Building a Multilingual Multi-Agent Chat Application Using LangGraph — Part I
In this 3 part series, learn how to build a RAG-based, multilingual, agentic chat application along with an integrated AI assistant to streamline tasks at workplaces
Background
Despite the advancements in technology, language barriers still exist in today’s world. Whether it’s at work or while you are outside, there are always situations where differences in languages can create awkward situations. This is especially true for large enterprises that have teams spread across different geographies, speaking different languages. As part of the recently concluded Aya Expedition organized by the Cohere for AI research community, I was able to work on a project that aimed to address this language barrier along with other workplace-related inefficiencies by developing a multilingual agentic chat application for workplaces.
Instead of talking more about the product, I think the best way to introduce the product and what we will be building through this series is to actually watch it in action.
The following tutorial series covers the development of this application which includes :
- An agentic workflow for translating to the user’s preferred language
- Building features for the AI assistant: RAG-based question answering, Documentation-on-the-Go, and Smart Summarize features
- Deploying the agentic workflow through FastAPI and developing a web UI to interface with it
High-level framework
Given the popularity of LangChain and its graph based counterpart, LangGraph, I don’t want this to be another tutorial that explains the basics of these packages and their methods. Instead I want to focus more on the design choices and challenges faced while implementing our solution through these packages as I feel that would be more useful in the long run.
LangChain vs LangGraph
The first design choice we faced was selecting between LangChain and LangGraph.
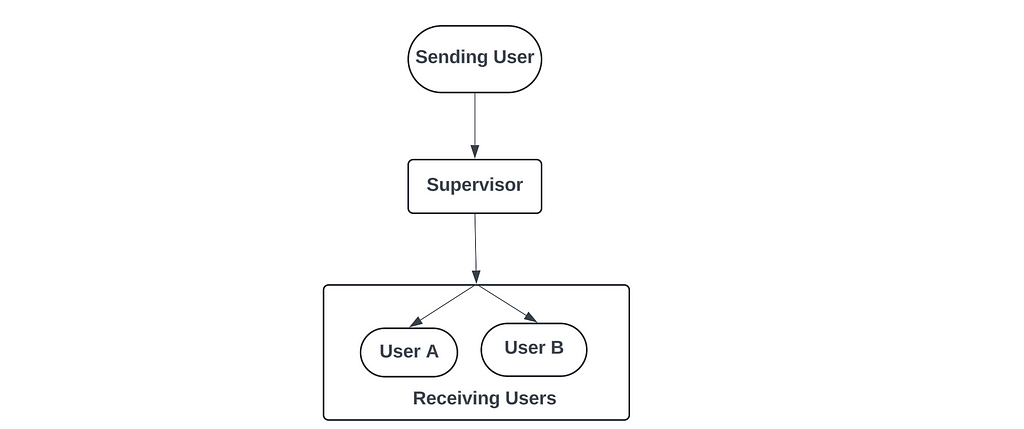
In a simple scenario (as pictured below), where every message provided by a user is sent to all other users and translated to their preferred language, then LangChain would have been a sufficient choice. This is a unidirectional flow that starts from the user sending the message and ends with the users receiving the messages:
However, the primary constraint in our scenario was the inclusion of an AI assistant, which we shall be referring to as Aya (named after the Expedition). Aya was planned to be a significant component of this chat application and added a new layer of complexity to our system. With Aya, messages from the sending user needed to be analyzed and depending on the nature of the message (if it was a command addressed to Aya), the system needed to send back a message, which in turn needed to be sent again to the receiving users.
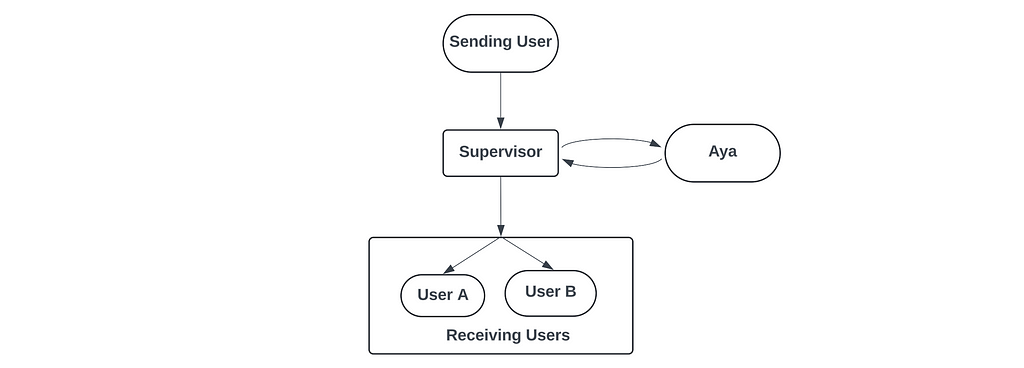
Defining a Run: Another design choice thats relevant here is the definition of one ‘run’ or one ‘iteration’ of the messaging cycle.
In the definition we chose, we considered each run to be initiated by any user sending a message and it being terminated when all messages related to that initial message reach the receiving users.
So if it’s a message that doesn’t address Aya and is just a direct message to other users, the run is considered to be terminated when the initial translated message is received by all users. And if it’s a message that addresses Aya, then it’s considered terminated when the initial message along with the response from Aya, BOTH, reach all users.
So with this design choice/definition of a run, we wanted a flow where we wait for the responses from Aya to be generated and pushed to the users before terminating the run. And for implementing such a flow, we used LangGraph, as it was specifically built to solve for such cases.
Building the Agents
The backbone of this application are the agents and their interactions. Overall, we had two different types of agents :
- User Agents: Agents attached to each user. Primarily tasked with translating incoming messages into the user’s preferred language
- Aya Agents: Various agents associated with Aya, each with its own specific role/job
User Agents
The UserAgent class is used to define an agent that will be associated with every user part of the chat room. Some of the functions implemented by the UserAgent class:
1. Translate incoming messages into the user’s preferred language
2. Activate/Invoke graph when a user sends a message
3. Maintain a chat history to help provide context to the translation task to allow for ‘context-aware’ translation
class UserAgent(object):
def __init__(self, llm, userid, user_language):
self.llm = llm
self.userid = userid
self.user_language = user_language
self.chat_history = []
prompt = ChatPromptTemplate.from_template(USER_SYSTEM_PROMPT2)
self.chain = prompt | llm
def set_graph(self, graph):
self.graph = graph
def send_text(self,text:str, debug = False):
message = ChatMessage(message = HumanMessage(content=text), sender = self.userid)
inputs = {"messages": [message]}
output = self.graph.invoke(inputs, debug = debug)
return output
def display_chat_history(self, content_only = False):
for i in self.chat_history:
if content_only == True:
print(f"{i.sender} : {i.content}")
else:
print(i)
def invoke(self, message:BaseMessage) -> AIMessage:
output = self.chain.invoke({'message':message.content, 'user_language':self.user_language})
return output
For the most part, the implementation of UserAgent is pretty standard LangChain/LangGraph code:
- Define a LangChain chain ( a prompt template + LLM) that is responsible for doing the actual translation.
- Define a send_text function thats used to invoke the graph whenever a user wants to send a new message
For the most part, the performance of this agent is dependent on the translation quality of the LLM, as translation is the primary objective of this agent. And LLM performance can vary significantly for translation, especially depending on the languages involved. Certain low resource languages don’t have good representation in the training data of some models and this does affect the translation quality for those languages.
Aya Agents
For Aya, we actually have a system of separate agents that all contributes towards the overall assistant. Specifically, we have
- AyaSupervisor : Control agent that supervises the operation of the other Aya agents.
- AyaQuery : Agent for running RAG based question answering
- AyaSummarizer : Agent for generating chat summaries and doing task identification
- AyaTranslator: Agent for translating messages to English
class AyaTranslator(object):
def __init__(self, llm) -> None:
self.llm = llm
prompt = ChatPromptTemplate.from_template(AYA_TRANSLATE_PROMPT)
self.chain = prompt | llm
def invoke (self, message: str) -> AIMessage:
output = self.chain.invoke({'message':message})
return output
class AyaQuery(object):
def __init__(self, llm, store, retriever) -> None:
self.llm = llm
self.retriever = retriever
self.store = store
qa_prompt = ChatPromptTemplate.from_template(AYA_AGENT_PROMPT)
self.chain = qa_prompt | llm
def invoke(self, question : str) -> AIMessage:
context = format_docs(self.retriever.invoke(question))
rag_output = self.chain.invoke({'question':question, 'context':context})
return rag_output
class AyaSupervisor(object):
def __init__(self, llm):
prompt = ChatPromptTemplate.from_template(AYA_SUPERVISOR_PROMPT)
self.chain = prompt | llm
def invoke(self, message : str) -> str:
output = self.chain.invoke(message)
return output.content
class AyaSummarizer(object):
def __init__(self, llm):
message_length_prompt = ChatPromptTemplate.from_template(AYA_SUMMARIZE_LENGTH_PROMPT)
self.length_chain = message_length_prompt | llm
prompt = ChatPromptTemplate.from_template(AYA_SUMMARIZER_PROMPT)
self.chain = prompt | llm
def invoke(self, message : str, agent : UserAgent) -> str:
length = self.length_chain.invoke(message)
try:
length = int(length.content.strip())
except:
length = 0
chat_history = agent.chat_history
if length == 0:
messages_to_summarize = [chat_history[i].content for i in range(len(chat_history))]
else:
messages_to_summarize = [chat_history[i].content for i in range(min(len(chat_history), length))]
print(length)
print(messages_to_summarize)
messages_to_summarize = "n ".join(messages_to_summarize)
output = self.chain.invoke(messages_to_summarize)
output_content = output.content
print(output_content)
return output_content
Most of these agents have a similar structure, primarily consisting of a LangChain chain consisting of a custom prompt and a LLM. Exceptions include the AyaQuery agent which has an additional vector database retriever to implement RAG and AyaSummarizer which has multiple LLM functions being implemented within it.
Design considerations
Role of AyaSupervisor Agent: In the design of the graph, we had a fixed edge going from the Supervisor node to the user nodes. Which meant that all messages that reached the Supervisor node were pushed to the user nodes itself. Therefore, in cases where Aya was being addressed, we had to ensure that only a single final output from Aya was being pushed to the users. We didn’t want intermediate messages, if any, to reach the users. Therefore, we had the AyaSupervisor agent that acted as the single point of contact for the Aya agent. This agent was primarily responsible for interpreting the intent of the incoming message, direct the message to the appropriate task-specific agent, and then outputting the final message to be shared with the users.
Design of AyaSummarizer: The AyaSummarizer agent is slightly more complex compared to the other Aya agents as it carries out a two-step process. In the first step, the agent first determines the number of messages that needs to be summarized, which is a LLM call with its own prompt. In the second step, once we know the number of messages to summarize, we collate the required messages and pass it to the LLM to generate the actual summary. In addition to the summary, in this step itself, the LLM also identifies any action items that were present in the messages and lists it out separately.
So broadly there were three tasks: determining the length of the messages to be summarized, summarizing messages, identifying action items. However, given that the first task was proving a bit difficult for the LLM without any explicit examples, I made the choice to have this be a separate LLM call and then combine the two last two tasks as their own LLM call.
It may be possible to eliminate the additional LLM call and combine all three tasks in one call. Potential options include :
- Providing very detailed examples that cover all three tasks in one step
- Generating lot of examples to actually finetune a LLM to be able to perform well in this task
Role of AyaTranslator: One of the goals with respect to Aya was to make it a multilingual AI assistant which can communicate in the user’s preferred language. However, it would be difficult to handle different languages internally within the Aya agents. Specifically, if the Aya agents prompt is in English and the user message is in a different language, it could potentially create issues. So in order to avoid such situations, as a filtering step, we translated any incoming user messages to Aya into English. As a result, all of the internal work within the Aya group of agents was done in English, including the output. We didnt have to translate the Aya output back to the original language because when the message reaches the users, the User agents will take care of translating the message to their respective assigned language.
Prompt Design
With respect to prompt designs, the majority of the work was focused on getting the LLM to output responses in a particular format in a consistent manner. For most cases, I was able to achieve this by providing explicit instructions. In some cases, instructions alone was not enough and I had to provide examples for the agent to behave consistently.
For the most part, the prompt template had the following structure :
[High level task definition] You are an AI assistant that answers user's questions...
[List of specific constraints related to the response]
Obey the following rules :
1. ....
[Providing context/user input]
Message :
To take a specific example, we take a look at the prompt used by the User Agent:
You are a {user_language} translator, translating a conversation between work colleagues. Translate the message provided by the user into {user_language}.
Obey the following rules :
1. Only translate the text thats written after 'Message:' and nothing else
2. If the text is already in {user_language} then return the message as it is.
3. Return only the translated text
4. Ensure that your translation uses formal language
Message:
{message}
With regards to this agent, an important constraint was to ensure that the model only outputted the translated text and no supporting text like “Here’s the translated text” or “Sure, the following is a translation for the provided text”. In this case, adding a specific rule to obey (rule #3) was enough to ensure that the models were only outputting the translated text and nothing else.
An example of an instance that required examples in the prompt were the prompts related to the summarizer agent. Specifically for the agent responsible for identifying the number of messages to summarize over. I found it difficult to get the agent to consistently extract the number of messages listed, if any, and output it in a specific format. Therefore, it became necessary to provide examples to better explain what I was expecting as a response from the agent.
Other implementation details
ChatMessage
Those familiar with LangChain should already be aware of AIMessage, HumanMessage classes that are used to hold AI and human messages. For our use case, we needed to be able to store the ID of the sender for downstream tasks. Therefore to address this, we created a new derived class called ChatMessage that stores a message along with the sender’s ID
class ChatMessage(object):
def __init__(self, message : BaseMessage, sender : str = None):
self.message = message
self.sender = sender
self.content = message.content
def __repr__(self) -> str:
return f"{self.sender} | {self.content}"
Graph State
In LangGraph, one of key elements of the graph is the graph state. The state variable/object is crucial for proper communication between the agents as well as for keeping track of the progress through the graph workflow.
def reducer(a : list, b : list | str ) -> list:
if type(b) == list:
return a + b
else:
return a
class AgentState(TypedDict):
messages: Annotated[Sequence[ChatMessage], reducer]
In most LangGraph examples, the state variable is a list of strings that keeps getting appended to after passing through every agent. In our use case, I wanted to exclude the outputs from certain nodes from affecting the state of the graph, despite the workflow having passed through that node. To accommodate such cases, I differentiated between the two types of state changes by having one as a list and the other as a string. In cases where the state update is in the form of a list, it gets appended to the overall state object. In cases, where the state update is a string, we ignore that update and propagate the existing state. This is achieved using the custom reducer function defined above.
Conclusion
At this stage, we have covered the design choices of one of the key components of the agentic workflow : the agents. In the next tutorial, we will cover more details about the actual LangGraph graph and its implementation, along with some more details about the features associated with Aya.
Resources
For the code, you can refer to the repo here : Multilingual Chatbot.
Unless specified otherwise, all images are created by the author.
In addition to Medium, I share my thoughts, ideas and other updates on LinkedIn.
Building a Multilingual Multi-Agent Chat Application Using LangGraph — Part I was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Building a Multilingual Multi-Agent Chat Application Using LangGraph — Part I