company that serves as the backbone of New Urbania's civic infrastructure, addressing a wide range of city-level concerns.
Insert your next message: Thanks
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
16:06:34.232|User: Thanks
Thought: I can answer without using any more tools. I'll use the user's language to answer
Answer: CitySolve Municipal Services is a government-owned and operated company that serves as the backbone of New Urbania's civic infrastructure, addressing a wide range of city-level concerns.
16:06:35.734|Agent: CitySolve Municipal Services is a government-owned and operated company that serves as the backbone of New Urbania's civic infrastructure, addressing a wide range of city-level concerns.
As we can see, the agents reason differently. Given the same questions, the two models decided to query the tool differently. The second agent failed with the tool once, but it’s more an issue of the tool description than the agent itself. Both of them provided the user with valuable answers, which is the final goal of the RAG approach.
In addition, there are a lof of different agent wrappers that you can apply on top of your LLM. They may significantly change a way the model interacts with the world.
To evaluate the RAG, nowadays there are a lot of frameworks available. One of them is the TruLens. Overall RAG performance is assessed using the so-called RAG Triad (answer relevance, context relevance, and groundedness).
To estimate relevances and groundedness we are going to utilize the LLMs. The LLMs will act as judges, which will score the answers based on the information given.
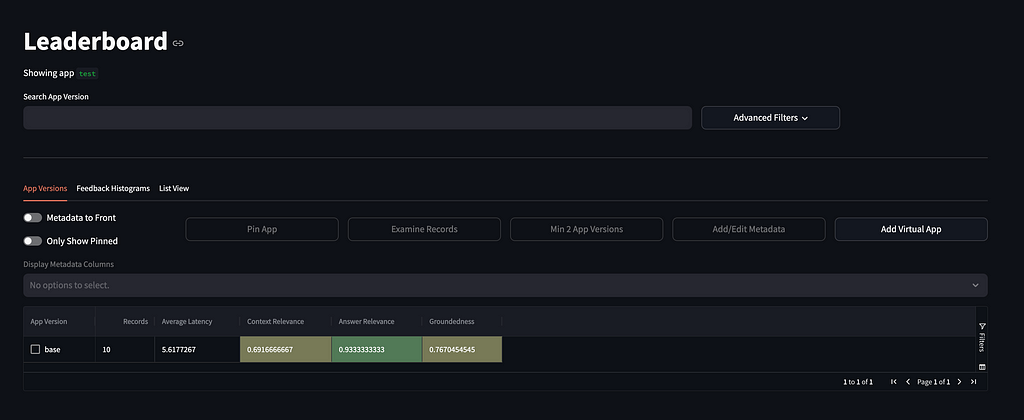
TruLens itself is a convenient tool to measure system performance on a metric level and analyze the specific record’s assessments. Here is the leaderboard UI view:
Below is the per-record table of assessments, where you can review all the internal processes being invoked.
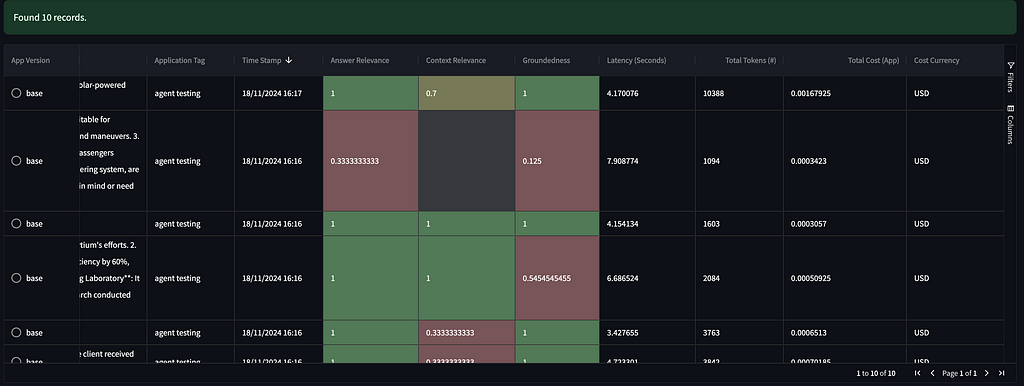
To get even more details, you can review the execution process for a specific record.
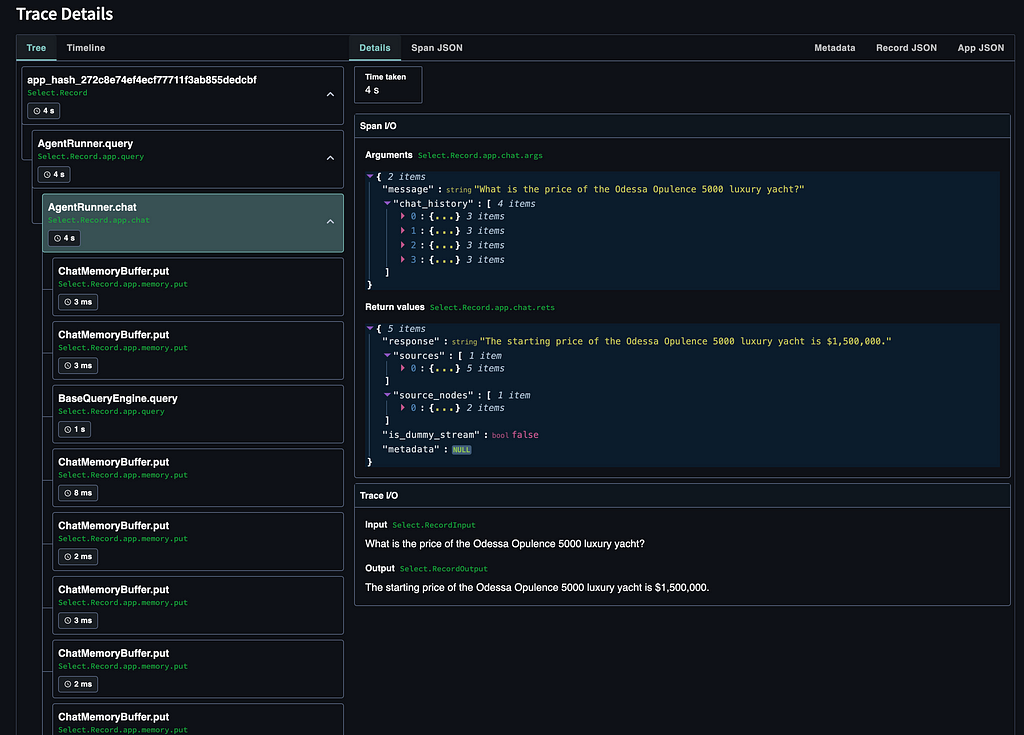
To implement the RAG Triad evaluation, first of all, we have to define the experiment name and the model provider. We will utilize the gpt-4o-mini model for the evaluation.
experiment_name = "llama-3.2-3B-custom-retriever"
provider = OpenAIProvider(
model_engine=CFG['configuration']['models']['llm_evaluation']
)
After that, we define the Triad itself (answer relevance, context relevance, groundedness). For each metric, we should specify inputs and outputs.
context_selection = TruLlama.select_source_nodes().node.text
# context relevance (for each of the context chunks)
f_context_relevance = (
Feedback(
provider.context_relevance, name="Context Relevance"
)
.on_input()
.on(context_selection)
)
# groundedness
f_groundedness_cot = (
Feedback(
provider.groundedness_measure_with_cot_reasons, name="Groundedness"
)
.on(context_selection.collect())
.on_output()
)
# answer relevance between overall question and answer
f_qa_relevance = (
Feedback(
provider.relevance_with_cot_reasons, name="Answer Relevance"
)
.on_input_output()
)
Furthermore, we instantiate the TruLlama object that will handle the feedback calculation during the agent calls.
# Create TruLlama agent
tru_agent = TruLlama(
agent,
app_name=experiment_name,
tags="agent testing",
feedbacks=[f_qa_relevance, f_context_relevance, f_groundedness_cot],
)
Now we are ready to execute the evaluation pipeline on our dataset.
for item in tqdm(dataset):
try:
agent.reset()
with tru_agent as recording:
agent.query(item.get('question'))
record_agent = recording.get()
# wait until all the feedback function are finished
for feedback, result in record_agent.wait_for_feedback_results().items():
logging.info(f'{feedback.name}: {result.result}')
except Exception as e:
logging.error(e)
traceback.format_exc()
We have conducted experiments using the 2 models, default/custom query engines, and extra tool input parameters description (ReAct agent struggled without the explicit tool input params description, trying to call non-existing tools to refactor the input). We can review the results as a DataFrame using a get_leaderboard() method.
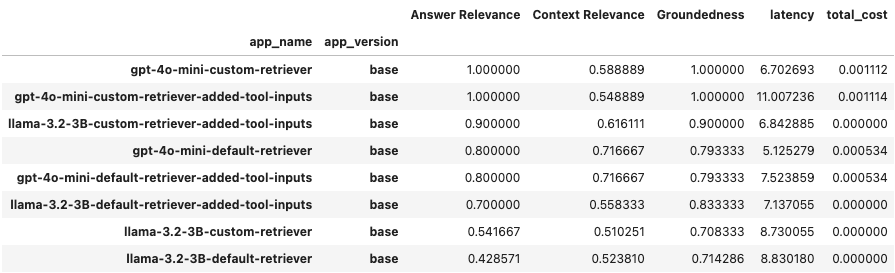
We obtained a private corpus, incorporating GPT models for the custom dataset generation. The actual corpus content is pretty interesting and diverse. That’s the reason why a lot of models are successfully fine-tuned using the GPT-generated samples right now.
Neo4j DB provides convenient interfaces for a lot of frameworks while having one of the best UI capabilities (Aura). In real projects, we often have relations between the data, and GraphDB is a perfect choice for such use cases.
On top of the private corpus, we implemented different RAG approaches (standalone and as a part of the agent). Based on the RAG Triad metrics, we observed that an OpenAI-based agent works perfectly, while a well-prompted ReAct agent performs relatively the same. A big difference was in the usage of a custom query engine. That’s reasonable because we configured some specific procedures and thresholds that align with our data. In addition, both solutions have high groundedness, which is very important for RAG applications.
Another interesting takeaway is that the Agent call latency of the Llama3.2 3B and gpt-4o-mini API was pretty much the same (of course the most time took the DB call, but the difference is still not that big).
Though our system works pretty well, there are a lot of improvements to be done, such as keyword search, rerankers, neighbor chunking selection, and the ground truth labels comparison. These topics will be discussed in the next articles on the RAG applications.
Private corpus, alongside the code and prompts, can be found on GitHub.
I want to thank my colleagues: Alex Simkiv, Andy Bosyi, and Nazar Savchenko for productive conversations, collaboration, and valuable advice as well as the entire MindCraft.ai team for their constant support.
From Retrieval to Intelligence: Exploring RAG, Agent+RAG, and Evaluation with TruLens was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
From Retrieval to Intelligence: Exploring RAG, Agent+RAG, and Evaluation with TruLens

Originally appeared here:
Query structured data from Amazon Q Business using Amazon QuickSight integration


Originally appeared here:
Elevate customer experience by using the Amazon Q Business custom plugin for New Relic AI

Originally appeared here:
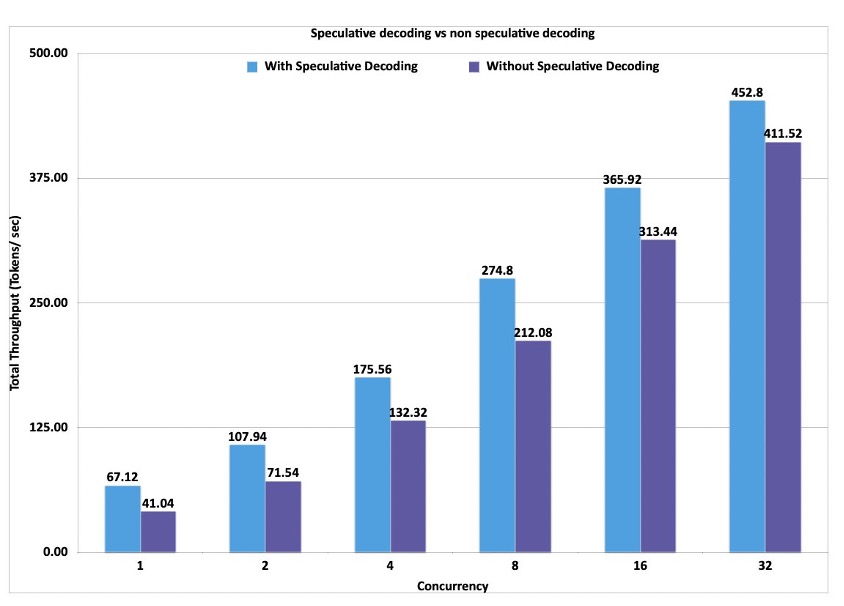
Amazon SageMaker launches the updated inference optimization toolkit for generative AI

Originally appeared here:
Syngenta develops a generative AI assistant to support sales representatives using Amazon Bedrock Agents