

An LLM Approach to Summarizing Students’ Responses for Open-ended Questionnaires in Language Courses
Madrasa (מדרסה in Hebrew) is an Israeli NGO dedicated to teaching Arabic to Hebrew speakers. Recently, while learning Arabic, I discovered that the NGO has unique data and that the organization might benefit from a thorough analysis. A friend and I joined the NGO as volunteers, and we were asked to work on the summarization task described below.
What makes this summarization task so interesting is the unique mix of documents in three languages — Hebrew, Arabic, and English — while also dealing with the imprecise transcriptions among them.
A word on privacy: The data may include PII and therefore cannot be published at this time. If you believe you can contribute, please contact us.
Context of the Problem
As part of its language courses, Madrasa distributes questionnaires to students, which include both quantitative questions requiring numeric responses and open-ended questions where students provide answers in natural language.
In this blog post, we will concentrate on the open-ended natural language responses.
The Problem
The primary challenge is managing and extracting insights from a substantial volume of responses to open-ended questions. Specifically, the difficulties include:
Multilingual Responses: Student responses are primarily in Hebrew but also include Arabic and English, creating a complex multilingual dataset. Additionally, since transliteration is commonly used in Spoken Arabic courses, we found that students sometimes answered questions using both transliteration and Arabic script. We were surprised to see that some students even transliterated Hebrew and Arabic into Latin letters.
Nuanced Sentiments: The responses vary widely in sentiment and tone, including humor, suggestions, gratitude, and personal reflections.
Diverse Topics: Students touch on a wide range of subjects, from praising teachers to reporting technical issues with the website and app, to personal aspirations.
The Data
There are couple of courses. Each course includes three questionnaires administered at the beginning, middle, and end of the course. Each questionnaire contains a few open-ended questions.
The tables below provides examples of two questions along with a curated selection of student responses.

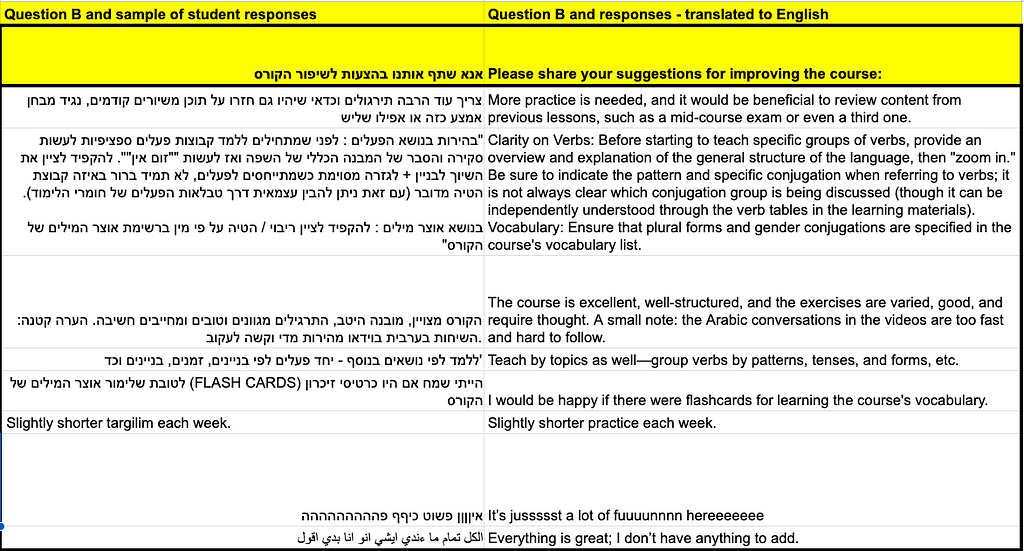
There are tens of thousands of student responses for each question, and after splitting into sentences (as described below), there can be up to around 100,000 sentences per column. This volume is manageable, allowing us to work locally.
Our goal is to summarize student opinions on various topics for each course, questionnaire, and open-ended question. We aim to capture the “main opinions” of the students while ensuring that “niche opinions” or “valuable insights” provided by individual students are not overlooked.
The Solution
To tackle challenges mention above, we implemented a multi-step natural language processing (NLP) solution.
The process pipeline involves:
- Sentence Tokenization (using NLTK Sentence Tokenizer)
- Topic Modeling (using BERTopic)
- Topic representation (using BERTopic + LLM)
- Batch summarizing (LLM with mini-batch fitting into the context-size)
- Re-summarizing the batches to create a final comprehensive summary.
Sentence Tokenization: We use NLTK to divide student responses into individual sentences. This process is crucial because student inputs often cover multiple topics within a single response. For example, a student might write, “The teacher used day-to-day examples. The games on the app were very good.” Here, each sentence addresses a different aspect of their experience. While sentence tokenization sometimes results in the loss of context due to cross-references between sentences, it generally enhances the overall analysis by breaking down responses into more manageable and topic-specific units. This approach has proven to significantly improve the end results.
NLTK’s Sentence Tokenizer (nltk.tokenize.sent_tokenize) splits documents into sentences using linguistics rules and models to identify sentence boundaries. The default English model worked well for our use case.
Topic Modeling with BERTopic: We utilized BERTopic to model the topics of the tokenized sentences, identify underlying themes, and assign a topic to each sentence. This step is crucial before summarization for several reasons. First, the variety of topics within the student responses is too vast to be handled effectively without topic modeling. By splitting the students’ answers into topics, we can manage and batch the data more efficiently, leading to improved performance during analysis. Additionally, topic modeling ensures that niche topics, mentioned by only a few students, do not get overshadowed by mainstream topics during the summarization process.
BERTopic is an elegant topic-modeling tool that embeds documents into vectors, clusters them, and models each cluster’s representation. Its key advantage is modularity, which we utilize for Hebrew embeddings and hyperparameter tuning.
The BERTopic configuration was meticulously designed to address the multilingual nature of the data and the specific nuances of the responses, thereby enhancing the accuracy and relevance of the topic assignment.
Specifically, note that we used a Hebrew Sentence-embedding model. We did consider using an embedding on word-level, but the sentence-embedding proved to be capturing the needed information.
For dimension-reduction and clustering we used BERTopic standard models UMAP and HDBSCAN, respectively, and with some hyper-parameter fine tuning the results satisfied us.
Here’s a fantastic talk on HDBSCAN by John Healy, one of the authors. It’s not just very educational; the speaker is really funny and witty! Definitely worth a watch 🙂
BERTopic has excellent documentation and a supportive community, so I’ll share a code snippet to show how easy it is to use with advanced models. More importantly, we want to emphasize some hyperparameter choices designed to achieve high cluster granularity and allow smaller topics. Remember that our goal is not only to summarize the “mainstream” ideas that most students agree upon but also to highlight nuanced perspectives and rarer students’ suggestions. This approach comes with the trade-off of slower processing and the risk of having too many topics, but managing ~40 topics is still feasible.
- UMAP dimension reduction: higher-than-standard number of components and small number of UMAP-neighbors.
- HDBSCAN clustering: min_sample = 2 for high sensitivity, while min_cluster_size = 7 allows very small clusters.
- BERTopic: nr_topics = 40.
from bertopic import BERTopic
from umap import UMAP
from hdbscan import HDBSCAN
from sentence_transformers import SentenceTransformer
from bertopic.vectorizers import ClassTfidfTransformer
topic_size_ = 7
# Sentence Embedding in Hebrew (works well also on English)
sent_emb_model = "imvladikon/sentence-transformers-alephbert"
sentence_model = SentenceTransformer(sent_emb_model)
# Initialize UMAP model for dimensionality reduction to improve BERTopic
umap_model = UMAP(n_components=128, n_neighbors=4, min_dist=0.0)
# Initialize HDBSCAN model for BERTopic clustering
hdbscan_model = HDBSCAN(min_cluster_size = topic_size_,
gen_min_span_tree=True,
prediction_data=True,
min_samples=2)
# class-based TF-IDF vectorization for topic representation prior to clustering
ctfidf_model = ClassTfidfTransformer(reduce_frequent_words=True)
# Initialize MaximalMarginalRelevance for enhancing topic representation
representation_model = MaximalMarginalRelevance(diversity=0.1)
# Configuration for BERTopic
bert_config = {
'embedding_model': sentence_model,
'top_n_words': 20, # Number of top words to represent each topic
'min_topic_size': topic_size_,
'nr_topics': 40,
'low_memory': False,
'calculate_probabilities': False,
'umap_model': umap_model,
'hdbscan_model': hdbscan_model,
'ctfidf_model': ctfidf_model,
'representation_model': representation_model
}
# Initialize BERTopic model with the specified configuration
topic_model = BERTopic(**bert_config)
Topic Representation & Summarization
For the next two parts — topic representation and topic summarization — we used chat-based LLMs, carefully crafting system and user prompts. The straightforward approach involved setting the system prompt to define the tasks of keyword extraction and summarization, and using the user prompt to input a lengthy list of documents, constrained only by context limits.
Before diving deeper, let’s discuss the choice of chat-based LLMs and the infrastructure used. For a rapid proof of concept and development cycle, we opted for Ollama, known for its easy setup and minimal friction. we encountered some challenges switching models on Google Colab, so we decided to work locally on my M3 laptop. Ollama utilizes the Mac iGPU efficiently and proved adequate for my needs.
Initially, we tested various multilingual models, including LLaMA2, LLaMA3 and LLaMA3.1. However, a new version of the Dicta 2.0 model was released recently, which outperformed the others right away. Dicta 2.0 not only delivered better semantic results but also featured improved Hebrew tokenization (~one token per Hebrew character), allowing for longer context lengths and therefore larger batch processing without quality loss.
Dicta is an LLM, bilingual (Hebrew/English), fine-tuned on Mistral-7B-v0.1. and is available on Hugging Face.
Topic Representation: This crucial step in topic modeling involves defining and describing topics through representative keywords or phrases, capturing the essence of each topic. The aim is to create clear, concise descriptions to understand the content associated with each topic. While BERTopic offers effective tools for topic representation, we found it easier to use external LLMs for this purpose. This approach allowed for more flexible experimentation, such as keyword prompt engineering, providing greater control over topic description and refinement.
- System Prompt:
“תפקידך למצוא עד חמש מילות מפתח של הטקסט ולהחזירן מופרדות בסימון נקודה. הקפד שכל מילה נבחרת תהיה מהטקסט הנתון ושהמילים תהיינה שונות אחת מן השניה. החזר לכל היותר חמש מילים שונות, בעברית, בשורה אחת קצרה, ללא אף מילה נוספת לפני או אחרי, ללא מספור וללא מעבר שורה וללא הסבר נוסף.”
- User prompt was simply keywords and representative sentences returned by BERTopic default representation model (c-tf-idf).
Batch Summarization with LLM Models: For each topic, we employed an LLM to summarize student responses. Due to the large volume of data, responses were processed in batches, with each batch summarized individually before aggregating these summaries into a final comprehensive overview.
- System Prompt:
“המטרה שלך היא לתרגם לעברית ואז לסכם בעברית. הקלט הוא תשובות התלמידים לגבי השאלה הבאה [<X>]. סכם בפסקה אחת בדיוק עם לכל היותר 10 משפטים. הקפד לוודא שהתשובה מבוססת רק על הדעות שניתנו. מבחינה דקדוקית, נסח את הסיכום בגוף ראשון יחיד, כאילו אתה אחד הסטודנטים. כתוב את הסיכום בעברית בלבד, ללא תוספות לפני או אחרי הסיכום”
[<X>] above is the string of the question, that we are trying to summarize.
- User prompt was was a batch of students’ response (as in the example above)
Note that we required translation to Hebrew before summarization. Without this specification, the model occasionally responded in English or Arabic if the input contained a mix of languages.
[Interestingly, Dicta 2.0 was able to converse in Arabic as well. This is surprising because Dicta 2.0 was not trained on Arabic (according to its release post, it was trained on 50% English and 50% Hebrew), and its base model, Mistral, was not specifically trained on Arabic either.]
Re-group the Batches: The non-trivial final step involved re-summarizing the aggregated batches to produce a single cohesive summary per topic per question. This required meticulous prompt engineering to ensure relevant insights from each batch were accurately captured and effectively presented. By refining prompts, we guided the LLM to focus on key points, resulting in a comprehensive and insightful summary.
This multi-step approach allowed us to effectively manage the multilingual and nuanced dataset, extract significant insights, and provide actionable recommendations to enhance the educational experience at מדרסה (Madrasa).
Evaluation
Evaluating the summarization task typically involves manual scoring of the summary’s quality by humans. In our case, the task includes not only summarization but also business insights. Therefore, we require a summary that captures not only the average student’s response but also the edge cases and rare or radical insights from a small number of students.
To address these needs, we split the evaluation into the six steps mentioned and assess them manually with a business-oriented approach. If you have a more rigorous method for holistic evaluation of such a project, we would love to hear your ideas 🙂
Results — example
For instance, let’s look at one question from a questionnaire in the middle of a beginners’ course. The students were asked: “אנא שתף אותנו בהצעות לשיפור הקורס” (in English: “Please share with us suggestions for improving the course”).
Most students responded with positive feedback, but some provided specific suggestions. The variety of suggestions is vast, and using clustering (topic modeling) and summarization, we can derive impactful insights for the NGO’s management team.
Here is a plot of the topic clusters, presented using BERTopic visualization tools.
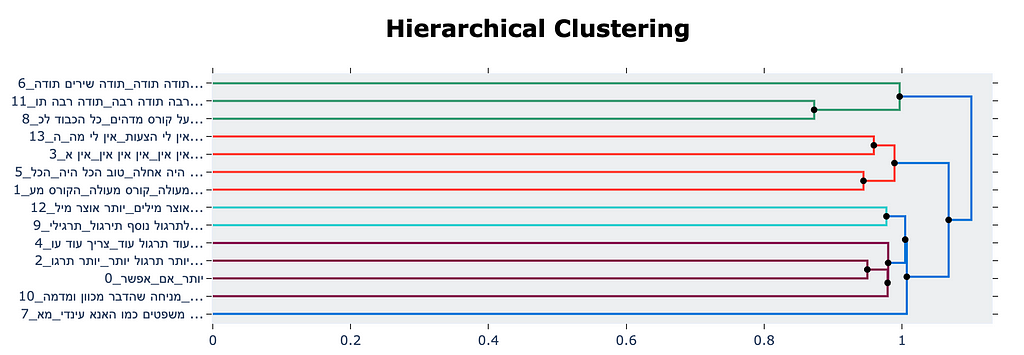
And finally, below are seven topics (out of 40) summarizing the students’ responses to the above question. Each topic includes its keywords (generated by the keyword prompt), three representative responses from the cluster (selected using Representation Model), and the final summarization.
Bottom line, note the variety of topics and the insightful summaries.

What next?
We have six steps in mind:
- Optimization: Experimenting with different architectures and hyperparameters.
- Robustness: Understanding and addressing unexpected sensitivity to certain hyperparameters.
- Hallucinations: Tackling hallucinations, particularly in small clusters/topics where the number of input sentences is limited, causing the model to generate ‘imaginary’ information.
- Enriching Summarizations: Using chain-of-thought techniques.
- Enriching Topic Modeling: Adding sentiment analysis before clustering. For example, if in a specific topic 95% of the responses were positive but 5% were very negative, it might be helpful to cluster based on both the topic and the sentiment in the sentence. This might help the summarizer avoid converging to the mean.
- Enhancing User Experience: Implementing RAG or LLM-explainability techniques. For instance, given a specific non-trivial insight, we want the user to click on the insight and trace back to the exact student’s response that led to the insight.
If you’re an LLM expert and would like to share your insights, we’d love to learn from you. Do you have suggestions for better models or approaches we should use? Ping us!
Want to learn more about Madarsa? https://madrasafree.com/

Keywords: NLP, Topic Modeling, LLM, Hebrew, Sentence Embedding , BERTopic, llama, NLTK, Dicta 2.0, Summarization, madrasa
Case-Study: Multilingual LLM for Questionnaire Summarization was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Case-Study: Multilingual LLM for Questionnaire Summarization
Go Here to Read this Fast! Case-Study: Multilingual LLM for Questionnaire Summarization