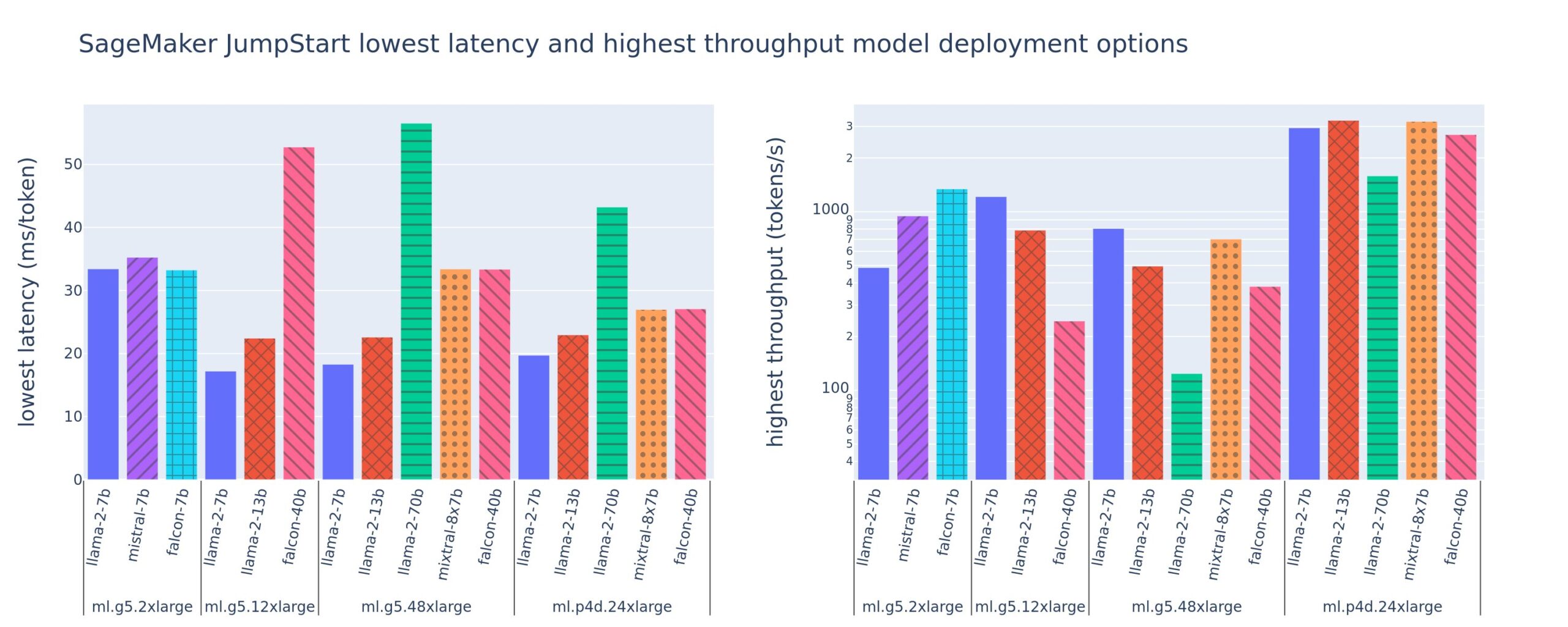
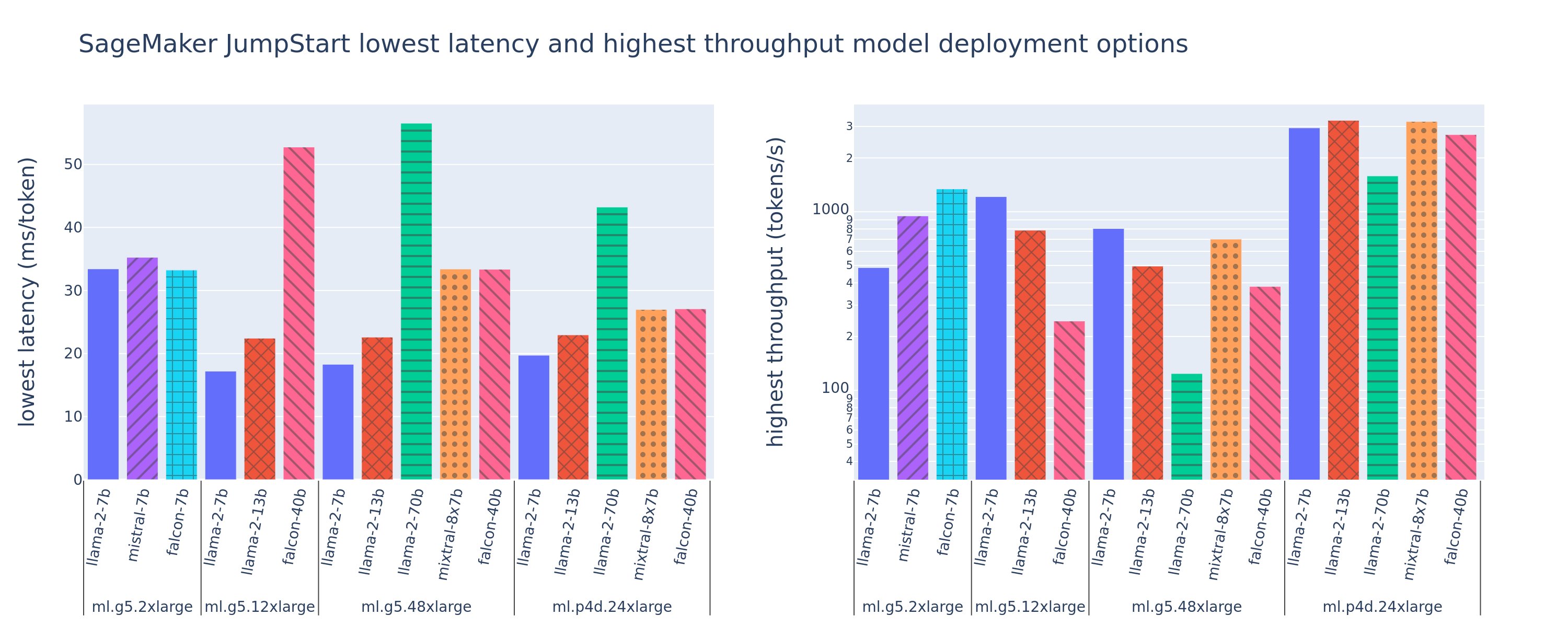
When deploying a large language model (LLM), machine learning (ML) practitioners typically care about two measurements for model serving performance: latency, defined by the time it takes to generate a single token, and throughput, defined by the number of tokens generated per second. Although a single request to the deployed endpoint would exhibit a throughput […]
Originally appeared here:
Benchmark and optimize endpoint deployment in Amazon SageMaker JumpStart
Go Here to Read this Fast! Benchmark and optimize endpoint deployment in Amazon SageMaker JumpStart