
Inpainting radar gaps with deep learning
Overview
In this post, we review high-level details from our recent work on image inpainting of radar blind zones. We discuss the main science problems, inpainting techniques, model architecture decisions, fidelity metrics, uncertainties, and finish with an analysis of model explainability (XAI), in the hope that this information can help others when planning future, similar projects. This work was recently published in the American Meteorologic Society’s Artificial Intelligence for Earth Sciences (AIES) https://doi.org/10.1175/AIES-D-23-0063.1, which we recommend readers view for additional project details.
Motivation
Radar observations are powerful sources of information for tasks like precipitation forecasting. These systems are used by millions of people daily to help plan their lives, and their predictive accuracy has large economic impacts to agriculture, tourism, and the outdoor recreation industry. But how do these systems work? In a nutshell, these predictive models relate precipitation rates to power backscatter measurements from a radar signal interacting with falling hydrometeors in the atmosphere (Fig. 1). With a large enough reference dataset, we can take the information produced by the radar profile (along with some atmospheric state variables) and back-out an estimate of surface precipitation.

Unlike vertical-pointing surface radar instruments which are stationary, satellites are unrestricted in space and can provide a much richer, comprehensive view of global precipitation patterns due to their orbit. However, unlike surface radars, satellite instruments exhibit a unique type of measurement problem since they point down towards the Earth: a radar blind zone. As implied by its name, the blind zone is a portion of the radar profile that the satellite cannot directly observe. As the downward pointed radar signal reaches the Earth’s surface, the backscatter from the ground produces an attenuated signal that becomes saturated with noise (and therefore unobserved). A comparison between surface and spaceborne radars (and the corresponding blind zone) is illustrated in Fig. 2.
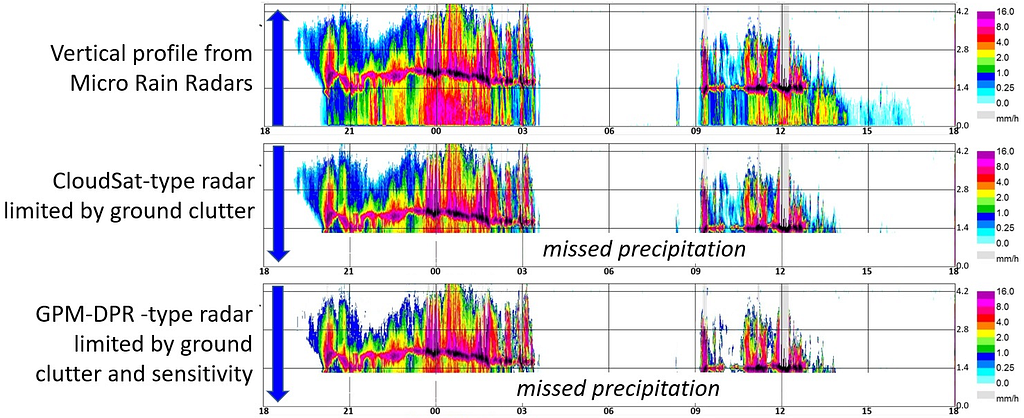
While the size of the blind zone region can vary, it is a common issue on active spaceborne systems (e.g. GPM, CloudSat) that will persist as a source of uncertainty in future Earth observing missions (e.g. EarthCARE and AOS). Additionally, although this region is just a small subset of the full profile (only about 4% of CloudSat’s vertical extent, for instance), this 0–2 km of the atmosphere can contain large quantities of precipitating cloud (Lamer et al., 2020). Therefore, by masking this region, we are potentially missing a large quantity of snow (or overestimating snow in the case of virga), further increasing the uncertainty of an already uncertain estimate of surface snow accumulation.
… the blind zone leads to reflectivity being underestimated by up to 1 dB, the number of events being altered by +/- 5% and the precipitation amount being underestimated by 9 to 11 percentage points (Maahn et al., 2014).
What can we do about this?
Our Solution
At its core, the ideas behind image inpainting have been around for decades for use in things like image restoration (e.g. removing a scratch on a family photo), or object removal (removing a tourist in a picture from your last vacation) (Guillemot and Le Meur, 2013). Originally, this type of repair was a costly endeavour that was done by hand by a trained artist (Fig. 2), but as has become increasingly clear in recent years, computers are quite skilled at this task too (with much shorter training times compared to a human)!

While the first iterations of these techniques like structure-based linear interpolation, texture-synthesis-based Efros interpolation, and diffusion-based Laplace or Navier-Stokes interpolation can work well in certain contexts, they often fell short when dealing with large gaps. The differences between these techniques are shown in Fig. 4 where an elephant mask is inpainted in the center of the image. These techniques rely heavily on information/patterns from the edges of the targeted inpainting region and are often unable to effectively make use information from the scene’s global context when making intelligent predictions.

However, the field of computer vision has flourished in recent decades, primarily driven by advances in computing power and the development of newer, more efficient machine learning techniques. Generative approaches using Generative Adversarial Networks (GANs) for instance have been very popular recently with OpenAI’s DALL-E, or Stability.ai’s Stable Diffusion, producing incredibly realistic images based on a simple text prompt. There has also been some work previously attempting to use similar methods for inpainting, but there exists a trade-off between realism and fidelity/stability for inpainting taskings (Lugmayr et al., 2017; Geiss and Hardin, 2021).
For instance, while you might generate a region of an image that looks great to the human eye, the actual pixel values are not necessarily correct if compared to a reference image and may vary quite a bit based on the provided random noise/seed (Fig. 5). This is not unexpected, though, as these techniques are not necessarily constructed with such constraints in mind and exist for other purposes.

Instead, we focus on another machine learning architecture in this work: the U-Net. U-Nets are a class of Convolutional Neural Networks (CNNs), that ingest information in the form of an image (typically) and produce an output that is of the same dimensions. Often used for image segmentation, the encoder-decoder architecture of the U-Net allow the model to learn both local and global features of an image (context that is often quite valuable for correctly interpreting an image’s content during inpainting). We will use this architecture to teach the model to learn about latent features in aloft cloud to predict near surface reflectivity data in the aforementioned radar blind zone.
Data
The data used in this project comes from primary two sources:
Both datasets are publicly available (governed by the Creative Commons Attribution 4.0 International (CC BY 4.0)) and are collocated at two Arctic locations in northern Alaska, USA at North Slope and Oliktok Point (Fig. 6). Since we are focused on snowfall, we limit our observations to cold periods below 2 degrees C. Further, data is split in contiguous training/validation/testing chunks to avoid overfitting from autocorrelation as shown in Fig. 6.c. We are using radar reflectivity data from the ARM KaZR, along with temperature, specific humidity, u-component wind, and v-component wind from ERA-5.

Our Model
What type of U-Net should be used for this task? We experimented with a variety of different U-Nets in this project, including the UNet++ model from Zhou et al., 2018 and the 3Net+ from Huang et al., 2020. But let’s talk about the model architecture for a moment. For instance, why use these methods over a just a traditional U-Net? First let’s review how U-Nets work.
U-Nets are primarily thought of in three parts, an encoder path, a bottleneck layer, and a decoder path. The encoder is responsible for taking your initially high-resolution image, and through a series of convolutions and pooling steps, trades spatial information for rich feature information (learning about the latent context of your image). Depending on how deep your network is, these latent features are encoded most densely in the lowest dimensionality bottleneck layer at the base of the U. At this point, the image array may be only a fraction of the size of the original, and while you’ve lost most of the spatial information, the model has identified a set of embeddings that represent what it sees as key elements. Then, in the decoder path, the reverse occurs. The low-resolution, feature-rich arrays in the bottleneck layer are downsampled until the feature information has been transformed back into spatial information (resulting in a final image that has the same dimensions as the original).
One of the key differences between a U-Net, U-Net++ and 3Net+, is how each variation handles skip connections (Fig. 7). Skip connections allow these models to “skip” some data directly across the encoder path to be used in the decoder, which helps in conveying low-level feature information during decoding and produces a more stable model that converges in meaningful ways. In a vanilla U-Net for example, these connections simply concatenate feature maps from the contracting encoder path to the corresponding level in the decoding expansive path.

The UNet++ introduces a series of nested and dense skip pathways that attempt to address the issue of the unknown depth of the optimal architecture in a traditional U-Net. Instead of just having direct connections from the encoder to the decoder, the UNet++ has multiple skip pathways. For a given level in the encoder, there are skip connections to all subsequent levels in the decoder, creating a dense set of connections. These nested skip connections are designed to capture and fuse features at various semantic levels more effectively than the vanilla U-Net, however this comes at the cost of a larger model (more parameters) and increased training times.
The 3Net+ builds on ideas of both previous techniques and is the architecture used in our final model (Fig. 8). This method breaks the skip connections into a series of across-skip connections (similar to the vanilla U-Net), inter-skip connections, and intra-skip connections. These inter- and intra- skip connections make full use of multi-scale features in the scene by passing information in a manner which incorporates low-level details with high-level semantics from feature maps in full scales, but with fewer parameters to the U-Net++ model.
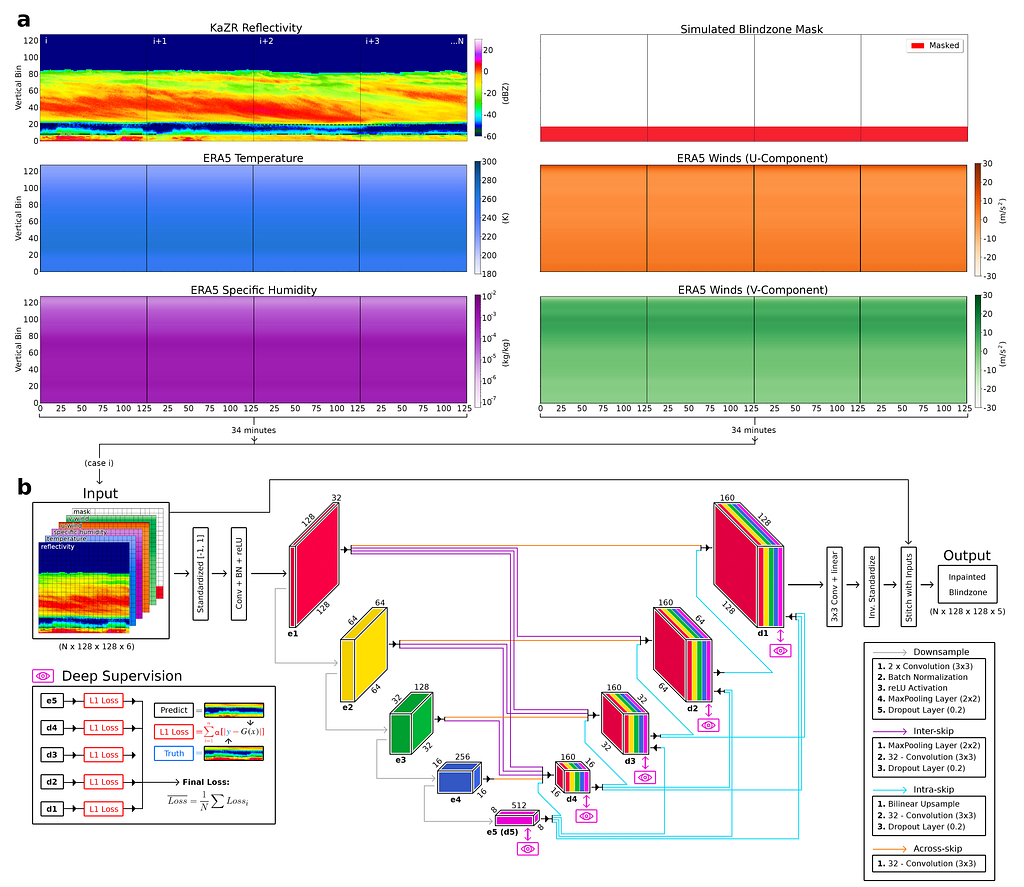
Further, our model makes use of deep supervision to learn hierarchical representations from the full-scale aggregated feature maps at each level of the decoder. This helps the model learn to correctly position clouds within the blind zone by examining the wider context of the scene. In the remaining sections we will compare the skill of this 3Net+ model trained on just reflectivity (herein denoted as 3+_1), another version trained on reflectivity and ERA5 data (3+_5) and two linear inpainting techniques using repeating extrapolation (REP) and marching average (MAR) methods. For additional details on how these are implemented, please refer to our AIES paper.
Fidelity
To comprehensively evaluate model performance in blind zone reconstructive accuracy, we will first examine a handful of common cases, followed by a more general statistical analysis of the full test dataset. Note that all results shown from here on out are strictly taken from the unseen test set of observations.
Case Studies
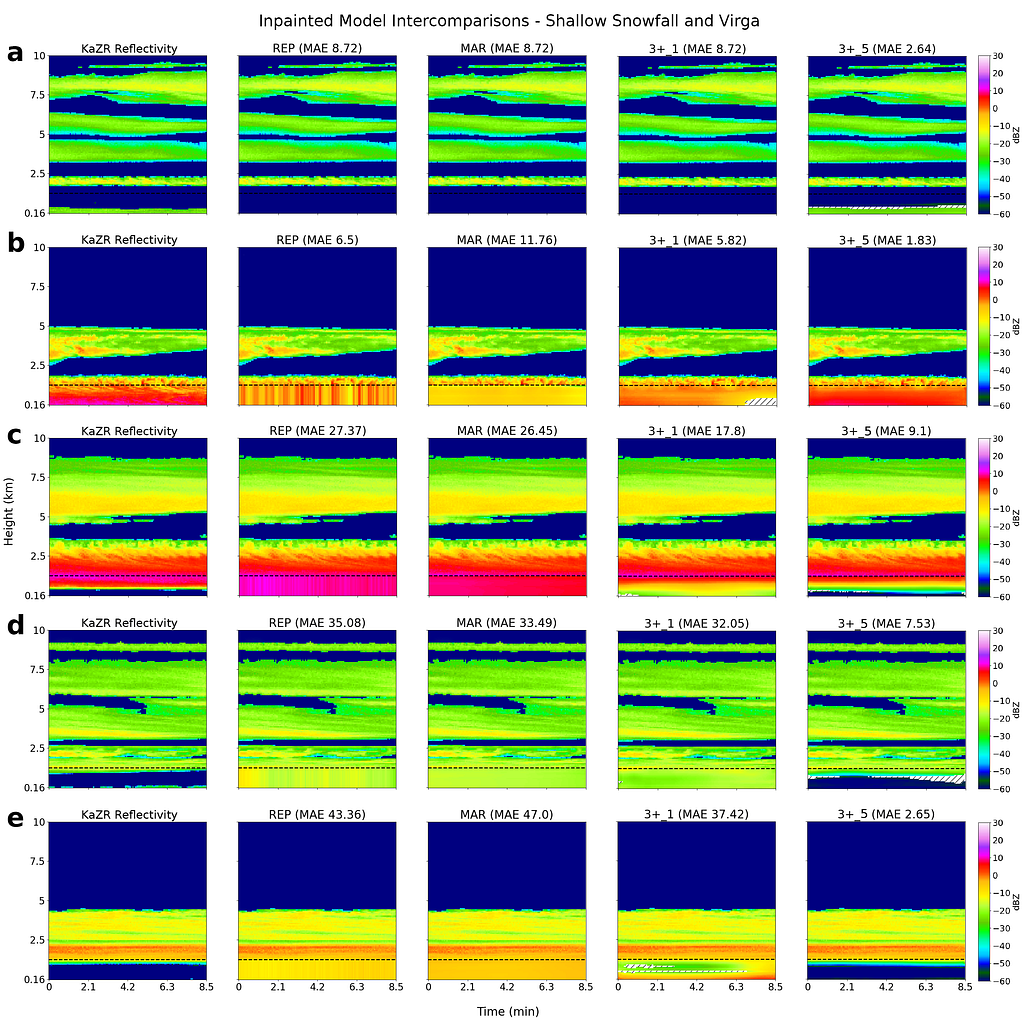
Examples of inpainted blind zone reflectivity values (taken from both NSA and OLI) for REP, MAR, 3+ 1 and 3+ 5 models, along with the corresponding target KaZR VAP product (i.e. the ground truth) in the far left column are shown below in Figs. 9/10.
This first set of examples highlights cases of near surface reflectivity gradients and cloud gaps that are common at both locations. The black dashed line indicates the 1.2 km blind zone threshold (values below this are masked and reconstructed by each model), and the shaded regions indicate areas of high uncertainty in the inpainted U-Net predictions (more on this later in the Monte Carlo Dropout section).

We find that the linear models (REP and MAR) perform well for deep, homogeneous systems, but fall short in more complex cases. Further, due to their reliance on blind zone threshold reflectivities, reflectivity gradients (vertical and horizontal) are missed by REP and MAR (and usually captured using the U-Nets). Finally, shallow, Arctic mixed-phase clouds can also be resolved using U-Nets, along with cloud gaps and cases of virga (Fig. 10), which is exciting as this has substantial implications to surface snowfall quantities.
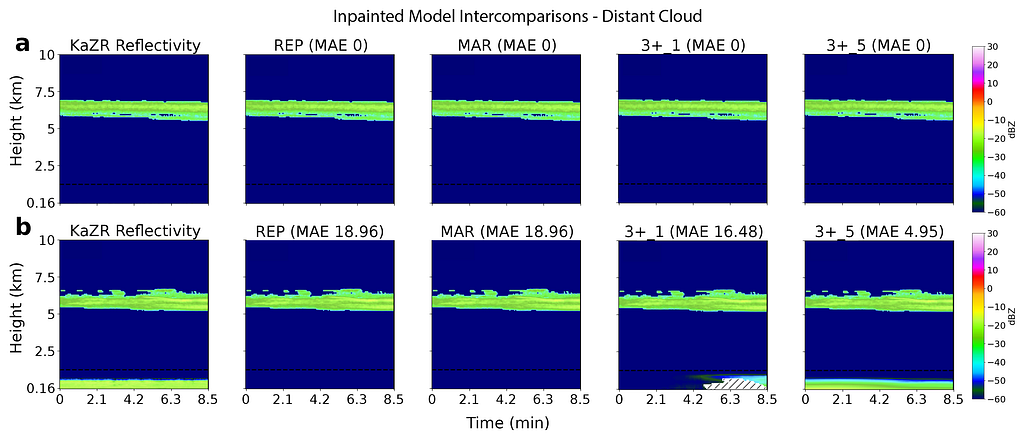
The most challenging cases to accurately model are those with sparse reflectivity profiles and distant cloud. For instance, consider Fig. 11 showing two similar cases at NSA occurring in different years. To the human eye, both locations have very similar cloud structures, however one has a shallow near surface cloud in the blind zone while the other does not. The linear inpainting techniques are clearly well outside of their comfort zone here and will always produce the same “no cloud” output as we see in a). However, the U-Net models are still able to resolve cloud presence in cases such as this, with the 3+_5 model using the additional context from ERA-5 to better understand that the atmospheric conditions in this case likely result in blind zone cloud.
Robustness
As we can see in Fig. 12 a), the U-Net PSD curves are closer to observations compared to the linear methods. Further, the nonlinear reconstructions produce a more realistic lowest cloud echo height (shown in the probability density plots of b), suggesting that we are better capturing cloud positions. Finally, the entire blind zone structure is summarized in c)-g), where the linear methods are able to capture general macro-scale trends in reflectivity but fall short of capturing the fine-scale variability. We do note that the U-Net models have a slight “cold” bias towards -60 dBZ due to their tendency to produce “safer” estimates closer to “no cloud” over much rarer, high intensity snowfall events.
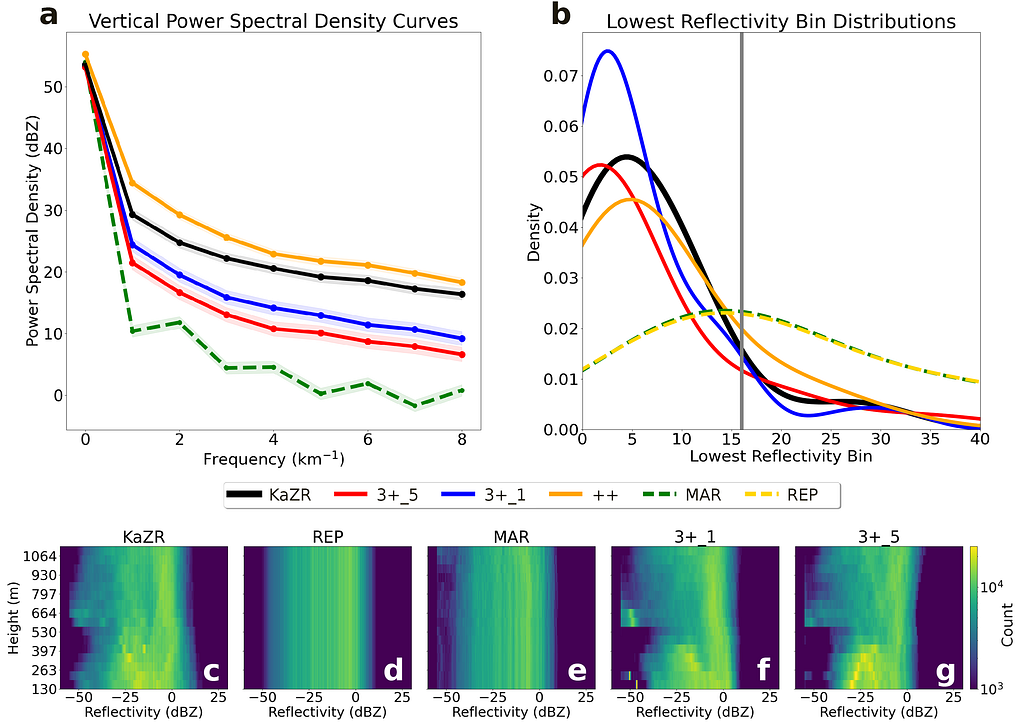
Further, improving our predictions of surface snowfall and virga cases would have substantial hydrologic implications and reduce our uncertainty in snow accumulation quantities. So, we performed checks to see how well three cases were reconstructed with our model using probability of detection (POD) and false alarm rate (FAR):
- Blind zone cloud presence (i.e. was any cloud detected)
- Shallow snowfall (i.e. was there snowfall at the surface but not at the blind zone threshold)
- Virga (i.e. was there snowfall detected at the blind zone threshold but not at the surface)
The critical success index (CSI) for each of these metrics is shown in the performance diagram below (Fig. 13), with the 3+_5 model performing the best overall. Shallow snowfall cases were typically the hardest to reconstruct, as we saw these cases can be quite tricky to get right (Fig. 11).

Explainability
To add further trust in the model’s decision-making process, we also performed a series of eXplainable Artificial Intelligence (XAI) tests (i.e., thinking towards a mechanistic interpretation of model behaviour). These tests were aimed at connecting model behaviour to logical physical processes to both inspire confidence in the model and provide additional insights for potentially enhancing future retrievals. If we can learn about previously unknown connections in the data, that can be very valuable! Separately, each individual XAI method gives a slightly different “local” explination of the decision-making process, and it is therefore useful to incorporate multiple tests to derive a more robust understanding.
Feature Maps
The first, most basic, test we considered were feature/activation maps. By examining the values of the reLU activator in different levels of the encoder path of Fig. 8.b, we get a rough idea of where the model is looking in an image for a given input. As shown in Fig.14 below, the e1 encoder layer of the 3+_5 model typically looked along cloud edges, at reflectivity gradients and directly along the blind zone threshold.

Drop Channel Importance
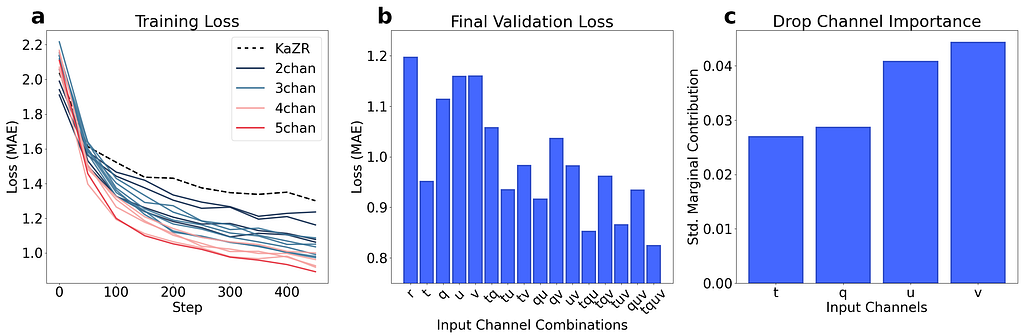
One of the biggest questions in this project was whether ERA-5 was providing useful context to the model. If we can use a more simplistic U-Net that only relies on reflectivity for instance (i.e. the 3+_1 model), then we should do so, as this would be more computationally efficient. However, if the additional atmospheric state variables from ERA-5 provide the model with useful context for inpainting complex systems, then the use of this more complex model may be warranted.
Since we only have a handful of inputs in this case (1 mandatory (radar) and 4 supplementary (temperature, humidity, u-wind, and v-wind), we can do an exhaustive search of the input space to evaluate their marginal contributions to accuracy. More formally, this drop-channel approach uses the below formula (Eq. 1/ Eq. 2) to calculate marginal contributions of importance from the provided inputs. Note that this technique does not consider potential nonlinear interactions between inputs.
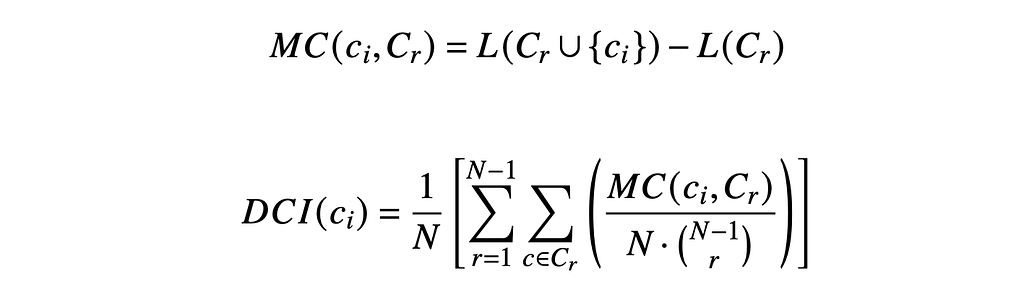
If we perform a series of this test runs (25 epochs) and examine changes in the validation loss, we can gain some rough insight into which inputs are most useful. The results of these tests are shown below in Fig. 15, where we note a trend of decreasing validation loss as we add more ERA-5 inputs (suggesting that none of the inputs are wholly unimportant). Further, the marginal contributions to validation loss suggest that the wind data is the most influential overall. We believe that this importance may stem from that fact that in the upper troposphere, wind patterns can hint at mesoscale atmospheric dynamics, such as the presence of high or low-pressure systems, fronts, and jet streams (which are of course linked to cloud/hydrometeor formation).
Saliency Maps
Finally, we also examined saliency maps for a handful of cases (Fig. 16), to further compare the differences in importance between the 3+_5 and 3+_1 models. These pixel attribution vanilla gradient saliency maps are inspired by the work of Simonyan et al., 2014, and provide additional insight into areas the model identifies as crucial contributors of information for inpainting accuracy using a given input. These saliency maps are generated by running an image through the network and subsequently extracting the gradients of the output based on the input across all channels. While simplistic, this method is particularly useful for visualizing which parts of the observed image are most valuable in inpainting the blind zone reflectivity values, allowing for direct plotting of the activation gradients.
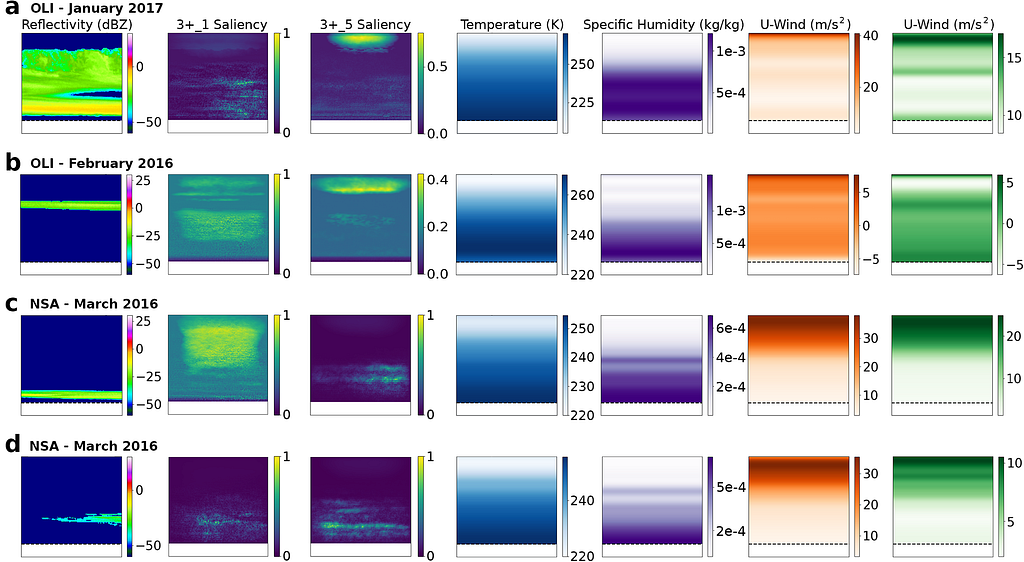
For multilayer clouds that intersect with the blind zone cut-off (e.g. Fig. 16.a), both models focus on the top of the cloud and the 1.2 km boundary threshold, as these systems often continue to extend down to the surface with similar reflectivity intensities. Both models also typically focus on and around cloud gaps in deeper systems (e.g. Fig. 16.b), however, a distinct halo of importance towards the tropopause is noticeable in the 3+_5 model. This recurring feature is likely incorporating upper troposphere wind and humidity data into predictions of near surface reflectivity. Interestingly, the 3+_1 model does not solely focus on the areas of high reflectivity in the scene but also on the regions around the cloud.
Applications
The motivating goal of this work is to eventually apply a surface trained U-Net to spaceborne observations. While additional work needs to be completed on resolution-matching between these two systems, we performed early tests against coincident CloudSat-CPR observations near NSA. The idea here being that both systems (while not perfectly overlapped), will be observing similar portions of the same storm system. We consider a handful of examples and include one below for a shallow cumuliform snowfall case.

In this example, we noted that both the spaceborne and surface radars observed a shallow cloud about 3 km tall (however CloudSat misses the increased reflectivity gradient below the blind zone due to surface clutter). When this region is reconstructed using both the traditional techniques and our U-Net, we find the U-Net is the only method that can accuratly represent the band of increased reflectivity around 1 km. More formally, if we look at the structure between the nearest CloudSat observation to the site (white dashed line) to each of the closest reconstructed regions, Pearson correlations are substantially improved using the U-Net (r_MAR=0.13 to r_3+_1=0.74).
While these examples don’t comprise a comprehensive anaylsis allowing us to say something about general performance, they do indicate that we see skill consistent with what we have previous noted when looking at the simulated surface blind zone. Further application work to spaceborne instruments is ongoing.
Final Notes
Before we finish up this already long post, I wanted to highlight a few of the other features we built into the model and provide some training code examples for those interested in developing their own inpainting model.
Monte Carlo Dropout
Unlike traditional Bayesian methods, we do not directly produce a physically-based uncertainty estimate using a U-Net. To get a rough idea of model confidence and stability, we decided to introduce a dropout at inference layer to the model based on the work of Gal and Ghahramani, 2016 which allows us to generate a distribution of inpainted predictions for each test case. These distributions allow us to produce confidence intervals for each inpainted pixel, and further refine our estimates to regions that model is more certain of when inpainting. An example of this is shown below in Fig. 17.
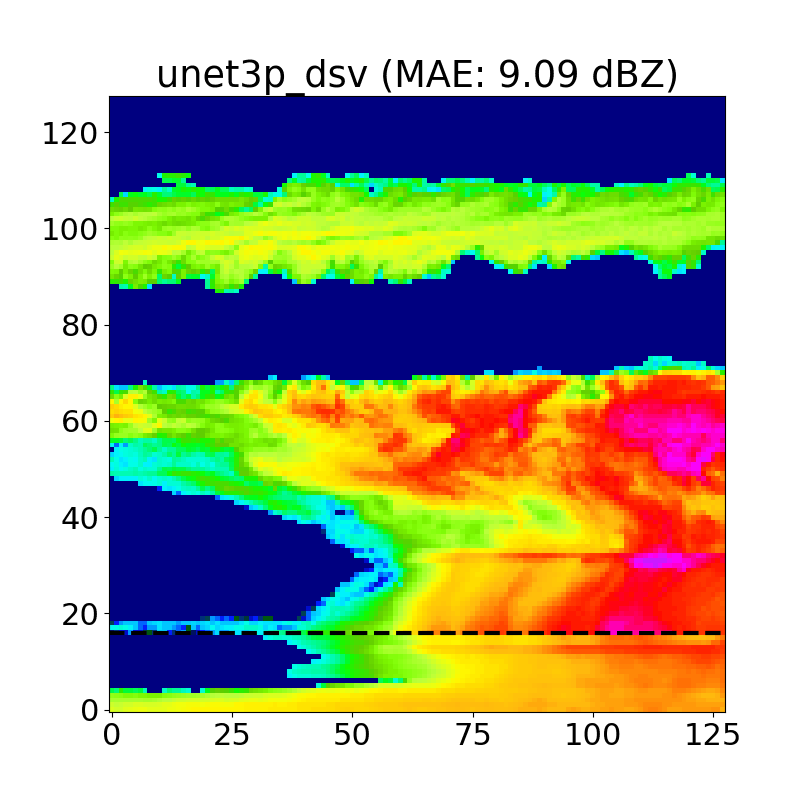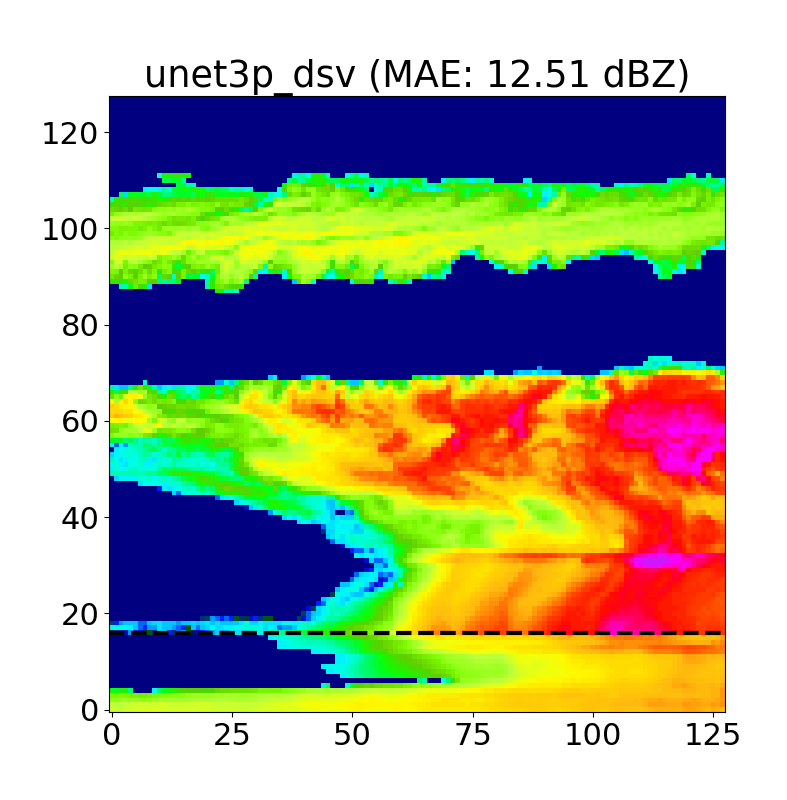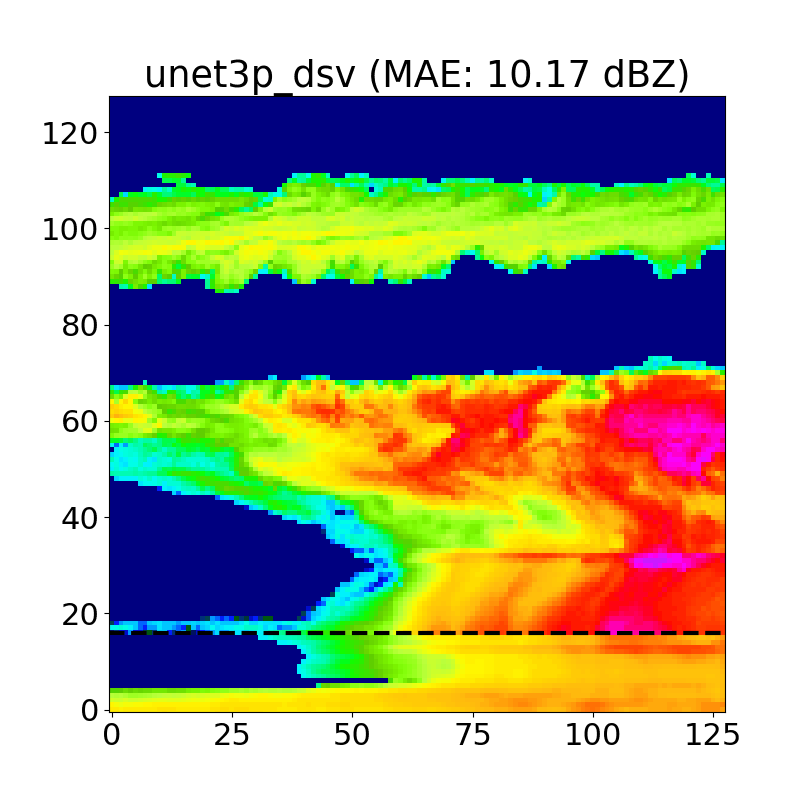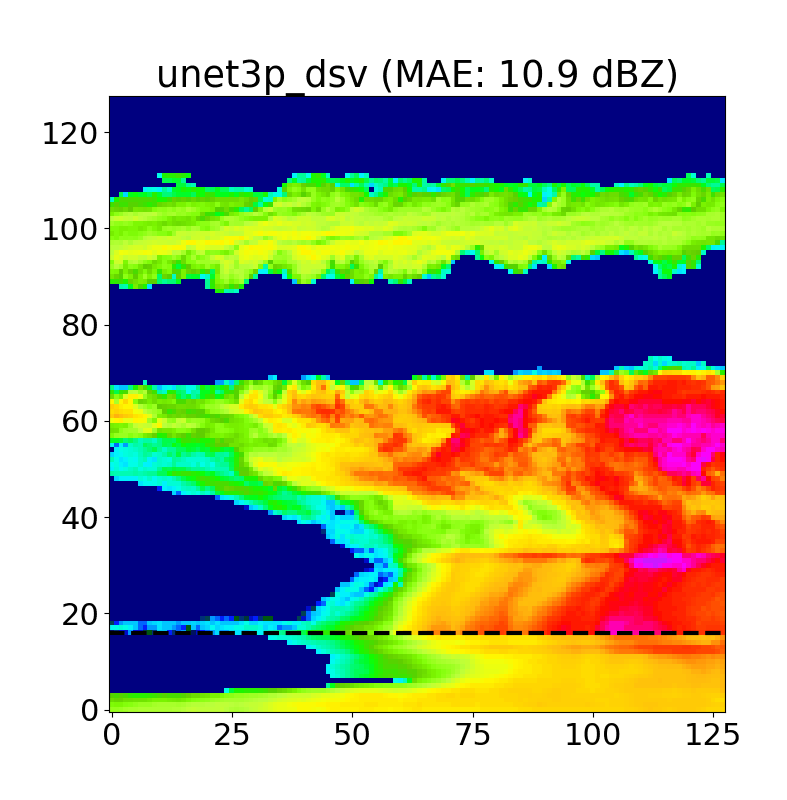
We typically use N=50 iterations per case, and as we can see above, the areas with the highest uncertainty are typically cloud edges and cloud gaps, as the model often hallucinates when positioning these features.
Training Statistics
Model training for this project was completed on two sets of hardware, including a Linux-based GPU computing cluster on Microsoft Azure, and a high-performance desktop running Windows 11 (additional system details in Table 1). An extensive Bayesian hyperparameter sweep was also performed over the course of 2 days. Further, batch normalization is applied along with early stopping (n=20), dropout and L2 regularization (ridge regression) to help mitigate overfitting during the training process. Learning rate decay is also applied at two epochs (450 and 475), allowing the model to more easily settle into a local loss minima near the end of the training phase. All training runs and hyperparameter sweeps are saved online using the Weights & Biases cloud storage option, to monitor model learning rates and stability over time.

Example Code
A link to the GitHub is here: https://github.com/frasertheking/blindzone_inpainting
However, I wanted to provide an overview of the actual 3Net+ implementation (with variable depth) in Tensorflow below for those interested in playing around with it.
def conv_block(x, kernels, kernel_size=(3, 3), strides=(1, 1), padding='same', is_bn=True, is_relu=True, n=2, l2_reg=1e-4):
for _ in range(1, n+1):
x = k.layers.Conv2D(filters=kernels, kernel_size=kernel_size,
padding=padding, strides=strides,
kernel_regularizer=tf.keras.regularizers.l2(l2_reg),
kernel_initializer=k.initializers.he_normal(seed=42))(x)
if is_bn:
x = k.layers.BatchNormalization()(x)
if is_relu:
x = k.activations.relu(x)
return x
def unet3plus(input_shape, output_channels, config, depth=4, training=False, clm=False):
""" Prep """
interp = config['interpolation']
input_layer = k.layers.Input(shape=input_shape, name="input_layer")
xpre = preprocess(input_layer, output_channels)
""" Encoder """
encoders = []
for i in range(depth+1):
if i == 0:
e = conv_block(xpre, config['filters']*(2**i), kernel_size=(config['kernel_size'], config['kernel_size']), l2_reg=config['l2_reg'])
else:
e = k.layers.MaxPool2D(pool_size=(2, 2))(encoders[i-1])
e = k.layers.Dropout(config['dropout'])(e, training=True)
e = conv_block(e, config['filters']*(2**i), kernel_size=(config['kernel_size'], config['kernel_size']), l2_reg=config['l2_reg'])
encoders.append(e)
""" Middle """
cat_channels = config['filters']
cat_blocks = depth+1
upsample_channels = cat_blocks * cat_channels
""" Decoder """
decoders = []
for d in reversed(range(depth+1)):
if d == 0 :
continue
loc_dec = []
decoder_pos = len(decoders)
for e in range(len(encoders)):
if d > e+1:
e_d = k.layers.MaxPool2D(pool_size=(2**(d-e-1), 2**(d-e-1)))(encoders[e])
e_d = k.layers.Dropout(config['dropout'])(e_d, training=True)
e_d = conv_block(e_d, cat_channels, kernel_size=(config['kernel_size'], config['kernel_size']), n=1, l2_reg=config['l2_reg'])
elif d == e+1:
e_d = conv_block(encoders[e], cat_channels, kernel_size=(config['kernel_size'], config['kernel_size']), n=1, l2_reg=config['l2_reg'])
elif e+1 == len(encoders):
e_d = k.layers.UpSampling2D(size=(2**(e+1-d), 2**(e+1-d)), interpolation=interp)(encoders[e])
e_d = k.layers.Dropout(config['dropout'])(e_d, training=True)
e_d = conv_block(e_d, cat_channels, kernel_size=(config['kernel_size'], config['kernel_size']), n=1, l2_reg=config['l2_reg'])
else:
e_d = k.layers.UpSampling2D(size=(2**(e+1-d), 2**(e+1-d)), interpolation=interp)(decoders[decoder_pos-1])
e_d = k.layers.Dropout(config['dropout'])(e_d, training=True)
e_d = conv_block(e_d, cat_channels, kernel_size=(config['kernel_size'], config['kernel_size']), n=1, l2_reg=config['l2_reg'])
decoder_pos -= 1
loc_dec.append(e_d)
de = k.layers.concatenate(loc_dec)
de = conv_block(de, upsample_channels, kernel_size=(config['kernel_size'], config['kernel_size']), n=1, l2_reg=config['l2_reg'])
decoders.append(de)
""" Final """
d1 = decoders[len(decoders)-1]
d1 = conv_block(d1, output_channels, kernel_size=(config['kernel_size'], config['kernel_size']), n=1, is_bn=False, is_relu=False, l2_reg=config['l2_reg'])
outputs = [d1]
""" Deep Supervision """
if training:
for i in reversed(range(len(decoders))):
if i == 0:
e = conv_block(encoders[len(encoders)-1], output_channels, kernel_size=(config['kernel_size'], config['kernel_size']), n=1, is_bn=False, is_relu=False, l2_reg=config['l2_reg'])
e = k.layers.UpSampling2D(size=(2**(len(decoders)-i), 2**(len(decoders)-i)), interpolation=interp)(e)
outputs.append(e)
else:
d = conv_block(decoders[i - 1], output_channels, kernel_size=(config['kernel_size'], config['kernel_size']), n=1, is_bn=False, is_relu=False, l2_reg=config['l2_reg'])
d = k.layers.UpSampling2D(size=(2**(len(decoders)-i), 2**(len(decoders)-i)), interpolation=interp)(d)
outputs.append(d)
if training:
for i in range(len(outputs)):
if i == 0:
continue
d_e = outputs[i]
d_e = k.layers.concatenate([out1, out2, out3])
outputs[i] = merge_output(input_layer, k.activations.linear(d_e), output_channels)
return tf.keras.Model(inputs=input_layer, outputs=outputs, name='UNet3Plus')
Future
I know this was a long post, and we covered a lot of stuff, but I want to give a quick summary of everything we’ve covered for those who have made this far (or those who skipped to the end).
The satellite radar blind zone is an ongoing problem on satellite-based Earth observing precipitation missions, with critical implications to global water-energy budget calculations. In order to overcome common issues with traditional linear inpainting methods for filling in this region, we opted to use a nonlinear, deeply supervised U-Net for radar blind zone inpainting. The U-Net outperforms linear techniques across nearly all metrics and can even reconstruct complex cloud structures like multilayer clouds, cloud gaps and shallow cloud. Further, using a variety of XAI techniques, we saw that information directly at the blind zone threshold and along the tropopause (especially wind information) was found to be very useful in the model’s decision-making process. While we don’t suggest that these models fully replace current physically-based solutions, we believe they offer a unique new perspective that can be used to supplement other retrievals in future missions.
We are currently working on a follow-up project to this with direct applications to CloudSat-CPR observations.
Referernces
Gal, Y., & Ghahramani, Z. (2016). Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning (arXiv:1506.02142). arXiv. https://doi.org/10.48550/arXiv.1506.02142
Geiss, A., & Hardin, J. C. (2021). Inpainting radar missing data regions with deep learning. Atmospheric Measurement Techniques, 14(12), 7729–7747. https://doi.org/10.5194/amt-14-7729-2021
Guillemot, C., & Le Meur, O. (2014). Image Inpainting: Overview and Recent Advances. IEEE Signal Processing Magazine, 31(1), 127–144. https://doi.org/10.1109/MSP.2013.2273004
Huang, H., Lin, L., Tong, R., Hu, H., Zhang, Q., Iwamoto, Y., Han, X., Chen, Y.-W., & Wu, J. (2020). UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation (arXiv:2004.08790). arXiv. https://doi.org/10.48550/arXiv.2004.08790
Kidd, C., Graham, E., Smyth, T., & Gill, M. (2021). Assessing the Impact of Light/Shallow Precipitation Retrievals from Satellite-Based Observations Using Surface Radar and Micro Rain Radar Observations. Remote Sensing, 13(9), Article 9. https://doi.org/10.3390/rs13091708
King, F., & Fletcher, C. G. (2020). Using CloudSat-CPR Retrievals to Estimate Snow Accumulation in the Canadian Arctic. Earth and Space Science, 7(2), e2019EA000776. https://doi.org/10.1029/2019EA000776
Lamer, K., Kollias, P., Battaglia, A., & Preval, S. (2020). Mind the gap — Part 1: Accurately locating warm marine boundary layer clouds and precipitation using spaceborne radars. Atmospheric Measurement Techniques, 13(5), 2363–2379. https://doi.org/10.5194/amt-13-2363-2020
Lugmayr, A., Danelljan, M., Romero, A., Yu, F., Timofte, R., & Van Gool, L. (2022). RePaint: Inpainting using Denoising Diffusion Probabilistic Models. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 11451–11461. https://doi.org/10.1109/CVPR52688.2022.01117
Maahn, M., Burgard, C., Crewell, S., Gorodetskaya, I. V., Kneifel, S., Lhermitte, S., Van Tricht, K., & van Lipzig, N. P. M. (2014). How does the spaceborne radar blind zone affect derived surface snowfall statistics in polar regions? Journal of Geophysical Research: Atmospheres, 119(24), 13,604–13,620. https://doi.org/10.1002/2014JD022079
Simonyan, K., Vedaldi, A., & Zisserman, A. (2014). Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps (arXiv:1312.6034). arXiv. https://doi.org/10.48550/arXiv.1312.6034
Zhou, Z., Siddiquee, M. M. R., Tajbakhsh, N., & Liang, J. (2018). UNet++: A Nested U-Net Architecture for Medical Image Segmentation (arXiv:1807.10165). arXiv. https://doi.org/10.48550/arXiv.1807.10165
Beyond the Blind Zone was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Beyond the Blind Zone