

Building a Chat Application with LangChain, LLMs, and Streamlit for Complex SQL Database Interaction
Build and deploy a chat application for complex database interaction with LangChain agents.
In this article we will see how we can use large language models (LLMs) to interact with a complex database using Langchain agents and tools, and then deploying the chat application using Streamlit.
This article is the second and final part of a two-phase project that exploits RappelConso API data, a French public service that shares information about product recalls in France.
In the first article, we set up a pipeline that queries the data from the API and stores it in a PostgreSQL database using various data engineering tools. In this article, we will develop a language model-based chat application that allows us to interact with the database.
Table of Contents
· Overview
· Set-up
· SQL Agent
· SQL Database Toolkit
· Extra tools
· Implementing Memory Features
· Creating the application with Streamlit
· Observations and enhancements
· Conclusion
· References
Overview
In this project, we’re going to create a chatbot that can talk to the RappelConso database through the Langchain framework. This chatbot will be able to understand natural language and use it to create and run SQL queries. We’ll enhance the chatbot’s ability to make SQL queries by giving it additional tools. It will also have a memory feature to remember past interactions with users. To make it user-friendly, we’ll use Streamlit to turn it into a chat-based web application.
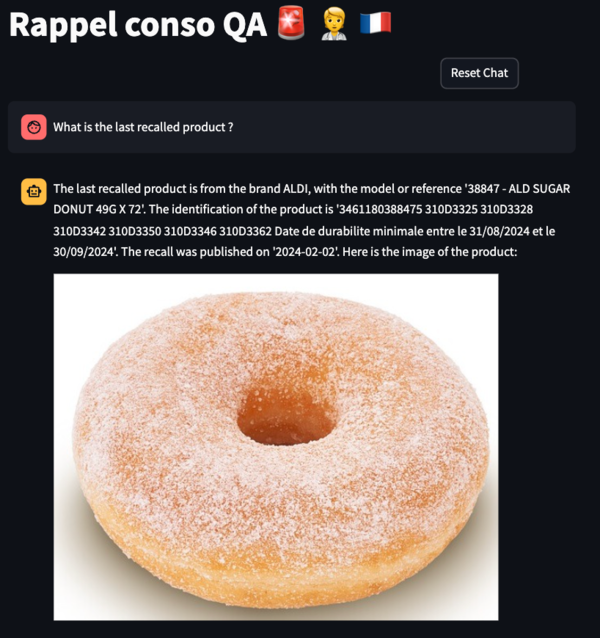
You can see a demo of the final application here:
The chatbot can answer queries with different complexities, from the categories count of the recalled products to specific questions about the products or brands. It can identify the right columns to query by using the tools at its disposal. The chatbot can also answer queries in “ASCII” compatible languages such as English, French, German, etc …
Glossary:
Here is a quick rundown of key terms to help you get a grasp of the concepts mentioned in this article.
- Langchain: LangChain is an open-source framework designed for building applications that leverage large language models (LLMs).
- Agents: They are components of Langchain that use a language model to determine which actions to take and in which order. The Agent has typically access to a set of functions called Tools and it can decide which Tool to use based on the user input.
- Tools: These are functions that an agent can invoke and enable it to interact with the world. Tools must be well described in a way that is most helpful to the agent.
- Toolkits: A set of related tools. In this project we will be using the SQLDatabaseToolkit. More on this in the subsequent sections.
- SQL Databases: The backbone holding the data you’ll be querying. In our project we will be using a Postgres Database.
- Streamlit: A python framework that enables the creation of interactive web applications very simply.
Now let’s dive into the technical details of this project !
Set-up
First you can clone the github repo with the following command:
git clone https://github.com/HamzaG737/rappel-conso-chat-app.git
Next, you can navigate to the project root and install the packages requirements:
pip install -r requirements.txt
In this project we experimented with two large language models from OpenAI, gpt-3.5-turbo-1106 and gpt-4–1106-preview . Since the latter is better at understanding and executing complex queries, we used it as the default LLM.
Setting-up the database
In my previous article, I covered how to set up a data pipeline for streaming data from a source API directly into a Postgres database. However, if you want a simpler solution, I created a script that allows you to transfer all the data from the API straight to Postgres, bypassing the need to set up the entire pipeline.
First off, you need to install Docker. Then you have to set the POSTGRES_PASSWORD as environment variable. By default, it will be set to the string “postgres” .
Next, get the Postgres server running with the docker-compose yaml file at the project’s root:
docker-compose -f docker-compose-postgres.yaml up -d
After that, the script database/stream_data.py helps you create the rappel_conso_table table, stream the data from the API into the database, and do a quick check on the data by counting the rows. As of February 2024, you should see around 10400 rows, so expect a number close to that.
To run the script, use this command:
python database/stream_data.py
Please note that the data transfer might take around one minute, possibly a little longer, depending on the speed of your internet connection.
The rappel_conso_table contains in total 25 columns, most of them are in TEXT type and can take infinite values. Some of the important columns are:
- reference_fiche (reference sheet): Unique identifier of the recalled product. It acts as the primary key of our Postgres database.
- categorie_de_produit (Product category): For instance food, electrical appliance, tools, transport means, etc …
- sous_categorie_de_produit (Product sub-category): For instance we can have meat, dairy products, cereals as sub-categories for the food category.
- motif_de_rappel (Reason for recall): Self explanatory and one of the most important fields.
- date_de_publication which translates to the publication date.
- risques_pour_le_consommateur which contains the risks that the consumer may encounter when using the product.
- There are also several fields that correspond to different links, such as link to product image, link to the distributers list, etc..
The full list of columns can be found in the constants.py file under the constant RAPPEL_CONSO_COLUMNS .
Given the wide range of columns present, it’s crucial for the agent to effectively distinguish between them, particularly in cases of ambiguous user queries. The SQLDatabaseToolkit, along with the additional tools we plan to implement, will play an important role in providing the necessary context. This context is key for the agent to accurately generate the appropriate SQL queries.
SQL Agent
LangChain has an SQL Agent which provides a flexible way of interacting with SQL Databases.
The benefits of employing the SQL Agent include:
- Its capability to respond to queries not only about the structure of the databases (such as details about a particular table) but also their content.
- Its ability to handle errors effectively. When an error occurs during the execution of a query, the SQL Agent can identify the issue, correct it, and then execute the revised query successfully.
In Langchain, we can initalize a SQL agent with the create_sql_agent function.
from langchain.agents import create_sql_agent
agent = create_sql_agent(
llm=llm_agent,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
toolkit=toolkit,
verbose=True,
)
- In this function, the llm is the large language model backbone of the agent. We chose OpenAI GPT models for this task but other models could also be suitable. Here is how we can define the LLM for the agent:
from langchain.chat_models import ChatOpenAI
from constants import chat_openai_model_kwargs, langchain_chat_kwargs
# Optional: set the API key for OpenAI if it's not set in the environment.
# os.environ["OPENAI_API_KEY"] = "xxxxxx"
def get_chat_openai(model_name):
llm = ChatOpenAI(
model_name=model_name,
model_kwargs=chat_openai_model_kwargs,
**langchain_chat_kwargs
)
return llm
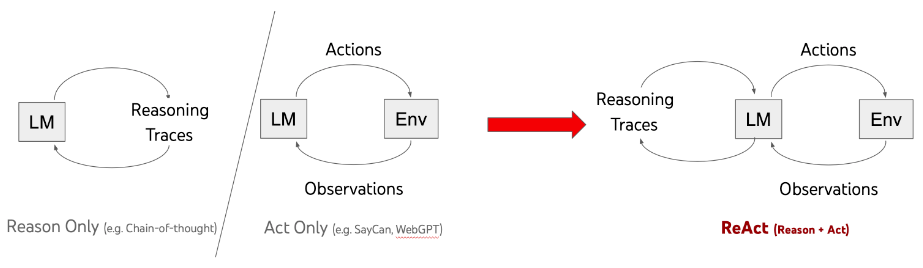
- Currently, the create_sql_agent function supports two types of agents: OpenAI functions and ReAct agents. We opted for ReAct agents due to their easier integration with memory features. The ReAct agent model uses large language models to generate reasoning and task-specific actions together. This method helps the agent to plan, track, and adjust its actions while dealing with exceptions. It also enables the agent to connect with external sources like knowledge bases to get more information, improving its effectiveness in tasks. More details about this framework can be found here.
- Finally the toolkit in the create_sql_agent function represents the SQL set of tools used to interact with the database. More on this in the next section !
SQL Database Toolkit
The SQLDatabaseToolkit contains tools that can:
- Create and execute queries: In the following example, the ReAct agent will call the sql_db_query tool with a certain SQL query as input. Following this, it analyzes the database results to formulate an appropriate response for the user.
Action: sql_db_query
Action Input: SELECT reference_fiche, nom_de_la_marque_du_produit, noms_des_modeles_ou_references, date_de_publication, liens_vers_les_images FROM rappel_conso_table WHERE categorie_de_produit = 'Alimentation' ORDER BY date_de_publication DESC LIMIT 1
Observation: [('2024-01-0125', 'MAITRE COQ', 'Petite Dinde', '2024-01-13', 'https://rappel.conso.gouv.fr/image/ea3257df-7a68-4b49-916b-d6f019672ed2.jpg https://rappel.conso.gouv.fr/image/2a73be1e-b2ae-4a31-ad38-266028c6b219.jpg https://rappel.conso.gouv.fr/image/95bc9aa0-cc75-4246-bf6f-b8e8e35e2a88.jpg')]
Thought:I now know the final answer to the question about the last recalled food item.
Final Answer: The last recalled food item is "Petite Dinde" by the brand "MAITRE COQ", which was published on January 13, 2024. You can find the images of the recalled food item here: [lien vers l'image](https://rappel.conso.gouv.fr/image/ea3257df-7a68-4b49-916b-d6f019672ed2.jpg), [lien vers l'image](https://rappel.conso.gouv.fr/image/2a73be1e-b2ae-4a31-ad38-266028c6b219.jpg), [lien vers l'image](https://rappel.conso.gouv.fr/image/95bc9aa0-cc75-4246-bf6f-b8e8e35e2a88.jpg).
- Check the query syntax with the sql_db_query_checker tool.
Action: sql_db_query_checker
Action Input: SELECT reference_fiche, nom_de_la_marque_du_produit, noms_des_modeles_ou_references, date_de_publication, liens_vers_les_images FROM rappel_conso_table WHERE categorie_de_produit = 'Alimentation' ORDER BY date_de_publication DESC LIMIT 1
Observation: ```sql
SELECT reference_fiche, nom_de_la_marque_du_produit, noms_des_modeles_ou_references, date_de_publication, liens_vers_les_images FROM rappel_conso_table WHERE categorie_de_produit = 'Alimentation' ORDER BY date_de_publication DESC LIMIT 1
```
Thought:The query has been checked and is correct. I will now execute the query to find the last recalled food item.
- Retrieve table descriptions with the sql_db_schema tool.
Action: sql_db_schema
Action Input: rappel_conso_table
Observation:
CREATE TABLE rappel_conso_table (
reference_fiche TEXT NOT NULL,
liens_vers_les_images TEXT,
lien_vers_la_liste_des_produits TEXT,
lien_vers_la_liste_des_distributeurs TEXT,
lien_vers_affichette_pdf TEXT,
lien_vers_la_fiche_rappel TEXT,
date_de_publication TEXT,
date_de_fin_de_la_procedure_de_rappel TEXT,
categorie_de_produit TEXT,
sous_categorie_de_produit TEXT,
nom_de_la_marque_du_produit TEXT,
noms_des_modeles_ou_references TEXT,
identification_des_produits TEXT,
conditionnements TEXT,
temperature_de_conservation TEXT,
zone_geographique_de_vente TEXT,
distributeurs TEXT,
motif_du_rappel TEXT,
numero_de_contact TEXT,
modalites_de_compensation TEXT,
risques_pour_le_consommateur TEXT,
recommandations_sante TEXT,
date_debut_commercialisation TEXT,
date_fin_commercialisation TEXT,
informations_complementaires TEXT,
CONSTRAINT rappel_conso_table_pkey PRIMARY KEY (reference_fiche)
)
/*
1 rows from rappel_conso_table table:
reference_fiche liens_vers_les_images lien_vers_la_liste_des_produits lien_vers_la_liste_des_distributeurs lien_vers_affichette_pdf lien_vers_la_fiche_rappel date_de_publication date_de_fin_de_la_procedure_de_rappel categorie_de_produit sous_categorie_de_produit nom_de_la_marque_du_produit noms_des_modeles_ou_references identification_des_produits conditionnements temperature_de_conservation zone_geographique_de_vente distributeurs motif_du_rappel numero_de_contact modalites_de_compensation risques_pour_le_consommateur recommandations_sante date_debut_commercialisation date_fin_commercialisation informations_complementaires
2021-04-0165 https://rappel.conso.gouv.fr/image/bd8027eb-ba27-499f-ba07-9a5610ad8856.jpg None None https://rappel.conso.gouv.fr/affichettePDF/225/Internehttps://rappel.conso.gouv.fr/fiche-rappel/225/Interne 2021-04-22 mercredi 5 mai 2021 Alimentation Cereales et produits de boulangerie GERBLE BIO BISCUITS 3 GRAINES BIO 3175681257535 11908141 Date de durabilite minimale 31/03/2022 ETUI CARTON 132 g Produit a conserver a temperature ambiante France entiere CASINO Presence possible d'oxyde d'ethylene superieure a la limite autorisee sur un lot de matiere premiere 0805293032 Remboursement Produits phytosanitaires non autorises Ne plus consommer Rapporter le produit au point de vente 19/03/2021 02/04/2021 None
Before defining the SQLDatabaseToolkit class, we must initialise the SQLDatabase wrapper around the Postgres database:
import os
from langchain.sql_database import SQLDatabase
from .constants_db import port, password, user, host, dbname
url = f"postgresql+psycopg2://{user}:{password}@{host}:{port}/{dbname}"
TABLE_NAME = "rappel_conso_table"
db = SQLDatabase.from_uri(
url,
include_tables=[TABLE_NAME],
sample_rows_in_table_info=1,
)
The sample_rows_in_table_info setting determines how many example rows are added to each table’s description. Adding these sample rows can enhance the agent’s performance, as shown in this paper. Therefore, when the agent accesses a table’s description to gain a clearer understanding, it will obtain both the table’s schema and a sample row from that table.
Finally let’s define the SQL toolkit:
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
def get_sql_toolkit(tool_llm_name):
llm_tool = get_chat_openai(model_name=tool_llm_name)
toolkit = SQLDatabaseToolkit(db=db, llm=llm_tool)
return toolkit
Extra tools
Given the complexity of our table, the agent might not fully understand the information in the database by only examining the schema and a sample row. For example, the agent should recognise that a query regarding cars equates to searching the ‘category’ column for the value ‘Automobiles et moyens de déplacement’ (i.e., ‘Automobiles and means of transportation’). Therefore, additional tools are necessary to provide the agent with more context about the database.
Here’s a breakdown of the extra tools we plan to use:
- get_categories_and_sub_categories: This tool is designed to help the agent fetch a list of distinct items from the category and sub_category columns. This approach is effective due to the relatively low number of unique values within these columns. If the columns contained hundreds or thousands of unique values, it might be better to use a retrieval tool. In such cases, when a user asks about a category, the agent could look for the most similar categories in a vector database, which stores embeddings of various values. The agent would then use these categories for its SQL queries. However, given that our category and sub_category columns don’t have a wide range of unique values, we’ll simply return the list directly.
from langchain.tools import tool, Tool
import ast
import json
from sql_agent.sql_db import db
def run_query_save_results(db, query):
res = db.run(query)
res = [el for sub in ast.literal_eval(res) for el in sub]
return res
def get_categories(query: str) -> str:
"""
Useful to get categories and sub_categories. A json is returned where the key can be category or sub_category,
and the value is a list of unique itmes for either both.
"""
sub_cat = run_query_save_results(
db, "SELECT DISTINCT sous_categorie_de_produit FROM rappel_conso_table"
)
cat = run_query_save_results(
db, "SELECT DISTINCT categorie_de_produit FROM rappel_conso_table"
)
category_str = (
"List of unique values of the categorie_de_produit column : n"
+ json.dumps(cat, ensure_ascii=False)
)
sub_category_str = (
"n List of unique values of the sous_categorie_de_produit column : n"
+ json.dumps(sub_cat, ensure_ascii=False)
)
return category_str + sub_category_str
- get_columns_descriptions: Since we can’t feed the columns descriptions in the schema directly, we created an extra tool that returns short description for every ambiguous column. Some examples include:
"reference_fiche": "primary key of the database and unique identifier in the database. ",
"nom_de_la_marque_du_produit": "A string representing the Name of the product brand. Example: Apple, Carrefour, etc ... When you filter by this column,you must use LOWER() function to make the comparison case insensitive and you must use LIKE operator to make the comparison fuzzy.",
"noms_des_modeles_ou_references": "Names of the models or references. Can be used to get specific infos about the product. Example: iPhone 12, etc, candy X, product Y, bread, butter ...",
"identification_des_produits": "Identification of the products, for example the sales lot.",
def get_columns_descriptions(query: str) -> str:
"""
Useful to get the description of the columns in the rappel_conso_table table.
"""
return json.dumps(COLUMNS_DESCRIPTIONS)
- get_today_date : tool that retrieves today’s date using python datetime library. The agent will use this tool when asked about temporality. For example: “What are the recalled products since last week ?”
from datetime import datetime
def get_today_date(query: str) -> str:
"""
Useful to get the date of today.
"""
# Getting today's date in string format
today_date_string = datetime.now().strftime("%Y-%m-%d")
return today_date_string
Finally we create a list of all these tools and we feed it to the create_sql_agent function. For every tool we must define a unique name within the set of tools provided to the agent. The description is optional but is very recommended as it can be used to provide more information.
def sql_agent_tools():
tools = [
Tool.from_function(
func=get_categories,
name="get_categories_and_sub_categories",
description="""
Useful to get categories and sub_categories. A json is returned where the key can be category or sub_category,
and the value is a list of unique items for either both.
""",
),
Tool.from_function(
func=get_columns_descriptions,
name="get_columns_descriptions",
description="""
Useful to get the description of the columns in the rappel_conso_table table.
""",
),
Tool.from_function(
func=get_today_date,
name="get_today_date",
description="""
Useful to get the date of today.
""",
),
]
return tools
extra_tools = sql_agent_tools()
agent = create_sql_agent(
llm=llm_agent,
toolkit=toolkit,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
extra_tools=extra_tools,
verbose=True,
)
Sometimes, the tool descriptions aren’t enough for the agent to understand when to use them. To address this, we can change the ending part of the agent LLM prompt, known as the suffix. In our setup, the prompt has three sections:
- Prefix: This is a string placed before the tool list. We’re sticking with the default prefix, which instructs the agent on how to create and execute SQL queries in response to user questions, set a limit on result numbers to 10 , check the queries carefully, and avoid making changes to the database.
- The list of tools: This part lists out all the tools that the agent has at its disposal.
- Suffix: This is the part where we give the agent directions on how to process and think about the user’s question.
Here’s the default suffix for the SQL ReAct agent in Langchain:
SQL_SUFFIX = """Begin!
Question: {input}
Thought: I should look at the tables in the database to see what I can query. Then I should query the schema of the most relevant tables.
{agent_scratchpad}"""
input and agent_scratchpad are two placeholders. input represents the user’s query and agent_scratchpad will represent the history of tool invocations and the corresponding tool outputs.
We can make the “Thought” part longer to give more instructions on which tools to use and when:
CUSTOM_SUFFIX = """Begin!
Question: {input}
Thought Process: It is imperative that I do not fabricate information not present in the database or engage in hallucination;
maintaining trustworthiness is crucial. If the user specifies a category, I should attempt to align it with the categories in the `categories_produits`
or `sous_categorie_de_produit` columns of the `rappel_conso_table` table, utilizing the `get_categories` tool with an empty string as the argument.
Next, I will acquire the schema of the `rappel_conso_table` table using the `sql_db_schema` tool.
Utilizing the `get_columns_descriptions` tool is highly advisable for a deeper understanding of the `rappel_conso_table` columns, except for straightforward tasks.
When provided with a product brand, I will search in the `nom_de_la_marque_du_produit` column; for a product type, in the `noms_des_modeles_ou_references` column.
The `get_today_date` tool, requiring an empty string as an argument, will provide today's date.
In SQL queries involving string or TEXT comparisons, I must use the `LOWER()` function for case-insensitive comparisons and the `LIKE` operator for fuzzy matching.
Queries for currently recalled products should return rows where `date_de_fin_de_la_procedure_de_rappel` (the recall's ending date) is null or later than today's date.
When presenting products, I will include image links from the `liens_vers_les_images` column, formatted strictly as: [lien vers l'image] url1, [lien vers l'image] url2 ... Preceded by the mention in the query's language "here is(are) the image(s) :"
Additionally, the specific recalled product lot will be included from the `identification_des_produits` column.
My final response must be delivered in the language of the user's query.
{agent_scratchpad}
"""
This way, the agent doesn’t just know what tools it has but also gets better guidance on when to use them.
Now let’s modify the arguments for the create_sql_agent to account for new suffix:
agent = create_sql_agent(
llm=llm_agent,
toolkit=toolkit,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
suffix=CUSTOM_SUFFIX,
extra_tools=agent_tools,
verbose=True,
)
Another option we considered was to include the instructions in the prefix. However, our empirical observations indicated that this had little to no impact on the final response. Therefore, we chose to retain the instructions in the suffix. Conducting a more extensive evaluation of the model outputs could be beneficial for a detailed comparison of the two approaches.
Implementing Memory Features
A useful feature for our agent would be the ability to remember past interactions. This way, it doesn’t have to start over with each conversation, especially when queries are connected.
To add this memory feature, we’ll take a few steps:
- First, we import the ConversationBufferMemory class. This is a buffer that keeps track of the conversation history.
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="history", input_key="input")
- Next, we update the suffix to include the conversation history.
custom_suffix = """Begin!
Relevant pieces of previous conversation:
{history}
(Note: Only reference this information if it is relevant to the current query.)
Question: {input}
Thought Process: It is imperative that I do not fabricate information ... (same as previous suffix)
{agent_scratchpad}
"""
- Finally, we adjust the create_sql_agent function to add the history into the prompt placeholders and include the memory in the agent executor arguments.
agent = create_sql_agent(
llm=llm_agent,
toolkit=toolkit,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
input_variables=["input", "agent_scratchpad", "history"],
suffix=custom_suffix,
agent_executor_kwargs={"memory": memory},
extra_tools=agent_tools,
verbose=True,
)
This way, the agent can use its memory to better handle related queries in a conversation.
Creating the application with Streamlit
We will use the python framework Streamlit to build a basic LLM chat app. Streamlit offers chat elements that can be used to construct a conversational application. The elements that we will use are:
- st.chat_input : a chat input widget that the user can use to type in a message.

- st.chat_message : This function adds a chat message to the app, displaying input from either the user or the application. The first argument specifies the message author, with “user” or “assistant” options to apply appropriate styling and avatars.

Additionally, we’ll utilize Streamlit’s session state to maintain a history of the conversation. This feature is crucial for providing a good user experience by preserving chat context.
More details on the process to create the conversational app can be found here.
Since we instructed the agent to always return the images urls, we created a post-processing function that fetches the images from these urls, formats the output, and displays the content using Streamlit’s markdown and image components. The implementation details for this functionality are available in the streamlit_app/gen_final_output.py module.
Now everything is set to start the chat application. You can execute the following command:
streamlit run streamlit_app/app.py
Future enhancements could include options for users to select the desired model and configure the OpenAI API key, further customizing the chat experience.
Observations and enhancements
Here are some insights we gained after running multiple dialogues with the agent:
- It’s not surprising, but GPT-4 is significantly better than GPT-3.5. The latter manages simple queries well but often struggles to invoke the necessary tools for additional context about the database, leading to frequent hallucinations.
- The complexity of the user’s question can make using GPT-4 both costly and slow. Generating detailed information like the database schema, row counts, and column descriptions uses a lot of tokens. Furthermore, if you’re looking for in-depth results, such as information on the last 10 recalled products, the agent has to process the query’s output along with the tools’ actions and observations, which can be very expensive. Therefore, it’s important to keep an eye on your usage to avoid unexpected costs.
To enhance the agent’s performance, we can:
- Refine how we engineer prompts, adjusting the suffix and/or prefix to better anticipate and efficiently invoke the right tools when needed.
- Include a few examples in the prompt, or employ a retrieval tool to find the most relevant examples for common user queries, reducing the need to repeatedly invoke the same tools for each new question.
- Add an evaluation framework to assess for instance the LLMs performance based on the final answer, or to compare prompts.
Conclusion
To wrap up, this article delved into creating a chat application that uses Large Language Models (LLMs) to communicate with SQL databases via the Langchain framework. We utilized the ReACT agent framework, along with various SQL tools and additional resources, to be able to respond to a wide range of user queries.
By incorporating memory capabilities and deploying via Streamlit, we’ve created a user-friendly interface that simplifies complex database queries into conversational exchanges.
Given the database’s complexity and the extensive number of columns it contains, our solution required a comprehensive set of tools and a powerful LLM.
We already talked about ways to enhance the capabilities of the chatbot. Additionally, using an LLM fine-tuned on SQL queries can be a substitute approach to using a general model like GPT. This could make the system much better at working with databases, helping it get even better at figuring out and handling tough queries.
References
- [2210.03629] ReAct: Synergizing Reasoning and Acting in Language Models (arxiv.org)
- Langchain SQL database
- Langchain SQL agent
- Langchain agents and tools documentation
- Build a basic LLM chat app with Streamlit
- An article on LLMs and SQL on Langchain’s blog.
Building a Chat App with LangChain, LLMs, and Streamlit for Complex SQL Database Interaction was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Building a Chat App with LangChain, LLMs, and Streamlit for Complex SQL Database Interaction