If you have been a data scientist for a while, sooner or later you’ll notice that your day-to-day has shifted from a VSCode-loving, research paper-reading, git-version-committing data scientist to a collaboration-driving, project-scoping, stakeholder-managing, and strategy-setting individual.
This shift will be gradual and almost unnoticeable but one that will require you to put on different hats to ensure data initiatives are on track and impactful. It is at this point that you will start to notice the need for honing some business skills, in addition to your usual data science skills. This will also be a good indication that you are ready to aim for senior tech leadership roles such as Principal, Lead, or Staff DS.
Here are my top three picks that have been quite useful as I took on a data science leadership role in an FTSE 100 company, but ones that would be equally useful in a scrappy startup environment.
1. Get fluent in finance
Knowing how a business makes money is crucial regardless of the size of the company and your role in it. Unfortunately, a lot of data science work often happens in silos where the problem statement or hypothesis, or analysis workflow is top-down and may lack direct alignment with the company’s financial goals.
As you take on a more senior leadership role with the team, it is essential that you speak the language of business. Having a broad understanding of terms like CapEx vs. OpEx, EBITDA margin, amortization, blended CAC, churn cohorts, fair share index, etc. is helpful when you are communicating the results to the higher-ups. This way, you can tailor your insights to highlight how data science-driven initiatives will impact these areas, making your analysis more relevant and convincing to financial stakeholders.
Did you know Apple spent $110 billion on stock buybacks in 2024. Why? Fewer shares in the market = higher earnings per share (EPS), which boosts the stock price.
Knowing your numbers can benefit both you and the company: Understanding your numbers means that you know what’s working and not working for the business, identify areas for growth, and make sound financial choices based on data. For instance, instead of just showing improved model accuracy, one could demonstrate exactly how the predictions would impact the bottom line.
Similarly, by showcasing how your work directly contributes to the company’s financial success, you can even negotiate better pay for yourself!
But it goes beyond just communication. This knowledge opens doors to opportunities many data scientists miss. For instance, there are schemes that allow you to apply for tax rebates on your company’s CapEx that are associated with R&D activity (like patent-related costs, specialized software licenses, etc).
I have seen teams who were able to secure funding by understanding these financial mechanisms and positioning their ML infrastructure investments as R&D initiatives.
Likewise, there are certain government grants you or your company may be eligible for, depending on the space you are in. For instance, USDA (United States Department of Agriculture) offers grants and funding for projects in agri-tech innovation.
How to build this skill?
Read books on finance to quickly grasp key terms and learn from case studies of other companies in the same niche as you (worst case scenario — you either fail fast or best case scenario — you learn about common pitfalls to avoid). If you don’t have the time to read books end-to-end, at the very least, get familiarized with their key ideas. I use AcceleratEd to get book summaries but there are other options that you choose from that I have discussed in this article. P.S. Here is my book collection for upskilling in finance, including books like The Alchemy of Finance, Value Investing, and One Up On Wall Street.
Consume content from YT channels like TheFinanceStoryteller and Investopedia who break down complex finance topics into bitesized chunks.
Keep an eye out for bursaries and grants applicable to your business.
Shadow your COOs, Operations Manager, or, in some cases, even your POs (mine has been god-sent in helping me understand value calculations in the healthcare sector and improving my corporate finance understanding).
2. Keep Up With The Curve
Love it or hate it, but you can’t deny the fact that the AI/ML/Generative AI field is moving at an unprecedented rate. I have often read news articles describing technology X replaced technology Y and I am left thinking — what is technology Y!
On average, about 8000 new research papers (in Computer Science category) are published on arXiv every month! [Source]
To provide any sort of thought leadership in this new role, your industry, and technological awareness need to operate at two levels — local and global.
Keeping up with the localcurve involves staying updated with the latest tools, techniques, and trends. In practical terms, this would translate as knowing (a) which models sit on top of the leaderboard for your usecase (be it forecasting, generative AI, or computer vision), (b) any new groundbreaking frameworks that would be game-changers for your field (for instance, Baidu recently unveiled iRAG technology that addresses the issue of hallucinations in image generation), and (c) advancements in DevOps/LLMOps/MLOps that could streamline workflows and improve efficiency.
Keeping up with the globalcurve means acknowledging the bigger picture around the tech field— understanding how innovations are shaping industries and the broader ethical and societal impacts of these technologies — especially as governments around the world are taking steps to regulate the tech domain.
In practical terms, this could mean keeping up-to-date with regulations in the field in which you operate (legal, healthcare, FMCG, etc) and checking compliance with relevant guidelines.
For instance, the European Union’s AI Act 2024, which came into effect recently, has detailed guidelines on the dos and don’ts surrounding the development, deployment, and use of AI, including guidelines such as mandatory watermark to content generated by AI.
Similarly, keeping track of the big tech players like NVIDIA, OpenAI, Anthropic, etc. is even more important to anticipate short and long-term technological shifts for your business. A short-term example would be the recent news of the OpenAI-Microsoft partnership turning sour, which could impact any ongoing projects if you rely on Microsoft’s Azure OpenAI as your LLM provider.
A long-term example is the recent investment in nuclear power projects by companies like Microsoft, Amazon, and Google, to meet the growing demand for high energy consumption by large language models (LLMs), often seen as a bottleneck for AI advancements. A stable, predictable, and carbon-free energy source could mean long-term cost savings for your AI-driven business.
How to build this skill?
Get a daily dose of tech news via apps (like Curio) or websites like HackerNews.
Subscribe to a couple of weekly AI newsletters, or as many as you can realistically keep up with given your workload. I am highly self-aware and my only go-to is The Batch.
3. Be a communication ninja
For a lucky few who step up from data scientist into this new leadership role, soft communication skills — useful for managing teams, data storytelling, and cross-team collaboration — come naturally to them. For the rest, there’s hope! With practice, achieving any skill is possible.
And, before you ask why this is crucial — Imagine not knowing how to pitch your excellent data product to a group of non-technical VCs and investors. Or, an effective way to communicate insights from your week-long EDA process. Or, the right way to motivate your brilliant but overwhelmed data scientists during a critical product launch.
Stepping into a leadership position means being firm but polite, clearly explaining what the team needs to do, and being crystal clear with stakeholders on technical limitations between their ask and what’s within the realm of possibilities — keeping in mind constraints like cost, latency, etc.
It means staying cool when a stakeholder says ‘ChatGPT can do this in seconds’ or when someone demands ‘a 100% accurate model.’
To deliver this effectively, you need to learn the different dynamics at play. You need to be more diplomatic and rational rather than reacting impulsively when someone suggests ‘trying these 20 ideas that came up during the meeting’ or using inappropriate verbal and non-verbal cues when you can clearly detect scope creep.
How to build this skill?
Again, books can be your best friend here. Here is my book collection for managing team dynamics, including books like Emotional Intelligence 2.0, The Five Dysfunctions of a Team, and Crucial Conversations: Tools for Talking When Stakes Are High, Made to Stick. I recently wrote about how these books have been insanely useful for saving my sanity as a tech lead.
(Books can only take you so far so step up to) Lead stakeholder-facing meetings at work. Nothing beats a hands-on experience.
Volunteer for roundtable discussions and fireside chats at conferences and seminars. These formats are more relaxed and take the pressure off compared to when you’re the only one presenting and others are passively listening. Back up your discussion points with facts and shreds of evidence from books, recent news, and reputed research papers to ensure your argument holds weight.
Final Thoughts
It might be scary to transition from a core data scientist role to a thought leader who is looked up to define, foresee, and shape the strategic direction of the data team.
But you need to remember that, as a person with both tech and business skills in your arsenal, no one is better positioned than you to take the reins.
You understand the technology behind the black box models, which makes finding feasible tech solutions easier, and you also have the business acumen to best align these solutions with business objectives.
I hope this article was useful and should an opportunity present itself, you’ll grab it with both hands. Watching your company/team/BU (business unit) succeed and knowing you’ve played a part in their growth can be a truly rewarding experience.
Leveraging GPT-3.5 and unstructured APIs for translations
This blog post details how I utilised GPT to translate the personal memoir of a family friend, making it accessible to a broader audience. Specifically, I employed GPT-3.5 for translation and Unstructured’s APIs for efficient content extraction and formatting.
The memoir, a heartfelt account by my family friend Carmen Rosa, chronicles her upbringing in Bolivia and her romantic journey in Paris with an Iranian man during the vibrant 1970s. Originally written in Spanish, we aimed to preserve the essence of her narrative while expanding its reach to English-speaking readers through the application of LLM technologies.
Cover image of “Un Destino Sorprendente”, used with permission of author Carmen Rosa Wichtendahl.
I followed the next steps for the translation of the book:
Import Book Data: I imported the book from a Docx document using the Unstructured API and divided it into chapters and paragraphs.
Translation Technique: I translated each chapter using GPT-3.5. For each paragraph, I provided the latest three translated sentences (if available) from the same chapter. This approach served two purposes:
Style Consistency: Maintaining a consistent style throughout the translation by providing context from previous translations.
Token Limit:Limiting the number of tokens processed at once to avoid exceeding the model’s context limit.
3. Exporting translation as Docx: I used Unstructured’s API once again to save the translated content in Docx format.
Technical implementation
1. Libraries
We’ ll start with the installation and import of the necessary libraries.
The code allows us to import the book in Docx format and divide it into individual paragraphs.
elements = partition_docx( filename="/content/libro.docx", paragraph_grouper=group_broken_paragraphs )
The code below returns the paragraph in the 10th index of elements.
print(elements[10])
# Returns: Destino sorprendente, es el título que la autora le puso ...
4. Group book into titles and chapters
The next step involves creating a list of chapters. Each chapter will be represented as a dictionary containing a title and a list of paragraphs. This structure simplifies the process of translating each chapter and paragraph individually. Here’s an example of this format:
[ {"title": title 1, "content": [paragraph 1, paragraph 2, ..., paragraph n]}, {"title": title 2, "content": [paragraph 1, paragraph 2, ..., paragraph n]}, ... {"title": title n, "content": [paragraph 1, paragraph 2, ..., paragraph n]}, ]
To achieve this, we’ll create a function called group_by_chapter. Here are the key steps involved:
Extract Relevant Information: We can get each narrative text and title by calling element.category. Those are the only categories we’re interested in translating at this point.
Identify Narrative Titles: We recognise that some titles should be part of the narrative text. To account for this, we assume that italicised titles belong to the narrative paragraph.
text_style = element.metadata.emphasized_text_tags # checks if it is 'b' or 'i' and returns list unique_text_style = list(set(text_style)) if text_style is not None else None
# we consider an element a title if it is a title category and the style is bold is_title = (element.category == "Title") & (unique_text_style == ['b'])
# we consider an element a narrative content if it is a narrative text category or # if it is a title category, but it is italic or italic and bold is_narrative = (element.category == "NarrativeText") | ( ((element.category == "Title") & (unique_text_style is None)) | ((element.category == "Title") & (unique_text_style == ['i'])) | ((element.category == "Title") & (unique_text_style == ['b', 'i'])) )
# for new titles if is_title: print(f"Adding title {element.text}")
# Add previous chapter when a new one comes in, unless current title is None if current_title is not None: chapters.append(current_chapter)
else: print(f'### No need to convert. Element type: {element.category}')
return chapters
In the example below, we can see an example:
book_chapters[2]
# Returns {'title': 'Proemio', 'content': [ 'La autobiografía es considerada ...', 'Dentro de las artes literarias, ...', 'Se encuentra más próxima a los, ...', ] }
5. Book translation
To translate the book, we follow these steps:
Translate Chapter Titles: We translate the title of each chapter.
Translate Paragraphs: We translate each paragraph, providing the model with the latest three translated sentences as context.
Save Translations: We save both the translated titles and content.
The function below automates this process.
def translate_book(book_chapters: List[Dict]) -> Dict: translated_book = [] for chapter in book_chapters: print(f"Translating following chapter: {chapter['title']}.") translated_title = translate_title(chapter['title']) translated_chapter_content = translate_chapter(chapter['content']) translated_book.append({ "title": translated_title, "content": translated_chapter_content }) return translated_book
For the title, we ask GPT a simple translation as follows:
def translate_title(title: str) -> str: response = client.chat.completions.create( model="gpt-3.5-turbo", messages= [{ "role": "system", "content": f"Translate the following book title into English:n{title}" }] ) return response.choices[0].message.content
To translate a single chapter, we provide the model with the corresponding paragraphs. We instruct the model as follows:
Identify the role: We inform the model that it is a helpful translator for a book.
Provide context: We share the latest three translated sentences from the chapter.
Request translation: We ask the model to translate the next paragraph.
During this process, the function combines all translated paragraphs into a single string.
# Function to translate a chapter using OpenAI API def translate_chapter(chapter_paragraphs: List[str]) -> str: translated_content = ""
for i, paragraph in enumerate(chapter_paragraphs):
print(f"Translating paragraph {i + 1} out of {len(chapter_paragraphs)}")
# Builds the message dynamically based on whether there is previous translated content messages = [{ "role": "system", "content": "You are a helpful translator for a book." }]
if translated_content: latest_content = get_last_three_sentences(translated_content) messages.append( { "role": "system", "content": f"This is the latest text from the book that you've translated from Spanish into English:n{latest_content}" } )
# Adds the user message for the current paragraph messages.append( { "role": "user", "content": f"Translate the following text from the book into English:n{paragraph}" } )
# Calls the API response = client.chat.completions.create( model="gpt-3.5-turbo", messages=messages )
# Extracts the translated content and appends it paragraph_translation = response.choices[0].message.content translated_content += paragraph_translation + 'nn'
return translated_content
Finally, below we can see the supporting function to get the latest three sentences.
def get_last_three_sentences(paragraph: str) -> str: # Use regex to split the text into sentences sentences = re.split(r'(?<!w.w.)(?<![A-Z][a-z].)(?<=.|?)s', paragraph)
# Get the last three sentences (or fewer if the paragraph has less than 3 sentences) last_three = sentences[-3:]
# Join the sentences into a single string return ' '.join(last_three)
6. Book export
Finally, we pass the dictionary of chapters to a function that adds each title as a heading and each content as a paragraph. After each paragraph, a page break is added to separate the chapters. The resulting document is then saved locally as a Docx file.
for chapter in chapters: # Add chapter title as Heading 1 doc.add_heading(chapter['title'], level=1)
# Add chapter content as normal text doc.add_paragraph(chapter['content'])
# Add a page break after each chapter doc.add_page_break()
# Save the document doc.save(output_filename)
Limitations
While using GPT and APIs for translation is fast and efficient, there are key limitations compared to human translation:
Pronoun and Reference Errors: GPT did misinterpret pronouns or references in few cases, potentially attributing actions or statements to the wrong person in the narrative. A human translator can better resolve such ambiguities.
Cultural Context: GPT missed subtle cultural references and idioms that a human translator could interpret more accurately. In this case, several slang terms unique to Santa Cruz, Bolivia, were retained in the original language without additional context or explanation.
Combining AI with human review can balance speed and quality, ensuring translations are both accurate and authentic.
Conclusion
This project demonstrates an approach to translating a book using a combination of GPT-3 and Unstructured APIs. By automating the translation process, we significantly reduced the manual effort required. While the initial translation output may require some minor human revisions to refine the nuances and ensure the highest quality, this approach serves as a strong foundation for efficient and effective book translation
If you have any feedback or suggestions on how to improve this process or the quality of the translations, please feel free to share them in the comments below.
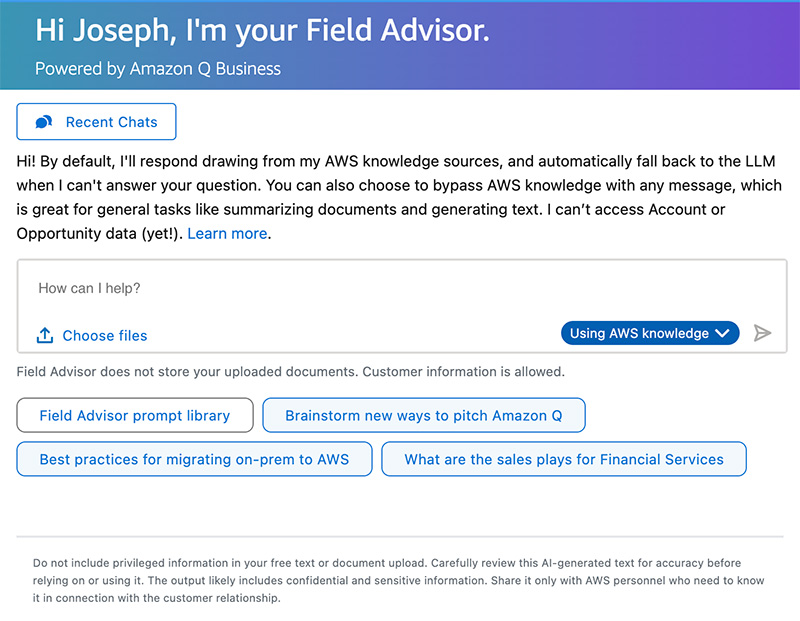
In April 2024, we launched our AI sales assistant, which we call Field Advisor, making it available to AWS employees in the Sales, Marketing, and Global Services organization, powered by Amazon Q Business. Since that time, thousands of active users have asked hundreds of thousands of questions through Field Advisor, which we have embedded in our customer relationship management (CRM) system, as well as through a Slack application.
In this post, we walk you through configuring and integrating Amazon Q for Business with Aurora PostgreSQL-Compatible to enable your database administrators, data analysts, application developers, leadership, and other teams to quickly get accurate answers to their questions related to the content stored in Aurora PostgreSQL databases.
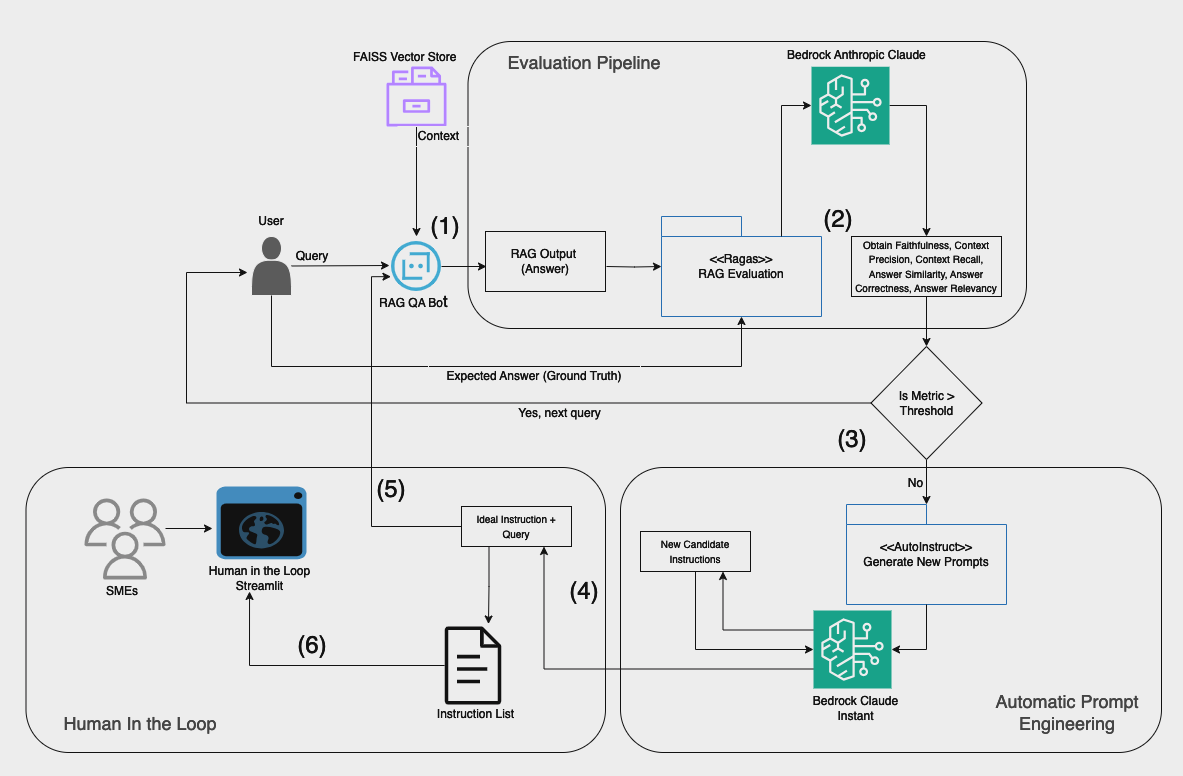
In this post, we illustrate the importance of generative AI in the collaboration between Tealium and the AWS Generative AI Innovation Center (GenAIIC) team by automating the following: 1/ Evaluating the retriever and the generated answer of a RAG system based on the Ragas Repository powered by Amazon Bedrock, 2/ Generating improved instructions for each question-and-answer pair using an automatic prompt engineering technique based on the Auto-Instruct Repository. An instruction refers to a general direction or command given to the model to guide generation of a response. These instructions were generated using Anthropic’s Claude on Amazon Bedrock, and 4/ Providing a UI for a human-based feedback mechanism that complements an evaluation system powered by Amazon Bedrock.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.