

FulFILL your dreams of having AI write repetitive reports for you. Find out how we built Fill.sg in 2 weeks at LAUNCH!
Table of Contents
- Introduction
- Problem statement
- Our Solution
- Prompts Behind Fill.sg
∘ Breakthrough in LLMs: Long-context models
∘ Our Prompting Approach
∘ Report Generation: Divide and Conquer - UI/UX Considerations for a User-Friendly GenAI Tool
∘ Building an inclusive AI tool
∘ Bespoke Interface for Editing and Reviewing - Post-Hackathon: Potential for Future Development
- Conclusion
- How to be a part of LAUNCH!
- Acknowledgments
Introduction
We are a team from the Ministry of Social and Family Development (MSF) and GovTech’s Data Science and AI Division. United by the cause of the problem statement to make report writing easier and less time consuming, we teamed up to build Fill.sg from ideation to prototyping. Within just two weeks, we conducted user discovery, built a prototype, and gathered preliminary user feedback to determine the feasibility of the solution. This article shares our journey through the first LAUNCH! Hackathon Sprint in April 2024 and our approach to developing the solution.
Problem statement
Background
When ChatGPT first debuted, it opened our eyes to the potential of an intelligent chatbot, far beyond anything we had seen before. This breakthrough sparked our imaginations, inspiring us to explore solutions to solve problems that gradually expanded from recipe creations to tough enterprise use cases across different domains and their business functions.
Similarly, there is a strong desire from agencies in the Singapore Government to leverage AI to better serve citizens and public servants. We have seen over 400 diverse ideas contributed in a short span of 12 months. These ideas stem from long-established pain points, and AI has opened possibilities to solve them. These pain points were diverse with their own unique challenges. At GovTech, we do our best to take a stab at as many problem statements within the periphery as possible — using the concept of ‘problem space’.
Why did we choose to tackle the problem space of report writing?
One key problem space that caught our attention was how we could support officers to draft reports in a more efficient manner. Writing reports is an integral part of our roles as public service officers — from simpler ones like meeting minutes to more complex ones like economic reports and court reports. While our intention was not to use AI to replace decision-making tasks requiring professional judgement and assessment, we saw potential in leveraging AI to synthesise and organise information for report writing. Complex reports can take hours, maybe days, and require synthesising myriads of information from various sources including graphs, texts, excel spreadsheets, etc. The same report type is usually written multiple times with the same format for different cases, which can start to get mundane very quickly. Certainly, a templating tool that can help draft even 50% of repetitive reports would be a substantial time saver for public officers, freeing up their time by allowing them to vet and amend reports to ensure accuracy rather than drafting them from scratch, so they may focus on more important tasks.
However, this is a difficult and complicated problem space — specifically, how do we abstract the methods to take in sources of information with various lengths, instruct Large Language Models (LLMs) to extract the crucial details, and generate relevant outputs? Each step is crucial to produce a quality report grounded with the right context.
With this in mind, we started our two-week journey of making report writing less onerous. Our goal was to relieve officers from time-consuming administrative tasks, so that they could focus on engaging and providing support to citizens.
Our Solution
Introducing Fill.sg and What It Offers

Fill.sg is a web application that helps you fulFILL your dreams of making report writing simpler, easier, and faster by having AI generate reports for you, so you can focus on more important tasks.
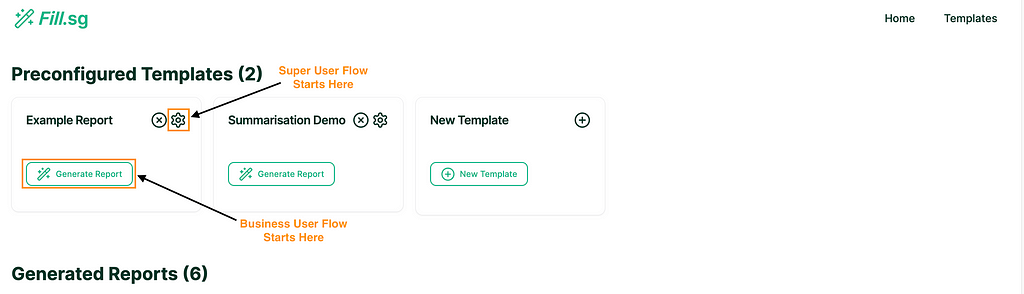
Business User Flow
Fill.sg provides an interface for business users to curate Modular and Versatile Templates for Generation of Structured Reports. In gist, users can select a previously defined Template, upload multiple unstructured or structured text documents as Context for the report, and voila, a full report can be generated without touching the keyboard. The report can even be exported to Microsoft Word with the formatting of headings and tables intact.
A single Template created in Fill.sg can be reused to generate multiple reports with the same structure. For instance, a Company Report Template can be reused for generating reports about Company A, B, C, and so on using different Context provided.

In the demonstration above, the user is able to upload documents and use those documents as Context to generate a report. The AI behind the scenes will take these Context documents and use them to generate a bespoke report based on the Template. Once generated, users can download it as a Word document (.docx), which preserves the headings and table formatting.
Super User Flow
Super users are users with both the technical and domain knowledge required to understand how to prompt the LLM correctly to fill in each section of the report Template. These super users play a crucial role for the success of the tool, as they have enough domain knowledge, and technical expertise on prompt engineering to instruct LLM in filling each section of the report Template.
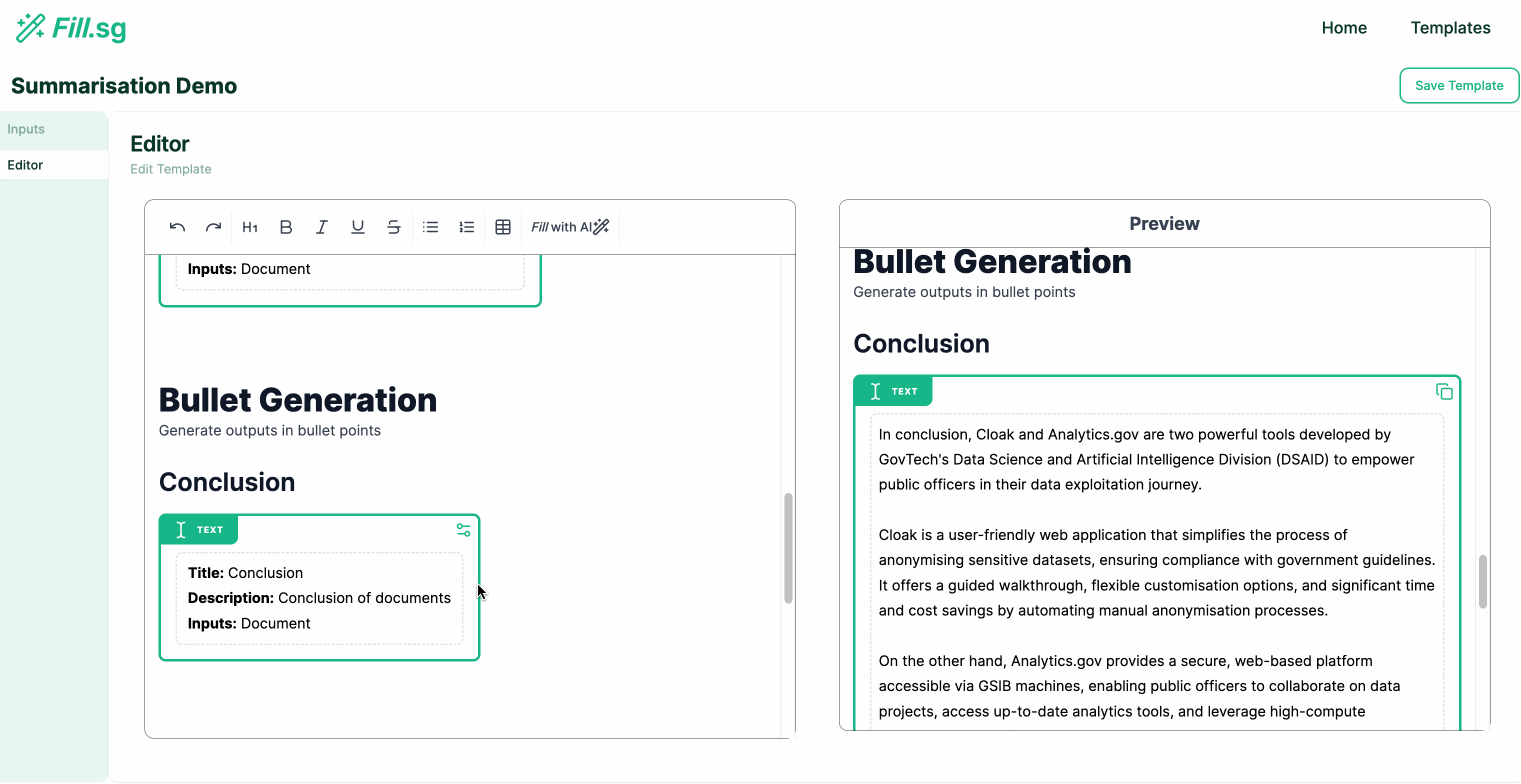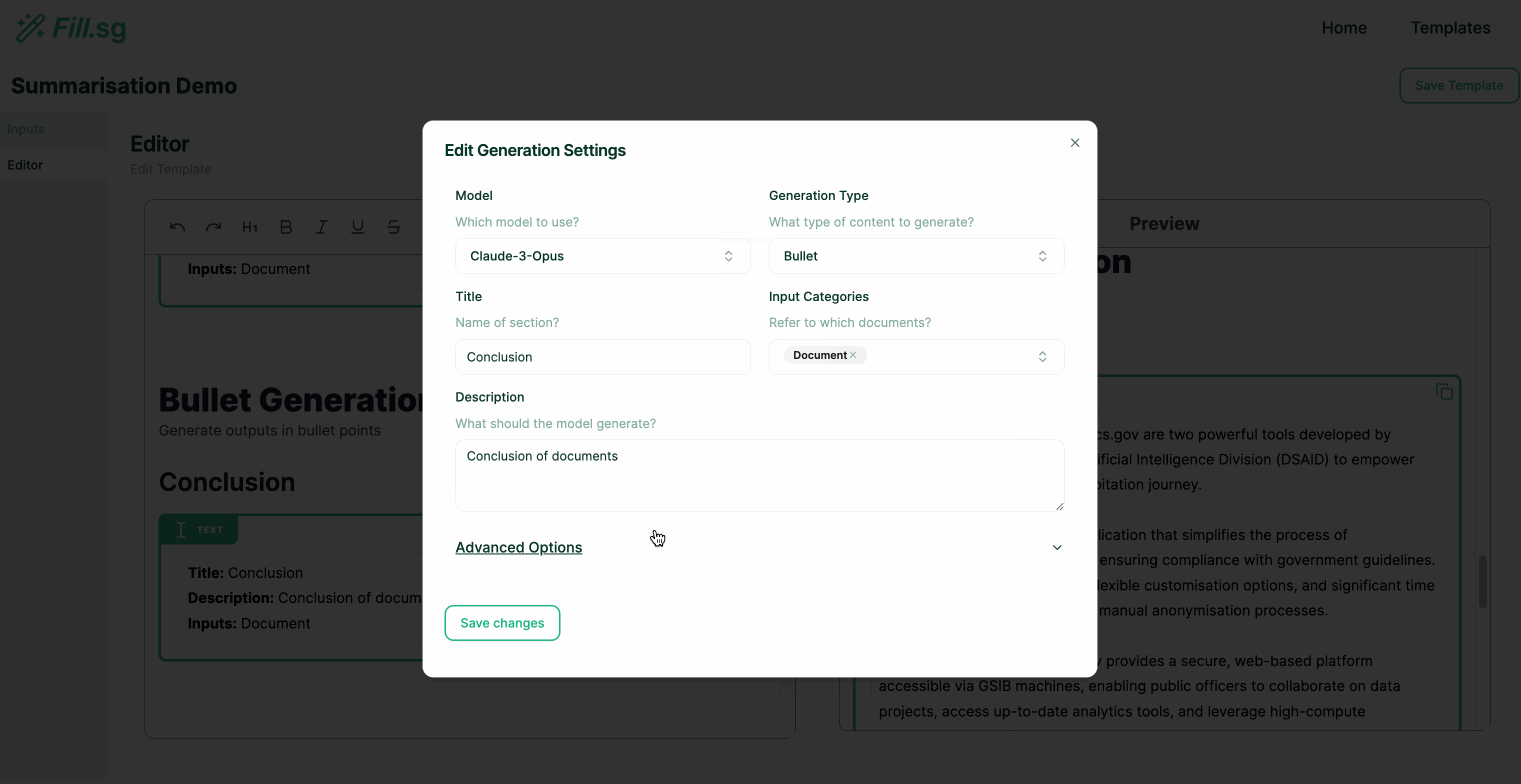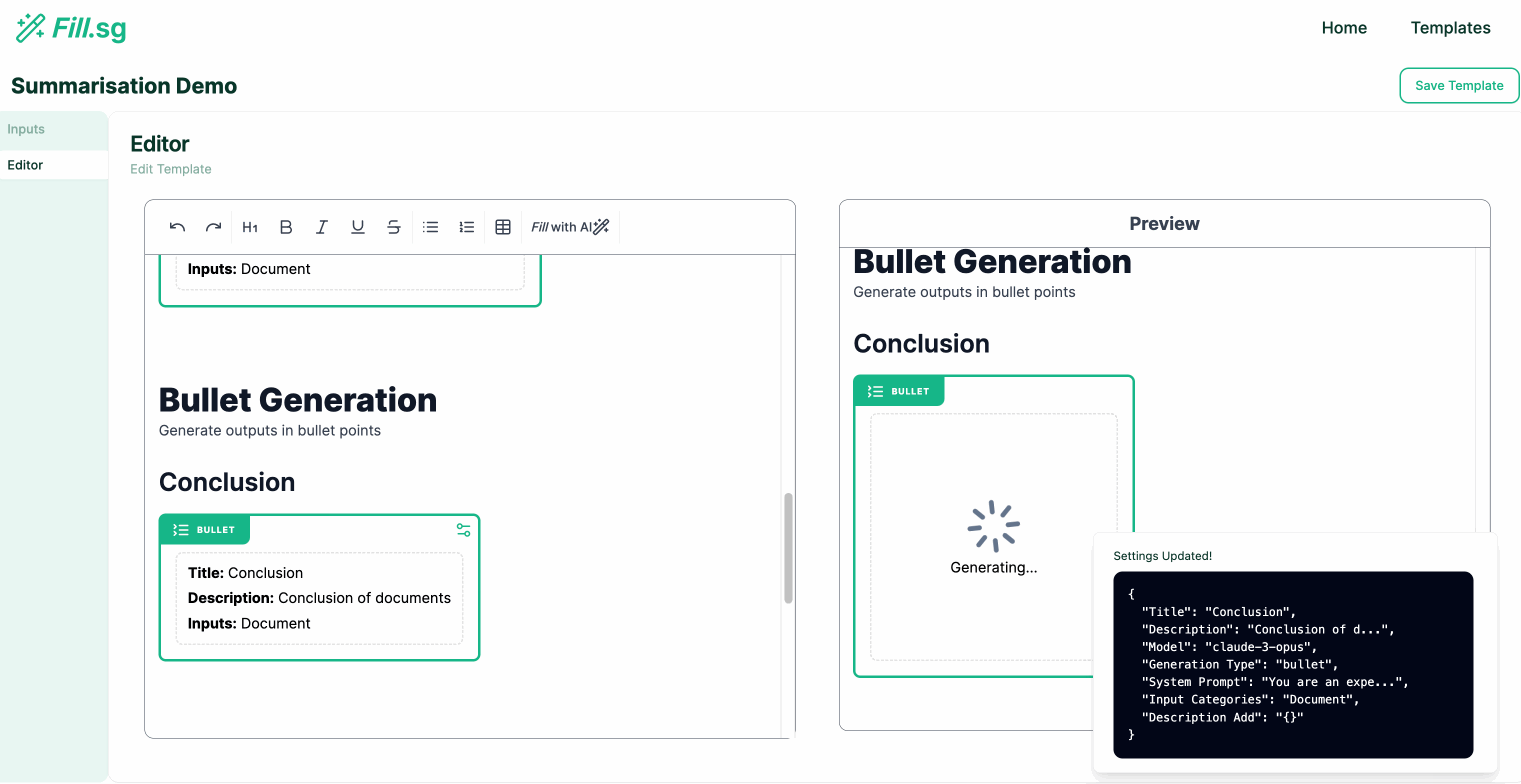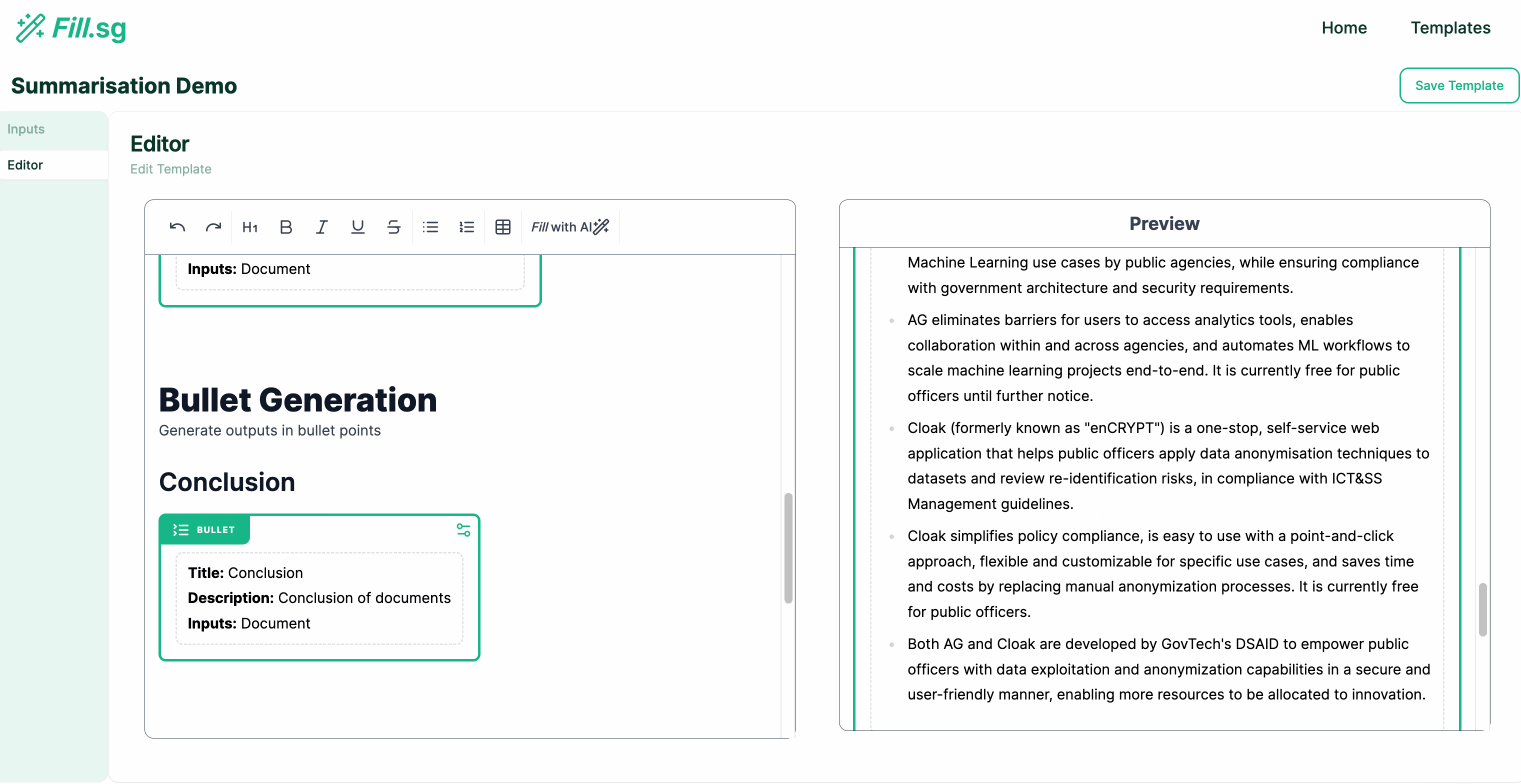
Super users can go into edit mode, where they can edit the structure of Templates and add new generation blocks. Each generation block is intended to fill up a particular section of a report. Once a Template is created and saved, business users will be able to use the curated template to generate multiple reports of the same structure.

In the above demo, the super user first uploads a set of example Context documents, which are used for previewing the template generation. They then go to the editor panel to edit the Template. For each new section of the report, the user adds a new generation block, where they are able to configure the generation settings and instruct the template on what should be generated for the section. Once the generation settings are saved, the LLM generates a sample result based on the example Context documents, and the super user is able to verify the preview of the generation. Once the super user is satisfied with the template, they can then save it and make it available for business users to use.
Having simple, modular, and editable templates allows agency users to be self-reliant when using the tool, as they can create and modify templates to adapt to ever-changing business needs.
Prompts Behind Fill.sg
Breakthrough in LLMs: Long-context models
In the past few months, the context window size of leading LLMs has been rapidly increasing. For example, OpenAI’s GPT-4-Turbo has a context window of 128,000 tokens, which is approximately 400% of its predecessor, GPT-4–32k. The term ‘context window’ refers to the number of tokens that the LLM can consider when generating a response.
Having a longer context window, therefore, means more information can be provided to the LLM via the prompt and is often indicative of the semantic capability of the LLM in managing more tokens.
This capability solves some of the teething challenges of an RAG workflow. Instead of optimising chunking, search, and retrieval strategies, we can use in-context prompting and instruct the LLM to take reference from relevant sources accordingly. For example, we could feed the entire input document(s) to the LLM, instruct it to focus on specific sections, and provide an output (whether it is in bullet points, a paragraph, or a table) based on the context that we had given an instruction to.
Our Prompting Approach
For this use case, we leverage this in our solution by feeding more relevant information, including entire documents, in the prompt. In our experimentations, this method has shown to be effective, based on the assumption that the input document(s) are relevant to each report.
Throughout the 2 weeks, we took an iterative prompt engineering approach to write, evaluate, and refine prompts:
- Write the initial prompt making use of system, user, and/or assistant roles when outlining the task definition and context needed to serve as a starting point.
- Evaluate the LLM’s responses against expected outputs using consistent success criteria, whether through human evaluation or self-evaluation like in the LLM-as-a-Judge approach.
- Based on the evaluation results, refine the prompt to improve the performance such as by adding clarifications or constraints in steering the LLM’s responses
Our crucial success criteria in evaluation is the ability to generalise across various report sections and formats, in order to allow the generation of paragraphs, tables, bullet points, and even constrained choices to meet the needs of a typical report.
The prompts that we have crafted serve as the base to abstract away the challenges in prompt engineering and allow for domain-specific inputs from our end-users. This means users of Fill.sg simply focus on providing domain-specific information such as the title and description of a particular report section instead of worrying about the nitty-gritty of prompt engineering.
Report Generation: Divide and Conquer
Problems with Single Prompt Generation
For anyone who has attempted to generate a full report using a single prompt with an LLM, you would know that it usually does not turn out too well; outputs tend to be short, and hallucinations start to pop up after the third paragraph, and the later sections where you explicitly required tables are instead populated by walls of text.
This happens because LLMs generally are not trained for generating extremely long reports requiring multiple formats, i.e., tables, texts, or bullet points within a single response. We have seen LLMs perform better when asked to perform one task and one type of output at a time, not multiple tasks at once and certainly not different formats within the same output.
Smaller but Many Modular Prompts can be Advantageous
In software engineering, it is good practice to decompose complex systems into modular components. We found this principle to be equally effective when applied to tasks given to a LLM.
To ameliorate the issues with instructing the LLM to generate a full report within a single prompt, we studied closely how reports are written to see how we can decompose this complex task. We observed a trend — most standard reports tend to have sections where each section describes a specific topic and usually consists of a single format. This can be used to our advantage as we can break down the complex task of writing a full report into individual, smaller tasks — to write specific sections with specific output expectations.
Task decomposition via a section-level generation can help the model produce better outputs as each section can be assigned as single tasks, and localised context can be injected into the prompt for each section to give clearer instructions for the LLM to better understand its objectives. Furthermore, we can specify expected types for each generated section, which allows us to steer the generation and validate output formats more effectively.
Besides the benefits of structured modular prompts in generating higher quality content, the power of modular prompting also lies in allowing easy writing, modification and debugging. Not only does modular prompting help to provide clearer and better instructions to the LLM, it also helps developers in the iterative development of prompts.
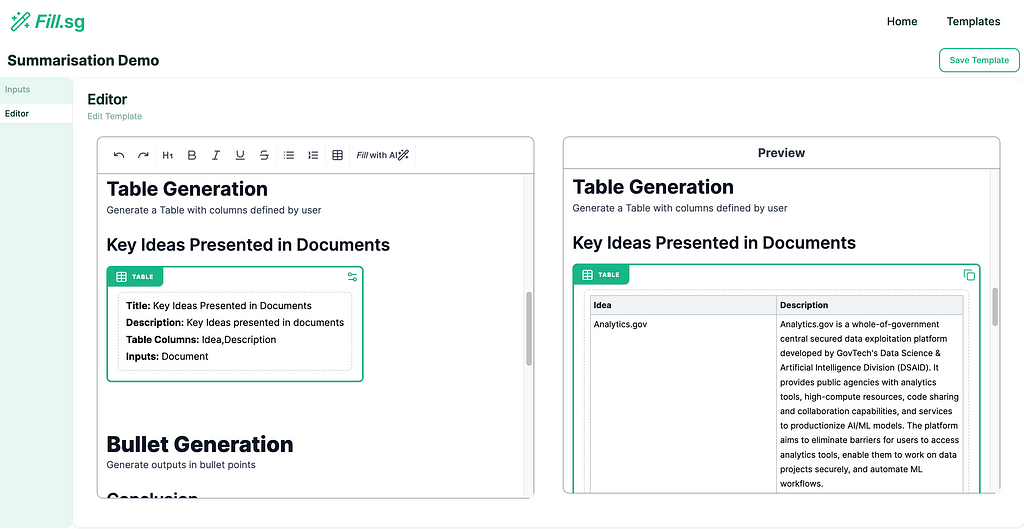
Generations Blocks and Generation Types
In our application, we term these sections where each generation task occurs as Generation Blocks. These Generation Blocks are set with a specific generation type so that we can enforce certain constraints on the outputs generated by the model.
In our case, we settled on a few generation types to implement for the hackathon:
- Long Text Generation: Long paragraphs of text
- Table Generation: Outputs in tabular formats with columns specified by settings
- Bullet Points Generation: Output generated in Bullet Point form
- Selection Generation: Outputs the most suitable value chosen from a pre-set list of values defined by the user
The following are demos for each Generation Type. As seen below, the app allows users to edit contents easily with pre-configured settings based on the requirements of the report.
Long Text Generation
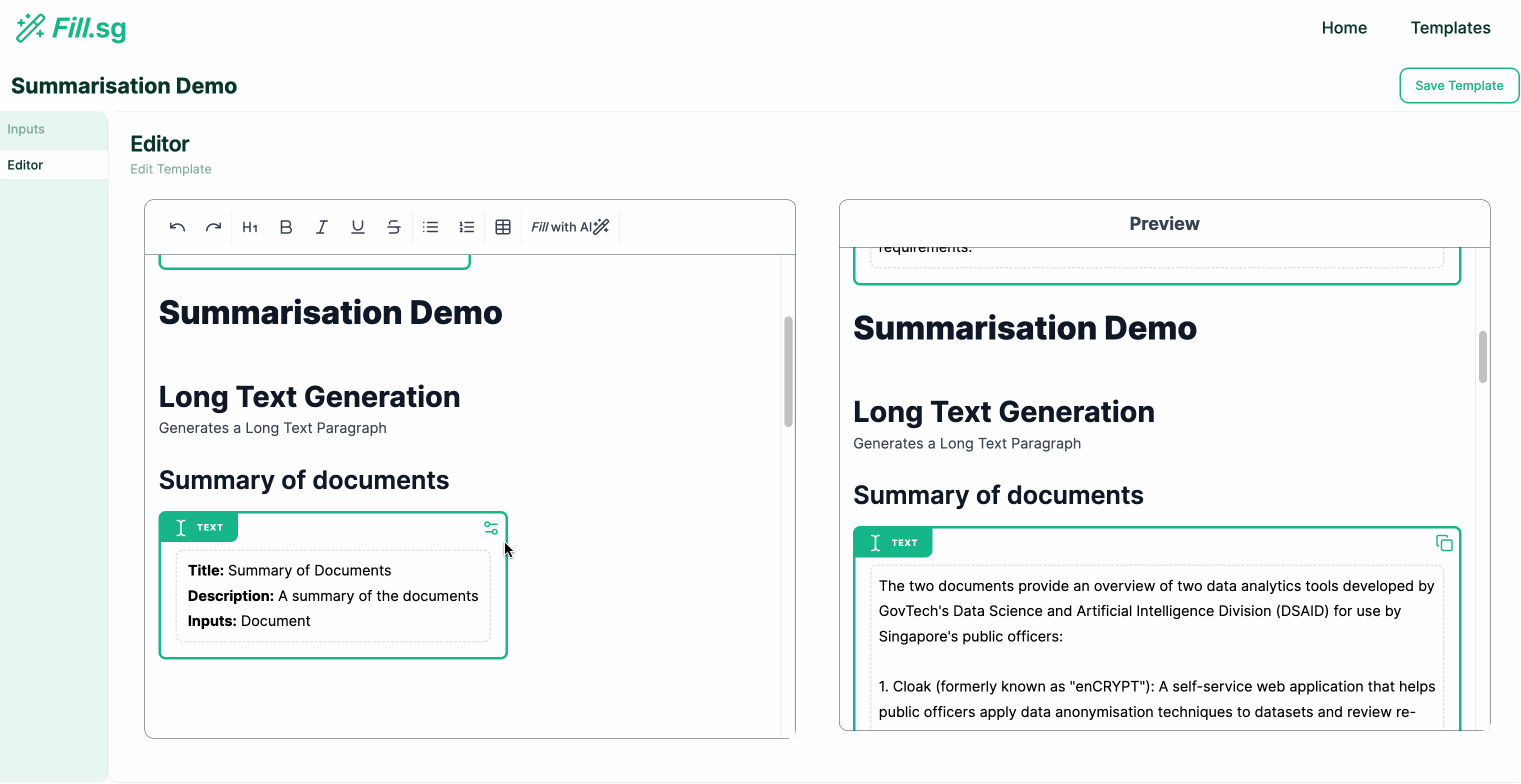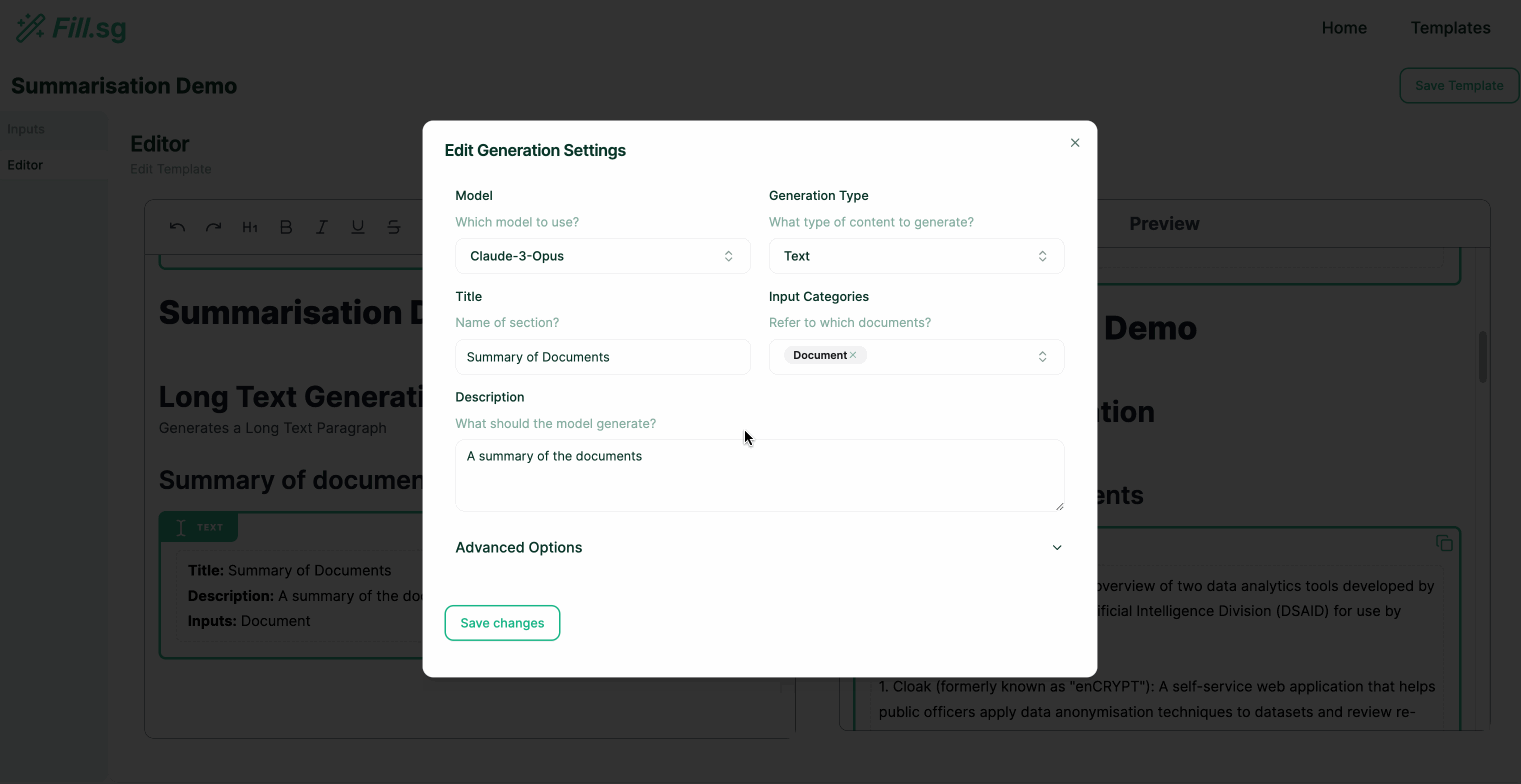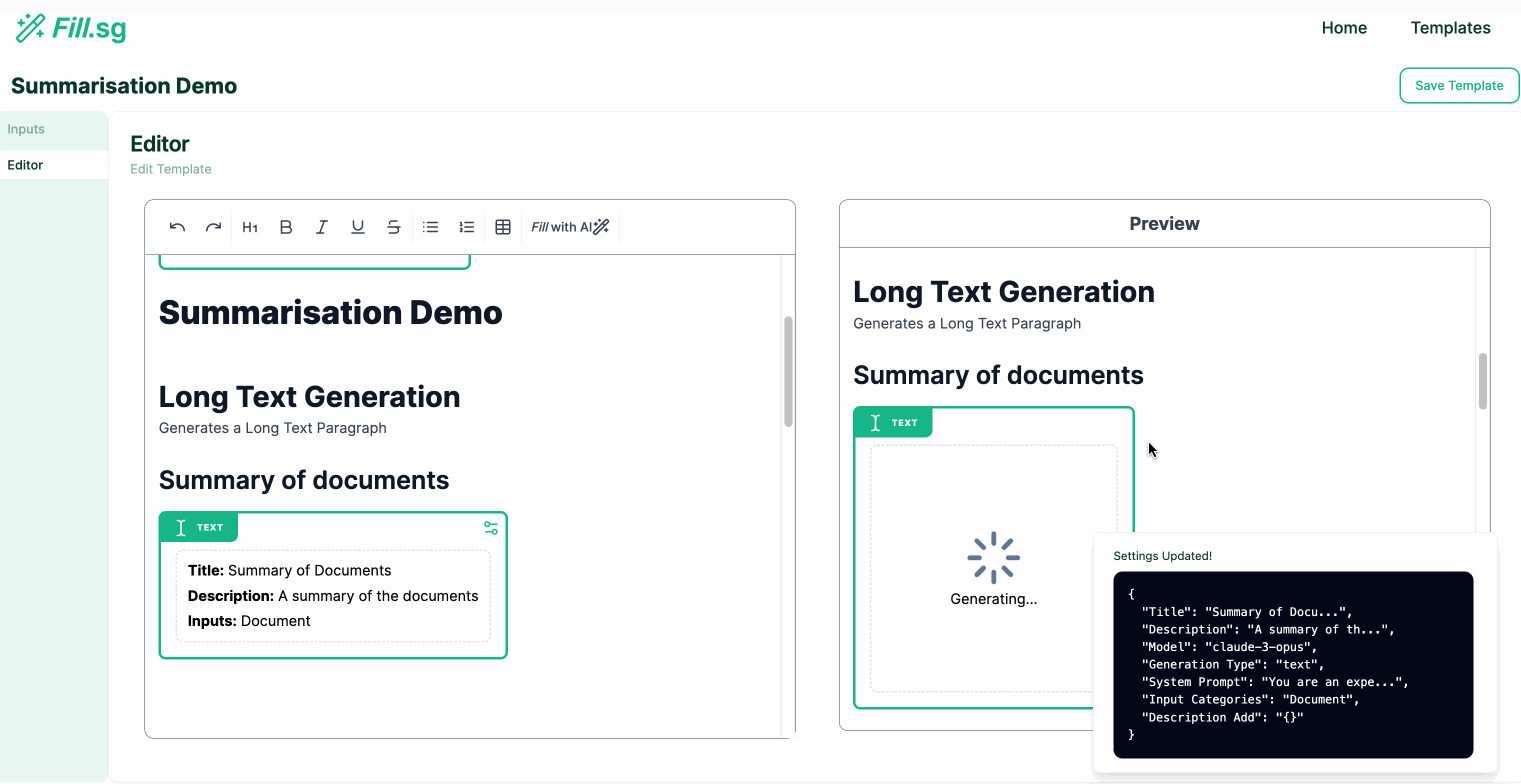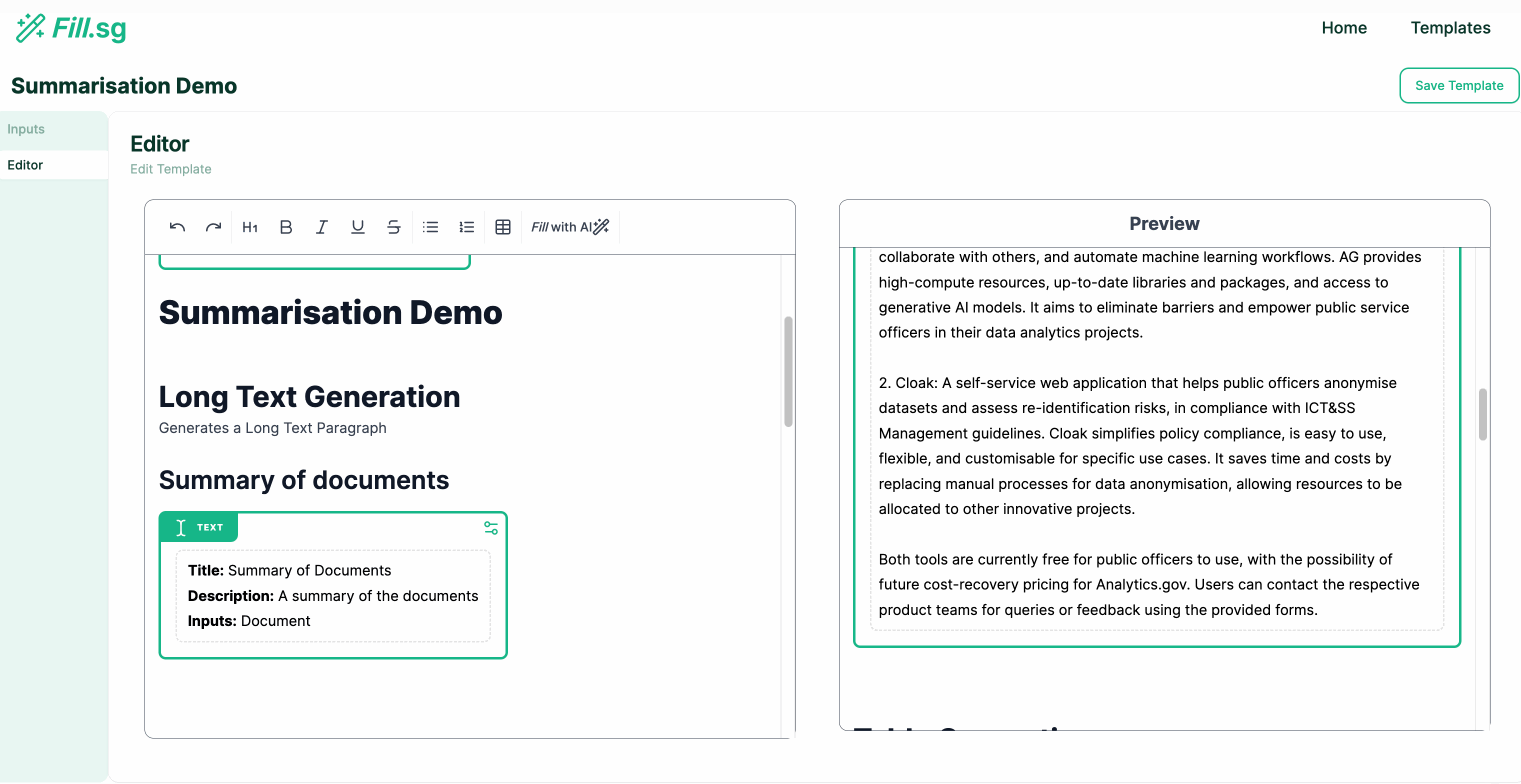
Table Generation
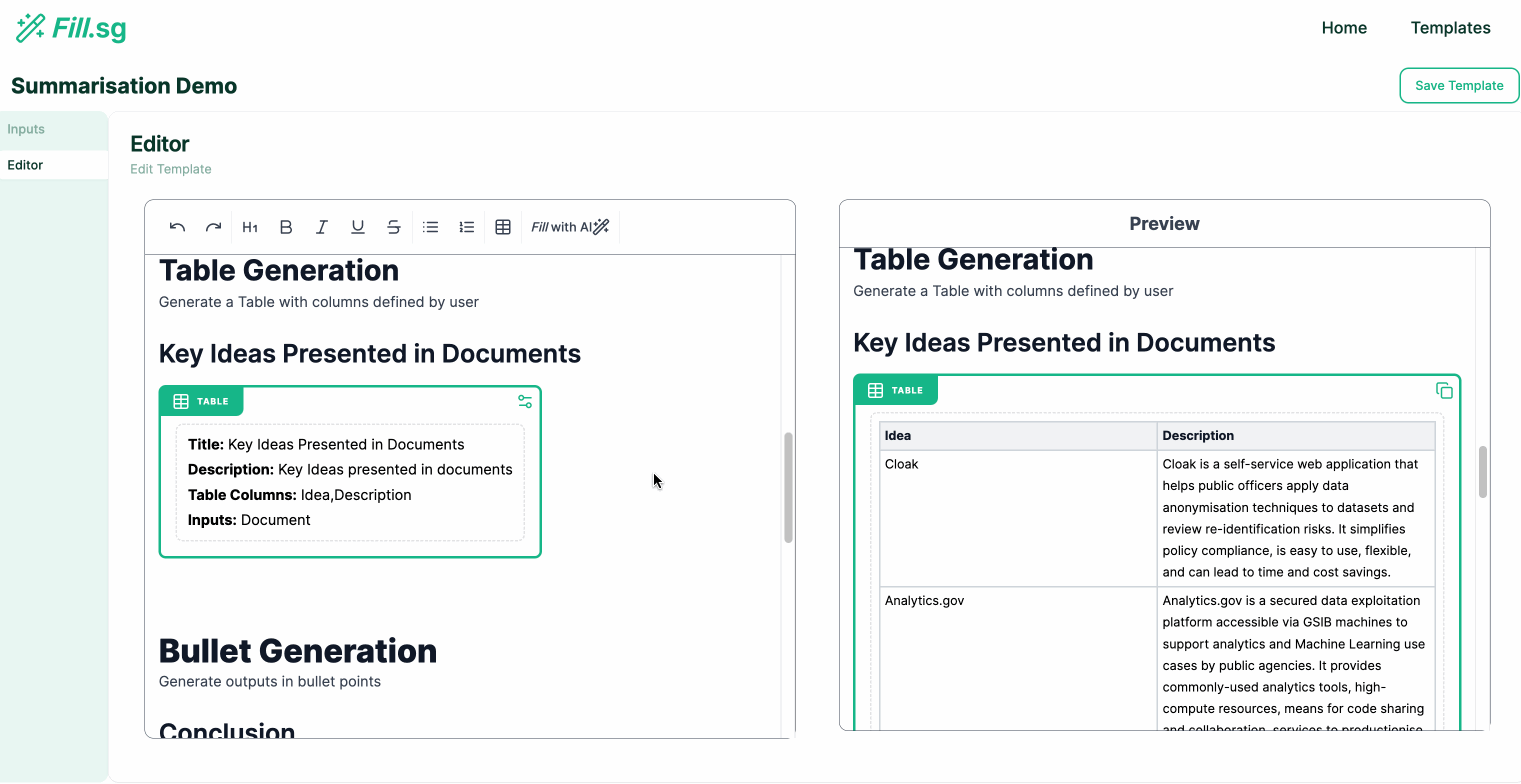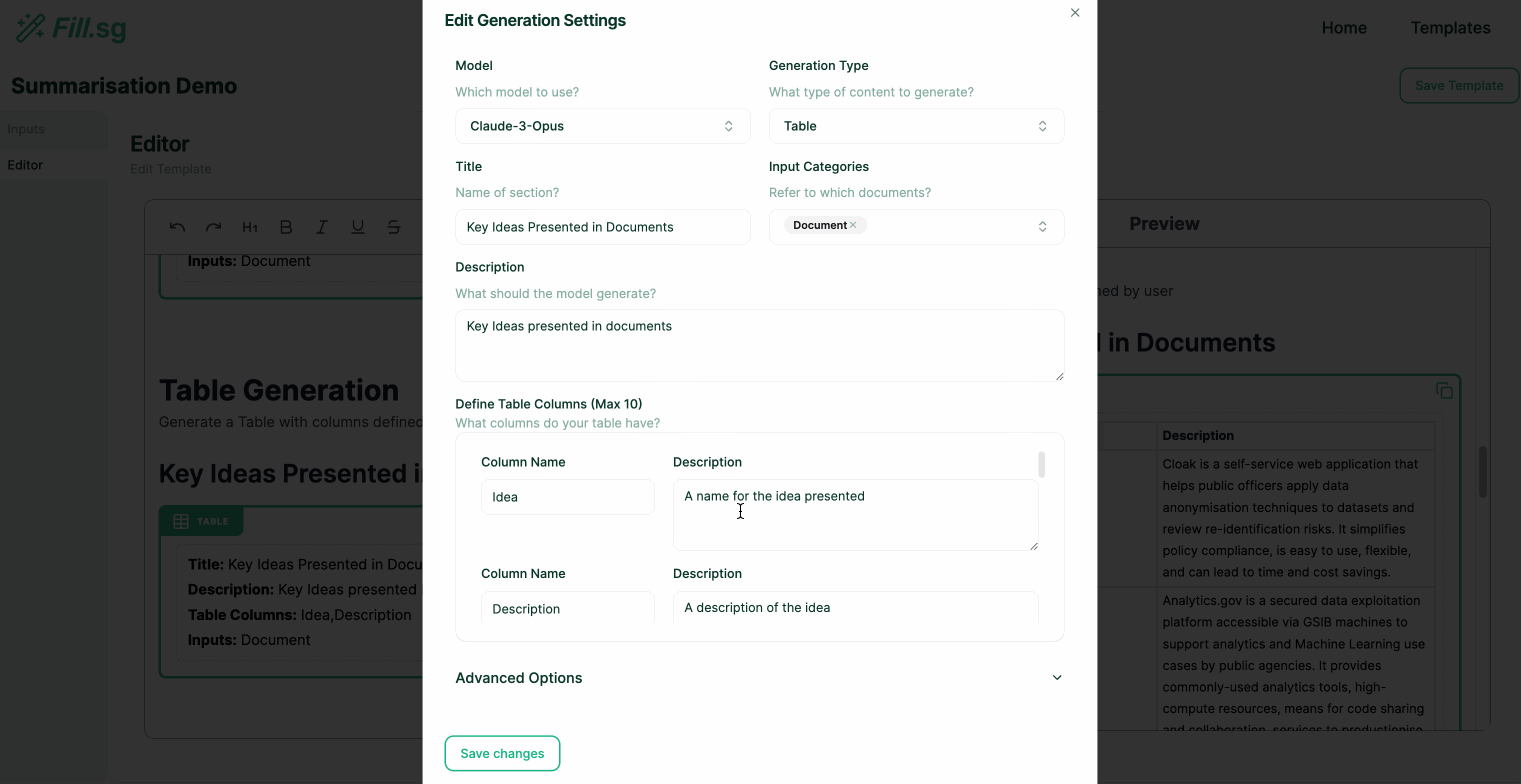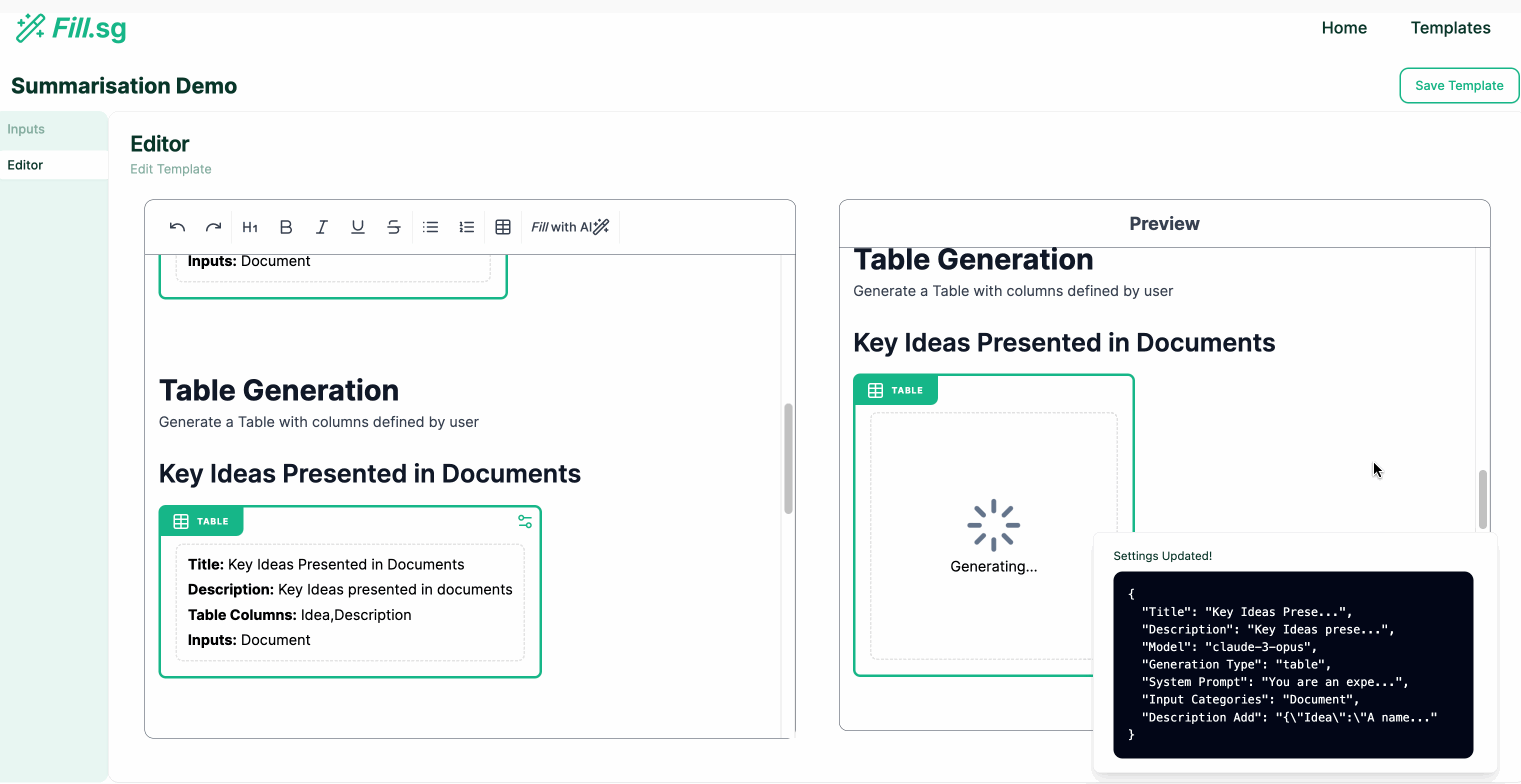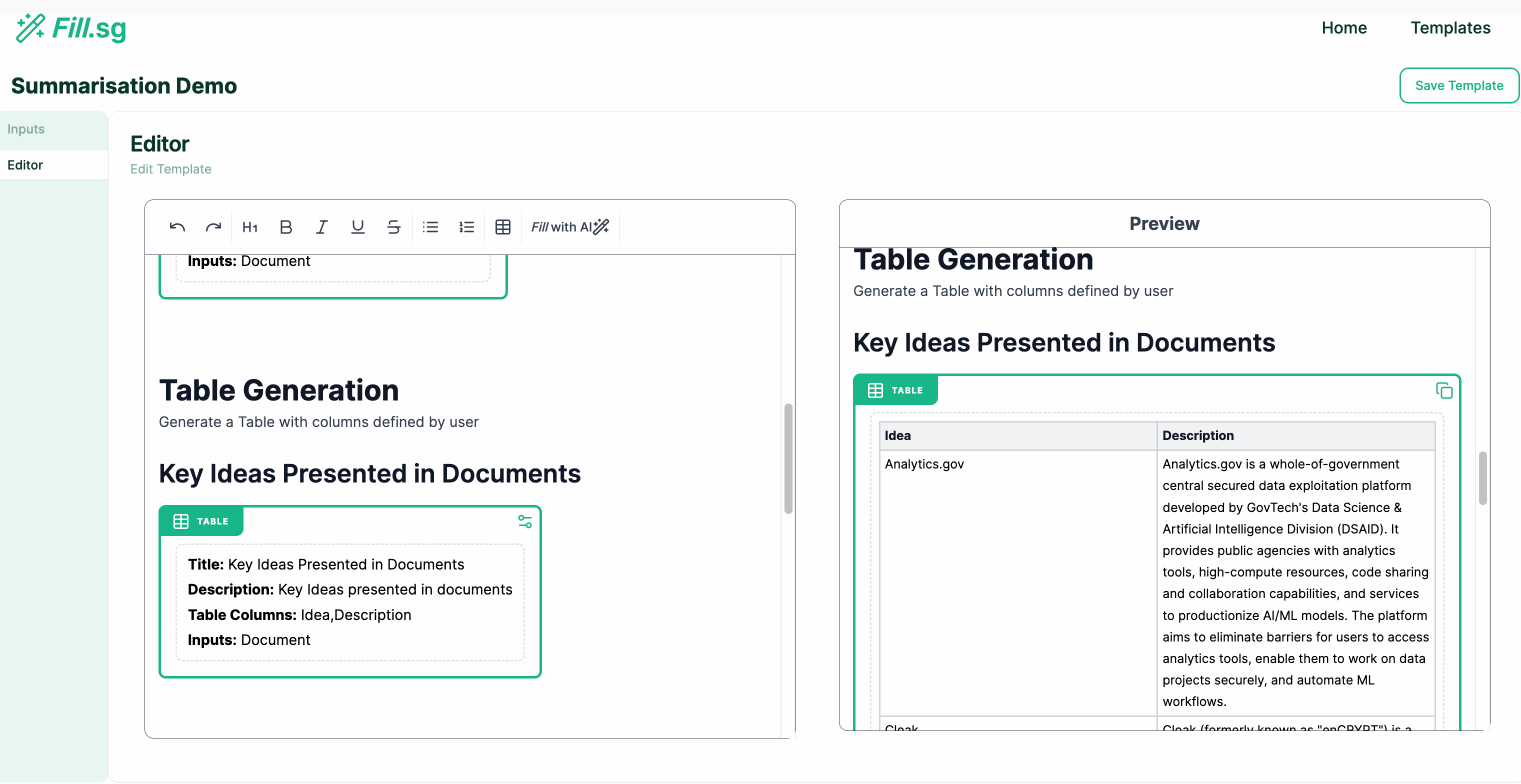
Bullet Points Generation
Selection Generation
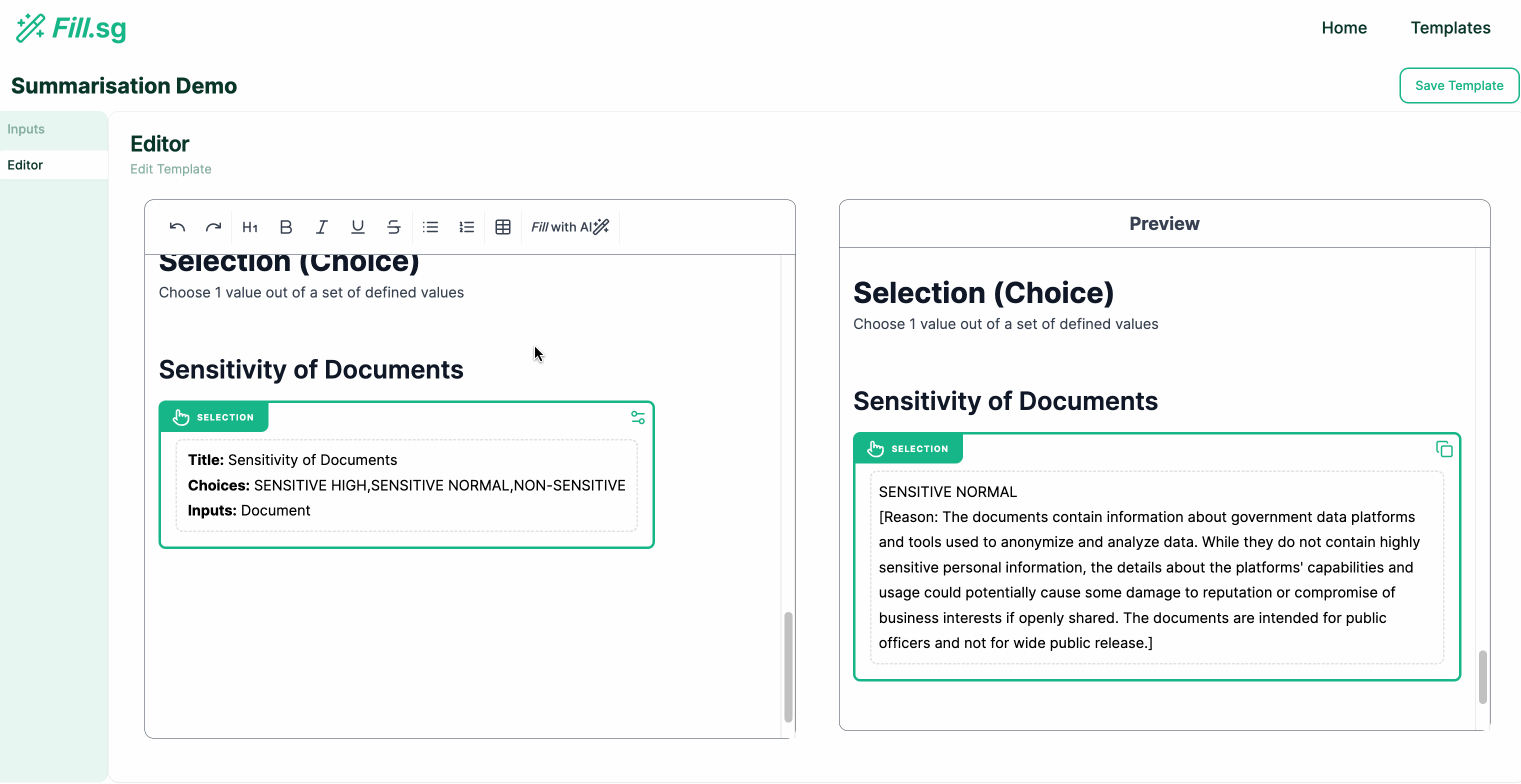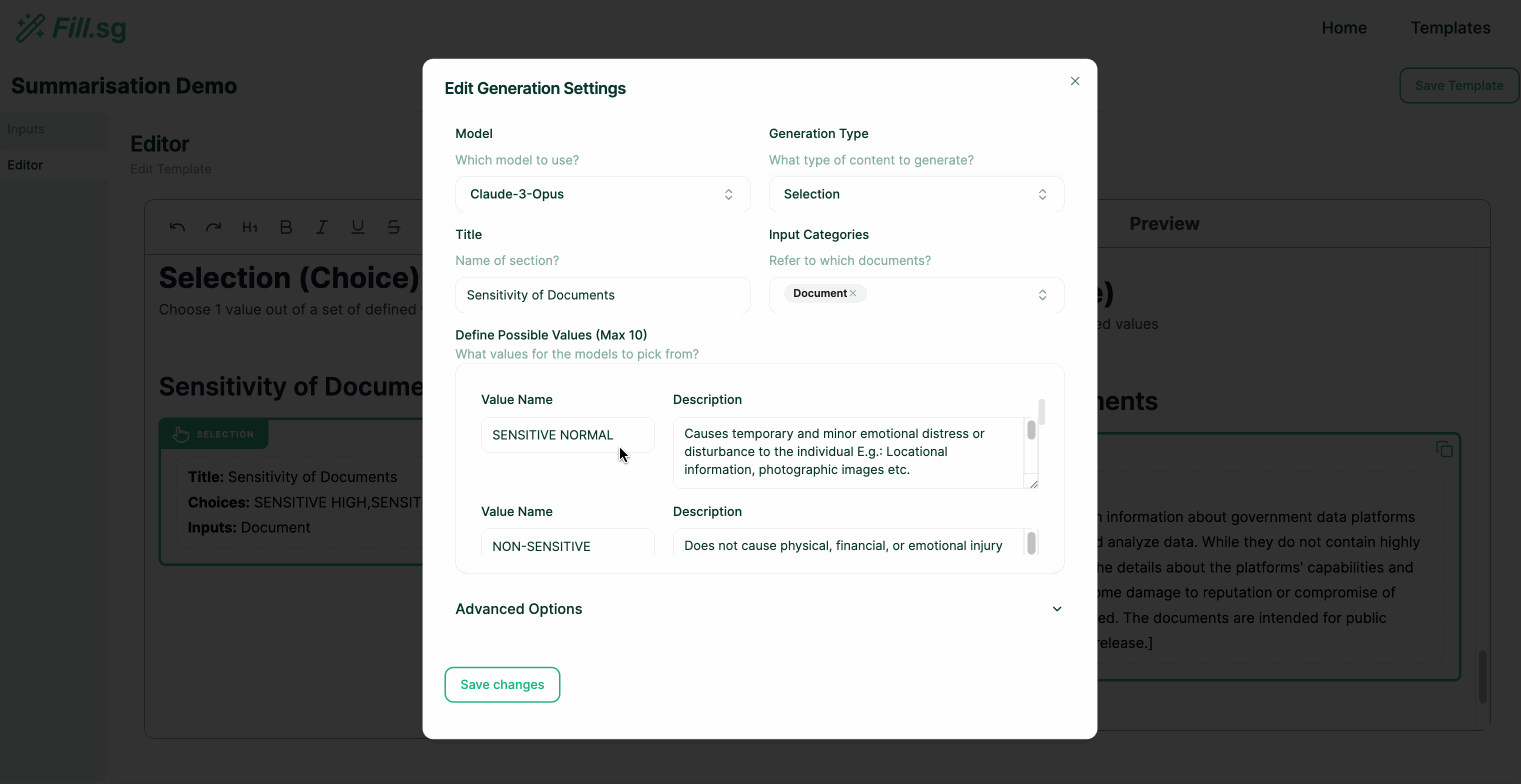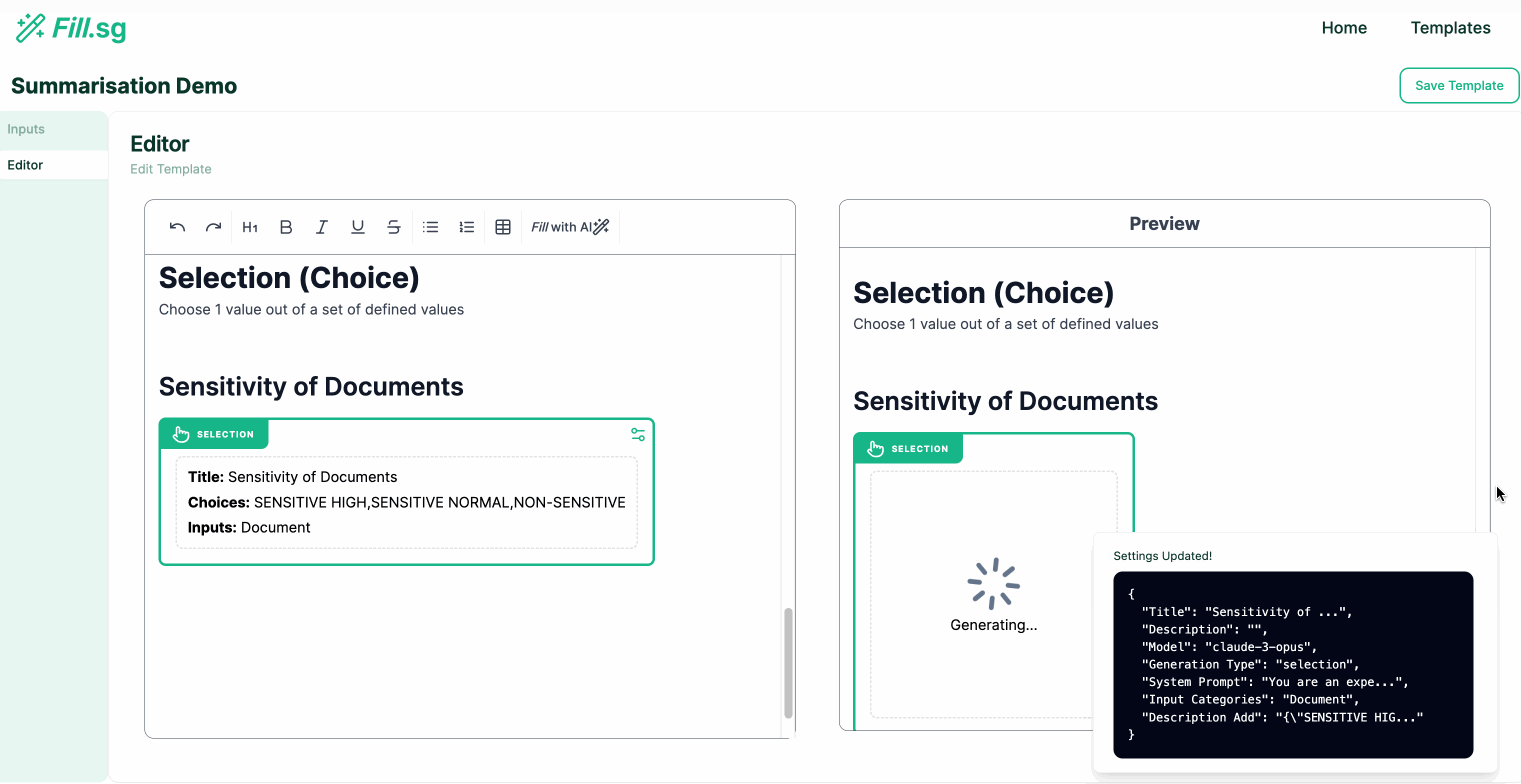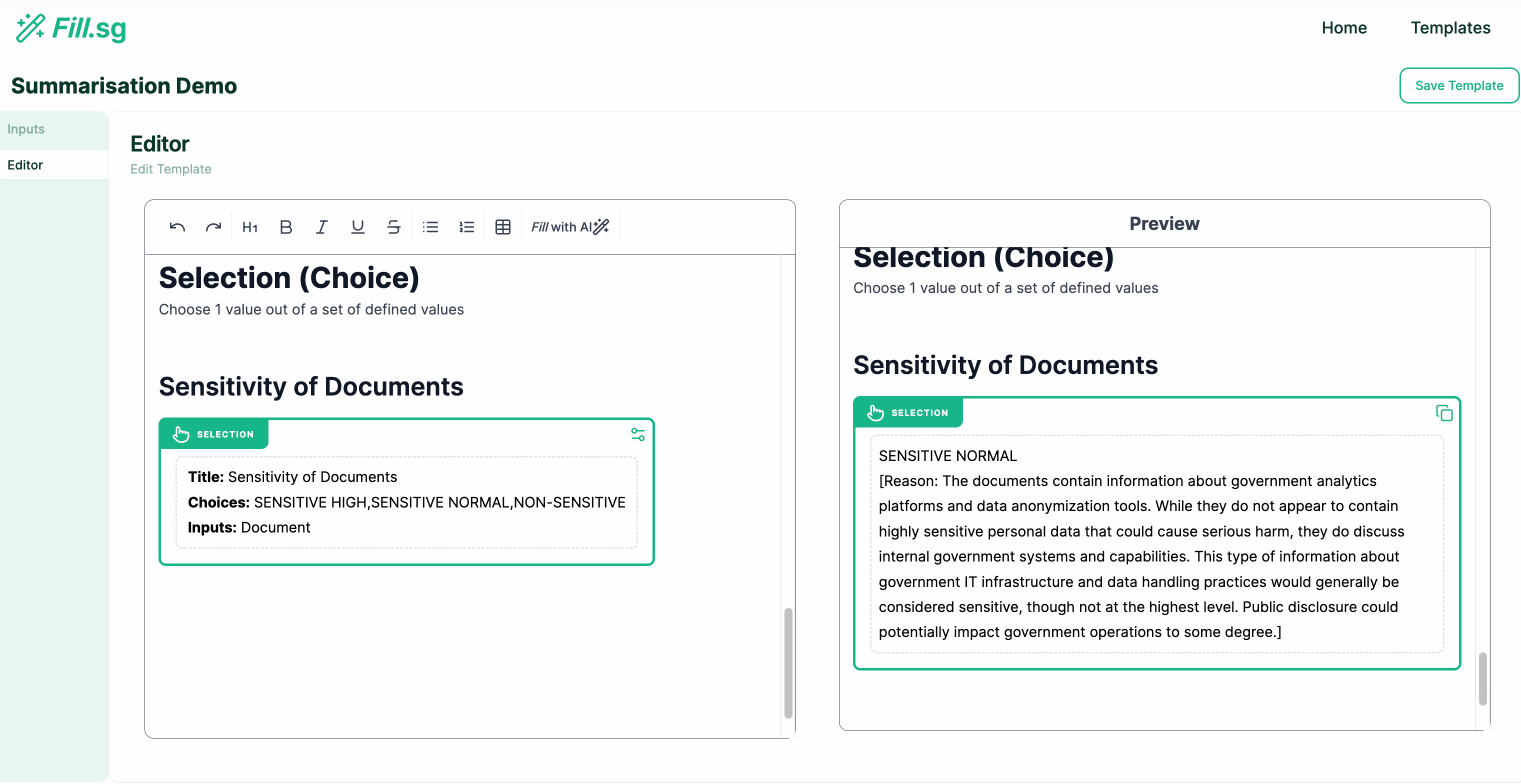
UI/UX Considerations for a User-Friendly GenAI Tool
Building an inclusive AI tool
One of the most important lessons happened during our first user interview. We received good feedback from the super users who were able to follow through with our initial proposed flow of customising templates very quickly. As we presented the ideas, they were also coming up with new ideas on how to improve the tool. However, we noticed that business users would much prefer to get their jobs of churning out reports done easily, without the need to customise any templates.
This taught us that even though technology may be powerful enough to solve the problem, we need to design a tool for users with different backgrounds and technical affinity to AI. So, we iterated Fill.sg and built it with 2 personas in mind — Super Users and Business Users.
Bespoke Interface for Editing and Reviewing
The purpose of Fill.sg is to reduce the time needed to write reports while balancing the need to ensure the responsibility of users in using any content created. So, we want to retain the mechanisms for users to have control within the workflow. Users need to ensure the AI-generated content is dutifully reviewed and checked for mistakes. Hence, with AI safety in mind, we made the editing and reviewing experience as smooth as possible. We furnished the application with a proper WYSIWYG editor, Tiptap, to provide a bespoke Graphical User Interface to interact with the AI in a more human-friendly way.
With the current available tools, users will typically use a chat interface for report writing. There are several pain points from this experience:
- The sequential format makes it hard to prompt the LLM in parallel, meaning users have to wait for an output before sending the next query.
- A great deal of copy-pasting is required between the chat interface and the actual document.
- Users are unable to reuse previous chats to generate the same structured reports.
Using an editor interface rather than a linear chat interface is beneficial as it solves all the aforementioned problems of the standard method.
- Having a side-by-side Editor and Preview panel allows users to continuously edit the templates while the LLM generates the preview in parallel in the background. This means users do not need to wait for the LLM generation to continue editing the template.
- Copy-pasting is no longer needed as the WYSIWYG editor can be directly exported to Word with the right setup. Users can edit directly in our application, then export the report directly to Word.
- Report Templates can be saved and later reused by many downstream reports.
Tiptap is an excellent choice for this as it provides a multitude of quality-of-life features that we can make available to users to improve the user experience. Thus, reducing pain in curating and reading structured reports. Furthermore, it also opens up space for new improvements, such as providing multi-user collaboration and further customisations to improve the reading and writing experience.
Post-Hackathon: Potential for Future Development
Multimodal Inputs
At the time of writing, OpenAI recently released a series of exciting announcements on new models. In a 26-minute demonstration, OpenAI showed off GPT-4o (“o” for “omni”), which is a step towards much more natural human-computer interaction. This model accepts any combination of text, audio, image, and video as inputs and generates any combination of text, audio, and image as outputs. Crucially, since our approach on this use case is through in-context prompting, the enhanced tokeniser’s compression requires fewer tokens to process the same amount of information.
This is particularly exciting for our use case. As we know, writing reports requires a person to synthesise different inputs such as text, images/infographics, charts, and interview scripts. There were some limitations to LLMs on their context window, token limits, and format of inputs, which made building a generic solution for report writing a particularly difficult engineering feat.
Extension to Generation Types
While the basic Generation Types we have defined are quite substantial and can cater to most repetitive reports, there are still even more ways that the report writing process can be automated and even empowered. We also thought of other generation types that could potentially be implemented:
- Chart Generation: Outputs a chart using a function caller agent
- DataTable Generation: Outputs a data table with a specific aggregation
- Temporal Generation: Outputs a date, time, or duration
- Graph Generation: Outputs a graph that plots out relationships based on given context
These new extensions not only solve current-day report generation problems but could also potentially supercharge and change the way we write reports.
Conclusion
Through the LAUNCH! Hackathon, we developed Fill.sg — a web application powered by large language models to automate report writing. By allowing users to create reusable templates and generate reports from unstructured data sources, Fill.sg saves substantial time and effort for all report-writing public officers.
AI is advancing fast, but business logic is harder to change as it involves policy considerations. Given this, the general direction for this application would be to retain the business logic and user needs while building a flexible infrastructure and frontend experience that allows it to include possibilities from more powerful AI models and their peripheral tools.
Looking ahead, Fill.sg may take advantage of new developments in multimodal AI that can understand inputs beyond just text, such as images, audio, and video, potentially elevating the tool’s capabilities to unimaginable magnitudes.
Fill.sg represents a small step to achieve our ambitions of leveraging AI to generate our reports. We hope that our learnings and experiences from this prototype will encourage other enterprising developers in government to develop and integrate AI to better serve public officers and citizens.
How to be a part of LAUNCH!
LAUNCH! Is an innovation programme designed to transform great ideas into impactful solutions for the public sector. Spearheaded by GovTech in collaboration with various government agencies and esteemed industry partners like Microsoft, Amazon Web Services (AWS), and Databricks, LAUNCH! is a movement towards fostering a culture of innovation and collaboration across the public sector. Interested public officers may connect with the organisers at LAUNCH! to find out more about contributing an idea or running a localised hackathon within your team, division, function, or organisation. You may access the info site on LAUNCH! via https://go.gov.sg/govtech-launch.
Acknowledgments
A huge thank you to the Hackathon team who powered through the fulfilling 2 weeks: Chan Li Shing (Product Manager), Gawain Yeo (Business Owner), James Teo (Data Engineer) and Nicole Ren (Data Engineer) as well as our Users who have provided valuable feedback!
Special thanks to the following persons who has contributed to the article: Alexia Lee (MSF) | Chan Li Shing (GovTech) | Gawain Yeo (MSF) | James Teo (GovTech) | Lim Hock Chuan (GovTech) | Mindy Lim (GovTech) | Nicole Ren (GovTech) | Terrance Goh (MSF)
Building Fill.sg, a GenAI Report Toolkit was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Building Fill.sg, a GenAI Report Toolkit
Go Here to Read this Fast! Building Fill.sg, a GenAI Report Toolkit