Increasing growth and data complexities have made data deduplication even more relevant
Data duplication is still a problem for many organisations. Although data processing and storage systems have developed rapidly along with technological advances, the complexity of the data produced is also increasing. Moreover, with the proliferation of Big Data and the utilisation of cloud-based applications, today’s organisations must increasingly deal with fragmented data sources.
Ignoring the phenomenon of the large amount of duplicated data will have a negative impact on the organisation. Such as:
Disruption of the decision-making process. Unclean data can bias metrics and not reflect the actual conditions. For example: if there is one customer that is actually the same, but is represented as 2 or 3 customers data in CRM, this can be a distortion when projecting revenue.
Swelling storage costs because every bit of data basically takes up storage space.
Disruption of customer experience. For example: if the system has to provide notifications or send emails to customers, it is very likely that customers whose data is duplicate will receive more than one notification.
Making the AI training process less than optimal. When an organisation starts developing an AI solution, one of the requirements is to conduct training with clean data. If there is still a lot of duplicates, the data cannot be said to be clean and when forced to be used in AI training, it will potentially produce biased AI.
Given the crucial impact caused when an organisation does not attempt to reduce or eliminate data duplication, the process of data deduplication becomes increasingly relevant. It is also critical to ensure data quality. The growing sophistication and complexity of the system must be accompanied by the evolution of adequate deduplication techniques.
On this occasion, we will examine the 3 latest deduplication methods, which can be a reference for practitioners when planning the deduplication process.
Global Deduplication
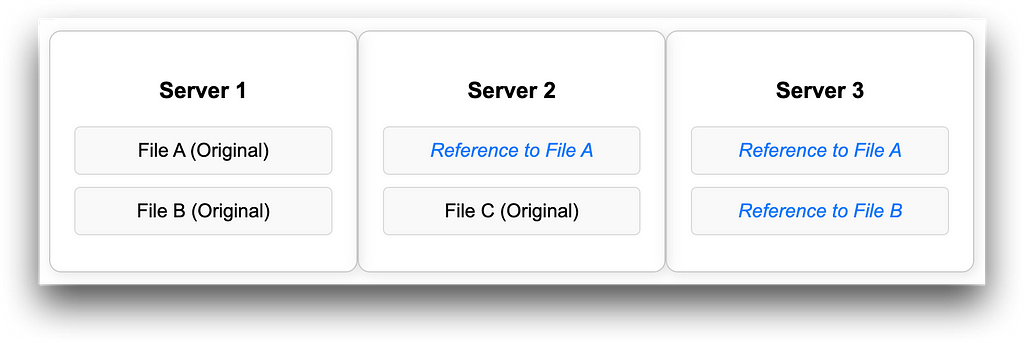
It is the process of eliminating duplicate data across multiple storage locations. It is now common for organisations to store their data across multiple servers, data centers, or the cloud. Global deduplication ensures that only one copy of the data is stored.
This method works by creating a global index, which is a list of all existing data, in the form of a unique code (hash) using an algorithm such as SHA256 that represents each piece of data. When a new file is uploaded to a server (for example Server 1), the system will store a unique code for that file.
On another day when a user uploads a file to Server 2, the system will compare the unique code of the new file with the global index. If the new file is found to have the same unique code/hash as the global index, then instead of continuing to store the same file in two places, the system will replace the duplicate file stored on Server 2 with a reference/pointer that points to a copy of the file that already exists on Server 1.
With this method, storage space can clearly be saved. And if combined with Data Virtualisation technique then when the file is needed the system will take it from the original location, but all users will still feel the data is on their respective servers.
The illustration below shows how Global Deduplication works where each server only stores one copy of the original data and duplicates on other servers are replaced by references to the original file.
source: Author
It should be noted that the Global Deduplication method does not work in real-time, but post-process. Which means the method can only be applied when the file has entered storage.
Inline Deduplication
Unlike Global Deduplication, this method works in real-time right when data is being written to the storage system. With the Inline Deduplication technique, duplicate data is immediately replaced with references without going through the physical storage process.
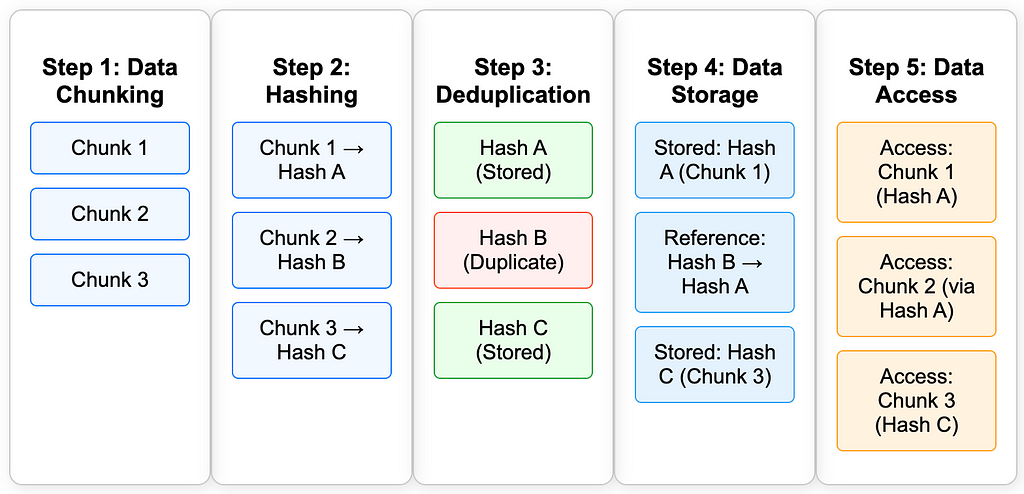
The process begins when data is about to enter the system or a file is being uploaded, the system will immediately divide the file into several small pieces or chunks. Using an algorithm such as SHA-256, each chunk will then be given a hash value as a unique code. Example:
Chunk1 -> hashA
Chunk2-> hashB
Chunk3 -> hashC
The system will then check whether any of the chunks have hashes already in the storage index. If one of the chunks is found whose unique code is already in the storage hash, the system will not re-save the physical data from the chunk, but will only store a reference to the original chunk location that was previously stored.
While each unique chunk will be stored physically.
Later, when a user wants to access the file, the system will rearrange the data from the existing chunks based on the reference, so that the complete file can be used by the user.
Inline Deduplication is widely used by cloud service providers such as Amazon S3 or Google Drive. This method is very useful for optimising storage capacity.
The simple illustration below illustrates the Inline Deduplication process, from data chunking to how data is accessed.
Source: Author
ML-Enhanced Deduplication
Machine learning-powered deduplication uses AI to detect and remove duplicate data, even if it is not completely identical.
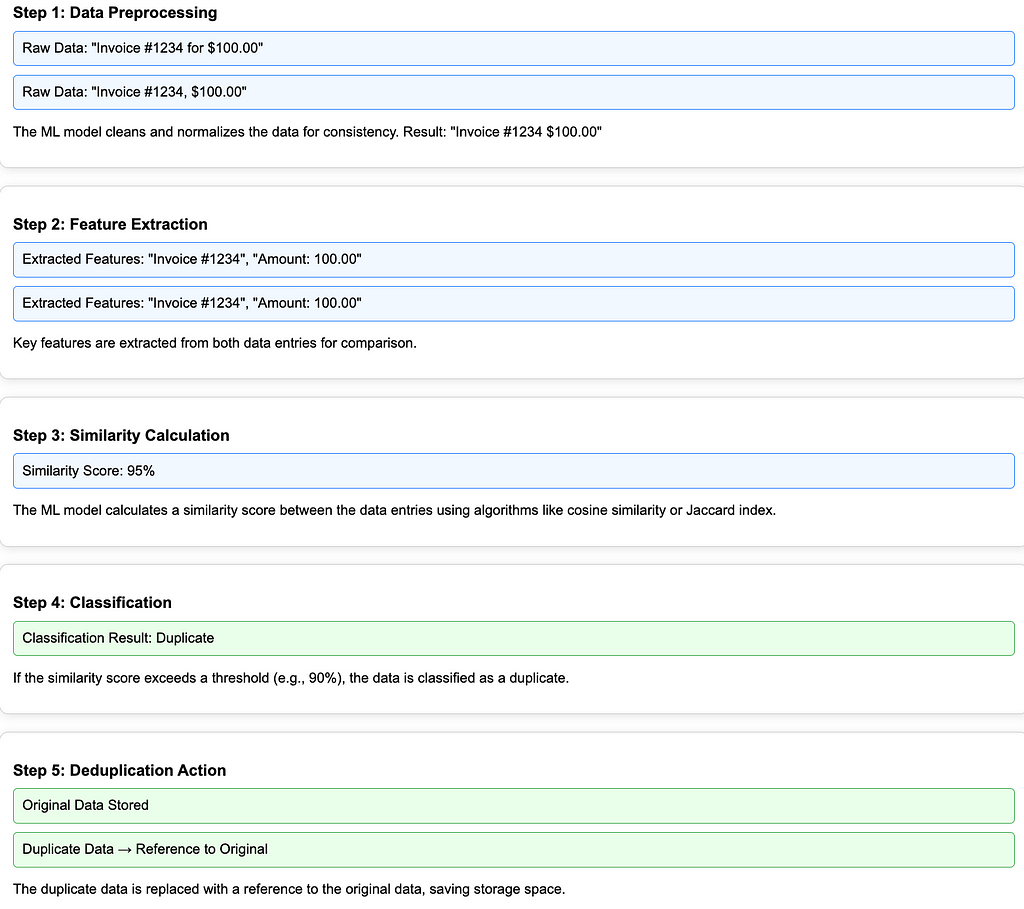
The process begins when incoming data, such as files/documents/records, are sent to the deduplication system for analysis. For example, the system receives two scanned documents that at first glance look similar but actually have subtle differences in layout or text format.
The system will then intelligently extract important features, usually in the form of metadata or visual patterns. These important features will then be analysed and compared for similarity. The similarity of a feature will be represented as a value/score. And each system/organisation can define whether data is a duplicate or not based on its similarity score. For example: only data with a similarity score above 90% can be said to be potentially duplicate.
Based on the similarity score, the system can judge whether the data is a duplicate. If stated that it is a duplicate, then steps can be taken like other duplication methods, where for duplicate data only the reference is stored.
What’s interesting about ML-enhanced Deduplication is that it allows human involvement to validate the classification that has been done by the system. So that the system can continue to get smarter based on the inputs that have been learned (feedback loop).
However, it should be noted that unlike Inline Deduplication, ML-enhanced deduplication is not suitable for use in real-time. This is due to the latency factor, where ML takes time to extract features and process data. In addition, if forced to be real-time, this method requires more intensive computing resources.
Although not real-time, the benefits it brings are still optimal, especially with its ability to handle unstructured or semi-structured data.
The following is an illustration of the steps of ML-enhanced Deduplication along with examples.
Source: Author
From the explanation above, it is clear that organisations have many choices of methods according to their capabilities and needs. So there is no reason to not doing deduplication, especially if the data stored or handled by the organisation is critical data that concerns the lives of many people.
Organisations should be able to use several consideration items to choose the most appropriate method. Aspects such as the purpose of deduplication, the type and volume of data, and the infrastructure capabilities of the organisation can be used for initial assessment.
It should be noted that there is flexible options that organisations can choose, such as a hybrid method of combining Inline Deduplication with the ML-enhanced counterpart. In that way, a wider benefit can be potentially obtained.
Data management regulations such as GDPR and HIPAA regulate sensitive information. Hence, organisations need to ensure that deduplication does not violate privacy policies. For example: an organisation could combine customer data from two different systems after detecting duplicates, without obtaining user consent. Organisations have to ensure this kind of thing is not happening.
Whatever the challenge is, deduplication must still be done, and organisations need to make efforts from the start. Do not wait until the data gets bigger and deduplication efforts become more expensive and complex.
A novel approach for lightweight safety classification using pruned language models
Leveraging the hidden state from an intermediate Transformer layer for efficient and robust content safety and prompt injection classification
Image by author and GPT-4o meant to represent the robust language understanding provided by Large Language Models.
Introduction
As the adoption of Language Models (LMs) grows, it’s more and more important to detect inappropriate content in both the user’s input and the generated outputs of the language model. With each new model release from any major model provider, one of the first things people try to do is find ways to “jailbreak” or otherwise manipulate the model to respond in ways it shouldn’t. A quick search on Google or X reveals many examples of how people have found ways around model alignment tuning to get models to respond to inappropriate requests. Furthermore, many companies have released Generative AI based chatbots publicly for tasks like customer service, which often end up suffering from prompt injection attacks and responding to tasks both inappropriate and far beyond their intended use. Detecting and classifying these instances is extremely important for businesses so that they don’t end up with a system that can be easily manipulated by their users, especially if they deploy their chat systems publicly.
My team, Mason Sawtell, Sandi Besen, Jim Brown, and I recently published our paper Lightweight Safety Classification using Pruned Language Modelsas an ArXiv preprint. Our work introduces a new approach, Layer Enhanced Classification (LEC), and demonstrates that using LEC it is possible to effectively classify both content safety violations and prompt injection attacks by using the hidden state(s) from the intermediate transformer layer(s) of a Language Model to train a penalized logistic regression classifier with very few trainable parameters (769 on the low end) and a small number of training examples, often fewer than 100. This approach combines the computational efficiency of a simple classification model with the robust language understanding of a Language Model.
All of the models trained using our approach, LEC, outperform special-purpose models designed for each task as well as GPT-4o. We find that there are optimal intermediate transformer layers that produce the necessary features for both content safety and prompt injection classification tasks. This is important because it suggests you can use the same model to simultaneously classify content safety violations, prompt injections, and generate the output tokens. Alternatively, you could use a very small LM, prune it to the optimal intermediate layer, and use the outputs from this layer as the features for the classification task. This would allow for an incredibly compute efficient and lightweight classifier that integrates well with an existing LM inference pipeline.
This is the first of several articles I plan to share on this topic. In this article I will summarize the goals, approach, key results, and implications of our research. In a future article, I plan to share how we applied our approach to IBM’s Granite-8B model and an open-source model without any guardrails, allowing both models to detect content safety & prompt injection violations and generate output tokens all in one pass through the model. For further details on our research feel free to check out the full paper or reach out with questions.
Goals & Approach
Overview: Our research focuses on understanding how well the hidden states of intermediate transformer layers perform when used as the input features for classification tasks. We wanted to understand if small general-purpose models and special-purpose models for content safety and prompt injection classification tasks would perform better on these tasks if we could identify the optimal layer to use for the task instead of using the entire model / the last layer for classification. We also wanted to understand how small of a model, in terms of the total number of parameters, we could use as a starting point for this task. Other research has shown that different layers of the model focus on different characteristics of any given prompt input, our work finds that the intermediate layers tend to best capture the features that are most important for these classification tasks.
Datasets: For both content safety and prompt injection classification tasks we compare the performance of models trained using our approach to baseline models on task-specific datasets. Previous work indicated our classifiers would only see small performance improvements after a few hundred examples so for both classification tasks we used a task-specific dataset with 5,000 randomly sampled examples, allowing for enough data diversity while minimizing compute and training time. For the content safety dataset we use a combination of the SALAD Data dataset from OpenSafetyLab and the LMSYS-Chat-1M dataset from LMSYS. For the prompt injection dataset we use the SPML dataset since it includes system and user prompt pairs. This is critical because some user requests might seem “safe” (e.g., “help me solve this math problem”) but they ask the model to respond outside of the system’s intended use as defined in the system prompt (e.g. “You are a helpful AI assistant for Company X, you only respond to questions about our company”).
Model Selection: We use GPT-4o as a baseline model for both tasks since it is widely considered one of the most capable LLMs and in some cases outperformed the baseline special-purpose model(s). For content safety classification we use Llama Guard 3 1B and 8B models and for prompt injection classification we use Protect AI’s DeBERTA v3 Base Prompt Injection v2 model since these models are considered leaders in their respective areas. We apply our approach, LEC, to the baseline special purpose models (Llama Guard 3 1B, Llama Guard 3 8B, and DeBERTa v3 Base Prompt Injection) and general-purpose models. For general-purpose models we selected Qwen 2.5 Instruct in sizes 0.5B, 1.5B, and 3B since these models are relatively close in size to the special-purpose models.
This setup allows us to compare 3 key things:
How well our approach performs when applied to a small general-purpose model compared to both baseline models (GPT-4o and the special-purpose model).
How much applying our approach improves the performance of the special-purpose model relative to its own baseline performance on that task.
How well our approach generalizes across model architectures, by evaluating its performance on both general-purpose and special-purpose models.
Important Implementation Details: For both Qwen 2.5 Instruct models and task-specific special-purpose models we prune individual layers and capture the hidden state of the transformer layer to train a Penalized Logistic Regression (PLR) model with L2 regularization. The PLR model has the same number of trainable parameters as the size of the model’s hidden state plus one for the bias in binary classification tasks, this ranges from 769 for the smallest model (Protect AI’s DeBERTa) to 4097 for the largest model (Llama Guard 3 8B). We train the classifier with varying numbers of examples for each layer allowing us to understand the impact of individual layers on the task and how many training examples are necessary to surpass the baseline models’ performance or achieve optimal performance in terms of F1 score. We run our entire test set through the baseline models to establish their performance on each task.
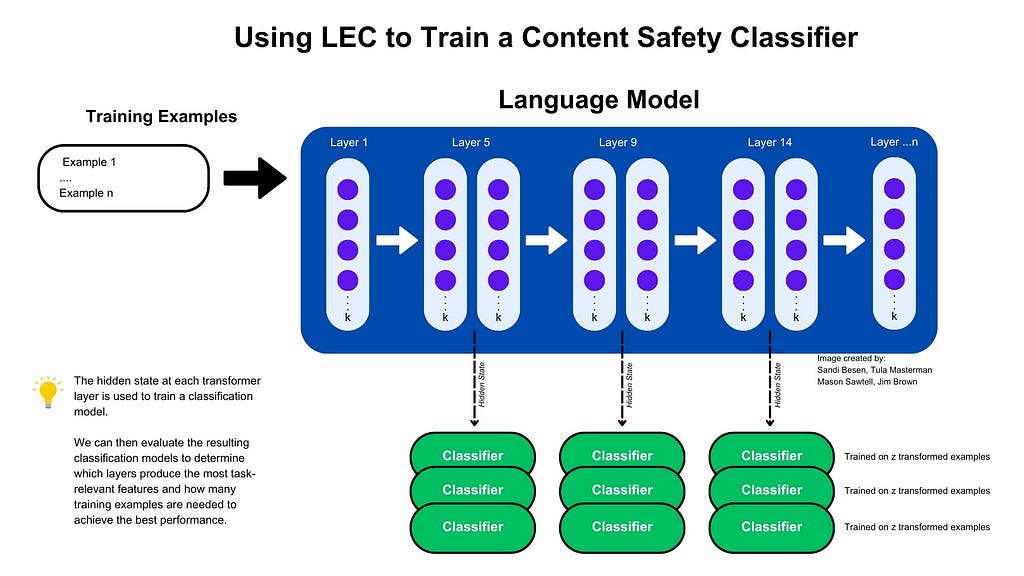
Image by author and team demonstrating the LEC training process at a high level. Training examples are independently passed through a model and the hidden state at each transformer layer is captured. These hidden states are then used to train classifiers. Each classifier is trained with a varying number of examples. The results allow us to determine which layers produce the most task-relevant features and how many examples are needed to achieve the best performance.
Key Results
In this section I’ll cover the important results across both tasks and for each task, content safety classification and prompt injection classification, individually.
Key findings across both tasks:
Overall, our approach results in a higher F1 score across all evaluated tasks, models, and number of of training examples, typically surpassing baseline model performance within 20–100 examples.
The intermediate layers tend to show the largest improvement in F1 score compared to the final layer when trained on fewer examples. These layers also tend to have the best performance relative to the baseline models. This indicates that local features important to both classification tasks are represented early on in the transformer network and suggests that use cases with fewer training examples can especially benefit from our approach.
Furthermore, we found that applying our approach to the special-purpose models outperforms the models own baseline performance, typically within 20 examples, by identifying and using the most task-relevant layer.
Both general-purpose Qwen 2.5 Instruct models and task-specific special-purpose models achieve higher F1 scores within fewer examples with our approach. This suggests that our approach generalizes across architectures and domains.
In the Qwen 2.5 Instruct models, we find that the intermediate model layers attain higher F1 scores with fewer examples for both content safety and prompt injection classification tasks. This suggests that it’s feasible to use one model for both classification tasks and generate the outputs in one pass. The additional compute time for these extra classification steps would be almost negligible given the small size of the classifiers.
Content safety classification results:
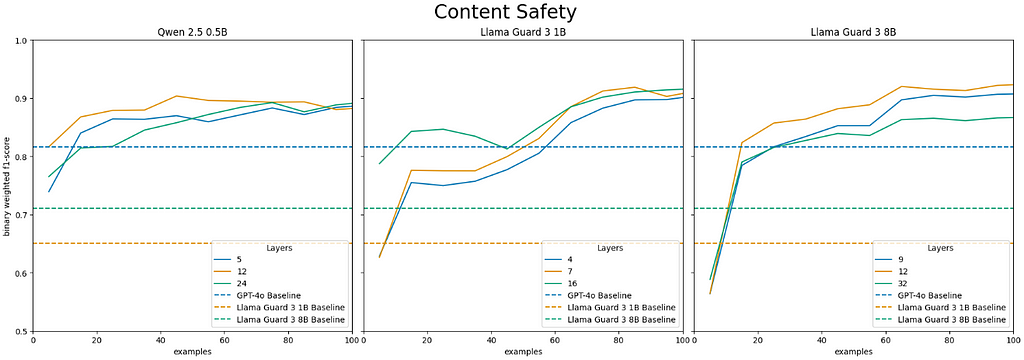
Image by author and team demonstrating LEC performance at select layers on the binary content safety classification task for Qwen 2.5 Instruct 0.5B, Llama Guard 3 1B, and Llama Guard 3 8b. The x-axis shows the number of training examples, and the Y-axis reflects the weighted F1-score.
For both binary and multi-class classification, the general and special purpose models trained using our approach typically outperform the baseline Llama Guard 3 models within 20 examples and GPT-4o in fewer than 100 examples.
For both binary and multi-class classification, the general and special purpose LEC models typically surpass all baseline models performance for the intermediate layers if not all layers. Our results on binary content safety classification surpass the baselines by the widest margins attaining maximum F1-scores of 0.95 or 0.96 for both Qwen 2.5 Instruct and Llama Guard LEC models. In comparison, GPT-4o’s baseline F1 score is 0.82, Llama Guard 3 1B’s is 0.65 , and Llama Guard 3 8B’s is 0.71.
For binary classification our approach performs comparably when applied to Qwen 2.5 Instruct 0.5B, Llama Guard 3 1B, and Llama Guard 3 8B. The models attain a maximum F1 score of 0.95, 0.96, and 0.96 respectively. Interestingly, Qwen 2.5 Instruct 0.5B surpasses GPT-4o’s baseline performance in 15 examples for the middle layers while it takes both Llama Guard 3 models 55 examples to do so.
For multi-class classification, a very small LEC model using the hidden state from the middle layers of Qwen 2.5 Instruct 0.5B surpasses GPT-4o’s baseline performance within 35 training examples for all three difficulty levels of the multi-class classification task.
Prompt injection classification results:
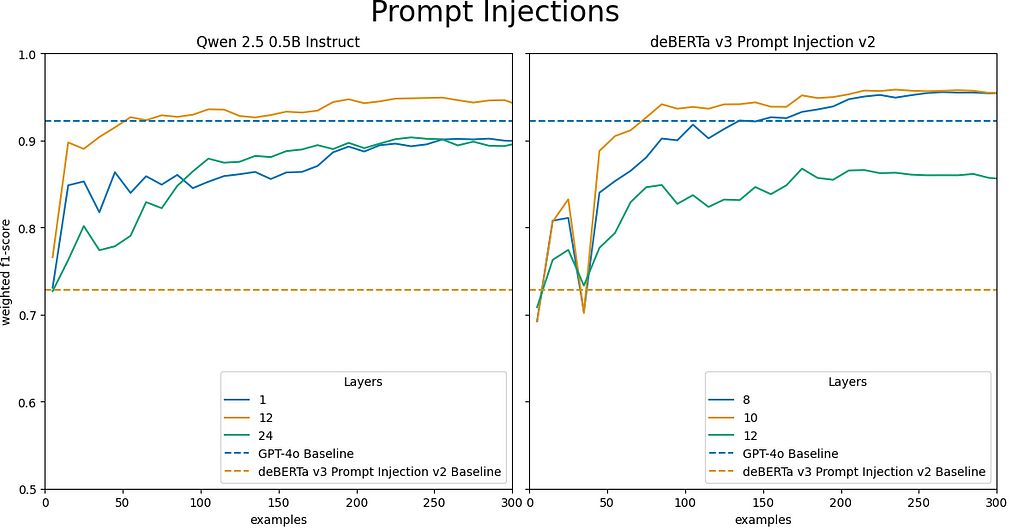
Image by author and team demonstrating LEC performance at select layers on the prompt injection classification task for Qwen 2.5 Instruct 0.5B and DeBERTa v3 Prompt Injection v2 models. The x-axis shows the number of training examples, and the Y-axis reflects the weighted F1-score. These graphs demonstrate how both LEC models outperform the baselines for the intermediate model layers with minimal training examples.
Applying our approach to both general-purpose Qwen 2.5 Instruct models and special-purpose DeBERTa v3 Prompt Injection v2 results in both models intermediate layers outperforming the baseline models in fewer than 100 training examples. This again indicates that our approach generalizes across model architectures and domains.
All three Qwen 2.5 Instruct model sizes surpass the baseline DeBERTa v3 Prompt Injection v2 model’s F1 score of 0.73 within 5 training examples for all model layers.
Qwen 2.5 Instruct 0.5B surpasses GPT-4o’s performance for the middle layer, layer 12 in 55 examples. Similar, but slightly better performance is observed for the larger Qwen 2.5 Instruct models.
Applying our approach to the DeBERTa v3 Prompt Injection v2 model results in a maximum F1 score of 0.98, significantly surpassing the model’s baseline performance F1 score of 0.73 on this task.
The intermediate layers achieve the highest weighted F1 scores for both the DeBERTa model and across Qwen 2.5 Instruct model sizes.
Conclusion
In our research we focused on two responsible AI related classification tasks but expect this approach to work for other classification tasks provided that the important features for the task can be detected by the intermediate layers of the model.
We demonstrated that our approach of training a classification model on the hidden state from an intermediate transformer layer creates effective content safety and prompt injection classification models with minimal parameters and training examples. Furthermore, we illustrated how our approach improves the performance of existing special-purpose models compared to their own baseline results.
Our results suggest two promising options for integrating top-performing content safety and prompt injection classifiers into existing LLM inference workflows. One option is to take a lightweight small model like the ones explored in our paper, prune it to the optimal layer and use it as a feature extractor for the classification task. The classification model could then be used to identify any content safety violations or prompt injections before processing the user input with a closed-source model like GPT-4o. The same classification model could be used to validate the generated response before sending it to the user. A second option is to apply our approach to an open-source, general-purpose model, like IBM’s Granite or Meta’s Llama models, identify which layers are most relevant to the classification task, then update the inference pipeline to simultaneously classify content safety and prompt injections while generating the output response. If content safety or prompt injections are detected you could easily stop the output generation, otherwise if there are no violations, the model can continue generating it’s response. Either of these options could be extended to apply to AI-agent based scenarios depending on the model used for each agent.
In summary, LEC provides a new promising and practical solution to safeguarding Generative AI based systems by identifying content safety and prompt injection attacks with better performance and fewer training examples compared to existing approaches. This is critical for any person or business building with Generative AI today to ensure their systems are operating both responsibly and as intended.
Note: The opinions expressed both in this article and the research paper are solely those of the authors and do not necessarily reflect the views or policies of their respective employers.
Interested in discussing further or collaborating? Reach out on LinkedIn!
Implementing evaluation frameworks to optimize accuracy in real-world applications
Image created by DALL-E 3
Building a prototype for an LLM application is surprisingly straightforward. You can often create a functional first version within just a few hours. This initial prototype will likely provide results that look legitimate and be a good tool to demonstrate your approach. However, this is usually not enough for production use.
LLMs are probabilistic by nature, as they generate tokens based on the distribution of likely continuations. This means that in many cases, we get the answer close to the “correct” one from the distribution. Sometimes, this is acceptable — for example, it doesn’t matter whether the app says “Hello, John!” or “Hi, John!”. In other cases, the difference is critical, such as between “The revenue in 2024 was 20M USD” and “The revenue in 2024 was 20M GBP”.
In many real-world business scenarios, precision is crucial, and “almost right” isn’t good enough. For example, when your LLM application needs to execute API calls, or you’re doing a summary of financial reports. From my experience, ensuring the accuracy and consistency of results is far more complex and time-consuming than building the initial prototype.
In this article, I will discuss how to approach measuring and improving accuracy. We’ll build an SQL Agent where precision is vital for ensuring that queries are executable. Starting with a basic prototype, we’ll explore methods to measure accuracy and test various techniques to enhance it, such as self-reflection and retrieval-augmented generation (RAG).
Setup
As usual, let’s begin with the setup. The core components of our SQL agent solution are the LLM model, which generates queries, and the SQL database, which executes them.
LLM model — Llama
For this project, we will use an open-source Llama model released by Meta. I’ve chosen Llama 3.1 8B because it is lightweight enough to run on my laptop while still being quite powerful (refer to the documentation for details).
If you haven’t installed it yet, you can find guides here. I use it locally on MacOS via Ollama. Using the following command, we can download the model.
ollama pull llama3.1:8b
We will use Ollama with LangChain, so let’s start by installing the required package.
pip install -qU langchain_ollama
Now, we can run the Llama model and see the first results.
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="llama3.1:8b") llm.invoke("How are you?") # I'm just a computer program, so I don't have feelings or emotions # like humans do. I'm functioning properly and ready to help with # any questions or tasks you may have! How can I assist you today?
We would like to pass a system message alongside customer questions. So, following the Llama 3.1 model documentation, let’s put together a helper function to construct a prompt and test this function.
system_prompt = ''' You are Rudolph, the spirited reindeer with a glowing red nose, bursting with excitement as you prepare to lead Santa's sleigh through snowy skies. Your joy shines as brightly as your nose, eager to spread Christmas cheer to the world! Please, answer questions concisely in 1-2 sentences. ''' prompt = get_llama_prompt('How are you?', system_prompt) llm.invoke(prompt)
# I'm feeling jolly and bright, ready for a magical night! # My shiny red nose is glowing brighter than ever, just perfect # for navigating through the starry skies.
The new system prompt has changed the answer significantly, so it works. With this, our local LLM setup is ready to go.
Database — ClickHouse
I will use an open-source database ClickHouse. I’ve chosen ClickHouse because it has a specific SQL dialect. LLMs have likely encountered fewer examples of this dialect during training, making the task a bit more challenging. However, you can choose any other database.
Installing ClickHouse is pretty straightforward — just follow the instructions provided in the documentation.
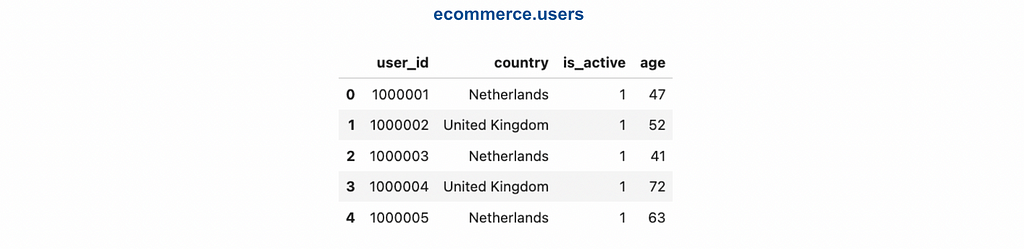
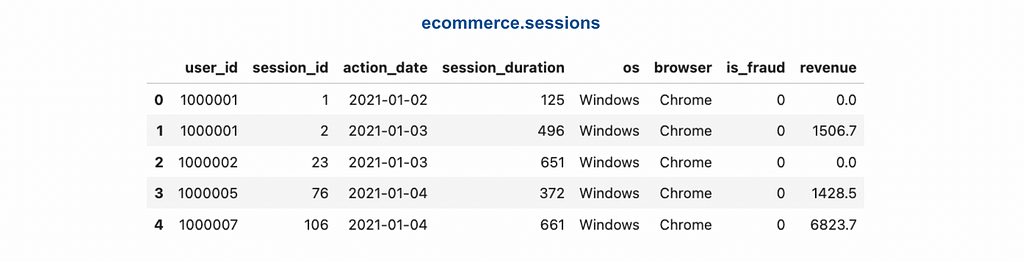
We will be working with two tables: ecommerce.users and ecommerce.sessions. These tables contain fictional data, including customer personal information and their session activity on the e-commerce website.
You can find the code for generating synthetic data and uploading it on GitHub.
With that, the setup is complete, and we’re ready to move on to building the basic prototype.
The first prototype
As discussed, our goal is to build an SQL Agent — an application that generates SQL queries to answer customer questions. In the future, we can add another layer to this system: executing the SQL query, passing both the initial question and the database results back to the LLM, and asking it to generate a human-friendly answer. However, for this article, we’ll focus on the first step.
The best practice with LLM applications (similar to any other complex tasks) is to start simple and then iterate. The most straightforward implementation is to do one LLM call and share all the necessary information (such as schema description) in the system prompt. So, the first step is to put together the prompt.
generate_query_system_prompt = ''' You are a senior data analyst with more than 10 years of experience writing complex SQL queries. There are two tables in the database with the following schemas.
Table: ecommerce.users Description: customers of the online shop Fields: - user_id (integer) - unique identifier of customer, for example, 1000004 or 3000004 - country (string) - country of residence, for example, "Netherlands" or "United Kingdom" - is_active (integer) - 1 if customer is still active and 0 otherwise - age (integer) - customer age in full years, for example, 31 or 72
Table: ecommerce.sessions Description: sessions of usage the online shop Fields: - user_id (integer) - unique identifier of customer, for example, 1000004 or 3000004 - session_id (integer) - unique identifier of session, for example, 106 or 1023 - action_date (date) - session start date, for example, "2021-01-03" or "2024-12-02" - session_duration (integer) - duration of session in seconds, for example, 125 or 49 - os (string) - operation system that customer used, for example, "Windows" or "Android" - browser (string) - browser that customer used, for example, "Chrome" or "Safari" - is_fraud (integer) - 1 if session is marked as fraud and 0 otherwise - revenue (float) - income in USD (the sum of purchased items), for example, 0.0 or 1506.7
Write a query in ClickHouse SQL to answer the following question. Add "format TabSeparatedWithNames" at the end of the query to get data from ClickHouse database in the right format. '''
I’ve included the example values for each field in the prompt to ensure that LLM understands the data format.
And that’s it! With this, we have our first functional prototype for the SQL Agent. Now, it’s time to put it to the test.
prompt = get_llama_prompt('How many customers made purchase in December 2024?', generate_query_system_prompt) llm.invoke(prompt)
# To find out how many customers made a purchase in December 2024, # we need to join the `sessions` table with the `users` table on the `user_id`, # and then filter by `action_date` for sessions that took place in December 2024.
# Here is the query: # # ```sql # SELECT COUNT(DISTINCT u.user_id) # FROM ecommerce.sessions s # JOIN ecommerce.users u ON s.user_id = u.user_id # WHERE # EXTRACT(YEAR FROM s.action_date) = 2024 # AND EXTRACT(MONTH FROM s.action_date) = 12 # AND revenue > 0; # ```
# This query first joins the `sessions` table with the `users` table # on the `user_id`. Then it filters out sessions where no purchase # was made (revenue is greater than 0). Finally, it selects the distinct # user IDs of these customers.
# When you run this query in ClickHouse SQL, you can add "format TabSeparatedWithNames" # at the end to get the result in the right format:
# ```sql # SELECT COUNT(DISTINCT u.user_id) # FROM ecommerce.sessions s # JOIN ecommerce.users u ON s.user_id = u.user_id # WHERE # EXTRACT(YEAR FROM s.action_date) = 2024 # AND EXTRACT(MONTH FROM s.action_date) = 12 # AND revenue > 0; # format TabSeparatedWithNames; # ```
The agent produced a fairly decent result, but there’s one issue — the LLM returned not only the SQL query but also some commentary. Since we plan to execute SQL queries later, this format is not suitable for our task. Let’s work on fixing it.
Fortunately, this problem has already been solved, and we don’t need to parse the SQL queries from the text manually. We can use the chat model ChatOllama. Unfortunately, it doesn’t support structured output, but we can leverage tool calling to achieve the same result.
To do this, we will define a dummy tool to execute the query and instruct the model in the system prompt always to call this tool. I’ve kept the comments in the output to give the model some space for reasoning, following the chain-of-thought pattern.
from langchain_ollama import ChatOllama from langchain_core.tools import tool
Args: comments (str): 1-2 sentences describing the result SQL query and what it does to answer the question, query (str): SQL query """ pass
chat_llm = ChatOllama(model="llama3.1:8b").bind_tools([execute_query]) result = chat_llm.invoke(prompt) print(result.tool_calls)
# [{'name': 'execute_query', # 'args': {'comments': 'SQL query returns number of customers who made a purchase in December 2024. The query joins the sessions and users tables based on user ID to filter out inactive customers and find those with non-zero revenue in December 2024.', # 'query': 'SELECT COUNT(DISTINCT T2.user_id) FROM ecommerce.sessions AS T1 INNER JOIN ecommerce.users AS T2 ON T1.user_id = T2.user_id WHERE YEAR(T1.action_date) = 2024 AND MONTH(T1.action_date) = 12 AND T2.is_active = 1 AND T1.revenue > 0'}, # 'type': 'tool_call'}]
With the tool calling, we can now get the SQL query directly from the model. That’s an excellent result. However, the generated query is not entirely accurate:
It includes a filter for is_active = 1, even though we didn’t specify the need to filter out inactive customers.
The LLM missed specifying the format despite our explicit request in the system prompt.
Clearly, we need to focus on improving the model’s accuracy. But as Peter Drucker famously said, “You can’t improve what you don’t measure.” So, the next logical step is to build a system for evaluating the model’s quality. This system will be a cornerstone for performance improvement iterations. Without it, we’d essentially be navigating in the dark.
Evaluating the accuracy
Evaluation basics
To ensure we’re improving, we need a robust way to measure accuracy. The most common approach is to create a “golden” evaluation set with questions and correct answers. Then, we can compare the model’s output with these “golden” answers and calculate the share of correct ones. While this approach sounds simple, there are a few nuances worth discussing.
First, you might feel overwhelmed at the thought of creating a comprehensive set of questions and answers. Building such a dataset can seem like a daunting task, potentially requiring weeks or months. However, we can start small by creating an initial set of 20–50 examples and iterating on it.
As always, quality is more important than quantity. Our goal is to create a representative and diverse dataset. Ideally, this should include:
Common questions. In most real-life cases, we can take the history of actual questions and use it as our initial evaluation set.
Challenging edge cases. It’s worth adding examples where the model tends to hallucinate. You can find such cases either while experimenting yourself or by gathering feedback from the first prototype.
Once the dataset is ready, the next challenge is how to score the generated results. We can consider several approaches:
Comparing SQL queries. The first idea is to compare the generated SQL query with the one in the evaluation set. However, it might be tricky. Similarly-looking queries can yield completely different results. At the same time, queries that look different can lead to the same conclusions. Additionally, simply comparing SQL queries doesn’t verify whether the generated query is actually executable. Given these challenges, I wouldn’t consider this approach the most reliable solution for our case.
Exact matches. We can use old-school exact matching when answers in our evaluation set are deterministic. For example, if the question is, “How many customers are there?” and the answer is “592800”, the model’s response must match precisely. However, this approach has its limitations. Consider the example above, and the model responds, “There are 592,800 customers”. While the answer is absolutely correct, an exact match approach would flag it as invalid.
Using LLMs for scoring. A more robust and flexible approach is to leverage LLMs for evaluation. Instead of focusing on query structure, we can ask the LLM to compare the results of SQL executions. This method is particularly effective in cases where the query might differ but still yields correct outputs.
It’s worth keeping in mind that evaluation isn’t a one-time task; it’s a continuous process. To push our model’s performance further, we need to expand the dataset with examples causing the model’s hallucinations. In production mode, we can create a feedback loop. By gathering input from users, we can identify cases where the model fails and include them in our evaluation set.
In our example, we will be assessing only whether the result of execution is valid (SQL query can be executed) and correct. Still, you can look at other parameters as well. For example, if you care about efficiency, you can compare the execution times of generated queries against those in the golden set.
Evaluation set and validation
Now that we’ve covered the basics, we’re ready to put them into practice. I spent about 20 minutes putting together a set of 10 examples. While small, this set is sufficient for our toy task. It consists of a list of questions paired with their corresponding SQL queries, like this:
[ { "question": "How many customers made purchase in December 2024?", "sql_query": "select uniqExact(user_id) as customers from ecommerce.sessions where (toStartOfMonth(action_date) = '2024-12-01') and (revenue > 0) format TabSeparatedWithNames" }, { "question": "What was the fraud rate in 2023, expressed as a percentage?", "sql_query": "select 100*uniqExactIf(user_id, is_fraud = 1)/uniqExact(user_id) as fraud_rate from ecommerce.sessions where (toStartOfYear(action_date) = '2023-01-01') format TabSeparatedWithNames" }, ... ]
tmp = [] for rec in tqdm.tqdm(golden_df.to_dict('records')): generated_query = generate_query(rec['question']) tmp.append( { 'id': rec['id'], 'generated_query': generated_query } )
eval_df = golden_df.merge(pd.DataFrame(tmp))
Before moving on to the LLM-based scoring of query outputs, it’s important to first ensure that the SQL query is valid. To do this, we need to execute the queries and examine the database output.
I’ve created a function that runs a query in ClickHouse. It also ensures that the output format is correctly specified, as this may be critical in business applications.
def get_clickhouse_data(query, host = CH_HOST, connection_timeout = 1500): # pushing model to return data in the format that we want if not 'format tabseparatedwithnames' in query.lower(): return "Database returned the following error:n Please, specify the output format."
r = requests.post(host, params = {'query': query}, timeout = connection_timeout) if r.status_code == 200: return r.text else: return 'Database returned the following error:n' + r.text # giving feedback to LLM instead of raising exception
The next step is to execute both the generated and golden queries and then save their outputs.
tmp = []
for rec in tqdm.tqdm(eval_df.to_dict('records')): golden_output = get_clickhouse_data(rec['sql_query']) generated_output = get_clickhouse_data(rec['generated_query'])
Next, let’s check the output to see whether the SQL query is valid or not.
def is_valid_output(s): if s.startswith('Database returned the following error:'): return 'error' if len(s.strip().split('n')) >= 1000: return 'too many rows' return 'ok'
Then, we can evaluate the SQL validity for both the golden and generated sets.
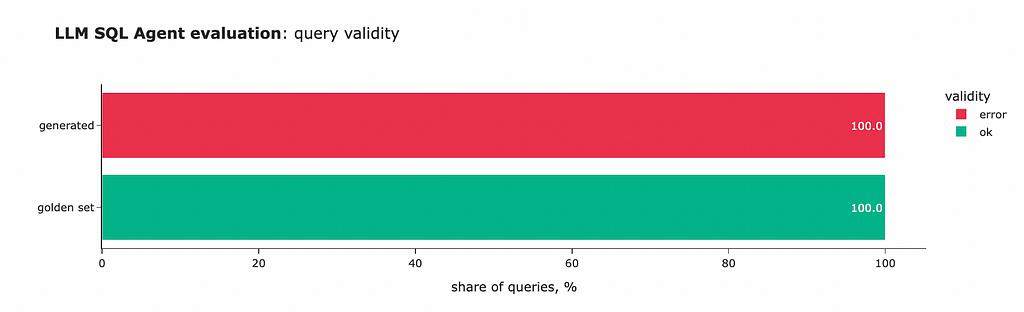
The initial results are not very promising; the LLM was unable to generate even a single valid query. Looking at the errors, it’s clear that the model failed to specify the right format despite it being explicitly defined in the system prompt. So, we definitely need to work more on the accuracy.
Checking the correctness
However, validity alone is not enough. It’s crucial that we not only generate valid SQL queries but also produce the correct results. Although we already know that all our queries are invalid, let’s now incorporate output evaluation into our process.
As discussed, we will use LLMs to compare the outputs of the SQL queries. I typically prefer using more powerful model for evaluation, following the day-to-day logic where a senior team member reviews the work. For this task, I’ve chosen OpenAI GPT 4o-mini.
Similar to our generation flow, I’ve set up all the building blocks necessary for accuracy assessment.
from langchain_openai import ChatOpenAI
accuracy_system_prompt = ''' You are a senior and very diligent QA specialist and your task is to compare data in datasets. They are similar if they are almost identical, or if they convey the same information. Disregard if column names specified in the first row have different names or in a different order. Focus on comparing the actual information (numbers). If values in datasets are different, then it means that they are not identical. Always execute tool to provide results. '''
@tool def compare_datasets(comments: str, score: int) -> str: """Stores info about datasets. Args: comments (str): 1-2 sentences about the comparison of datasets, score (int): 0 if dataset provides different values and 1 if it shows identical information """ pass
accuracy_chat_llm = ChatOpenAI(model="gpt-4o-mini", temperature = 0.0) .bind_tools([compare_datasets])
accuracy_question_tmp = ''' Here are the two datasets to compare delimited by #### Dataset #1: #### {dataset1} #### Dataset #2: #### {dataset2} #### '''
accuracy_result = accuracy_chat_llm.invoke(prompt) accuracy_result.tool_calls[0]['args'] # {'comments': 'The datasets contain different customer counts: 114032 in Dataset #1 and 114031 in Dataset #2.', # 'score': 0}
prompt = get_openai_prompt(accuracy_question_tmp.format( dataset1 = 'usersn114032n', dataset2 = 'customersn114032n'), accuracy_system_prompt) accuracy_result = accuracy_chat_llm.invoke(prompt) accuracy_result.tool_calls[0]['args'] # {'comments': 'The datasets contain the same numerical value (114032) despite different column names, indicating they convey identical information.', # 'score': 1}
Fantastic! It looks like everything is working as expected. Let’s now encapsulate this into a function.
As we discussed, building an LLM application is an iterative process, so we’ll need to run our accuracy assessment multiple times. It will be helpful to have all this logic encapsulated in a single function.
The function will take two arguments as input:
generate_query_func: a function that generates an SQL query for a given question.
golden_df: an evaluation dataset with questions and correct answers in the form of a pandas DataFrame.
As output, the function will return a DataFrame with all evaluation results and a couple of charts displaying the main KPIs.
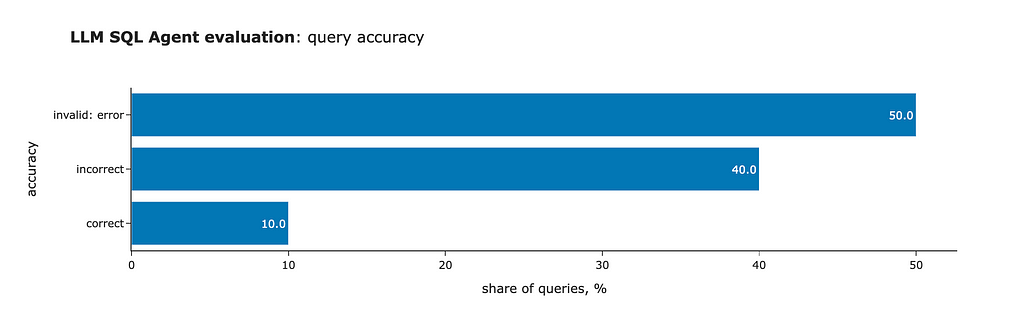
eval_df['accuracy'] = list(map( lambda x, y: 'invalid: ' + x if x != 'ok' else ('correct' if y == 1 else 'incorrect'), eval_df.generated_output_valid, eval_df.correct_output ))
With that, we’ve completed the evaluation setup and can now move on to the core task of improving the model’s accuracy.
Improving accuracy: Self-reflection
Let’s do a quick recap. We’ve built and tested the first version of SQL Agent. Unfortunately, all generated queries were invalid because they were missing the output format. Let’s address this issue.
One potential solution is self-reflection. We can make an additional call to the LLM, sharing the error and asking it to correct the bug. Let’s create a function to handle generation with self-reflection.
reflection_user_query_tmpl = ''' You've got the following question: "{question}". You've generated the SQL query: "{query}". However, the database returned an error: "{output}". Please, revise the query to correct mistake. '''
db_output = get_clickhouse_data(generated_query) is_valid_db_output = is_valid_output(db_output) if is_valid_db_output == 'too many rows': db_output = "Database unexpectedly returned more than 1000 rows."
if is_valid_db_output == 'ok': return generated_query
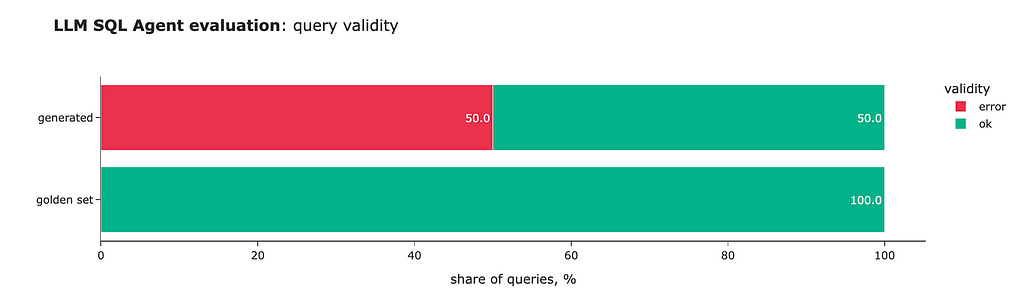
Wonderful! We’ve achieved better results — 50% of the queries are now valid, and all format issues have been resolved. So, self-reflection is pretty effective.
However, self-reflection has its limitations. When we examine the accuracy, we see that the model returns the correct answer for only one question. So, our journey is not over yet.
Improving accuracy: RAG
Another approach to improving accuracy is using RAG (retrieval-augmented generation). The idea is to identify question-and-answer pairs similar to the customer query and include them in the system prompt, enabling the LLM to generate a more accurate response.
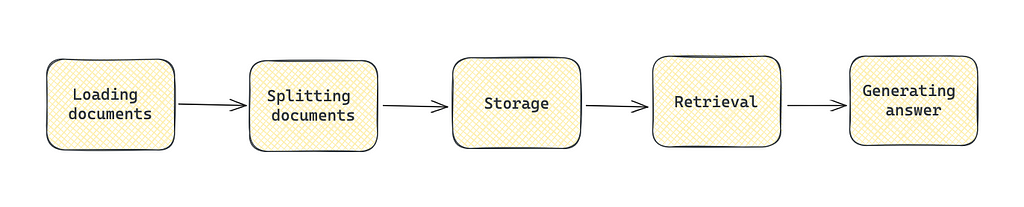
RAG consists of the following stages:
Loading documents: importing data from available sources.
Splitting documents: creating smaller chunks.
Storage: using vector stores to process and store data efficiently.
Retrieval: extracting documents that are relevant to the query.
Generation: passing a question and relevant documents to LLM to generate the final answer.
We will use the Chroma database as a local vector storage — to store and retrieve embeddings.
from langchain_chroma import Chroma vector_store = Chroma(embedding_function=embeddings)
Vector stores are using embeddings to find chunks that are similar to the query. For this purpose, we will use OpenAI embeddings.
from langchain_openai import OpenAIEmbeddings embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
Since we can’t use examples from our evaluation set (as they are already being used to assess quality), I’ve created a separate set of question-and-answer pairs for RAG. You can find it on GitHub.
Now, let’s load the set and create a list of pairs in the following format: Question: %s; Answer: %s.
with open('rag_set.json', 'r') as f: rag_set = json.loads(f.read()) rag_set_df = pd.DataFrame(rag_set)
Next, I used LangChain’s text splitter by character to create chunks, with each question-and-answer pair as a separate chunk. Since we are splitting the text semantically, no overlap is necessary.
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter( separator="nn", chunk_size=1, # to split by character without merging chunk_overlap=0, length_function=len, is_separator_regex=False, )
Now, we can test the retrieval to see the results. They look quite similar to the customer question.
question = 'What was the share of users using Windows yesterday?' retrieved_docs = vector_store.similarity_search(question, 3) context = "nn".join(map(lambda x: x.page_content, retrieved_docs)) print(context)
# Question: What was the share of users using Windows the day before yesterday?; # Answer: select 100*uniqExactIf(user_id, os = 'Windows')/uniqExact(user_id) as windows_share from ecommerce.sessions where (action_date = today() - 2) format TabSeparatedWithNames # Question: What was the share of users using Windows in the last week?; # Answer: select 100*uniqExactIf(user_id, os = 'Windows')/uniqExact(user_id) as windows_share from ecommerce.sessions where (action_date >= today() - 7) and (action_date < today()) format TabSeparatedWithNames # Question: What was the share of users using Android yesterday?; # Answer: select 100*uniqExactIf(user_id, os = 'Android')/uniqExact(user_id) as android_share from ecommerce.sessions where (action_date = today() - 1) format TabSeparatedWithNames
Let’s adjust the system prompt to include the examples we retrieved.
generate_query_system_prompt_with_examples_tmpl = ''' You are a senior data analyst with more than 10 years of experience writing complex SQL queries. There are two tables in the database you're working with with the following schemas.
Table: ecommerce.users Description: customers of the online shop Fields: - user_id (integer) - unique identifier of customer, for example, 1000004 or 3000004 - country (string) - country of residence, for example, "Netherlands" or "United Kingdom" - is_active (integer) - 1 if customer is still active and 0 otherwise - age (integer) - customer age in full years, for example, 31 or 72
Table: ecommerce.sessions Description: sessions of usage the online shop Fields: - user_id (integer) - unique identifier of customer, for example, 1000004 or 3000004 - session_id (integer) - unique identifier of session, for example, 106 or 1023 - action_date (date) - session start date, for example, "2021-01-03" or "2024-12-02" - session_duration (integer) - duration of session in seconds, for example, 125 or 49 - os (string) - operation system that customer used, for example, "Windows" or "Android" - browser (string) - browser that customer used, for example, "Chrome" or "Safari" - is_fraud (integer) - 1 if session is marked as fraud and 0 otherwise - revenue (float) - income in USD (the sum of purchased items), for example, 0.0 or 1506.7
Write a query in ClickHouse SQL to answer the following question. Add "format TabSeparatedWithNames" at the end of the query to get data from ClickHouse database in the right format. Answer questions following the instructions and providing all the needed information and sharing your reasoning.
Examples of questions and answers: {examples} '''
Once again, let’s create the generate query function with RAG.
db_output = get_clickhouse_data(generated_query) is_valid_db_output = is_valid_output(db_output) if is_valid_db_output == 'too many rows': db_output = "Database unexpectedly returned more than 1000 rows."
if is_valid_db_output == 'ok': return generated_query
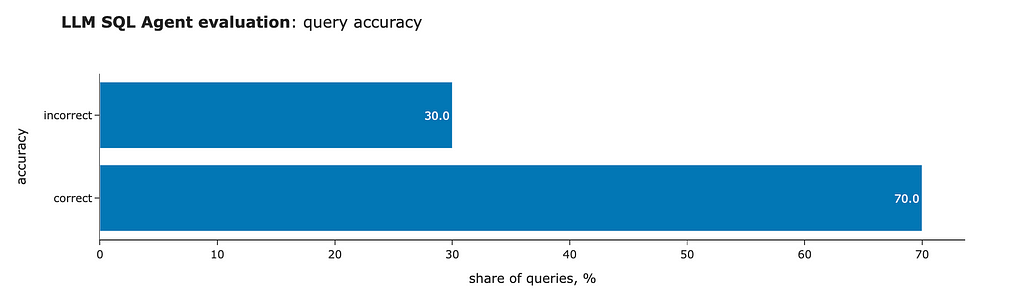
We can see another slight improvement: we’ve completely eliminated invalid SQL queries (thanks to self-reflection) and increased the number of correct answers to 7 out of 10.
That’s it. It’s been quite a journey. We started with 0 valid SQL queries and have now achieved 70% accuracy.
In this article, we explored the iterative process of improving accuracy for LLM applications.
We built an evaluation set and the scoring criteria that allowed us to compare different iterations and understand whether we were moving in the right direction.
We leveraged self-reflection to allow the LLM to correct its mistakes and significantly reduce the number of invalid SQL queries.
Additionally, we implemented Retrieval-Augmented Generation (RAG) to further enhance the quality, achieving an accuracy rate of 60–70%.
While this is a solid result, it still falls short of the 90%+ accuracy threshold typically expected for production applications. To achieve such a high bar, we need to use fine-tuning, which will be the topic of the next article.
Thank you a lot for reading this article. I hope this article was insightful for you. If you have any follow-up questions or comments, please leave them in the comments section.
Reference
All the images are produced by the author unless otherwise stated.
And just like that, 2024 is (almost) in the books. It was a year of exciting transitions — both for the TDS team and, in many meaningful ways, for the data science, machine learning, and AI communities at large. We’d like to thank all of you—readers, authors, and followers—for your support, and for keeping us busy and engaged with your excellent contributions and comments.
Unlike in 2023, when a single event (ChatGPT’s launch just weeks before the beginning of the year) stopped everyone in their tracks and shaped conversations for months on end, this year we experienced a more cumulative and fragmented sense of transformation. Practitioners across industry and academia experimented with new tools and worked hard to find innovative ways to benefit from the rapid rise of LLMs; at the same time, they also had to navigate a challenging job market and a world where AI’s footprint inches ever closer to their own everyday workflows.
To help you make sense of these developments, we published more than 3,500 articles this past year, including hundreds from first-time contributors. Our authors have an incredible knack for injecting their unique perspective into any topic they cover—from big questions and timely topics to more focused technical challenges—and we’re proud of every post we published in 2024.
Within this massive creative output, some articles manage to resonate particularly well with our readers, and we’re dedicating our final Variable edition to these: our most-read, -discussed, and -shared posts of the year. As you might expect, they cover a lot of ground, so we’ve decided to arrange them following the major themes we’ve detected this year: learning and building from scratch, RAG and AI agents, career growth, and breakthroughs and innovation.
We hope you enjoy exploring our 2024 highlights, and we wish you a relaxing end of the year — see you in January!
Learning and Building from Scratch
The most reliably popular type of TDS post is the one that teaches readers how to do or study something interesting and productive on their own, and with minimal prerequisites. This year is no exception—our three most-read articles of 2024 fall under this category.
Once the initial excitement surrounding LLMs settled (a bit), data and ML professionals realized that these powerful models aren’t all that useful out of the box. Retrieval-augmented generation and agentic AI rose to prominence in the past year as the two leading approaches that bridge the gap between the models’ potential and real-world value; they also ended up being our most covered technical topics in recent months.
12 RAG Pain Points and Proposed Solutions On a similar troubleshooting beat, Wenqi Glantz outlines a dozen streamlined approaches for tackling some of the most common challenges practitioners face when implementing RAG.
Choosing Between LLM Agent Frameworks It can be tough to make informed choices in an ecosystem where both major and emerging players release new tools every day. Aparna Dhinakaran is here to help with sharp insights on the tradeoffs to keep in mind.
Career Growth
Data science and machine learning career paths continue to evolve, and the need to adapt to this changing terrain can generate nontrivial amounts of stress for many professionals, whether they’re deep into their career or are just starting out. We love publishing personal reflections on this topic when they also offer readers pragmatic advice—here are four that stood out to us (and to our readers).
What I Learned in my First 3 Months as a Freelance Data Scientist Career switches are always tricky, and moving away from the structure of working at a company to the world of self-employment comes with its own set of challenges—and, as CJ Sullivan shows, with great opportunities for learning and growth.
Staying up-to-date with cutting-edge research and new tools can feel overwhelming at times, which is why we have a particular soft spot for top-notch paper walkthroughs and primers on emerging libraries and models. Here are three such articles that particularly resonated with our audience.
A New Coefficient of Correlation “What if you were told there exists a new way to measure the relationship between two variables just like correlation except possibly better”? So starts Tim Sumner’s explainer on a groundbreaking 2020 paper.
Intro to DSPy: Goodbye Prompting, Hello Programming! In another exciting year for open-source tools, one of the standout new arrivals was DSPy, which aims to open up LLMs for programmers and make it easier to build modular AI solutions. Leonie Monigatti’s hands-on introduction is the perfect place to start exploring its possibilities.
Thank you for supporting the work of our authors in 2024! If writing for TDS is one of your goals for 2025, why not get started now? Don’t hesitate to share your work with us.
Until the next Variable, coming your way in the first week of January,
Amazon Q embedded is a feature that lets you embed a hosted Amazon Q Business assistant on your website or application to create more personalized experiences that boost end-users’ productivity. In this post, we demonstrate how to use the Amazon Q embedded feature to add an Amazon Q Business assistant to your website or web application using basic HTML or React.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.