Originally appeared here:
A Visual Guide to Mamba and State Space Models
Go Here to Read this Fast! A Visual Guide to Mamba and State Space Models


Language models (LMs) trained to predict the next word given input text are the key technology for many applications [1, 2]. In Gboard, LMs are used to improve users’ typing experience by supporting features like next word prediction (NWP), Smart Compose, smart completion and suggestion, slide to type, and proofread. Deploying models on users’ devices rather than enterprise servers has advantages like lower latency and better privacy for model usage. While training on-device models directly from user data effectively improves the utility performance for applications such as NWP and smart text selection, protecting the privacy of user data for model training is important.
 |
| Gboard features powered by on-device language models. |
In this blog we discuss how years of research advances now power the private training of Gboard LMs, since the proof-of-concept development of federated learning (FL) in 2017 and formal differential privacy (DP) guarantees in 2022. FL enables mobile phones to collaboratively learn a model while keeping all the training data on device, and DP provides a quantifiable measure of data anonymization. Formally, DP is often characterized by (ε, δ) with smaller values representing stronger guarantees. Machine learning (ML) models are considered to have reasonable DP guarantees for ε=10 and strong DP guarantees for ε=1 when δ is small.
As of today, all NWP neural network LMs in Gboard are trained with FL with formal DP guarantees, and all future launches of Gboard LMs trained on user data require DP. These 30+ Gboard on-device LMs are launched in 7+ languages and 15+ countries, and satisfy (ɛ, δ)-DP guarantees of small δ of 10-10 and ɛ between 0.994 and 13.69. To the best of our knowledge, this is the largest known deployment of user-level DP in production at Google or anywhere, and the first time a strong DP guarantee of ɛ < 1 is announced for models trained directly on user data.
In “Private Federated Learning in Gboard”, we discussed how different privacy principles are currently reflected in production models, including:
In recent years, FL has become the default method for training Gboard on-device LMs from user data. In 2020, a DP mechanism that clips and adds noise to model updates was used to prevent memorization for training the Spanish LM in Spain, which satisfies finite DP guarantees (Tier 3 described in “How to DP-fy ML“ guide). In 2022, with the help of the DP-Follow-The-Regularized-Leader (DP-FTRL) algorithm, the Spanish LM became the first production neural network trained directly on user data announced with a formal DP guarantee of (ε=8.9, δ=10-10)-DP (equivalent to the reported ρ=0.81 zero-Concentrated-Differential-Privacy), and therefore satisfies reasonable privacy guarantees (Tier 2).
In “Federated Learning of Gboard Language Models with Differential Privacy”, we announced that all the NWP neural network LMs in Gboard have DP guarantees, and all future launches of Gboard LMs trained on user data require DP guarantees. DP is enabled in FL by applying the following practices:
SecAgg can be additionally applied by adopting the advances in improving computation and communication for scales and sensitivity.
 |
| Federated learning with differential privacy and (SecAgg). |
The DP guarantees of launched Gboard NWP LMs are visualized in the barplot below. The x-axis shows LMs labeled by language-locale and trained on corresponding populations; the y-axis shows the ε value when δ is fixed to a small value of 10-10 for (ε, δ)-DP (lower is better). The utility of these models are either significantly better than previous non-neural models in production, or comparable with previous LMs without DP, measured based on user-interactions metrics during A/B testing. For example, by applying the best practices, the DP guarantee of the Spanish model in Spain is improved from ε=8.9 to ε=5.37. SecAgg is additionally used for training the Spanish model in Spain and English model in the US. More details of the DP guarantees are reported in the appendix following the guidelines outlined in “How to DP-fy ML”.
The ε~10 DP guarantees of many launched LMs are already considered reasonable for ML models in practice, while the journey of DP FL in Gboard continues for improving user typing experience while protecting data privacy. We are excited to announce that, for the first time, production LMs of Portuguese in Brazil and Spanish in Latin America are trained and launched with a DP guarantee of ε ≤ 1, which satisfies Tier 1 strong privacy guarantees. Specifically, the (ε=0.994, δ=10-10)-DP guarantee is achieved by running the advanced Matrix Factorization DP-FTRL (MF-DP-FTRL) algorithm, with 12,000+ devices participating in every training round of server model update larger than the common setting of 6500+ devices, and a carefully configured policy to restrict each client to at most participate twice in the total 2000 rounds of training in 14 days in the large Portuguese user population of Brazil. Using a similar setting, the es-US Spanish LM was trained in a large population combining multiple countries in Latin America to achieve (ε=0.994, δ=10-10)-DP. The ε ≤ 1 es-US model significantly improved the utility in many countries, and launched in Colombia, Ecuador, Guatemala, Mexico, and Venezuela. For the smaller population in Spain, the DP guarantee of es-ES LM is improved from ε=5.37 to ε=3.42 by only replacing DP-FTRL with MF-DP-FTRL without increasing the number of devices participating every round. More technical details are disclosed in the colab for privacy accounting.
 |
| DP guarantees for Gboard NWP LMs (the purple bar represents the first es-ES launch of ε=8.9; cyan bars represent privacy improvements for models trained with MF-DP-FTRL; tiers are from “How to DP-fy ML“ guide; en-US* and es-ES* are additionally trained with SecAgg). |
Our experience suggests that DP can be achieved in practice through system algorithm co-design on client participation, and that both privacy and utility can be strong when populations are large and a large number of devices’ contributions are aggregated. Privacy-utility-computation trade-offs can be improved by using public data, the new MF-DP-FTRL algorithm, and tightening accounting. With these techniques, a strong DP guarantee of ε ≤ 1 is possible but still challenging. Active research on empirical privacy auditing [1, 2] suggests that DP models are potentially more private than the worst-case DP guarantees imply. While we keep pushing the frontier of algorithms, which dimension of privacy-utility-computation should be prioritized?
We are actively working on all privacy aspects of ML, including extending DP-FTRL to distributed DP and improving auditability and verifiability. Trusted Execution Environment opens the opportunity for substantially increasing the model size with verifiable privacy. The recent breakthrough in large LMs (LLMs) motivates us to rethink the usage of public information in private training and more future interactions between LLMs, on-device LMs, and Gboard production.
The authors would like to thank Peter Kairouz, Brendan McMahan, and Daniel Ramage for their early feedback on the blog post itself, Shaofeng Li and Tom Small for helping with the animated figures, and the teams at Google that helped with algorithm design, infrastructure implementation, and production maintenance. The collaborators below directly contribute to the presented results:
Research and algorithm development: Galen Andrew, Stanislav Chiknavaryan, Christopher A. Choquette-Choo, Arun Ganesh, Peter Kairouz, Ryan McKenna, H. Brendan McMahan, Jesse Rosenstock, Timon Van Overveldt, Keith Rush, Shuang Song, Thomas Steinke, Abhradeep Guha Thakurta, Om Thakkar, and Yuanbo Zhang.
Infrastructure, production and leadership support: Mingqing Chen, Stefan Dierauf, Billy Dou, Hubert Eichner, Zachary Garrett, Jeremy Gillula, Jianpeng Hou, Hui Li, Xu Liu, Wenzhi Mao, Brett McLarnon, Mengchen Pei, Daniel Ramage, Swaroop Ramaswamy, Haicheng Sun, Andreas Terzis, Yun Wang, Shanshan Wu, Yu Xiao, and Shumin Zhai.
Originally appeared here:
Advances in private training for production on-device language models
Go Here to Read this Fast! Advances in private training for production on-device language models


Integrating the capabilities of various AI models unlocks a symphony of potential, from automating complex tasks that require multiple abilities like vision, speech, writing, and synthesis to enhancing decision-making processes. Yet, orchestrating these collaborations presents a significant challenge in managing the inner relations and dependencies. Traditional linear approaches often fall short, struggling to manage the intricacies of diverse models and dynamic dependencies.
By translating your machine learning workflow into a graph, you gain a visualisation of how each model interacts and contributes to the overall outcome that combines natural language processing, computer vision, and speech models. With the graph approach, the nodes represent models or tasks, and edges define dependencies between them. This graph-based mapping offers several advantages, identifying which models rely on the output of others and leveraging parallel processing for independent tasks. Additionally, we can execute the tasks using existing graph navigation strategies like breadth-first or depth-first according to the task priorities.
The road to harmonious AI models collaboration is not without hurdles. Imagine conducting an orchestra where each individual speaks different languages and instruments operate independently. This challenge mirrors the communication gaps when integrating diverse AI models, requiring a framework to manage the relations and which models can receive each input format.
The graph-based orchestration approach opens doors to exciting possibilities across various domains:
Collaborative tasks for drug discovery
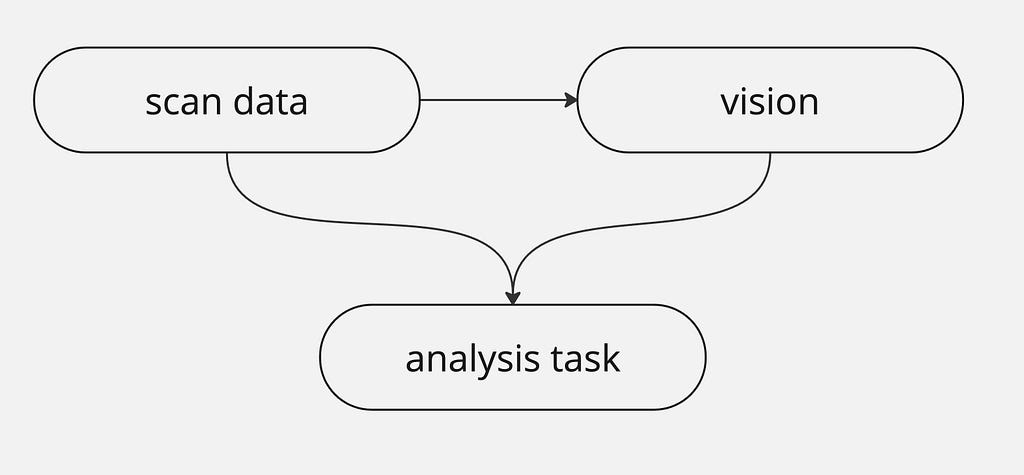
Researchers can accelerate the drug discovery process with a sequence of AI-powered assistants, each designed for a specific task, for example, using a three-step discovery mission. The first step involves a language model that scans vast scientific data to highlight potential protein targets strongly linked to specific diseases, followed by a vision model to explain complex diagrams or images, providing detailed insights into the structures of the identified proteins. This visual is crucial for understanding how potential drugs might interact with the protein. Finally, a third model integrates input from the language and vision models to predict how chemical compounds might affect the targeted proteins, offering the researchers valuable insights to lead the process efficiently.
Several challenges will emerge during the model integration to deliver the entire pipeline. Extracting relevant images from the scanned content and feeding them to the vision model isn’t as simple as it seems. An intermediate processor is needed between the text scan and vision tasks to filter the relevant images. Secondly, the analysis task itself should merge multiple inputs: the data scan output, the vision model’s explanation, and user-specified instructions. This requires a template to combine the information for the language model to process them. The following sections will describe how to utilise a python framework to handle the complex relations.
Creative Content Generation
The models collaboration can facilitate interactive content creation by integrating elements such as music composition, animation, and design models to generate animated scenes. For instance, in a graph-based collaboration approach, the first task can plan a scene like a director and pass the input for each music and image generation task. Finally, an animation model will use the output of the art and music models to generate a short video.
To optimise this process, we aim to achieve parallel execution of music and graphics generation as they are independent tasks. So there’s no need for music to wait for graphics completion. Additionally, we need to address the diverse input formats by the animation task. While some models like Stable Video Diffusion work with images only, the music can be combined using a post-processor.
These examples provide just a glimpse of the graph theory potential in model integration. The graph integration approach allows you to tailor multiple tasks to your specific needs and unlock innovative solutions.
Intelli is an open source python module to orchestrate AI workflows, by leveraging graph principles through three key components:
Using the flow component to manage the tasks relation as a graph provide several benefits when connecting multiple models, however for the case of one task only this might be overkill and direct call of the model will be sufficient.
Scaling: As your project grows in complexity, adding more models and tasks requires repetitive code updates to account for data format mismatches and complex dependency. The graph approach simplifies this by defining a new node representing the task, and the framework automatically resolves input/output differences to orchestrates data flow.
Dynamic Adaptation: With traditional approaches, changes for complex tasks will impact the entire workflow, requiring adjustments. When using the flow, it will handle adding, removing, or modifying connections automatically.
Explainability: The graph empowers deeper understanding of your AI workflow by visualising how the models interact, and optimise the tasks path navigation.
Note: the author participated in designing and developing the intelli framework. it is an open source project with Apache licence.
Getting Started
First, ensure you have python 3.7+, as intelli leverages the latest python asyncio features, and install:
pip install intelli
Agents: The Task Executors
Agents in Intelli are designed to interface with specific AI model. Each agent includes a unified input layer to access any model type and provides a dictionary allowing to pass custom parameters to the model, such as the maximum size, temperature and model version.
from intelli.flow.agents import Agent
# Define agents for various AI tasks
text_agent = Agent(
agent_type="text",
provider="openai",
mission="write social media posts",
model_params={"key": OPENAI_API_KEY, "model": "gpt-4"}
)
Tasks: The Building Blocks
Tasks represent individual units of work or operations to be performed by agents, and include the logic to handle the output of the previous task. Each task can be a simple operation like generating text or a more complex process, like analysing the sentiment of user feedback.
from intelli.flow.tasks import Task
from intelli.flow.input import TextTaskInput
# Define a task for text generation
task1 = Task(
TextTaskInput("Create a post about AI technologies"),
text_agent,
log=True
)
Processors: Tuned I/O
Processors add an extra layer of control by defining a custom pre-process for the task input and post-process for the output. The example below demonstrates creating a function to shorten the text output of the previous step before calling the image model.
class TextProcessor:
@staticmethod
def text_head(text, size=800):
retupytrn text[:size]
task2 = Task(
TextTaskInput("Generate image about the content"),
image_agent,
pre_process=TextProcessor.text_head,
log=True,
)
Flow: Specifying the dependencies
Flow translates your AI workflow into a Directed Acyclic Graph (DAG) and leverage the graph theory for dependency management. This enables you to easily visualise the task relations, and optimise the execution order of your tasks.
from intelli.flow.flow import Flow
flow = Flow(
tasks={
"title_task": title_task,
"content_task": content_task,
"keyword_task": keyword_task,
"theme_task": description_theme_task,
"image_task": image_task,
},
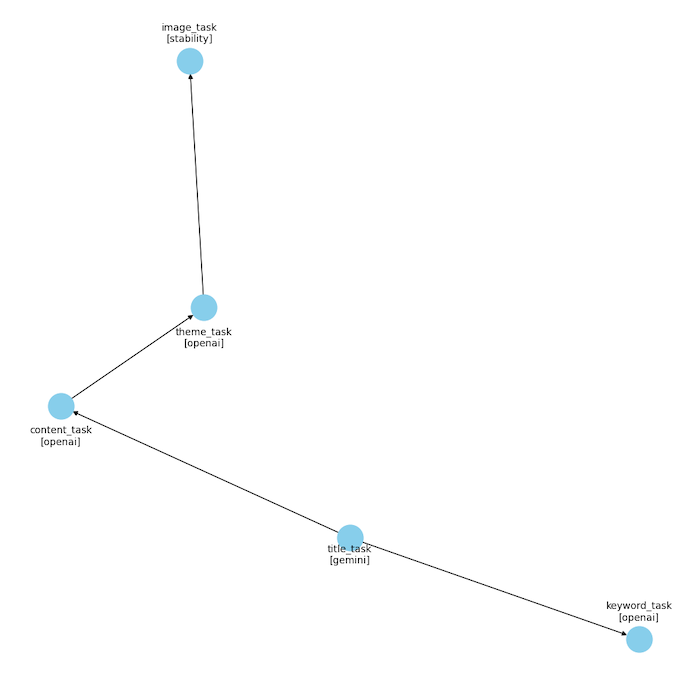
map_paths={
"title_task": ["keyword_task", "content_task"],
"content_task": ["theme_task"],
"theme_task": ["image_task"],
},
)
output = await flow.start()
The map_paths dictates the task dependencies, guiding Flow to orchestrate the execution order and ensuring each task receives the necessary output from its predecessors.
Here’s how Flow navigates the nodes:
To visualise your flow as a graph:
flow.generate_graph_img()
Using graph theory has transformed the traditional linear approaches to orchestrating AI models by providing a symphony of collaboration between diverse models.
Frameworks like Intelli translate your workflow into a visual representation, where tasks become nodes and dependencies are mapped as edges, creating an overview of your entire process to automate complex tasks.
This approach extends to diverse fields requiring collaborative AI models, including scientific research, business decision automation, and interactive content creation. However, effective scale requires further refinement in managing the data exchange between the models.
Graph Theory to Harmonize Model Integration was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Graph Theory to Harmonize Model Integration
Go Here to Read this Fast! Graph Theory to Harmonize Model Integration

Let’s look together under the hood with Python and PyTorch
Originally appeared here:
GPT Model: How Does it Work?
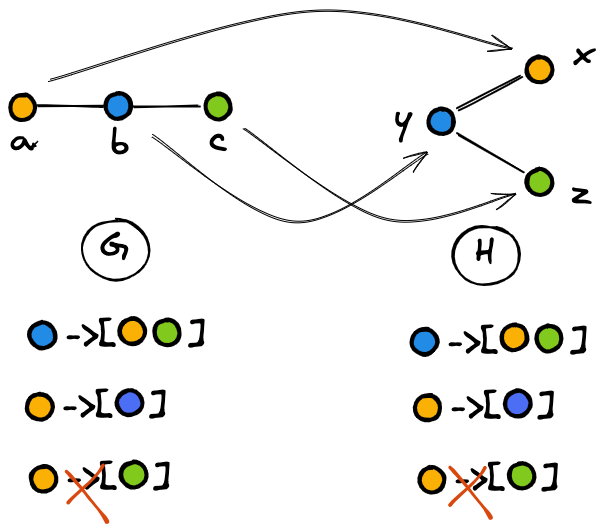
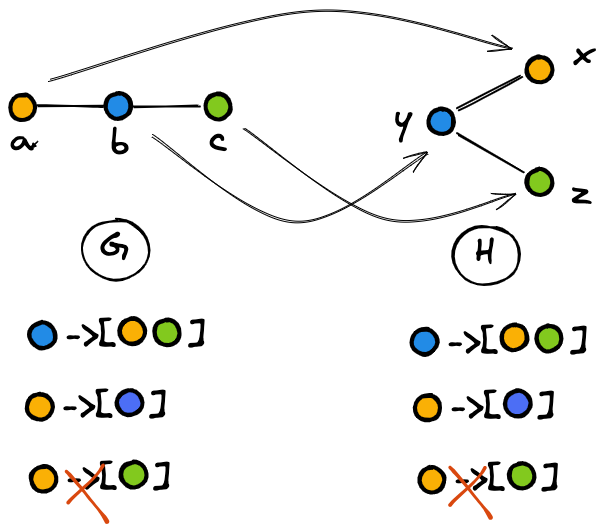
Connecting the dots for a theoretical analysis of Graph Neural Network models
Originally appeared here:
The Expressive Power of GNNs — Introduction and Foundations
Go Here to Read this Fast! The Expressive Power of GNNs — Introduction and Foundations


Converting a Colab notebook to two microservices with support for Milvus and NeMo Guardrails
Originally appeared here:
The Journey of RAG Development: From Notebook to Microservices
Go Here to Read this Fast! The Journey of RAG Development: From Notebook to Microservices
This article will show you different approaches you can take to create embeddings for your data
Originally appeared here:
How to Create Powerful Embeddings from Your Data to Feed into Your AI
Go Here to Read this Fast! How to Create Powerful Embeddings from Your Data to Feed into Your AI
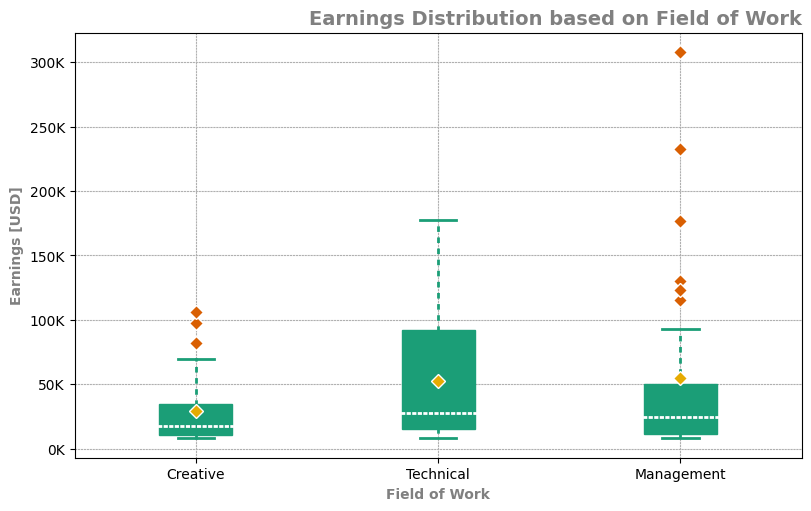
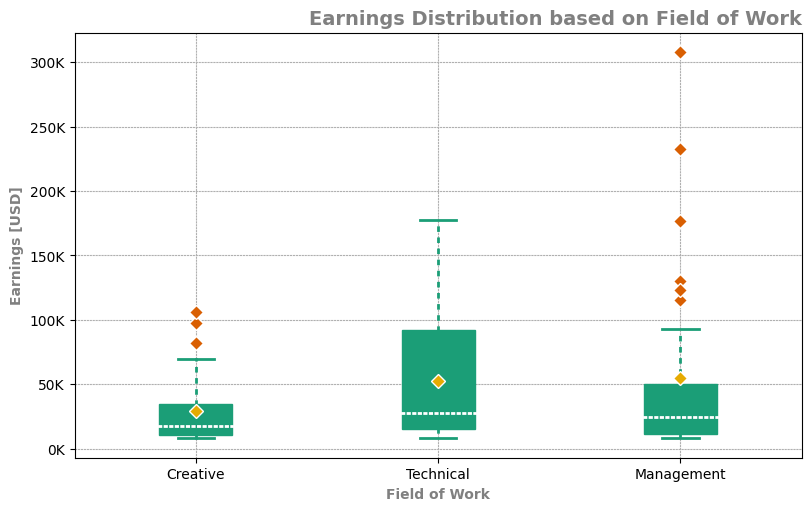
Consistently beautiful plots with less code and minimal effort
Originally appeared here:
Matplotlib: Make Your Plotting Life Easier with rcParams
Go Here to Read this Fast! Matplotlib: Make Your Plotting Life Easier with rcParams
Utilize large model inference containers powered by DJL Serving & Nvidia TensorRT
Originally appeared here:
Optimized Deployment of Mistral7B on Amazon SageMaker Real-Time Inference
Go Here to Read this Fast! Optimized Deployment of Mistral7B on Amazon SageMaker Real-Time Inference


Visualizing Satellite Images Captured over Volcanos and Wildfires in Various Spectral Bands
Originally appeared here:
Satellites Can See Invisible Lava Flows and Active Wildires, But How? (Python)