Misinformation and poor research: a case study
One cannot ignore the fact that AI models, such as ChatGPT, have taken over the internet, finding their way into every corner of it.
Most of AI’s applications are extremely useful and beneficial for a wide range of tasks (in healthcare, engineering, computer vision, education, etc) and there’s no reason why we shouldn’t invest our time and money in their development.
That’s not the case for Generative AI (GenAI), to which I’ll be specifically referring in this article. This includes LLMs and RAGs, such as ChatGPT, Claude, Gemini, Llama, and other models. It’s crucial to be very specific in what we call AI, what models we use, and their environmental impacts.
So, is AI taking over the world? Does it have an IQ of 120? Can it think faster and better than a human?
What is AI hype?
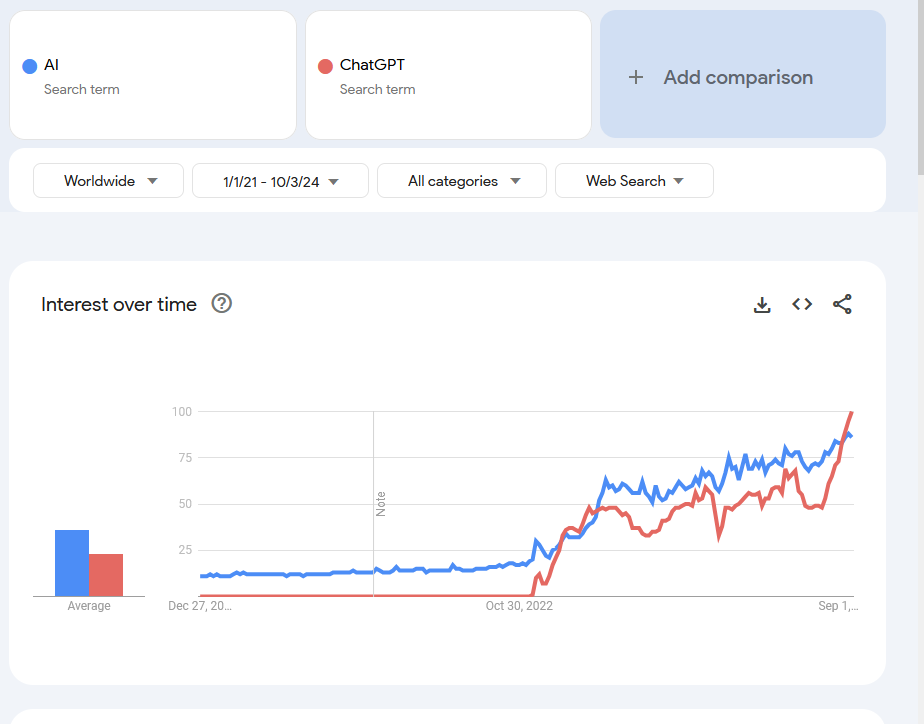
AI hype is the generalized societal excitement around AI, specifically, transformer (GPT-like) models. It has infiltrated every sector — healthcare, IT, economics, art — and every level of the production chain. In fact, a whopping 43% of executives and CEOs already use Generative AI to inform strategic decisions [2]. The following linked articles relate tech layoffs to AI usage in FAANG and other big companies [3, 4, 5].
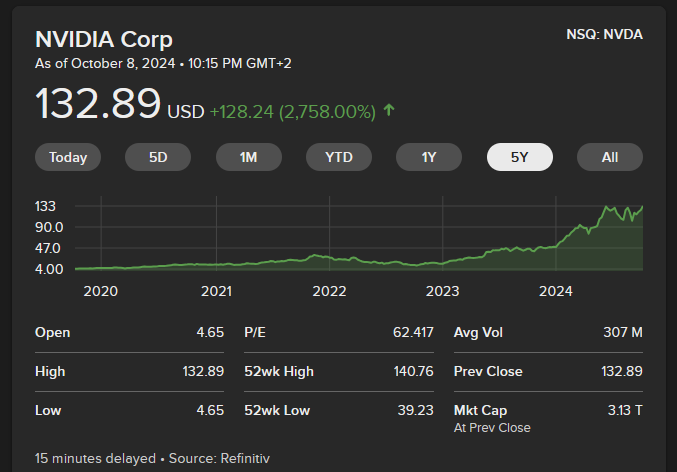
AI hype’s effects can also be seen in the stock martket. The case of NVIDIA Corp is a clear example of it: since NVIDIA produces key hardware components (GPU) to train AI models, their stock value has risen incredibly (and arguably not reflecting a real company’s growth, but more of a perceived importance).
Why is this a problem?
Humans have always been resistant to adopt new technologies, specially those which they don’t fully understand. It’s a scary steps to take. Every breakthrough feels like a “bet” against the unknown — and so we fear it. Most of us don’t switch over to the new thing until we’re sure its utility and safety justifies the risk. Well, that is until something upsets our instincts, something just as based in emotion as fear: hype.
Generative AI has a great deal of problems, most of them virtually unsolvable. A few examples are model hallucinations (how many r’s in strawberry? [6]), no auto-discrimination (models can’t tell wether they are doing a task correctly or not [7]) and others, like security vulnerabilities.

And, considering ethics…
When we take ethics into account, things don’t get any better. AI opens a vast array of cans of worms: copyright, privacy, environmental and economic issues. As a brief summary, to avoid exceeding this article’s extension:
AI is trained with stolen data: Most, if not the vast majority of content used for training is stolen. In the middle of our society’s reckoning with the limits of authorship protection and fair use, the panic ignited by IA coud do as much damage as its proper thievery. The Smithsonian [8], The Atlantic [9], IBM [10], and Nature [11] are all talking about it.
Perpetuation of economic inequalities: Proxy, very large and low-return investments made by the CEOs usually bounce back on the working class through massive layoffs, lower salaries, or worse working conditions. This perpetuates social and economic inequalities, and only serves the purpose of maintaining the AI hype bubble [12].
Contributing to the environmental crisis: Earth’s study [13], claims that ChatGPT-3 (175B parameters) used 700000 litres of freshwater for its training, and consumed half a litre of water per average conversation with a user. Linearly extrapolating the study, for ChatGPT-4 (around 1.8 trillion parameters), 7 million litres of water would have been used for the training, and 5 litres of water are being consumed per conversation.
The case study: an example of misinformation/ poor research
A recent study by Maxim Lott [14], titled (sic) “Massive Breakthrough in AI intelligence: OpenAI passes IQ 120 ” [15] and published in his 6000+ subscriber newsletter, showed promising results when evaluating AI with an IQ test. The new OpenAI o1 achieved 120 IQ score, leaving a huge gap between itself and the next models (Claude-3 Opus, GPT4 Omni and Claude-3.5 Sonnet, which scored just above 90 IQ each).
These are the averaged results of seven IQ tests. For context, an IQ of 120 would situate OpenAI among the top 10% of humans in terms of intelligence.
What’s the catch? Is this it? Have we already programmed a model (notably) smarter than the average human? Has the machine surpassed its creator?
The catch is, as always, the training set. Maxim Lott claims that the test questions were not in the training set, or that, at least, whether they were in there or not wasn’t relevant [15]. It is notable that when he evaluates the models with an allegedly private, unpublished (but calibrated) test, the IQ scores get absolutely demolished:
Why does this happen?
This happens because the models have the information in their training data set, and by searching the question they are being asked, they are able to get the results without having to “think” about them.
Think about it as if, before an exam, a human was given both the questions and the answers, and only needed to memorize each question-answer pair. You wouldn’t say they are intelligent for getting a 100%, right?
On top of that, the vision models perform terribly in both tests, with a calculated IQ between 50 and 67. Their scores are consistent with an agent answering at random, which in Mensa Norway’s test would result in 1 out of 6 questions being correct. Extrapolating from M. Lott’s observations and how actual tests like WAIS-IV work, if 25/35 is equivalent to an IQ of 120, then 17.5/35 would be equivalent to IQ 100, 9/35 would be just above 80 IQ, and choices at random (~6/35 correct) would score around 69–70 IQ.
Not only that, but most questions’ rationale seem, at best, significantly off or plain wrong. The models seem to find non-existent patterns, or generate pre-written, reused answers to justify their choices.
Furthermore, even while claiming that the test was offline-only, it seems that it was posted online for an undetermined number of hours. Quote, “I then created a survey consisting of his new questions, along with some Norway Mensa questions, and asked readers of this blog to take it. About 40 of you did. I then deleted the survey. That way, the questions have never been posted to the public internet accessed by search engines, etc, and they should be safe from AI training data.“ [15].
The author constantly contradicts himself, making ambiguous claims without actual proof to back them up, and presenting them as actual evidence.
So not only the questions were posted to the internet, but the test also included the older questions (the ones that were in the training data). We see here, again, contradictory statements by Lott.
Sadly, we don’t have a detailed breakdown of the questions results or proportions, separating them between old and new. The results would surely be interesting to see. Again, signs of incomplete research.
So yes, there is evidence that the questions were in the training data, and that none of the models really understand what they are doing or their own “thinking” process.
Further examples can be found in this article about AI and idea generation. Even though it, too, rides the hype wave, it shows how models are incapable of distinguishing between good or bad ideas, implying that they don’t understand the underlying concepts behind their tasks [7].
And what’s the problem with the results?
Following the scientific method, if a researcher got this results, the next logical step would be to accept that OpenAI has not made any significant breakthrough (or that if it has, it isn’t measurable using IQ tests). Instead, Lott doubles down on his “Massive breakthrough in AI” narrative. This is where the misinformation starts.
The impact of misinformation: a chain reaction
Let’s close the circle: how are these kinds of articles contributing to the AI hype bubble?
The article’s SEO [16] is very clever. Both the title and the thumbnail are incredibly misleading, which in turn make for very flashy tweets, Instagram and Linkedin posts. The miraculous scores on the IQ bell curve are just too good to ignore.
In this section, I’ll review afew examples of how the “piece of news” is being distributed along social media. Keep in mind that the embedded tweets might take a few seconds to load.
This tweet claims that the results are “according to the Norway Mensa IQ test”, which is untrue. The claims weren’t made by the test, they were made by a third party. Again, it states it as a fact, and later gives plausible deniability (“insane if true”). Let’s see the next one:
This tweet doesn’t budge and directly presents Lott’s study as factual (“AI is smarter than the average human now”). On top of that, only a screenshot of the first plot (questions-answers in the training data, inflated scores) is shown to the viewer, which is incredibly misleading.
This one is certainly misleading. Even if a sort of disclaimer was given, the information is incorrect. The latter test was NOT contamination free, since it reportedly contained online-available questions, and still showed terrible performance in the visual part of the test. There is no apparent trend that can be observed here.
Conclusion
Double, or even triple-checking the information we share is extremely important. While truth is an unattainable absolute, false or partially false information is very real. Hype, generalised societal emotion, or similar forces should not drive us to post carelessly, inadvertently contributing to keeping alive a movement that should have died years ago, and which is having such a negative economic and social impact.
More and more of what should be confined to the realm of emotion and ideas is affecting our market, with stock becoming more volatile each day. The case of the AI boom is just another example of how hype and misinformation are combined, and of how disastrous their effects can be.
Disclaimer: as always, replies are open for further discussion, and I encourage everyone to participate. Harassment and any kind of hate speech, either to the author of the original post, to third parties, or to myself, will not be tolerated. Any other form of discussion is more than welcome, wether it be constructive or harsh criticism. Research should always be able to be questioned and reviewed.
References
[1] Google Trends, visualization of “AI” and “ChatGPT” searches in the web since 2021. https://trends.google.com/trends/explore?date=2021-01-01%202024-10-03&q=AI,ChatGPT&hl=en
[2] IBM study in 2023 about CEOs and how they see and use AI in their business decisions. https://newsroom.ibm.com/2023-06-27-IBM-Study-CEOs-Embrace-Generative-AI-as-Productivity-Jumps-to-the-Top-of-their-Agendas
[3] CNN, AI in tech layoffs. https://edition.cnn.com/2023/07/04/tech/ai-tech-layoffs/index.html
[4] CNN, layoffs and investment in AI. https://edition.cnn.com/2024/01/13/tech/tech-layoffs-ai-investment/index.html
[5] Bloomberg, AI is driving more layoffs than companies want to admit. https://www.bloomberg.com/news/articles/2024-02-08/ai-is-driving-more-layoffs-than-companies-want-to-admit
[6] INC, how many rs in strawberry? This AI can’t tell you https://www.inc.com/kit-eaton/how-many-rs-in-strawberry-this-ai-cant-tell-you.html
[7] ArXiv, Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers. https://arxiv.org/abs/2409.04109
[8] Smithsonian, Are AI image generators stealing from artists? https://www.smithsonianmag.com/smart-news/are-ai-image-generators-stealing-from-artists-180981488/
[9] The Atlantic, Generative AI Can’t Cite Its Sources. https://www.theatlantic.com/technology/archive/2024/06/chatgpt-citations-rag/678796/
[10] IBM, topic on AI privacy https://www.ibm.com/think/topics/ai-privacy
[11] Nature, Intellectual property and data privacy: the hidden risks of AI. https://www.nature.com/articles/d41586-024-02838-z
[12] Springer, The mechanisms of AI hype and its planetary and social costs. https://link.springer.com/article/10.1007/s43681-024-00461-2
[13] Earth, Environmental Impact of ChatGPT-3 https://earth.org/environmental-impact-chatgpt/
[14] Twitter, user “maximlott”. https://x.com/maximlott
[15] Substack, Massive Breaktrhough in AI intelligence: OpenAI passes IQ 120. https://substack.com/home/post/p-148891210
[16] Moz, What is SEO? https://moz.com/learn/seo/what-is-seo
[17] Thairath tech innovation, tech companies, AI hallucination example https://www.thairath.co.th/money/tech_innovation/tech_companies/2814211
[18] Twitter, tweet 1 https://x.com/rowancheung/status/1835529620508016823
[19] Twitter, tweet 2 https://x.com/Greenbaumly/status/1837568393962025167
[20] Twitter, tweet 3 https://x.com/AISafetyMemes/status/1835339785419751496
Bursting the AI Hype Bubble Once and for All was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Bursting the AI Hype Bubble Once and for All
Go Here to Read this Fast! Bursting the AI Hype Bubble Once and for All