Understand Semantic Structures with Transformers and Topic Modeling
We live in the age of big data. At this point it’s become a cliche to say that data is the oil of the 21st century but it really is so. Data collection practices have resulted in huge piles of data in just about everyone’s hands.
Interpreting data, however, is no easy task, and much of the industry and academia still rely on solutions, which provide little in the ways of explanations. While deep learning is incredibly useful for predictive purposes, it rarely gives practitioners an understanding of the mechanics and structures that underlie the data.
Textual data is especially tricky. While natural language and concepts like “topics” are incredibly easy for humans to have an intuitive grasp of, producing operational definitions of semantic structures is far from trivial.
In this article I will introduce you to different conceptualizations of discovering latent semantic structures in natural language, we will look at operational definitions of the theory, and at last I will demonstrate the usefulness of the method with a case study.
Theory: What is a “Topic”?
While topic to us humans seems like a completely intuitive and self-explanatory term, it is hardly so when we try to come up with a useful and informative definition. The Oxford dictionary’s definition is luckily here to help us:
A subject that is discussed, written about, or studied.
Well, this didn’t get us much closer to something we can formulate in computational terms. Notice how the word subject, is used to hide all the gory details. This need not deter us, however, we can certainly do better.
In Natural Language Processing, we often use a spatial definition of semantics. This might sound fancy, but essentially we imagine that semantic content of text/language can be expressed in some continuous space (often high-dimensional), where concepts or texts that are related are closer to each other than those that aren’t. If we embrace this theory of semantics, we can easily come up with two possible definitions for topic.
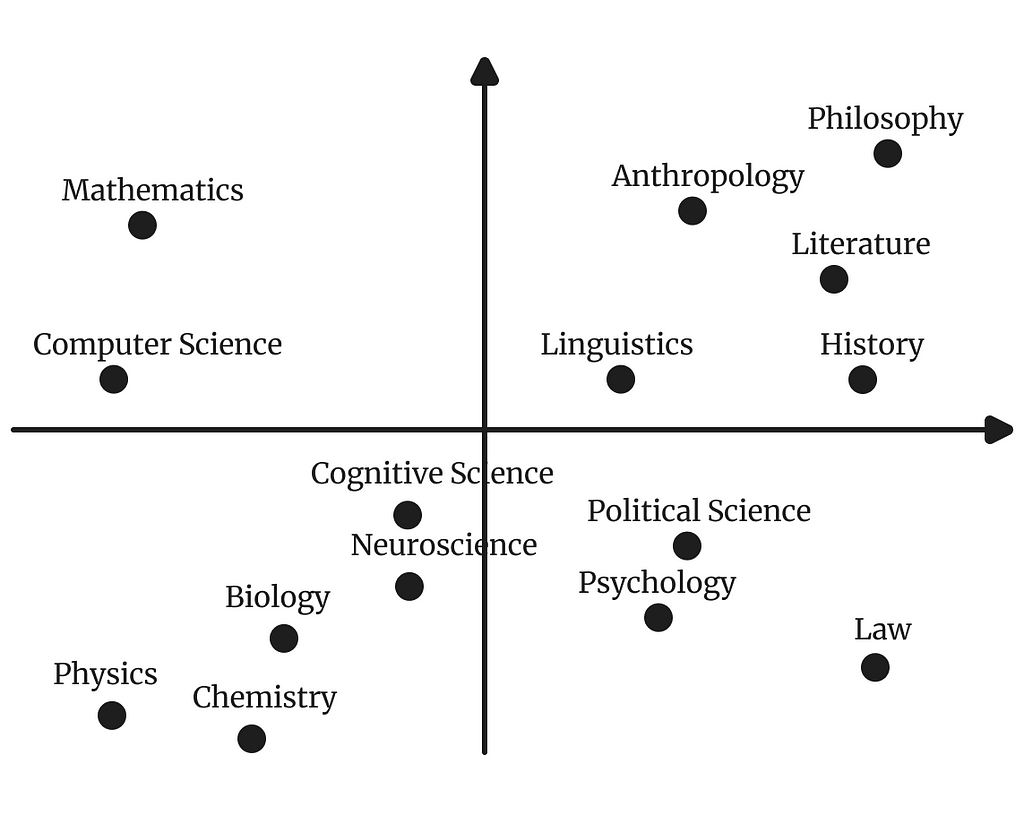
Topics as Semantic Clusters
A rather intuitive conceptualization is to imagine topic as groups of passages/concepts in semantic space that are closely related to each other, but not as closely related to other texts. This incidentally means that one passage can only belong to one topic at a time.
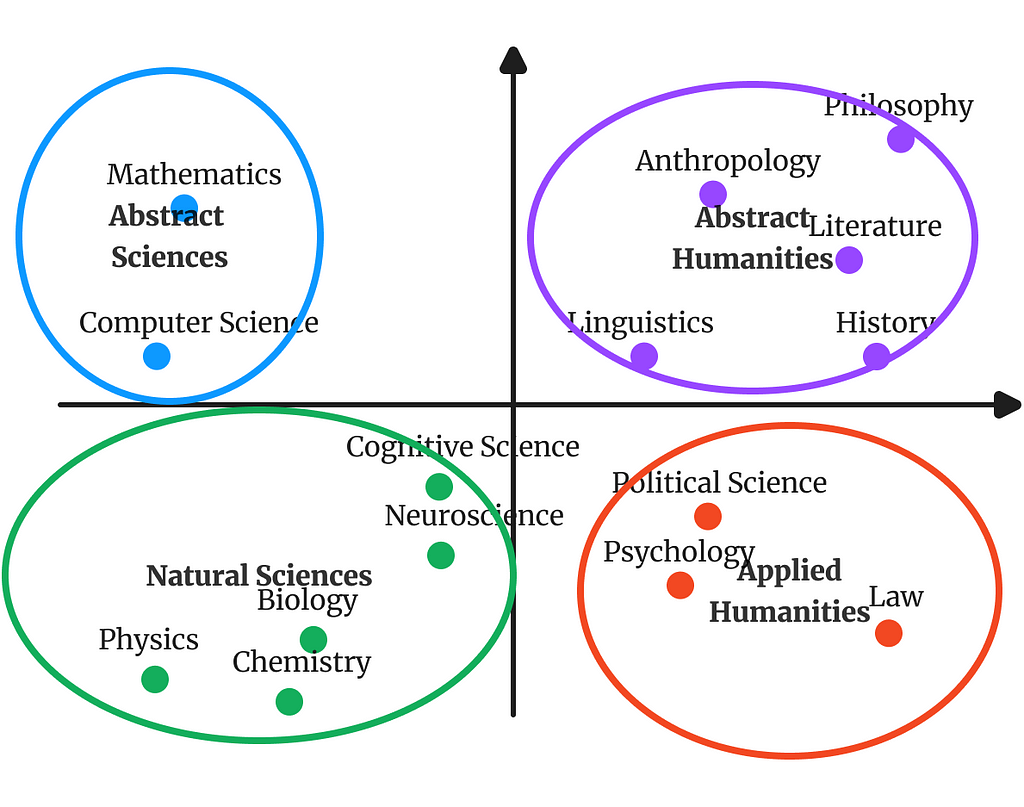
This clustering conceptualization also lends itself to thinking about topics hierarchically. You can imagine that the topic “animals” might contain two subclusters, one which is “Eukaryates”, while the other is “Prokaryates”, and then you could go down this hierarchy, until, at the leaves of the tree you will find actual instances of concepts.
Of course a limitation of this approach is that longer passages might contain multiple topics in them. This could either be addressed by splitting up texts to smaller, atomic parts (e.g. words) and modeling over those, but we can also ditch the clustering conceptualization alltogether.
Topics as Axes of Semantics
We can also think of topics as the underlying dimensions of the semantic space in a corpus. Or in other words: Instead of describing what groups of documents there are we are explaining variation in documents by finding underlying semantic signals.
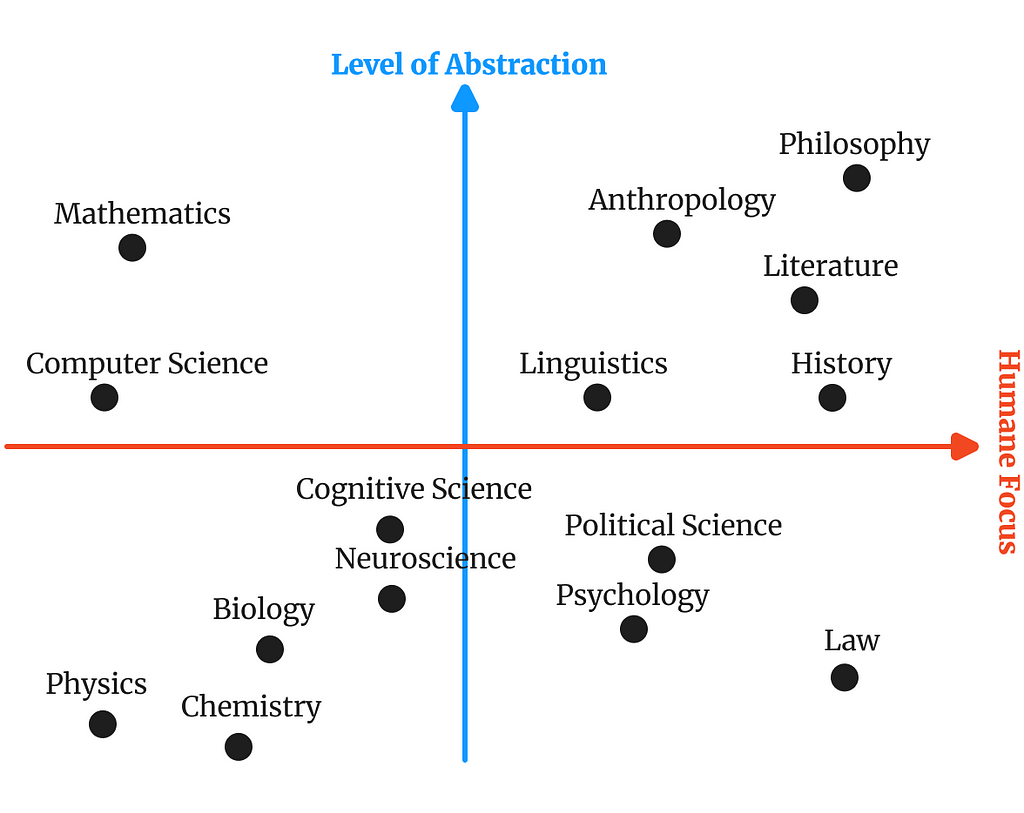
We are explaining variation in documents by finding underlying semantic signals.
You could for instance imagine that the most important axes that underlie restaurant reviews would be:
- Satisfaction with the food
- Satisfaction with the service
I hope you see why this conceptualization is useful for certain purposes. Instead of us finding “good reviews” and “bad reviews”, we get an understanding of what it is that drives differences between these. A pop culture example of this kind of theorizing is of course the political compass. Yet again, instead of us being interested in finding “conservatives” and “progressives”, we find the factors that differentiate these.
Let’s Model!
Now that we got the philosophy out of the way, we can get our hands dirty with designing computational models based on our conceptual understanding.
Semantic Representations
Classically the way we represented the semantic content of texts, was the so-called bag-of-words model. Essentially you make the very strong, and almost trivially wrong assumption, that the unordered collection of words in a document is constitutive of its semantic content. While these representations are plagued with a number of issues (curse of dimensionality, discrete space, etc.) they have been demonstrated useful by decades of research.
Luckily for us, the state of the art has progressed beyond these representations, and we have access to models that can represent text in context. Sentence Transformers are transformer models which can encode passages into a high-dimensional continuous space, where semantic similarity is indicated by vectors having high cosine similarity. In this article I will mainly focus on models that use these representations.
Clustering Models
Models that are currently the most widespread in the topic modeling community for contextually sensitive topic modeling (Top2Vec, BERTopic) are based on the clustering conceptualization of topics.
They discover topics in a process that consists of the following steps:
- Reduce dimensionality of semantic representations using UMAP
- Discover cluster hierarchy using HDBSCAN
- Estimate importances of terms for each cluster using post-hoc descriptive methods (c-TF-IDF, proximity to cluster centroid)
These models have gained a lot of traction, mainly due to their interpretable topic descriptions and their ability to recover hierarchies, as well as to learn the number of topics from the data.
If we want to model nuances in topical content, and understand factors of semantics, clustering models are not enough.
I do not intend to go into great detail about the practical advantages and limitations of these approaches, but most of them stem from philosophical considerations outlined above.
Semantic Signal Separation
If we are to discover the axes of semantics in a corpus, we will need a new statistical model.
We can take inspiration from classical topic models, such as Latent Semantic Allocation. LSA utilizes matrix decomposition to find latent components in bag-of-words representations. LSA’s main goal is to find words that are highly correlated, and explain their cooccurrence as an underlying semantic component.
Since we are no longer dealing with bag-of-words, explaining away correlation might not be an optimal strategy for us. Orthogonality is not statistical independence. Or in other words: Just because two components are uncorrelated, it does not mean that they are statistically independent.
Orthogonality is not statistical independence
Other disciplines have luckily come up with decomposition models that discover maximally independent components. Independent Component Analysis has been extensively used in Neuroscience to discover and remove noise signals from EEG data.
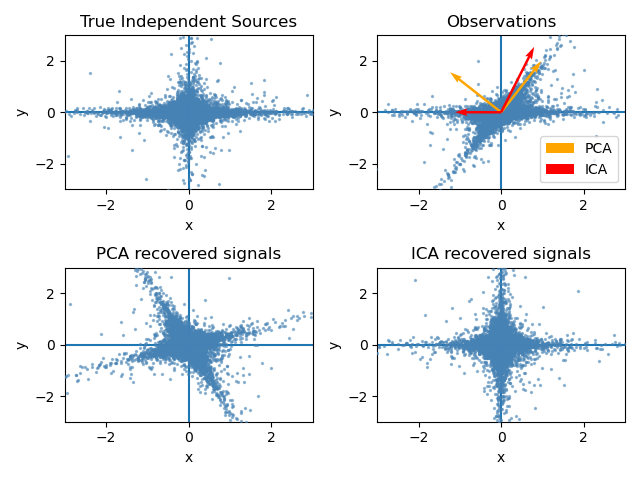
The main idea behind Semantic Signal Separation is that we can find maximally independent underlying semantic signals in a corpus of text by decomposing representations with ICA.
We can gain human-readable descriptions of topics by taking terms from the corpus that rank highest on a given component.
Case Study: Machine Learning Papers
To demonstrate the usefulness of Semantic Signal Separation for understanding semantic variation in corpora, we will fit a model on a dataset of approximately 118k machine learning abstracts.
To reiterate once again what we’re trying to achieve here: We want to establish the dimensions, along which all machine learning papers are distributed. Or in other words we would like to build a spatial theory of semantics for this corpus.
For this we are going to use a Python library I developed called Turftopic, which has implementations of most topic models that utilize representations from transformers, including Semantic Signal Separation. Additionally we are going to install the HuggingFace datasets library so that we can download the corpus at hand.
pip install turftopic datasets
Let us download the data from HuggingFace:
from datasets import load_dataset
ds = load_dataset("CShorten/ML-ArXiv-Papers", split="train")
We are then going to run Semantic Signal Separation on this data. We are going to use the all-MiniLM-L12-v2 Sentence Transformer, as it is quite fast, but provides reasonably high quality embeddings.
from turftopic import SemanticSignalSeparation
model = SemanticSignalSeparation(10, encoder="all-MiniLM-L12-v2")
model.fit(ds["abstract"])
model.print_topics()

These are highest ranking keywords for the ten axes we found in the corpus. You can see that most of these are quite readily interpretable, and already help you see what underlies differences in machine learning papers.
I will focus on three axes, sort of arbitrarily, because I found them to be interesting. I’m a Bayesian evangelist, so Topic 7 seems like an interesting one, as it seems that this component describes how probabilistic, model based and causal papers are. Topic 6 seems to be about noise detection and removal, and Topic 1 is mostly concerned with measurement devices.
We are going to produce a plot where we display a subset of the vocabulary where we can see how high terms rank on each of these components.
First let’s extract the vocabulary from the model, and select a number of words to display on our graphs. I chose to go with words that are in the 99th percentile based on frequency (so that they still remain somewhat visible on a scatter plot).
import numpy as np
vocab = model.get_vocab()
# We will produce a BoW matrix to extract term frequencies
document_term_matrix = model.vectorizer.transform(ds["abstract"])
frequencies = document_term_matrix.sum(axis=0)
frequencies = np.squeeze(np.asarray(frequencies))
# We select the 99th percentile
selected_terms_mask = frequencies > np.quantile(frequencies, 0.99)
We will make a DataFrame with the three selected dimensions and the terms so we can easily plot later.
import pandas as pd
# model.components_ is a n_topics x n_terms matrix
# It contains the strength of all components for each word.
# Here we are selecting components for the words we selected earlier
terms_with_axes = pd.DataFrame({
"inference": model.components_[7][selected_terms],
"measurement_devices": model.components_[1][selected_terms],
"noise": model.components_[6][selected_terms],
"term": vocab[selected_terms]
})
We will use the Plotly graphing library for creating an interactive scatter plot for interpretation. The X axis is going to be the inference/Bayesian topic, Y axis is going to be the noise topic, and the color of the dots is going to be determined by the measurement device topic.
import plotly.express as px
px.scatter(
terms_with_axes,
text="term",
x="inference",
y="noise",
color="measurement_devices",
template="plotly_white",
color_continuous_scale="Bluered",
).update_layout(
width=1200,
height=800
).update_traces(
textposition="top center",
marker=dict(size=12, line=dict(width=2, color="white"))
)
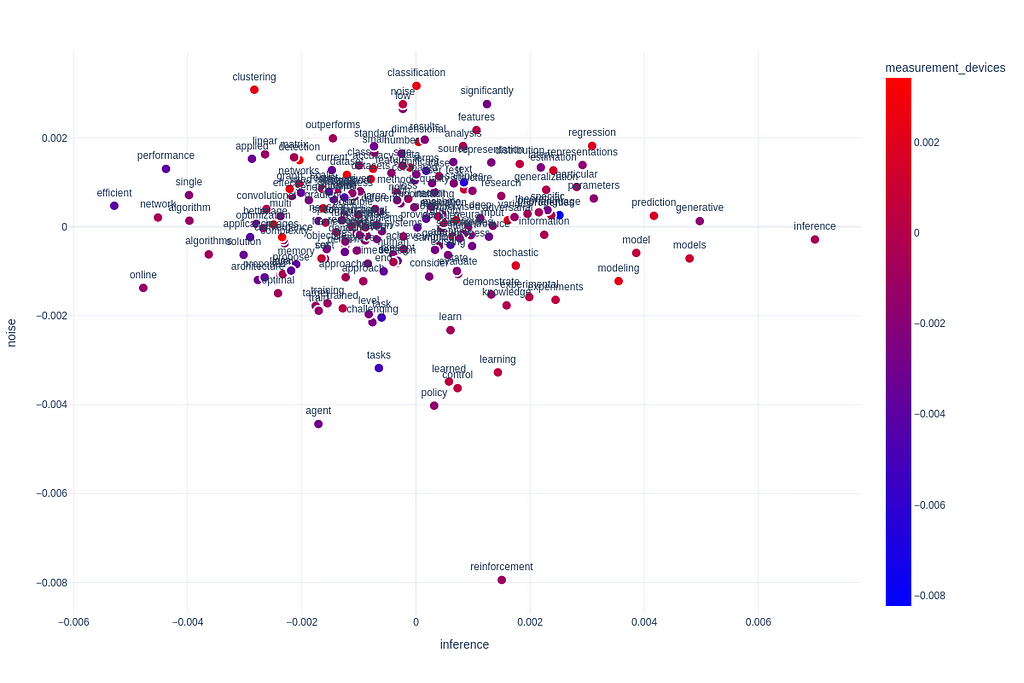
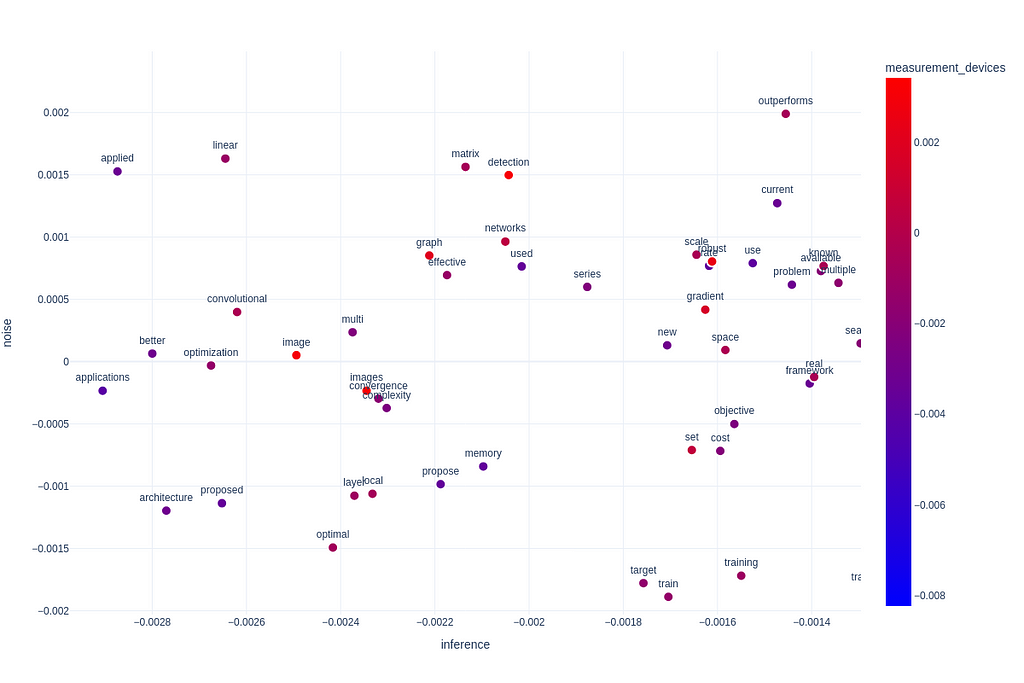
We can already infer a lot about the semantic structure of our corpus based on this visualization. For instance we can see that papers that are concerned with efficiency, online fitting and algorithms score very low on statistical inference, this is somewhat intuitive. On the other hand what Semantic Signal Separation has already helped us do in a data-based approach is confirm, that deep learning papers are not very concerned with statistical inference and Bayesian modeling. We can see this from the words “network” and “networks” (along with “convolutional”) ranking very low on our Bayesian axis. This is one of the criticisms the field has received. We’ve just given support to this claim with empirical evidence.
Deep learning papers are not very concerned with statistical inference and Bayesian modeling, which is one of the criticisms the field has received. We’ve just given support to this claim with empirical evidence.
We can also see that clustering and classification is very concerned with noise, but that agent-based models and reinforcement learning isn’t.
Additionally an interesting pattern we may observe is the relation of our Noise axis to measurement devices. The words “image”, “images”, “detection” and “robust” stand out as scoring very high on our measurement axis. These are also in a region of the graph where noise detection/removal is relatively high, while talk about statistical inference is low. What this suggests to us, is that measurement devices capture a lot of noise, and that the literature is trying to counteract these issues, but mainly not by incorporating noise into their statistical models, but by preprocessing. This makes a lot of sense, as for instance, Neuroscience is known for having very extensive preprocessing pipelines, and many of their models have a hard time dealing with noise.
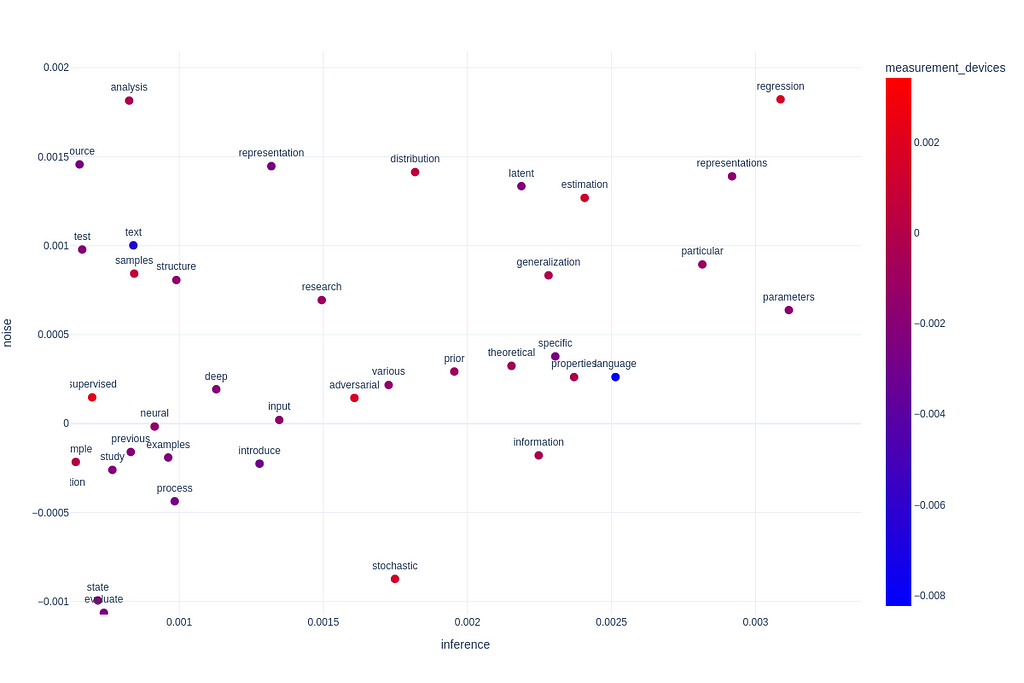
We can also observe that the lowest scoring terms on measurement devices is “text” and “language”. It seems that NLP and machine learning research is not very concerned with neurological bases of language, and psycholinguistics. Observe that “latent” and “representation is also relatively low on measurement devices, suggesting that machine learning research in neuroscience is not super involved with representation learning.
Of course the possibilities from here are endless, we could spend a lot more time interpreting the results of our model, but my intent was to demonstrate that we can already find claims and establish a theory of semantics in a corpus by using Semantic Signal Separation.
Semantic Signal Separation should mainly be used as an exploratory measure for establishing theories, rather than taking its results as proof of a hypothesis.
One thing I would like to emphasize is that Semantic Signal Separation should mainly be used as an exploratory measure for establishing theories, rather than taking its results as proof of a hypothesis. What I mean here, is that our results are sufficient for gaining an intuitive understanding of differentiating factors in our corpus, an then building a theory about what is happening, and why it is happening, but it is not sufficient for establishing the theory’s correctness.
Conclusion
Exploratory data analysis can be confusing, and there are of course no one-size-fits-all solutions for understanding your data. Together we’ve looked at how to enhance our understanding with a model-based approach from theory, through computational formulation, to practice.
I hope this article will serve you well when analysing discourse in large textual corpora. If you intend to learn more about topic models and exploratory text analysis, make sure to have a look at some of my other articles as well, as they discuss some aspects of these subjects in greater detail.
(( Unless stated otherwise, figures were produced by the author. ))
Semantic Signal Separation was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Semantic Signal Separation