A thorough list of Technologies for best Performance/Watt
The most commonly used metric to define AI performance is TOPs (Tera Operations Per Second), which indicates compute capability but oversimplifies the complexity of AI systems. When it comes to real AI use case system design, many other factors should also be considered beyond TOPs, including memory/cache size and bandwidth, data types, energy efficiency, etc.
Moreover, each AI use case has its characteristics and requires a holistic examination of the whole use case pipeline. This examination delves into its impact on system components and explores optimization techniques to predict the best pipeline performance.
In this post, we pick one AI use case — an end-to-end real-time infinite zoom feature with a stable diffusion-v2 inpainting model and study how to build a corresponding AI system with the best performance/Watt. This can serve as a proposal, with both well-established technologies and new research ideas that can lead to potential architectural features.
Background on end-to-end video zoom
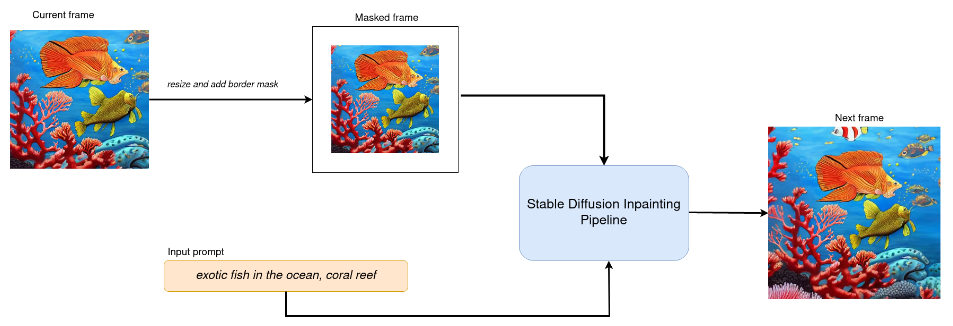
- As shown in the below diagram, to zoom out video frames (fish image), we resize and apply a border mask to the frames before feeding them into the stable diffusion inpainting pipeline. Alongside an input text prompt, this pipeline generates frames with new content to fill the border-masked region. This process is continuously applied to each frame to achieve the continuous zoom-out effect. To conserve compute power, we may sparsely sample video frames to avoid inpainting every frame(e.g., generating 1 frame every 5 frames) if it still delivers a satisfactory user experience.
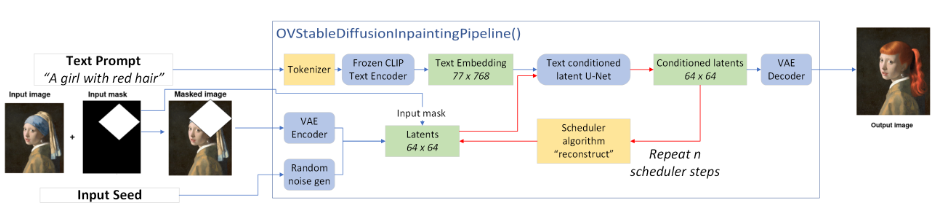
- Stable diffusion-v2 inpainting pipeline is pre-trained on stable diffusion-2 model, which is a text-to-image latent diffusion model created by stability AI and LAION. The blue box in below diagram displays each function block in the inpainting pipeline
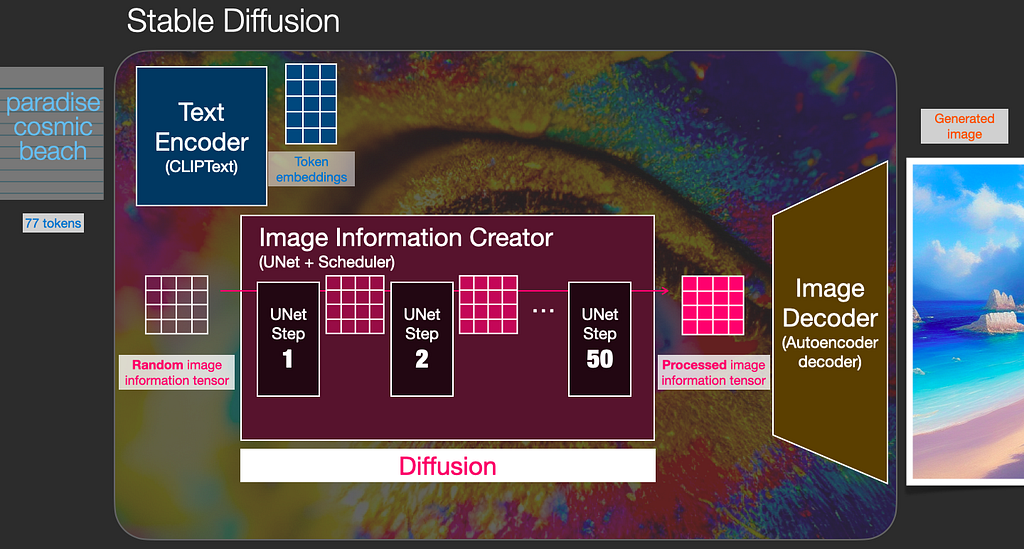
- Stable diffusion-2 model generates 768*768 resolution images, it is trained to denoise random noise iteratively (50 steps) to get a new image. The denoising process is implemented by Unet and scheduler which is a very slow process and requires lots of compute and memory.
There are 4 models used in the pipeline as below:
- VAE (image encoder). Convert image into low dimensional latent representation (64*64)
- CLIP (text encoder). Transformer architecture (77*768), 85MP
- UNet (diffusion process). Iteratively denoising processing via a schedular algorithm, 865M
- VAE (image decoder). Transforms the latent representation back into an image (512*512)
Most stable Diffusion operations (98% of the autoencoder and text encoder models and 84% of the U-Net) are convolutions. The bulk of the remaining U-Net operations (16%) are dense matrix multiplications due to the self-attention blocks. These models can be pretty big (varies with different hyperparameters) which requires lots of memory, for mobile devices with limited memory, it is essential to explore model compression techniques to reduce the model size, including quantization (2–4x mode size reduction and 2-3x speedup from FP16 to INT4), pruning, sparsity, etc.
Power efficiency optimization for AI features like end-to-end video zoom
For AI features like video zoom, power efficiency is one of the top factors for successful deployment on edge/mobile devices. These battery-operated edge devices store their energy in the battery, with the capacity of mW-H (milliWatt Hours, 1200WH means 1200 watts in one hour before it discharge, if an application is consuming 2w in one hour, then the battery can power the device for 600h). Power efficiency is computed as IPS/Watt where IPS is inferences per second (FPS/Watt for image-based applications, TOPS/Watt )
It’s critical to reduce power consumption to get long battery life for mobile devices, there are lots of factors contributing to high power usage, including large amounts of memory transactions due to big model size, heavy computation of matrix multiplications, etc., let’s take a look at how to optimize the use case for efficient power usage.
- Model optimization.
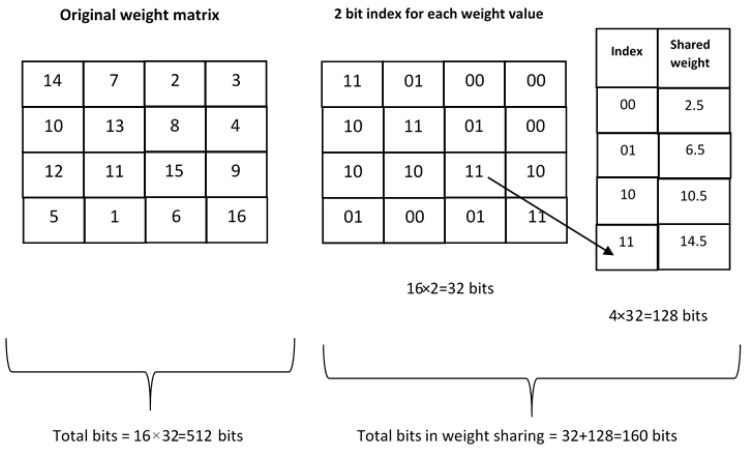
Beyond quantization, pruning, and sparsity, there is also weight sharing. There are lots of redundant weights in the network while only a small number of weights are useful, the number of weights can be reduced by letting multiple connections share the same weight shown as below. the original 4*4 weight matrix is reduced to 4 shared weights and a 2-bit matrix, total bits are reduced from 512 bits to 160 bits.
2. Memory optimization.
Memory is a critical component that consumes more power compared to matrix multiplications. For instance, the power consumption of a DRAM operation can be orders of magnitude more than that of a multiplication operation. In mobile devices, accommodating large models within local device memory is often challenging. This leads to numerous memory transactions between local device memory and DRAM, resulting in higher latency and increased energy consumption.
Optimizing off-chip memory access is crucial for enhancing energy efficiency. The article (Optimizing Off-Chip Memory Access for Deep Neural Network Accelerator [4]) introduced an adaptive scheduling algorithm designed to minimize DRAM access. This approach demonstrated a substantial energy consumption and latency reduction, ranging between 34% and 93%.
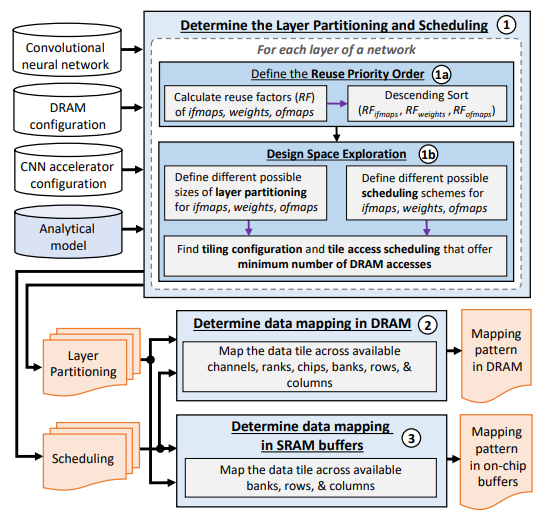
A new method (ROMANet [5]) is proposed to minimize memory access for power saving. The core idea is to optimize the right block size of CNN layer partition to match DRAM/SRAM resources and maximize data reuse, and also optimize the tile access scheduling to minimize the number of DRAM access. The data mapping to DRAM focuses on mapping a data tile to different columns in the same row to maximize row buffer hits. For larger data tiles, same bank in different chips can be utilized for chip-level parallelism. Furthermore, if the same row in all chips is filled, data are mapped in the different banks in the same chip for bank-level parallelism. For SRAM, a similar concept of bank-level parallelism can be applied. The proposed optimization flow can save energy by 12% for the AlexNet, by 36% for the VGG-16, and by 46% for the MobileNet. A high-level flow chart of the proposed method and schematic illustration of DRAM data mapping is shown below.

3. Dynamic power scaling.
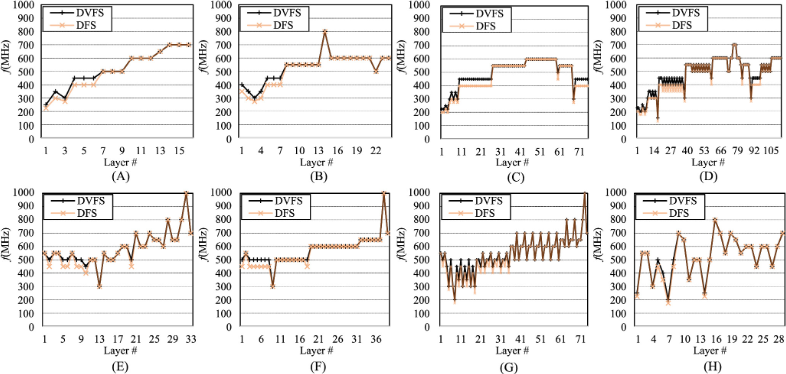
The power of a system can be calculated by P=C*F*V², where F is the operating frequency and V is the operating voltage. Techniques like DVFS (dynamic voltage frequency scaling) was developed to optimize runtime power. It scales voltage and frequency depending on workload capacity. In deep learning, layer-wise DVFS is not appropriate as voltage scaling has long latency. On the other hand, frequency scaling is fast enough to keep up with each layer. A layer-wise dynamic frequency scaling (DFS)[6] technique is proposed for NPU, with a power model to predict power consumption to determine the highest allowable frequency. It’s demonstrated that DFS improves latency by 33%, and saves energy by 14%
4. Dedicated low-power AI HW accelerator architecture. To accelerate deep learning inference, specialized AI accelerators have shown superior power efficiency, achieving similar performance with reduced power consumption. For instance, Google’s TPU is tailored for accelerating matrix multiplication by reusing input data multiple times for computations, unlike CPUs that fetch data for each computation. This approach conserves power and diminishes data transfer latency.
At the end
AI inferencing is only a part of the End-to-end use case flow, there are other sub-domains to be considered while optimizing system power and performance, including imaging, codec, memory, display, graphics, etc. Breakdown of the process and examine the impact on each sub-domain is essential. for example, to look at power consumption when we run infinite zoom, we need also to look into the power of camera capturing and video processing system, display, memory, etc. make sure the power budget for each component is optimized. There are numerous optimization methods and we need to prioritize based on the use case and product
Reference
[1] OpenVINO tutorial: Infinite Zoom Stable Diffusion v2 and OpenVINO™
[2] Jay Alammar, The Illustrated Stable Diffusion
[3] Chellammal Surianarayanan et al., A Survey on Optimization Techniques for Edge Artificial Intelligence (AI), Jan 2023
[4] Yong Zheng et al., Optimizing Off-Chip Memory Access for Deep Neural Network Accelerator, IEEE Transactions on Circuits and Systems II: Express Briefs, Volume: 69, Issue: 4, April 2022
[5] Rachmad Vidya Wicaksana Putra et al., ROMANet: Fine grained reuse-driven off-chip memory access management and data organization for deep neural network accelerators, arxiv, 2020
[6] Jaehoon Chung et al., A layer-wise frequency scaling for a neural processing unit, ETRI Journal, Volume 44, Issue 5, Sept 2022
End to End AI Use Case-Driven System Design was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
End to End AI Use Case-Driven System Design
Go Here to Read this Fast! End to End AI Use Case-Driven System Design