Today, we are excited to announce that Code Llama foundation models, developed by Meta, are available for customers through Amazon SageMaker JumpStart to deploy with one click for running inference. Code Llama is a state-of-the-art large language model (LLM) capable of generating code and natural language about code from both code and natural language prompts. […]
Efficiently scaling GPT from large to titanic magnitudes within the meta-learning framework
Introduction
GPT is a family of language models that has been recently gaining a lot of popularity. The attention of the Data Science community was rapidly captured by the release of GPT-3 in 2020. After the appearance of GPT-2, almost nobody could even assume that nearly in a year there would appear a titanic version of GPT containing 175B of parameters! This is by two orders of magnitude more, compared to its predecessor.
The enormous capacity of GPT-3 made it possible to use it in various everyday scenarios: code completion, article writing, content creation, virtual assistants, etc. While the quality of these tasks is not always perfect, the overall progress achieved by GPT-3 is absolutely astonishing!
In this article, we will have a detailed look at the main details of GPT-3 and useful ideas inspired by GPT-2 creators. Throughout the exploration, we will be referring to the official GPT-3 paper. It is worth noting that most of the GPT-3 settings including data collection, architecture choice and pre-training process are directly derived from GPT-2. That is why most of the time we will be focusing on novel aspects of GPT-3.
Note. For a better understanding, this article assumes that you are already familiar with the first two GPT versions. If not, please navigate to the articles below comprehensively explaining it:
GPT-3 creators were highly interested in the training approach used in GPT-2: instead of using a common pre-training + fine-tuning framework, the authors collected a large and diverse dataset and incorporated the task objective in the text input. This methodology was convenient for several reasons:
By eliminating the fine-tuning phase, we do not need several large labelled datasets for individual downstream tasks anymore.
For different tasks, a single version of the model can be used instead of many.
The model operates in a more similar way that humans do. Most of the time humans need no or only a few language examples to fully understand a given task. During inference, the model can receive those examples in the form of text. As a result, this aspect provides better perspectives for developing AI applications that interact with humans.
The model is trained only once on a single dataset. Contrary to the pre-training + fine-tuning paradigm, the model had to be trained on two different datasets which could have had completely dissimilar data distributions leading to potential generalization problems.
Formally, the described framework is called meta-learning. The paper provides an official definition:
“Meta-learning in the context of language models means the model develops a broad set of skills and pattern recognition abilities at training time, and then uses those abilities at inference time to rapidly adapt to or recognize the desired task”
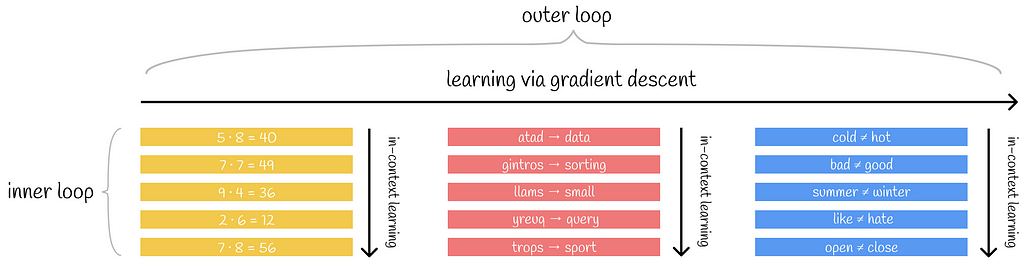
To further describe the learning paradigm, inner and outer loop terms are introduced. Basically, an inner loop is an equivalent of a single forward pass during training while an outer loop designates a set of all inner loops.
Throughout the training process, a model can receive similar tasks on different text examples. For example, the model can see the following examples across different batches:
Good is a synonym for excellent.
Computer is a synonym for laptop.
House is a synonym for building.
In this case, these examples help the model to understand what a synonym is that can be useful during inference when it is asked to find synonyms for a certain word. A combination of examples focused on helping the model capture similar linguistic knowledge within a paritcular task is called “in-context learning”.
Training examples passed to the model can be categorized into one of many abstract context groups. Within each of these groups, the model gains more knowledge and skills in a certain domain. In the example from the diagram, the model learns multiplication, text reverse algorithm and words with opposite meanings. Text sequences from the same group can be passed in different batches. Image adopted by the author.
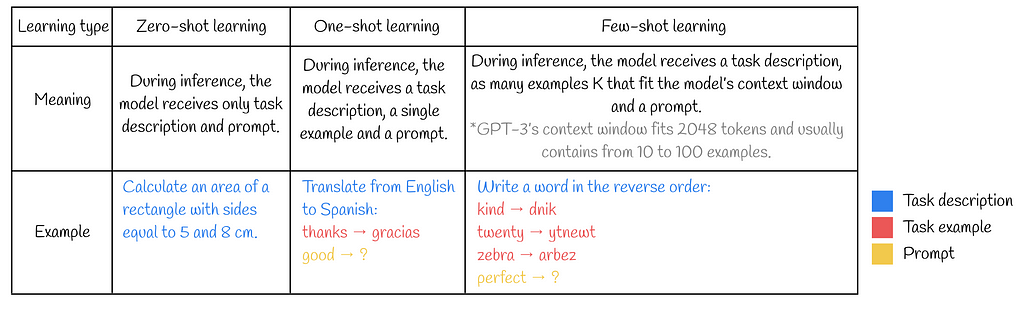
n-shot learning
A query performed for the model during inference can additionally contain task examples. It turns out that task demonstration plays an important role in helping the model to better understand the objective of a query. Based on the number of provided task examples (shots), there exist three types of learning which are summarized in the table below:
Learning types definitions
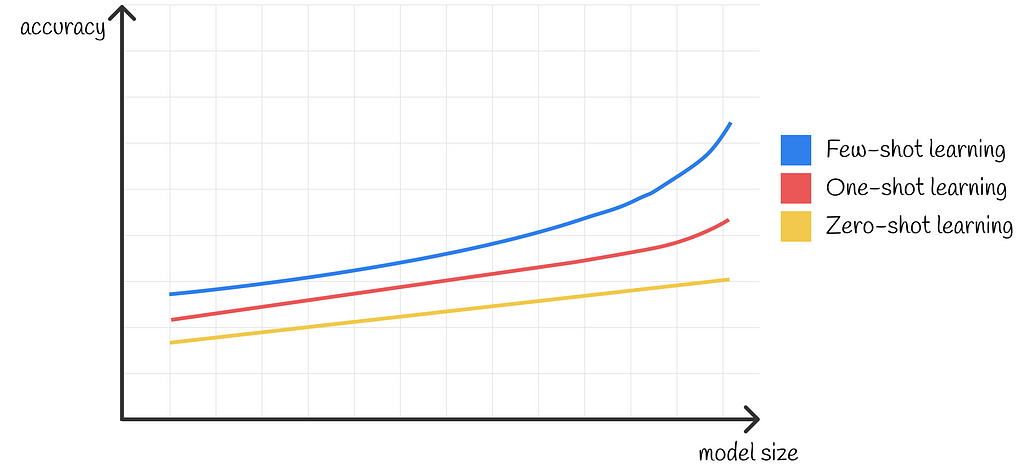
In the majority of cases (but not always) the number of provided examples positively correlates with the model’s ability to provide a correct answer. The authors have completed research in which they used models of different sizes in one of three n-shot settings. The results show that with capacity growth, models become more proficient at in-context learning. This is demonstrated in the lineplot below where the performance gap between few-, one- and zero-shot settings gets larger with the model’s size.
Plot demonstrating larger performance gaps between three different learning types with the increase of the model size
Architecture
The paper precisely describes architecture settings in GPT-3:
“We use the same model and architecture as GPT-2, including the modified initialization, pre-normalization, and reversible tokenization described therein, with the exception that we use alternating dense and locally banded sparse attention patterns in the layers of the transformer, similar to the Sparse Transformer”.
Dataset
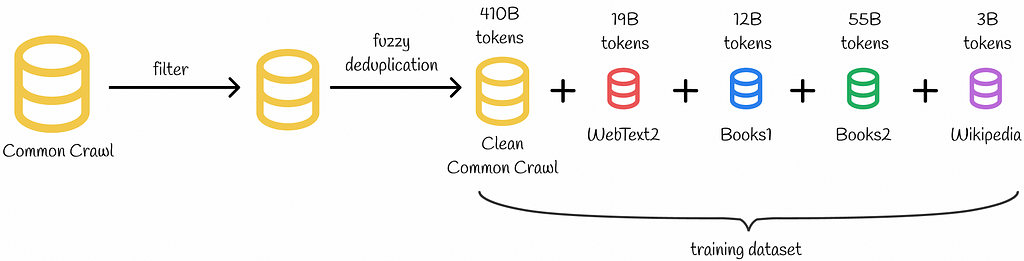
Initially, the authors wanted to use the Common Crawl dataset for training GPT-3. This extremely large dataset captures a diverse set of topics. The raw dataset version had issues with data quality, which is why it was initially filtered and deduplicated. To make the final dataset even more diverse, it was concatenated with four other smaller datasets demonstrated in the diagram below:
Training dataset composition
The dataset used for training GPT-3 is two magnitudes larger than the one used for GPT-2.
Training details
Optimizer: Adam (β₁ = 0.9, β₂ = 0.999, ε = 1e-6).
Gradient clipping at 1.0 is used to prevent the problem of exploding gradients.
A combination of cosine decay and linear warmup is used for learning rate adjustment.
Batch size is gradually increased from 32K to 3.2M tokens during training.
Weight decay of 0.1 is used as a regularizer.
For better computation efficiency, the length of all sequences is set to 2048. Different documents within a single sequence are separated by a delimiter token.
Beam search
GPT-3 is an autoregressive model which means that it uses information about predicted words in the past as input to predict the next word in the future.
The greedy approach is the most naive method of constructing text sequences in autoregressive models. Basically, at each iteration, it forces the model to choose the most probable word and use it as input for the next word. However, it turns out that choosing the most probable word at the current iteration is not optimal for log-likelihood optimization!
Log-likelihood loss function in GPT
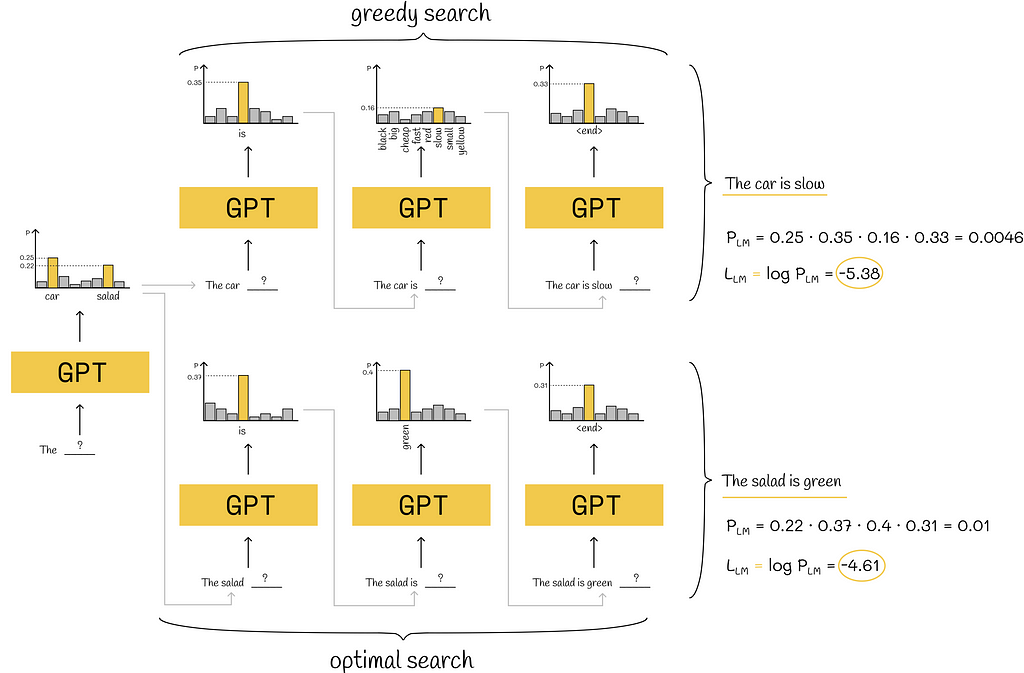
There might be a situation when choosing a current word with a lower probability could then lead to higher probabilities of the rest of the predicted words. In contrast, choosing a local word with the highest probability does not guarantee that the next words will also correspond to high probabilities. An example showing when the greedy strategy does not work optimally is demonstrated in the diagram below:
An example where the greedy search is not optimal. Though the chosen word “car” had a higher probability at the first iteration, the rest predictions ultimately led to lower total probability, compared to the optimal search. As a consequence, the log-likelihood for the greedy strategy is less (worse) than the one corresponding to the optimal search.
A possible solution would consist of finding the most probable sequence among all possible options.However, this approach is extremely inefficient since there exist innumerable combinations of possible sequences.
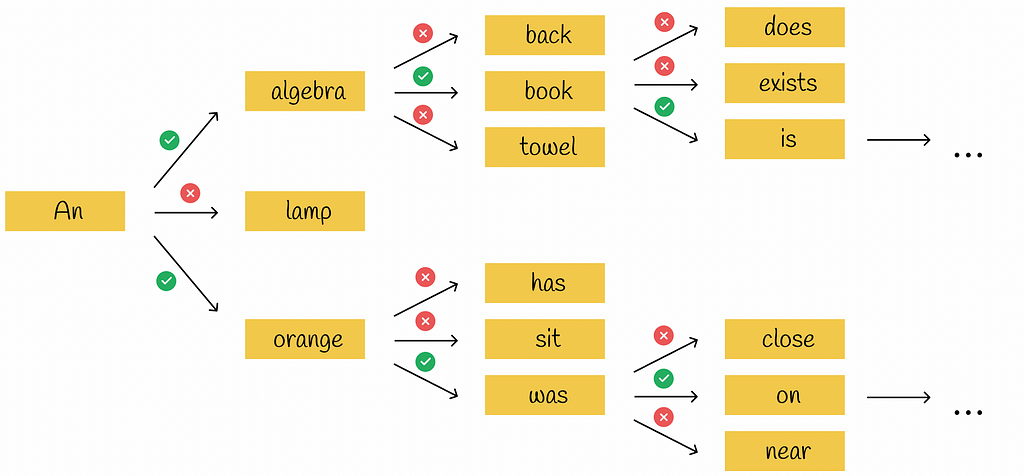
Beam search is a good trade-off between greedy search and exploration of all possible combinations. At each iteration, it chooses the several most probable tokens and maintains a set of the current most probable sequences. Whenever a new more probable sequence is formed, it replaces the least probable one from the set. At the end of the algorithm, the most probable sequence from the set is returned.
Beam search example. A set of size = 2 is used to maintain the most probable sequences.
Beam search does not guarantee the best search strategy but in practice, its approximations work very well. For that reason, it is used in GPT-3.
Drawbacks
Despite GPT-3 amazing capabilities to generate human-like long pieces of text, it has several drawbacks:
Decisions made by GPT-3 during text generation are usually not interpretable making it difficult to analyse.
GPT-3 can be used in harmful ways which cannot always be prevented by the model.
GPT-3 contains biases in the training dataset making it vulnerable in some cases to fairness aspects, especially when it comes to highly sensitive domains like gender equality, religion or race.
Compared to its previous predecessor GPT-2, GPT-3 required hundreds times more energy (thousands petaflops / day) to be trained which is not eco-friendly. At the same, the GPT-3 developers justify this aspect by the fact that their model is extremely efficient during inference, thus the average consumption is still low.
Conclusion
GPT-3 gained huge popularity due to its unimaginable 175B trainable parameters which have strongly bet all the previous models on several top benchmarks! At that time, the GPT-3 results were so good that sometimes it was difficult to distinguish whether a text was generated by a human or GPT-3.
Despite several disadvantages and limitations of GPT-3, it has opened doors to researchers for new explorations and potential improvements in the future.
Under The Hood Of The Generative AI For Video By OpenAI
How can AI transform a static image into a dynamic, realistic video? OpenAI’s Sora introduces an answer through the innovative use of spacetime patches.
In the rapidly evolving landscape of generative models, OpenAI’s Sora stands out as a significant milestone, promising to reshape our understanding and capabilities in video generation. We unpack the technology behind Sora and its potential to inspire a new generation of models in image, video, and 3D content creation.
The demo above was generated by OpenAI using the prompt: A cat waking up its sleeping owner demanding breakfast. The owner tries to ignore the cat, but the cat tries new tactics and finally the owner pulls out a secret stash of treats from under the pillow to hold the cat off a little longer. — With Sora we verge onto near indistinguishable realism with video content generation. The full model is yet to be fully released to the public as its undergoing testing.
How Sora’s Unique Approach Transforms Video Generation
In the world of generative models we have seen a number of approaches from GAN’s to auto-regressive, and diffusion models, all with their own strengths and limitations. Sora now introduces a paradigm shift with a new modelling techniques and flexibility to handle a broad range of duration’s, aspect ratios, and resolutions.
Sora combines both diffusion and transformer architectures together to create a diffusion transformer model and is able to provide features such as:
Text-to-video: As we have seen
Image-to-video: Bringing life to still images
Video-to-video: Changing the style of video to something else
Extending video in time: Forwards and backwards
Create seamless loops: Tiled videos that seem like they never end
Image generation: Still image is a movie of one frame (up to 2048 x 2048)
Generate video in any format: From 1920 x 1080 to 1080 x 1920 and everything in between
Simulate virtual worlds: Like Minecraft and other video games
Create a video: Up to 1 minute in length with multiple shorts
Imagine for one moment you’re in a kitchen. The traditional video generation models like those from Pika and RunwayML a like the cooks that follow recipes to the letter. They can produce excellent dishes (videos) but are limited by the recipes (algorithms) they know. The cooks might specialize in baking cakes (short clips) or cooking pasta (specific types of videos), using specific ingredients (data formats) and techniques (model architectures).
Sora, on the other hand, is a new kind of chef who understand the fundamentals of flavor. This chef doesn’t just follow recipes; they invent new ones. The flexibility of Sora’s ingredients (data) and techniques (model architecture) is what allow Sora to produce a wide range of high-quality videos, akin to a master chef’s versatile culinary creations.
The Core of Sora’s Secret Ingredient: Exploring the Spacetime Patches
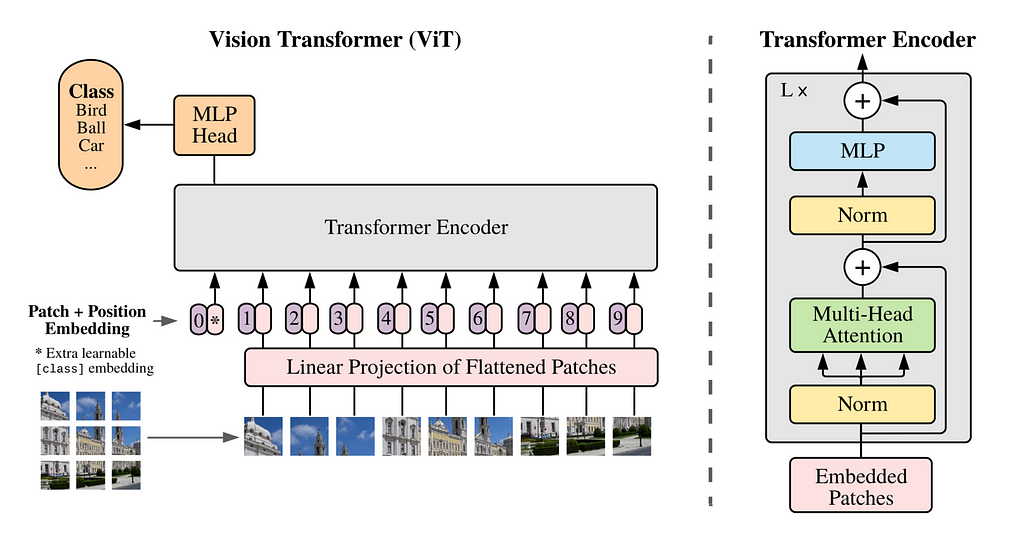
Traditionally with Vision Transformers we use a sequence of images “patches” to train a transformer model for image recognition instead of words for language transformers. The patches allow us to move away from convolutional neural networks for image processing.
However with vision transformers were constraint on image training data that was fixed in size and aspect ratio which limited the quality and required vast amounts of preprocessing of images.
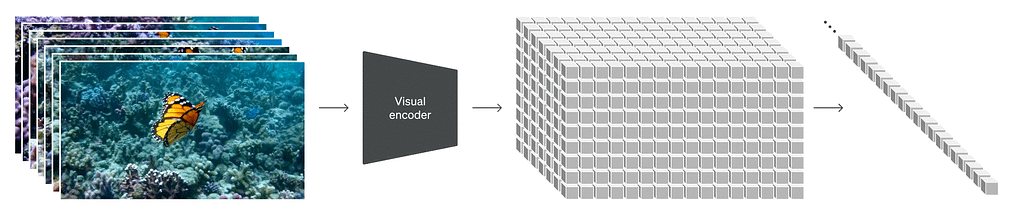
Visualization of Spacetime Patching (Processing) — Credit: OpenAI (Sora)
By treating videos as sequences of patches, Sora maintains the original aspect ratios and resolutions, similar to NaViT’s handling of images. This preservation is crucial for capturing the true essence of the visual data, enabling the model to learn from a more accurate representation of the world and thus giving Sora its near magical accuracy.
The method allows Sora to efficiently process a diverse array of visual data without the need for pre-processing steps like resizing or padding. This flexibility ensures that every piece of data contributes to the model’s understanding, much like how a chef uses a variety of ingredients to enhance a dish’s flavor profile.
The detailed and flexible handling of video data through spacetime patches lays the groundwork for sophisticated features such as accurate physics simulation and 3D consistency. These capabilities are essential for creating videos that not only look realistic but also adhere to the physical rules of the world, offering a glimpse into the potential for AI to create complex, dynamic visual content.
Feeding Sora: The Role of Diverse Data in Training
The quality and diversity of training data are crucial for the performance of generative models. Existing video models were traditionally trained on a more restrictive set of data, shorter lengths and narrow target.
Sora leverages a vast and varied dataset, including videos and images of different durations, resolutions, and aspect ratios. It’s ability to re-create digital worlds like Minecraft, its likely also included gameplay and simulated world footage from systems such as Unreal or Unity in its training set in order to capture all the angles and various styles of video content. This brings Sora to a “generalist” model just like GPT-4 for text.
This extensive training enables Sora to understand complex dynamics and generate content that is both diverse and high in quality. The approach mimics the way large language models are trained on diverse text data, applying a similar philosophy to visual content to achieve generalist capabilities.
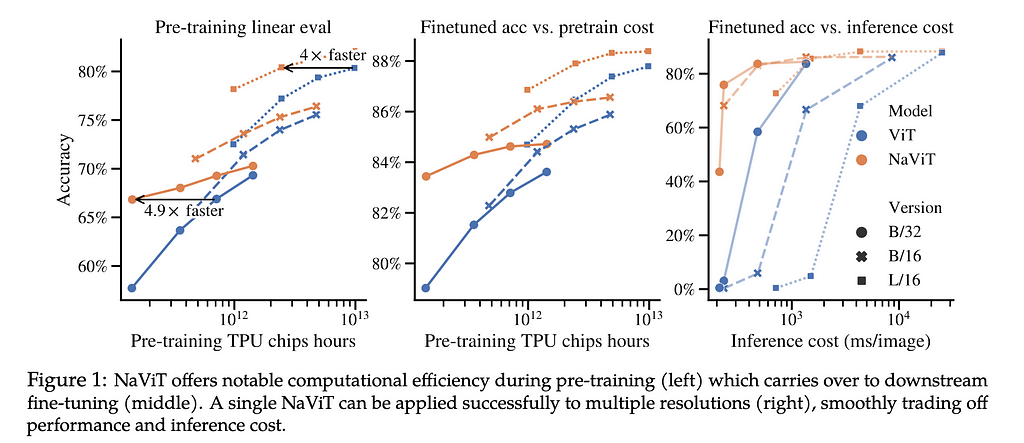
Variable “Patches” NaVit vs. Traditional Vision Transformers — Credit Dehghani et al., 2023
Just as the NaViT model demonstrates significant training efficiency and performance gains by packing multiple patches from different images into single sequences, Sora leverages spacetime patches to achieve similar efficiencies in video generation. This approach allows for more effective learning from a vast dataset, improving the model’s ability to generate high-fidelity videos yet lowering the compute required versus existing modeling architectures.
Bringing the Physical World to Life: Sora’s Mastery over 3D and Continuity
3D space and object permanence is one of the key standouts in the demo’s by Sora. Through its training on a wide range of video data without adapting or preprocessing the videos, Sora learns to model the physical world with impressive accuracy as its able to consume the training data in its original form.
It can generate digital worlds and videos where objects and characters move and interact in three-dimensional space convincingly, maintaining coherence even when they are occluded or leave the frame.
Looking Ahead: The Future Implications of Sora
Sora sets a new standard for what’s possible in generative models. This approach, much is likely to inspire the open-source community to experiment with and advance the capabilities in visual modalities, fueling a new generation of generative models that push the boundaries of creativity and realism.
The journey of Sora is just beginning, and as OpenAI put’s it “scaling video generation models is a promising path towards building general purpose simulators of the physical world”
Sora’s approach, blending the latest in AI research with practical applications, signals a bright future for generative models. As these technologies continue to evolve, they promise to redefine our interactions with digital content, making the creation of high-fidelity, dynamic videos more accessible and versatile.
Enjoyed This Story?
Vincent Koc is a highly accomplished, commercially-focused technologist and futurist with a wealth of experience focused in data-driven and digital disciplines.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.