
Cross Platform NLP in Rust
Optimization with Rayon with usage in C/C++, Android and Python

NLP tools and utilities have grown largely in the Python ecosystem, enabling developers from all levels to build high-quality language apps at scale. Rust is a newer introduction to NLP, with organizations like HuggingFace adopting it to build packages for machine learning.
Hugging Face has written a new ML framework in Rust, now open-sourced!
In this blog, we’ll explore how we can build a text summarizer using the concept of TFIDF. We’ll first have an intuition on how TFIDF summarization works, and why Rust could be a good language to implement NLP pipelines and how we can use our Rust code on other platforms like C/C++, Android and Python. Moreover, we discuss how we can optimize the summarization task with parallel computing with Rayon.
Here’s the GitHub project:
Let’s get started ➡️
Contents
- Motivation
- Extractive and Abstractive Text Summarization
- Understanding Text Summarization with TFIDF
- Rust Implementation
- Usage with C
- Future Scope
- Conclusion
Motivation
I had built a text summarizer using the same technique, back in 2019, with Kotlin and called in Text2Summary. It was primarily designed for Android apps, as a side project and used Kotlin for all computations. Fast-forward to 2023, I am now working with C, C++ and Rust codebases and have used modules built in these native languages in Android and Python.
I chose to re-implement Text2Summary in Rust, as it would serve as a great learning experience and also as a small, efficient, handy text summarization which can handle large texts easily. Rust is a compiled language with intelligent borrow and reference checkers that helps developers write bug-free code. Code written in Rust can be integrated with Java codebases through jni and converted to C headers/libraries for use in C/C++ and Python.
Extractive and Abstractive Text Summarization
Text summarization has been a long-studied problem in natural language processing (NLP). Extracting important information from the text and generating a summary of the given text is the core problem that text summarizers need to solve. The solutions belong to two categories, namely, extractive summarization and abstractive summarization.
Understanding Automatic Text Summarization-1: Extractive Methods
In extractive text summarization, phrases or sentences are derived from the sentence directly. We can rank sentences using a scoring function and pick the most suitable sentences from the text considering their scores. Instead of generating new text, as in abstractive summarization, the summary is a collection of selected sentences from the text, hence avoiding problems which generative models exhibit.
- Precision of the text is maintained in extractive summarization, but there is a high chance that some information is lost as the granularity of the selecting text is only limited to sentences. If a piece of information is spread across multiple sentences, the scoring function must take care of the relation which contains those sentences.
- Abstractive text summarization requires larger deep learning model to capture the semantics of the language and to build an appropriate document-to-summary mapping. Training such models requires huge datasets and a longer training time which in-turn overloads computing resources heavily. Pretrained models might solve the problem of longer training times and data demands, but are still inherently biased towards the domain of the text on which they trained.
- Extractive methods may have scoring functions which are free of parameters and do not require any learning. They fall in the unsupervised learning regime of ML, and are useful as they require lesser computation and are not biased towards the domain of the text. Summarization may be equally efficient on news articles as well as novel excerpts.
With our TFIDF-based technique, we do not require any training dataset or deep learning models. Our scoring function is based on the relative frequencies of words across different sentences.
Understanding Text Summarization with TFIDF
In order to rank each sentence, we need to calculate a score that would quantify the amount of information present within the sentence. TF-IDF comprises of two terms — TF, which stands for Term Frequency and IDF which denotes Inverse Document Frequency.
TF(Term Frequency)-IDF(Inverse Document Frequency) from scratch in python .
We consider that each sentence is made of tokens (words),
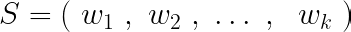
The term-frequency of each word, in the sentence S, is defined as,
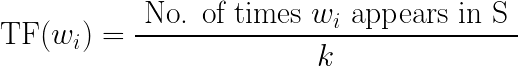
The inverse-document frequency of each word, in the sentence S, is defined as,
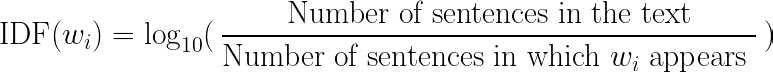
The score of each sentence is the sum of TFIDF scores of all words in that sentence,

Significance and Intuition
The term frequency, as you may have observed, would be lesser for words which are rarer in the sentence. If the same word has less presence in other sentences, then the IDF score is also higher. Hence, a sentence which contains repeated words (higher TF) which are more exclusive only to that sentence (higher IDF) will have a higher TFIDF score.
Rust Implementation
We start implementing our technique by creating functions which convert a given text into a Vec of sentences. This problem is referred as sentence tokenization which identifies sentence boundaries within a text. With Python packages like nltk , the punkt sentence tokenizer is available for this task, and there exists a Rust port of Punkt as well. rust-punkt is no longer being maintained, but we still use it here. Another function which splits the sentence into words is also written,
use punkt::{SentenceTokenizer, TrainingData};
use punkt::params::Standard;
static STOPWORDS: [ &str ; 127 ] = [ "i", "me", "my", "myself", "we", "our", "ours", "ourselves", "you",
"your", "yours", "yourself", "yourselves", "he", "him", "his", "himself", "she", "her", "hers", "herself",
"it", "its", "itself", "they", "them", "their", "theirs", "themselves", "what", "which", "who", "whom", "this",
"that", "these", "those", "am", "is", "are", "was", "were", "be", "been", "being", "have", "has", "had", "having",
"do", "does", "did", "doing", "a", "an", "the", "and", "but", "if", "or", "because", "as", "until", "while", "of",
"at", "by", "for", "with", "about", "against", "between", "into", "through", "during", "before", "after", "above",
"below", "to", "from", "up", "down", "in", "out", "on", "off", "over", "under", "again", "further", "then", "once",
"here", "there", "when", "where", "why", "how", "all", "any", "both", "each", "few", "more", "most", "other",
"some", "such", "no", "nor", "not", "only", "own", "same", "so", "than", "too", "very", "s", "t", "can",
"will", "just", "don", "should", "now" ] ;
/// Transform a `text` into a list of sentences
/// It uses the popular Punkt sentence tokenizer from a Rust port:
/// <`/`>https://github.com/ferristseng/rust-punkt<`/`>
pub fn text_to_sentences( text: &str ) -> Vec<String> {
let english = TrainingData::english();
let mut sentences: Vec<String> = Vec::new() ;
for s in SentenceTokenizer::<Standard>::new(text, &english) {
sentences.push( s.to_owned() ) ;
}
sentences
}
/// Transforms the sentence into a list of words (tokens)
/// eliminating stopwords while doing so
pub fn sentence_to_tokens( sentence: &str ) -> Vec<&str> {
let tokens: Vec<&str> = sentence.split_ascii_whitespace().collect() ;
let filtered_tokens: Vec<&str> = tokens
.into_iter()
.filter( |token| !STOPWORDS.contains( &token.to_lowercase().as_str() ) )
.collect() ;
filtered_tokens
}
In the above snippet, we remove stop-words, which are commonly occurring words in a language and have no significant contribution to the text’s information content.
Text pre-processing: Stop words removal using different libraries
Next, we create a function which computes the frequency of each word present in the corpus. This method will be used to compute the term frequency of each word present in a sentence. The (word, freq) pair is stored in a Hashmap for faster retrieval in later stages
use std::collections::HashMap;
/// Given a list of words, build a frequency map
/// where keys are words and values are the frequencies of those words
/// This method will be used to compute the term frequencies of each word
/// present in a sentence
pub fn get_freq_map<'a>( words: &'a Vec<&'a str> ) -> HashMap<&'a str,usize> {
let mut freq_map: HashMap<&str,usize> = HashMap::new() ;
for word in words {
if freq_map.contains_key( word ) {
freq_map
.entry( word )
.and_modify( | e | {
*e += 1 ;
} ) ;
}
else {
freq_map.insert( *word , 1 ) ;
}
}
freq_map
}
Next, we write the function which computes the term frequency of words present in a sentence,
// Compute the term frequency of tokens present in the given sentence (tokenized)
// Term frequency TF of token 'w' is expressed as,
// TF(w) = (frequency of w in the sentence) / (total number of tokens in the sentence)
fn compute_term_frequency<'a>(
tokenized_sentence: &'a Vec<&str>
) -> HashMap<&'a str,f32> {
let words_frequencies = Tokenizer::get_freq_map( tokenized_sentence ) ;
let mut term_frequency: HashMap<&str,f32> = HashMap::new() ;
let num_tokens = tokenized_sentence.len() ;
for (word , count) in words_frequencies {
term_frequency.insert( word , ( count as f32 ) / ( num_tokens as f32 ) ) ;
}
term_frequency
}
Another function which computes the IDF, inverse document frequency, for words in a tokenized sentence,
// Compute the inverse document frequency of tokens present in the given sentence (tokenized)
// Inverse document frequency IDF of token 'w' is expressed as,
// IDF(w) = log( N / (Number of documents in which w appears) )
fn compute_inverse_doc_frequency<'a>(
tokenized_sentence: &'a Vec<&str> ,
tokens: &'a Vec<Vec<&'a str>>
) -> HashMap<&'a str,f32> {
let num_docs = tokens.len() as f32 ;
let mut idf: HashMap<&str,f32> = HashMap::new() ;
for word in tokenized_sentence {
let mut word_count_in_docs: usize = 0 ;
for doc in tokens {
word_count_in_docs += doc.iter().filter( |&token| token == word ).count() ;
}
idf.insert( word , ( (num_docs) / (word_count_in_docs as f32) ).log10() ) ;
}
idf
}
We’ve now added functions to compute TF and IDF scores of each word present in a sentence. In order to compute a final score for each sentence, which would also determine its rank, we have to compute the sum of TFIDF-scores of all words present in a sentence.
pub fn compute(
text: &str ,
reduction_factor: f32
) -> String {
let sentences_owned: Vec<String> = Tokenizer::text_to_sentences( text ) ;
let mut sentences: Vec<&str> = sentences_owned
.iter()
.map( String::as_str )
.collect() ;
let mut tokens: Vec<Vec<&str>> = Vec::new() ;
for sentence in &sentences {
tokens.push( Tokenizer::sentence_to_tokens(sentence) ) ;
}
let mut sentence_scores: HashMap<&str,f32> = HashMap::new() ;
for ( i , tokenized_sentence ) in tokens.iter().enumerate() {
let tf: HashMap<&str,f32> = Summarizer::compute_term_frequency(tokenized_sentence) ;
let idf: HashMap<&str,f32> = Summarizer::compute_inverse_doc_frequency(tokenized_sentence, &tokens) ;
let mut tfidf_sum: f32 = 0.0 ;
// Compute TFIDF score for each word
// and add it to tfidf_sum
for word in tokenized_sentence {
tfidf_sum += tf.get( word ).unwrap() * idf.get( word ).unwrap() ;
}
sentence_scores.insert( sentences[i] , tfidf_sum ) ;
}
// Sort sentences by their scores
sentences.sort_by( | a , b |
sentence_scores.get(b).unwrap().total_cmp(sentence_scores.get(a).unwrap()) ) ;
// Compute number of sentences to be included in the summary
// and return the extracted summary
let num_summary_sents = (reduction_factor * (sentences.len() as f32) ) as usize;
sentences[ 0..num_summary_sents ].join( " " )
}
Using Rayon
For larger texts, we can perform some operations in parallel i.e. on multiple CPU threads using a popular Rust crate rayon-rs . In the compute function above, we can perform the following tasks parallelly,
- Converting each sentence to tokens and removing stop-words
- Computing the sum of TFIDF scores for each sentence
These tasks can be performed independently on each sentence, and have no dependence on other sentences, hence, they can be parallelized. To ensure mutual exclusion while different threads access a shared container, we use Arc (Atomic reference counted pointer) and Mutex which is basic synchronization primitive for ensuring atomic access.
Arc ensures that the referred Mutex is accessible to all threads, and the Mutex itself allows only a single thread to access the object wrapped in it. Here’s another function par_compute , which uses Rayon and performs the above-mentioned tasks in-parallel,
pub fn par_compute(
text: &str ,
reduction_factor: f32
) -> String {
let sentences_owned: Vec<String> = Tokenizer::text_to_sentences( text ) ;
let mut sentences: Vec<&str> = sentences_owned
.iter()
.map( String::as_str )
.collect() ;
// Tokenize sentences in parallel with Rayon
// Declare a thread-safe Vec<Vec<&str>> to hold the tokenized sentences
let tokens_ptr: Arc<Mutex<Vec<Vec<&str>>>> = Arc::new( Mutex::new( Vec::new() ) ) ;
sentences.par_iter()
.for_each( |sentence| {
let sent_tokens: Vec<&str> = Tokenizer::sentence_to_tokens(sentence) ;
tokens_ptr.lock().unwrap().push( sent_tokens ) ;
} ) ;
let tokens = tokens_ptr.lock().unwrap() ;
// Compute scores for sentences in parallel
// Declare a thread-safe Hashmap<&str,f32> to hold the sentence scores
let sentence_scores_ptr: Arc<Mutex<HashMap<&str,f32>>> = Arc::new( Mutex::new( HashMap::new() ) ) ;
tokens.par_iter()
.zip( sentences.par_iter() )
.for_each( |(tokenized_sentence , sentence)| {
let tf: HashMap<&str,f32> = Summarizer::compute_term_frequency(tokenized_sentence) ;
let idf: HashMap<&str,f32> = Summarizer::compute_inverse_doc_frequency(tokenized_sentence, &tokens ) ;
let mut tfidf_sum: f32 = 0.0 ;
for word in tokenized_sentence {
tfidf_sum += tf.get( word ).unwrap() * idf.get( word ).unwrap() ;
}
tfidf_sum /= tokenized_sentence.len() as f32 ;
sentence_scores_ptr.lock().unwrap().insert( sentence , tfidf_sum ) ;
} ) ;
let sentence_scores = sentence_scores_ptr.lock().unwrap() ;
// Sort sentences by their scores
sentences.sort_by( | a , b |
sentence_scores.get(b).unwrap().total_cmp(sentence_scores.get(a).unwrap()) ) ;
// Compute number of sentences to be included in the summary
// and return the extracted summary
let num_summary_sents = (reduction_factor * (sentences.len() as f32) ) as usize;
sentences[ 0..num_summary_sents ].join( ". " )
}
Cross-Platform Usage
C and C++
To use Rust structs and functions in C, we can use cbindgen to generate C-style headers containing the struct/function prototypes. On generating the headers, we can compile the Rust code to C-based dynamic or static libraries which contain the implementation of the functions declared in the header files. To generate C-based static library, we need to set the crate_type parameter in Cargo.toml to staticlib,
[lib]
name = "summarizer"
crate_type = [ "staticlib" ]
Next, we add FFIs to expose the summarizer’s functions in the ABI (application binary interface) in src/lib.rs ,
/// functions exposing Rust methods as C interfaces
/// These methods are accessible with the ABI (compiled object code)
mod c_binding {
use std::ffi::CString;
use crate::summarizer::Summarizer;
#[no_mangle]
pub extern "C" fn summarize( text: *const u8 , length: usize , reduction_factor: f32 ) -> *const u8 {
...
}
#[no_mangle]
pub extern "C" fn par_summarize( text: *const u8 , length: usize , reduction_factor: f32 ) -> *const u8 {
...
}
}
We can build the static library with cargo build and libsummarizer.a will be generated in the target directory.
Android
With Android’s Native Development Kit (NDK), we can compile the Rust program for armeabi-v7a and arm64-v8a targets. We need to write special interface functions with Java Native Interface (JNI), which can be found in the android module in src/lib.rs .
Python
With Python’s ctypes module, we can load a shared library ( .so or .dll ) and use the C-compatible datatypes to execute the functions defined in the library. The code isn’t available on the GitHub project, but will be soon available.
Python Bindings: Calling C or C++ From Python – Real Python
Future Scope
The project can be extended and improved in many ways, which we’ll discuss below:
- The current implementation requires the nightly build of Rust, only because of a single dependency punkt . punkt is a sentence tokenizer which is required to determine sentence boundaries in the text, following which other computations are made. If punkt can be built with stable Rust, the current implementation will no more require nightly Rust.
- Adding newer metrics to rank sentences, especially which capture inter-sentence dependencies. TFIDF is not the most accurate scoring function and has its own limitations. Building sentence graphs and using them for scoring sentences has greatly enhance the overall quality of the extracted summary.
- The summarizer has not been benchmarked against a known dataset. Rouge scores R1 , R2 and RL are frequently used to assess the quality of the generated summary against standard datasets like the New York Times dataset or the CNN Daily mail dataset. Measuring performance against standard benchmarks will provide developers more clarity and reliability towards the implementation.
Conclusion
Building NLP utilities with Rust has significant advantages, considering the increasing popularity of the language amongst developers due to its performance and future promises. I hope the article was knowledgeable. Do have a look at the GitHub project:
You may consider opening an issue or a pull request if you feel something can be improved! Keep learning and have a nice day ahead.
Building A Cross-Platform TFIDF Text Summarizer In Rust was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Building A Cross-Platform TFIDF Text Summarizer In Rust
Go Here to Read this Fast! Building A Cross-Platform TFIDF Text Summarizer In Rust

