

Say goodbye to paid customer insights hubs! Learn how to combine five open-source AI models to automate insights gathering from your user interviews.
As a technical product manager for a data platform, I frequently run user interviews to identify challenges associated with data development processes.
However, when exploring a new problem area with users, I can easily become overwhelmed by the numerous conversations I have with various individuals across the organization.
Over time, I have adopted a systematic approach to address this challenge. I focus on taking comprehensive notes during each interview and then revisit them. This allows me to consolidate my understanding and identify user discussion patterns.
However, dividing my attention between note-taking and active listening often compromised the quality of my conversations. I noticed that when someone else took notes for me, my interviews significantly improved. This allowed me to fully engage with the interviewees, concentrate solely on what they were saying, and have more meaningful and productive interactions.
To be more efficient, I transitioned from taking notes during meetings to recording and transcribing them whenever the functionality was available. This significantly reduced the number of interviews I needed to conduct, as I could gain more insights from fewer conversations. However, this change required me to invest time reviewing transcriptions and watching videos. The figure below shows what became a simplified flow of the process I follow for mapping a new product development opportunity.

Due to the size of the meeting transcriptions and difficulties in categorizing user insights, consolidation and analysis became challenging.
Furthermore, the meeting transcription tools available to me were limited to English, while most of my conversations were in Portuguese. As a result, I decided to look to the market for a solution that could help me with those challenges.
The solutions I found that solved most of my pain points were Dovetail, Marvin, Condens, and Reduct. They position themselves as customer insights hubs, and their main product is generally Customer Interview transcriptions.
Basically, you can upload an interview video there, and you are going to receive a transcription indicating who is speaking with hyperlinks to the original video on every phrase. Over the text, you can add highlights, tags, and comments and ask for a summary of the conversation. These features would solve my problem; however, these tools are expensive, especially considering that I live in Brazil and they charge in dollars.
The tools offer nothing revolutionary, so I decided to implement an open-source alternative that would run for free on Colab notebooks.
The requirements
As a good PM, the first thing I did was identify the must-haves for my product based on the user’s (my) needs. Here are the high-level requirements I mapped:
Cost and Accessibility
- Free;
- No coding experience is required to use;
Data Privacy and Security
- Keep data private — no connection with external services;
Performance
- Execution must be faster than the video duration;
- High-precision transcription in different languages;
Functionality
- Speakers identification;
- Easy to search over the transcriptions;
- Easy to highlight the transcriptions;
- Easy to create repositories of research being done;
Integration
- Integrated with my company’s existing tools (Google Workspace);
- LLM model integrated to receive prompts for tasks on top of the transcriptions;
The solution
With the requirements, I designed what would be the features of my solution:

Then, I projected what would be the expected inputs and the user interfaces to define them:
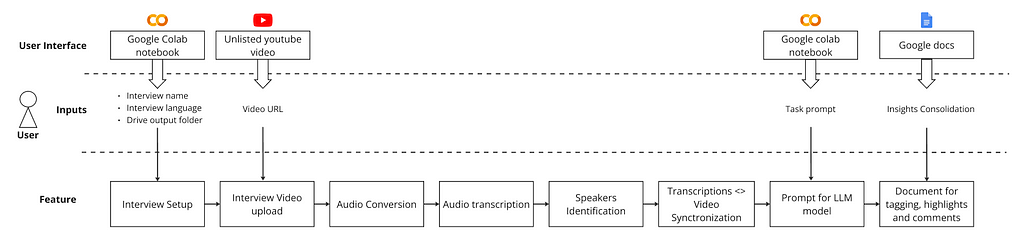
Users will upload their interview to YouTube as an unlisted video and create a Google Drive folder to store the transcription. They will then access a Google Colab notebook to provide basic information about the interview, paste the video URL, and optionally define tasks for an LLM model. The output will be Google Docs, where they can consolidate insights.
Below is the product architecture. The solution required combining five different ML models and some Python libraries. The next sections provide overviews of each of the building blocks; however, if you are more interested in trying the product, please go to the “I got it” section.
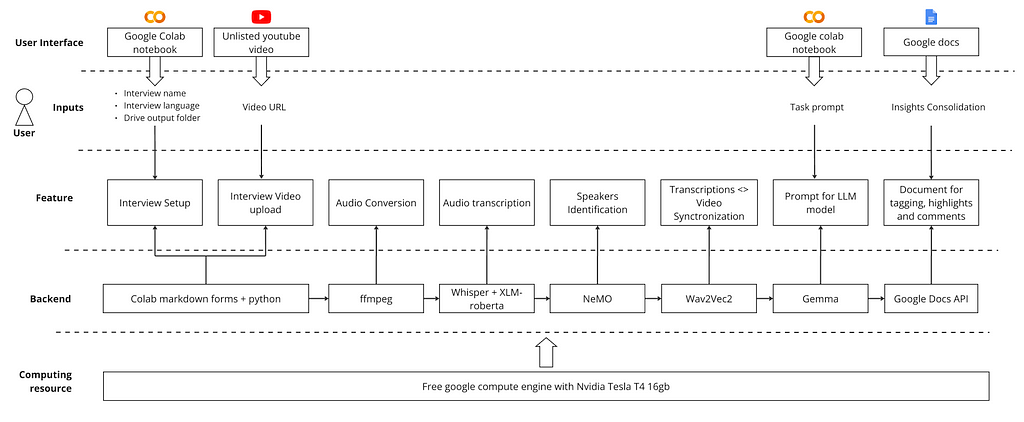
Interview Setup and Video Upload
To create a user-friendly interface for setting up interviews and providing video links, I used Google Colab’s forms functionality. This allows for the creation of text fields, sliders, dropdowns, and more. The code is hidden behind the form, making it very accessible for non-technical users.

Audio download and conversion
I used the yt-dlp lib to download only the audio from a YouTube video and convert it to the mp3 format. It is very straightforward to use, and you can check its documentation here.

Audio transcription
To transcribe the meeting, I used Whisper from Open AI. It is an open-source model for speech recognition trained on more than 680K hours of multilingual data.
The model runs incredibly fast; a one-hour audio clip takes around 6 minutes to be transcribed on a 16GB T4 GPU (offered by free on Google Colab), and it supports 99 different languages.
Since privacy is a requirement for the solution, the model weights are downloaded, and all the inference occurs inside the colab instance. I also added a Model Selection form in the notebook so the user can choose different models based on the precision they are looking for.

Speakers Identification
Speaker identification is done through a technique called Speakers Diarization. The idea is to identify and segment audio into distinct speech segments, where each segment corresponds to a particular speaker. With that, we can identify who spoke and when.
Since the videos uploaded from YouTube don’t have metadata identifying who is speaking, the speakers will be divided into Speaker 1, Speaker 2, etc.… Later, the user can find and replace those names in Google Docs to add the speakers’ identification.
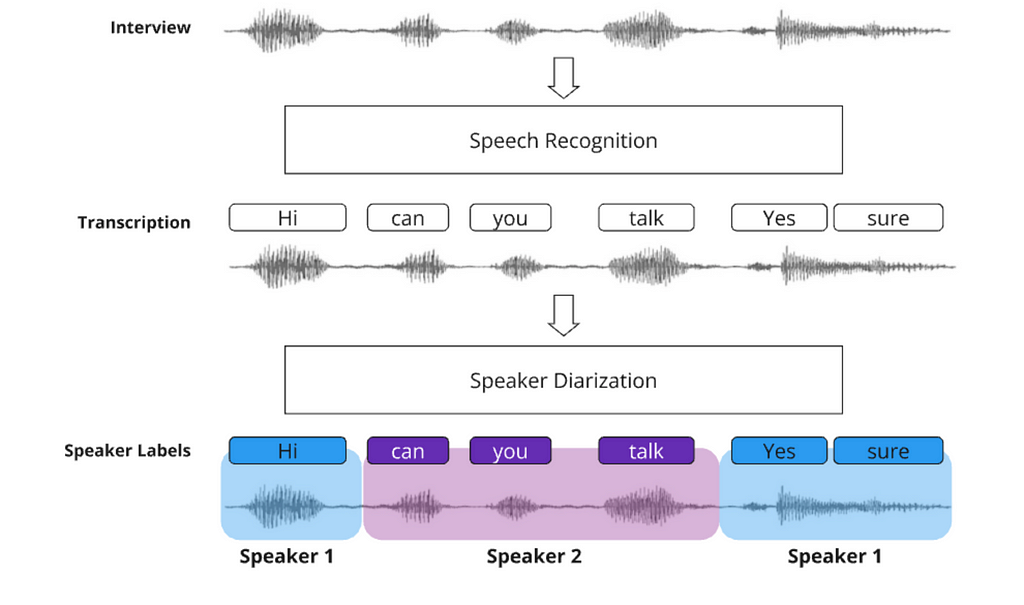
For the diarization, we will use a model called the Multi-Scale Diarization Decoder (MSDD), which was developed by Nvidia researchers. It is a sophisticated approach to speaker diarization that leverages multi-scale analysis and dynamic weighting to achieve high accuracy and flexibility.
The model is known for being quite good at identifying and properly categorizing moments where multiple speakers are talking—a thing that occurs frequently during interviews.
The model can be used through the NVIDIA NeMo framework. It allowed me to get MSDD checkpoints and run the diarization directly in the colab notebook with just a few lines of code.
Looking into the Diarization results from MSDD, I noticed that punctuation was pretty bad, with long phrases, and some interruptions such as “hmm” and “yeah” were taken into account as a speaker interruption — making the text difficult to read.
So, I decided to add a punctuation model to the pipeline to improve the readability of the transcribed text and facilitate human analysis. So I got the punctuate-all model from Hugging Face, which is a very precise and fast solution and supports the following languages: English, German, French, Spanish, Bulgarian, Italian, Polish, Dutch, Czech, Portuguese, Slovak, and Slovenian.
Video Synchronization
From the industry solutions I benchmarked, a strong requirement was that every phrase should be linked to the moment in the interview the speaker was talking.
The Whisper transcriptions have metadata indicating the timestamps when the phrases were said; however, this metadata is not very precise.
Therefore, I used a model called Wav2Vec2 to do this match in a more accurate way. Basically, the solution is a neural network designed to learn representations of audio and perform speech recognition alignment. The process involves finding the exact timestamps in the audio signal where each segment was spoken and aligning the text accordingly.
With the transcription <> timestamp match properly done, through simple Python code, I created hyperlinks pointing to the moment in the video where the phrases start to be said.
The LLM Model
This step of the pipeline has a large language model ready to run locally and analyze the text, providing insights about the interview. By default, I added a Gemma Model 1.1b with a prompt to summarize the text. If the users choose to have the summarization, it will be in a bullet list at the top of the document.

Also, by clicking on Show code, the users can change the prompt and ask the model to perform a different task.

Document generation for tagging, highlights, and comments
The last task performed by the solution is to generate Google Docs with the transcriptions and hyperlinks to the interviews. This was done through the Google API Python client library.
I got it
Since the product has become incredibly useful in my day-to-day work, I decided to give it a name for easier reference. I called it the Insights Gathering Open-source Tool, or iGot.

When using the solution for the first time, some initial setup is required. Let me guide you through a real-world example to help you get started.
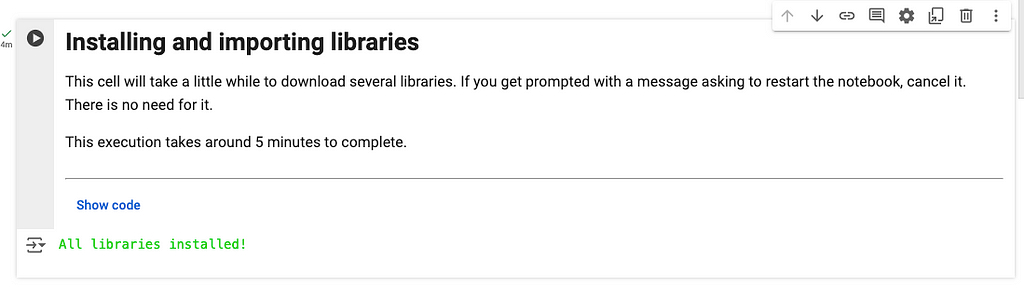
Open the iGot notebook and install the required libraries
Click on this link to open the notebook and run the first cell to install the required libraries. It is going to take around 5 minutes.
If you get a prompt asking you to restart the notebook, just cancel it. There is no need.
If everything runs as expected, you are going to get the message “All libraries installed!”.
Getting the Hugging User Access Token and model access
(This step is required just the first time you are executing the notebook)
For running the Gemma and punctuate-all models, we will download weights from hugging face. To do so, you must request a user token and model access.
To do so, you need to create a hugging face account and follow these steps to get a token with reading permissions.
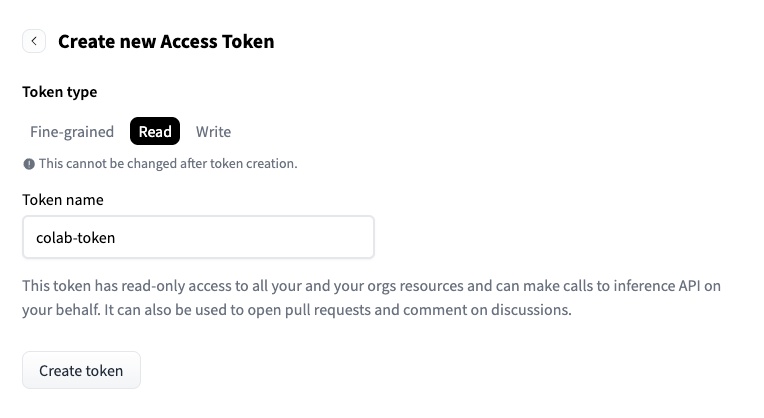
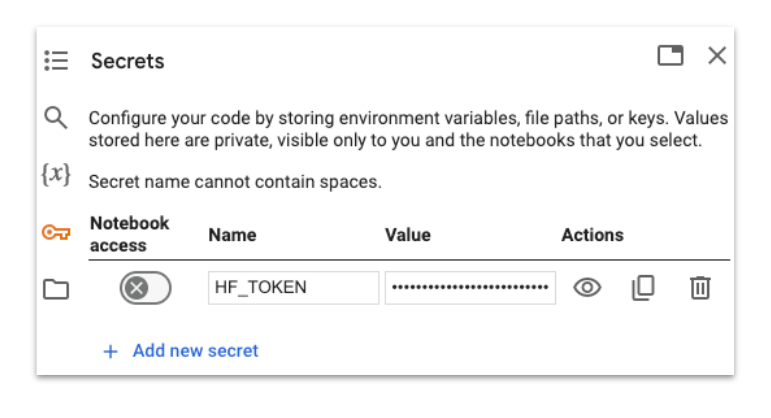
Once you have the token, copy it and return to the lab notebook. Go to the secrets tab and click on “Add new secret.”
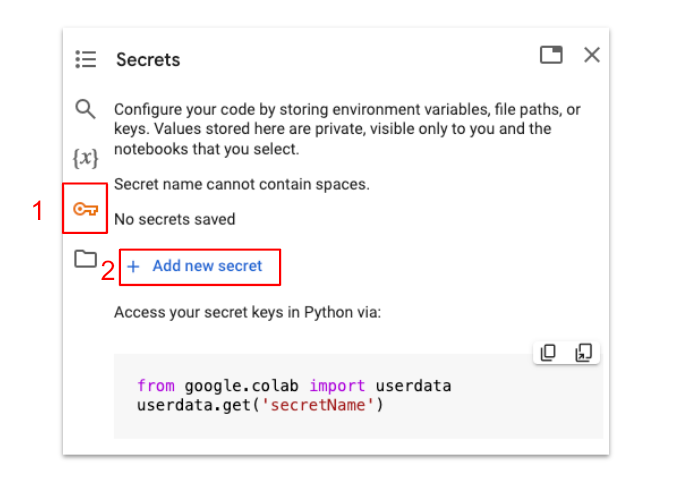
Name your token as HF_TOKEN and past the key you got from Hugging Face.
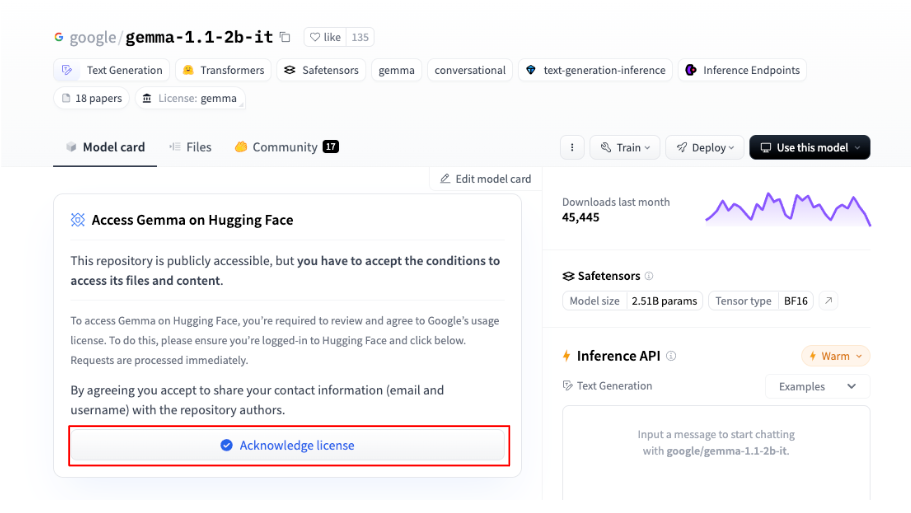
Next, click this link to open the Gemma model on Hugging Face. Then, click on “Acknowledge license” to get access the model.
Sending the interview
To send an interview to iGot, you need to upload it as an unlisted video on YouTube previously. For the purpose of this tutorial, I got a piece of the Andrej Karpathy interview with Lex Fridman and uploaded it to my account. It is part of the conversation where Andrej gave some advice for Machine Learning Beginners.
Then, you need to get the video URL, paste in the video_url field of the Interview Selection notebook cell, define a name for it, and indicate the language spoken in the video.
Once you run the cell, you are going to receive a message indicating that an audio file was generated.t into

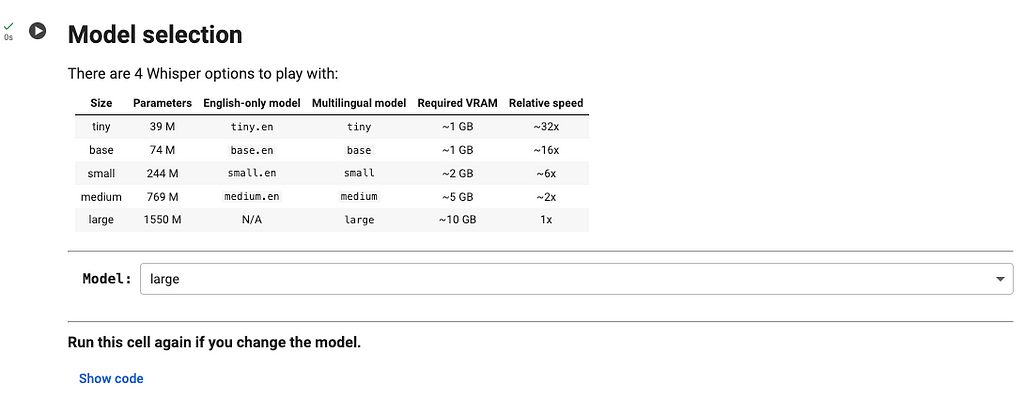
Model selection and execution
In the next cell, you can select the size of the Whisper model you want to use for the transcription. The bigger the model, the higher the transcription precision.
By default, the largest model is selected. Make your choice and run the cell.
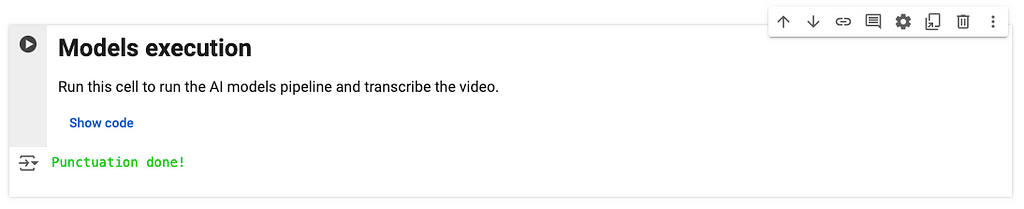
Then, run the models execution cell to run the pipeline of models showed in the previous section. If everything goes as expected, you should receive the message “Punctuation done!” by the end.
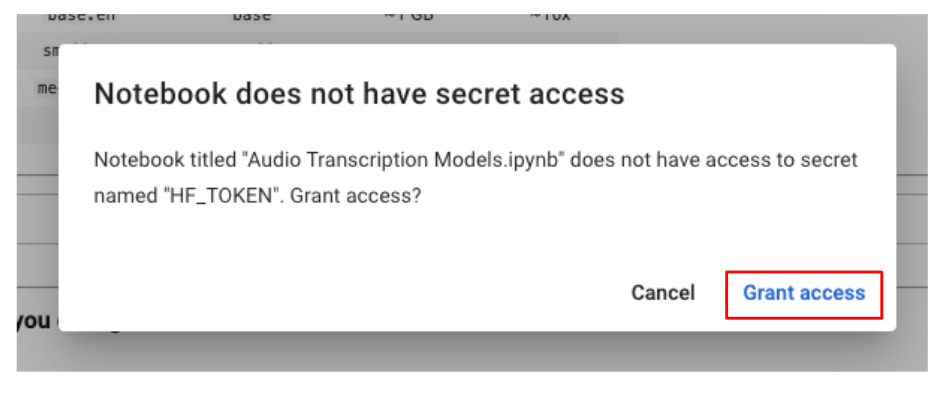
If you get prompted with a message asking for access to the hugging face token, grant access to it.
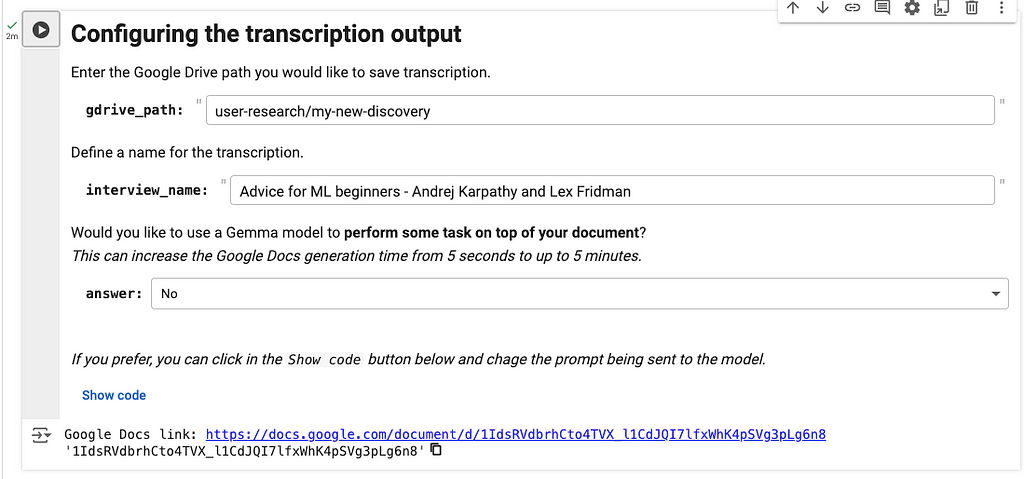
Configuring the transcript output
The final step is to save the transcription to a Google Docs file. To accomplish this, you need to specify the file path, provide the interview name, and indicate whether you want Gemma to summarize the meeting.
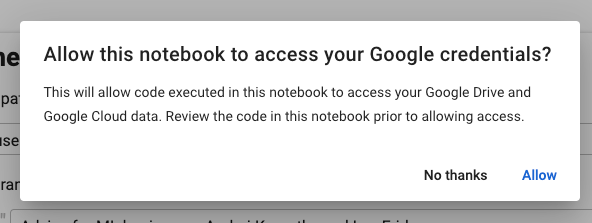
When executing the cell for the first time, you can get prompted with a message asking for access to your Google Drive. Click in allow.
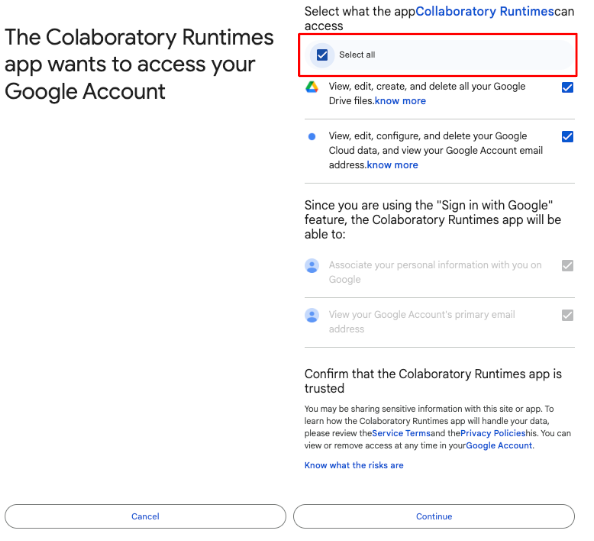
Then, give Colab full access to your Google Drive workspace.
If everything runs as expected, you are going to see a link to the google docs file at the end. Just click on it, and you are going to have access to your interview transcription.
Gathering insights from the generated document
The final document will have the transcriptions, with each phrase linked to the corresponding moment in the video where it begins. Since YouTube does not provide speaker metadata, I recommend using Google Docs’ find and replace tool to substitute “Speaker 0,” “Speaker 1,” and so on with the actual names of the speakers.
With that, you can work on highlights, notes, reactions, etc. As envisioned in the beginning:
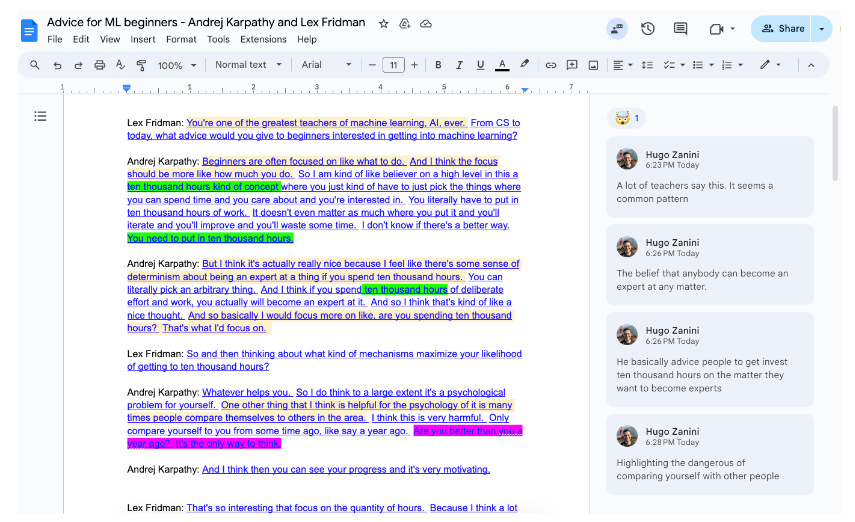
Final thoughts
The tool is just in its first version, and I plan to evolve it into a more user-friendly solution. Maybe hosting a website so users don’t need to interact directly with the notebook, or creating a plugin for using it in Google Meets and Zoom.
My main goal with this project was to create a high-quality meeting transcription tool that can be beneficial to others while demonstrating how available open-source tools can match the capabilities of commercial solutions.
I hope you find it useful! Feel free to reach out to me on LinkedIn if you have any feedback or are interested in collaborating on the evolution of iGot 🙂
Building a User Insights-Gathering Tool for Product Managers from Scratch was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Building a User Insights-Gathering Tool for Product Managers from Scratch
Go Here to Read this Fast! Building a User Insights-Gathering Tool for Product Managers from Scratch