Testing assumptions with path models

Data Scientists often collect a multitude of variables and search for relationships between them. During this journey, it is helpful to have assumptions and hypotheses on how exactly variables relate to each other. Does a student’s motivation to study for the next exam influence their grades? Or do good grades lead to motivation to study at all? And what exactly are the behavioral patterns that motivated people show that lead to good grades in the end?
To give some structure to questions like the aforementioned and to provide a tool to test them empirically, I want to explain path models, also called Structural Equation Models (SEMs) in this article. While in social sciences like psychology path models are commonly used, I feel they are not that prominent in other areas like data science and computer science. Hence I want to give an overview of the main concept of path analysis and introduce semopy, which is a package for applying path analysis in python. Throughout this article, we will analyze artificial data to showcase typical problems that can be solved with path models and introduce the concepts of moderators and mediators. Be aware that this data has been generated for demonstration purposes and may not be realistic in every detail.
Research question

If we want to analyze data, we need to have a research question in mind that we want to investigate. For this article, let us investigate school children and the grades they achieve. We might be interested in factors that foster learning and achieving good grades. That could be the amount of fun they have in school, their feeling of belonging to class, their interest in the subject, their number of friends in the class, their relationship with the teacher, their intelligence and much more. So we go into different schools and collect data by handing out questionnaires on the feeling of belonging, the relationship with the teacher, the interest in the topic and the fun the pupils have in school, we conduct an IQ test with the pupils and we ask them how many friends they have. And of course we collect their grades in the exams.
It all starts with data
We now have data for all the variables shown here:

Our next step is to investigate, how exactly the variables influence the grade. We can make different assumptions about the influences and we can verify these assumptions with the data. Let us start with the most trivial case, where we assume that each variable has a direct influence on the grades that is independent of all the other variables. For example, we would assume that higher intelligence leads to a better grade, no matter the interest in the topic or the fun the pupil has in school. A likewise relationship with the grades we would hypothesize for the other variables as well. Visually displayed, this relationship would look like this:
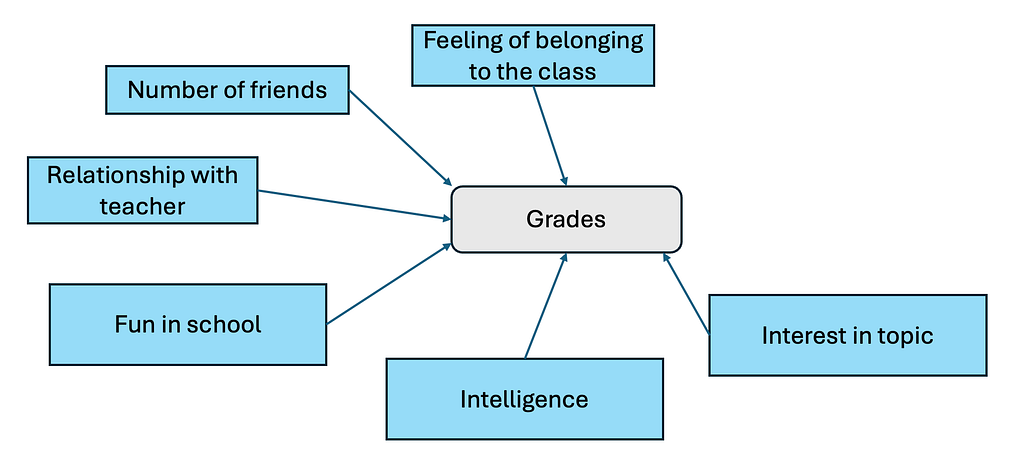
Each arrow describes an influence between the variables. We could also formulate this relationship as a weighted sum, like this:
grades = a*feeling_of_belonging + b*number_of_friends + c*relationship_with_teacher + d*fun_in_school + e*intelligence + f*interest_in_topic
Here a,b,c,d,e and f are weights that tell us, how strong the influence of the different variables is on our outcome grades. Okay, that is our assumption. Now we want to test this assumption given the data. Let’s say we have a data frame called data, where we have one column for each of the aforementioned variables. Then we can use semopy in python like this:
import semopy
path = """
grades ~ intelligence + interest_in_topic
+ feeling_of_belonging + relationship_with_teacher
+ fun_in_school + number_of_friends
"""
m = semopy.Model(path)
m.fit(data)
In the last lines, we create a semopy.Model object and fit it with the data. The most interesting part is the variable path before. Here we specify the assumption we just had, namely that the variable grades is a combination of all the other variables. On the left part of the tilde (~) we have the variable that we expect to be dependent on the variables right to the tilde. Note that we didn’t explicitly specify the weights a,b,c,d,e and f. These weights are actually what we want to know, so let us run the following line to get a result:
m.inspect()

The weights a,b,c,d,e and f are what we see in the column Estimate. What information can we extract from this table? First, we see that some weights are bigger and some are smaller. For example, the feeling_of_belonging has the biggest weight (0.40), indicating that it has the strongest influence. Interest_in_topic, for example, has a much lower influence (0.08) and other variables like intelligence and number_of_friends have a weight of (almost) zero.
Also, take a look at the p-value column. If you are familiar with statistical tests, you may already know how to interpret this. If not, don’t worry. There is a vast pile of literature on how to understand the topic of significance (this is what this column indicates) and I encourage you to deepen your knowledge about it. However, for the moment, we can just say that this column gives us some idea of how likely it is, that an effect we found is just random noise. For example, the influence of number_of_friends on grades is very small (-0.01) and it is very likely (0.42), that it is just a coincidence. Hence we would say there is no effect, although the weight is not exactly zero. The other way round, if the p-value is (close to) zero, we can assume that we indeed found an effect that is not just coincidence.
Okay, so according to our analysis, there are three variables that have an influence on the grade, that are interest_in_topic (0.08), feeling_of_belonging (0.40) and relationship_with_teacher (0.19). The other variables have no influence. Is this our final answer?
It is not! Remember, that the calculations performed by semopy were influenced by the assumptions we gave it. We said that we assume all variables to directly influence the grades independent of each other. But what if the actual relationship looks different? There are many other ways variables could influence each other, so let us come up with some different assumptions and thereby explore the concepts of mediators and moderators.
Mediators

Instead of saying that both number_of_friends and feeling_of_belonging influence grades directly, let us think in a different direction. If you don’t have any friends in class, you would not feel a sense of belonging to the class, would you? This feeling of (not) belonging might then influence the grade. So the relationship would rather look like this:

Note that the direct effect of number_of_friends on grades has vanished but we have an influence of number_of_friends on feeling_of_belonging, which in turn influences grades. We can take this assumption and let semopy test it:
path = """
feeling_of_belonging ~ number_of_friends
grades ~ feeling_of_belonging
"""
m = semopy.Model(path)
m.fit(data)
Here we said that feeling_of_belonging depends on number_of_friends and that grades depends on feeling_of_belonging. You see the output in the following. There is still a weight of 0.40 between feeling_of_belonging and grades, but now we also have a weight of 0.29 between number_of_friends and feeling_of_belonging. Looks like our assumption is valid. The number of friends influences the feeling of belonging and this, in turn, influences the grade.

The kind of influence we have modelled here is called a mediator because one variable mediates the influence of another. In other words, number_of_friends does not have a direct influence on grades, but an indirect one, mediated through the feeling_of_belonging.
Mediations can help us understand the exact ways and processes by which some variables influence each other. Students who have clear goals and ideas of what they want to become are less likely to drop out of high school, but what exactly are the behavioral patterns that lead to performing well in school? Is it learning more? Is it seeking help if one doesn’t understand a topic? These could both be mediators that (partly) explain the influence of clear goals on academic achievement.
Moderators

We just saw that assuming a different relationship between the variables helped describe the data more effectively. Maybe we can do something similar to make sense of the fact that intelligence has no influence on the grade in our data. This is surprising, as we would expect more intelligent pupils to reach higher grades on average, wouldn’t we? However, if a pupil is just not interested in the topic they wouldn’t spend much effort, would they? Maybe there is not a direct influence of intelligence on the grades, but there is a joint force of intelligence and interest. If pupils are interested in the topics, the more intelligent ones will receive higher grades, but if they are not interested, it doesn’t matter, because they don’t spend any effort. We could visualize this relationship like this:

That is, we assume there is an effect of intelligence on the grades, but this effect is influenced by interest_in_topic. If interest is high, pupils will make use of their cognitive abilities and achieve higher grades, but if interest is low, they will not.
If we want to test this assumption in semopy, we have to create a new variable that is the product of intelligence and interest_in_topic. Do you see how multiplying the variables reflects the ideas we just had? If interest_in_topic is near zero, the whole product is close to zero, no matter the intelligence. If interest_in_topic is high though, the product will be mainly driven by the high or low intelligence. So, we calculate a new column of our dataframe, call it intelligence_x_interest and feed semopy with our assumed relationship between this variable and the grades:
path = """
grades ~ intellgence_x_interest
"""
m = semopy.Model(path)
m.fit(data)
And we find an effect:

Previously, intelligence had no effect on grades and interest_in_topic had a very small one (0.08). But if we combine them, we find a very big effect of 0.81. Looks like this combination of both variables describes our data much better.
This interaction of variables is called moderation. We would say that interest_in_topic moderates the influence of intelligence on grades because the strength of the connection between intelligence and grades depends on the interest. Moderations can be important to understand how relations between variables differ in different circumstances or between different groups of participants. For example, longer experience in a job influences the salary positively, but for men, this influence is even stronger than for women. In this case, gender is the moderator for the effect of work experience on salary.
Summing up
If we combine all the previous steps, our new model looks like this:
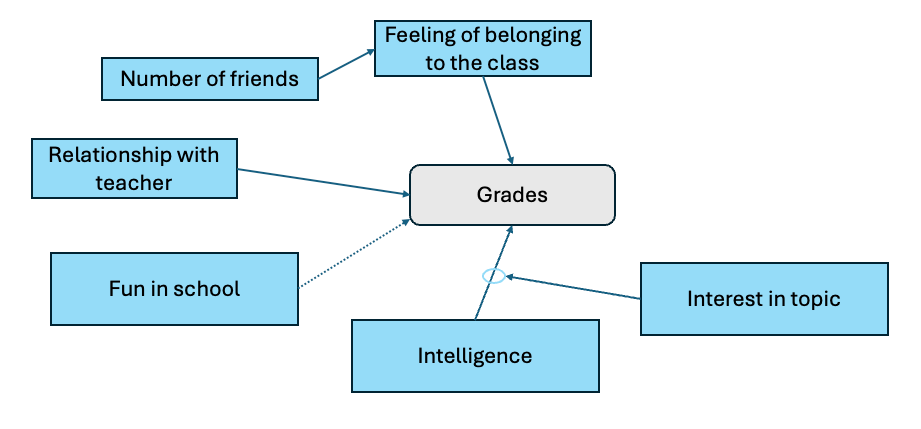

Now we have a more sophisticated and more plausible structure for our data. Note that fun_in_school still has no influence on the grades (hence I gave it a dashed line in the visualization above). Either there is none in the data, or we just did not find the correct interplay with the other variables yet. We might even be missing some interesting variables. Just like intelligence only made sense to look at in combination with interest_in_topic, maybe there is another variable that is required to understand the influence fun_in_school has on the grades. This shows you, that for path analysis, it is important to make sense of your data and have an idea what you want to investigate. It all starts with assumptions which you derive from theory (or sometimes from gut feeling) and which you then test with the data to better understand it.
This is what path models are about. Let us sum up what we just learned.
- Path models allow us to test assumptions on how exactly variables influence each other.
- Mediations appear, if a variable a does not have a direct influence on a variable c, but influences another variable b, which then influences c.
- We speak of moderations if the influence of a variable a on a variable c becomes stronger or less strong depending on another variable b. This can be modelled by calculating the product of variables.
- Semopy can be used to test path models with given data in python.
I hope I have been able to convince you of the usefulness of path models. What I showed you is just the very beginning of it though. Many more sophisticated assumptions can be tested with path models or other models derived from them, that go way beyond the scope of this article.
References
You can find semopy here:
If you want to learn more about path analysis, Wikipedia can be a good entry point:
I use this book for statistical background (unfortunately, it is available in German only):
- Eid, M., Gollwitzer, M., & Schmitt, M. (2015). Statistik und Forschungsmethoden.
This is how the data for this article has been generated:
import numpy as np
import pandas as pd
np.random.seed(42)
N = 7500
def norm(x):
return (x - np.mean(x)) / np.std(x)
number_of_friends = [int(x) for x in np.random.exponential(2, N)]
# let's assume the questionairs here had a range from 0 to 5
relationship_with_teacher = np.random.normal(3.5,1,N)
relationship_with_teacher = np.clip(relationship_with_teacher, 0,5)
fun_in_school = np.random.normal(2.5, 2, N)
fun_in_school = np.clip(fun_in_school, 0,5)
# let's assume the interest_in_topic questionaire goes from 0 to 10
interest_in_topic = 10-np.random.exponential(1, N)
interest_in_topic = np.clip(interest_in_topic, 0, 10)
intelligence = np.random.normal(100, 15, N)
# normalize variables
interest_in_topic = norm(interest_in_topic)
fun_in_school = norm(fun_in_school)
intelligence = norm(intelligence)
relationship_with_teacher = norm(relationship_with_teacher)
number_of_friends = norm(number_of_friends)
# create dependend variables
feeling_of_belonging = np.multiply(0.3, number_of_friends) + np.random.normal(0, 1, N)
grades = 0.8 * intelligence * interest_in_topic + 0.2 * relationship_with_teacher + 0.4*feeling_of_belonging + np.random.normal(0,0.5,N)
data = pd.DataFrame({
"grades":grades,
"intelligence":intelligence,
"number_of_friends":number_of_friends,
"fun_in_school":fun_in_school,
"feeling_of_belonging": feeling_of_belonging,
"interest_in_topic":interest_in_topic,
"intellgence_x_interest" : intelligence * interest_in_topic,
"relationship_with_teacher":relationship_with_teacher
})
Like this article? Follow me to be notified of my future posts.
Bringing Structure to Your Data was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Bringing Structure to Your Data