

How to solve binary classification problems using Bayesian methods in Python.
Introduction
In this article, I will build a simple Bayesian logistic regression model using Pyro, a Python probabilistic programming package. This article will cover EDA, feature engineering, model build and evaluation. The focus is to provide a simple framework for Bayesian logistic regression. Therefore, the depth of the first two sections will be limited. The code used in this article can be found here:
Exploratory Data Analysis
I am using the heart failure prediction dataset from Kaggle, linked below. This dataset is provided under the Open Data Commons Open Database License (ODbL) v1.0. Full reference to this dataset can be found at the end of this article.
Heart Failure Prediction Dataset
This dataset contains 918 examples and 11 features for predicting heart disease. The target variable is ‘HeartDisease’. There are five numeric and six categorical features in this dataset. To explore the distributions of the numeric features, I generated boxplots using seaborn, such as the one below.
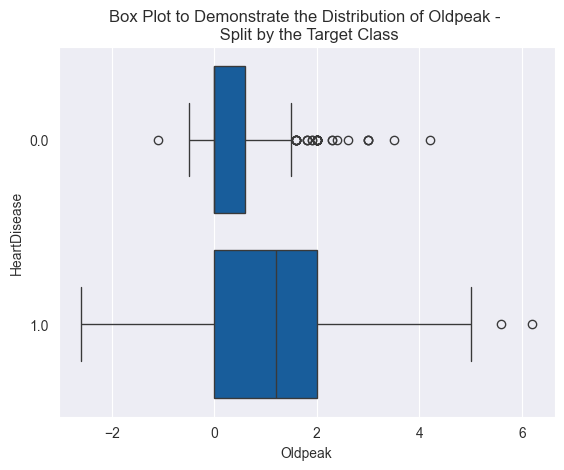
Something to highlight is the presence of outliers in the boxplot above. Outliers were present in many of the numeric features. This is important to note as it will influence the feature scaling method used in the next section. For categorical variables, I produced bar plots containing the volume of each category split by the target class.
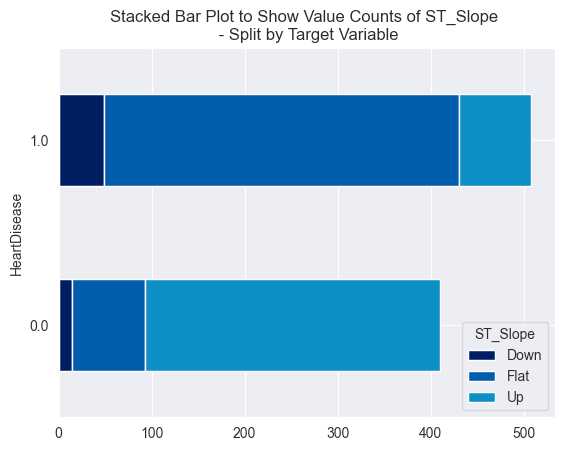
These graphs indicate that both of these variables could be predictive, given the difference in distribution by the target variable, ‘HeartDisease’.
Feature Engineering
I used standardisation scaling for continuous numerical features and one-hot encoding for categorical features for this model. My decision to use this scaling method was due to the presence of outliers in the features. Normalisation scaling is more sensitive to outliers, therefore employing the technique would require using methods to handle the outliers, or to remove them completely. For simplicity, I opted to use standardisation scaling, which is less sensitive to outliers.
Test and Training Data
I split the data into training and test sets using an 80/20 split. The function below generates the training and test data. Note that data is returned as PyTorch tensors.
Building the Logistic Regression Model
The function below defines the logistic regression model.
The code above generates two priors. We generate a sample of weights and a bias variable which are drawn from Normal distributions. The weights of the logistic regression model are drawn from a standard multivariate normal distribution, with a mean of 0 and a standard deviation of 1. The .independent() method is applied to the normal distribution which samples the model weights. This method tells Pyro that every sample drawn along the 1st dimension is independent. In other words, the coefficient applied to each feature in the model is independent of each other. Within the pyro.plate() context manager, the raw model logits are generated. This is calculated by the standard linear regression equation, defined below. The .squeeze() method is applied to remove dimensions that are of size 1, e.g. if the tensor shape is ( m x 1), the shape will be (m) after applying the method.

A sigmoid function is applied to the linear regression model, which maps the raw logit values into probabilities between 0 and 1. When solving multi-class classification problems with logistic regression, a softmax function should be used instead, as the probabilities of the classes sum to 1. PyTorch has a built-in function to apply the sigmoid function to our raw logits. This produces a one-dimensional tensor, with a length equal to the number of examples in our training data. Within the context manager, we define the likelihood term, which is sampled from a Bernoulli distribution. This term calculates the probability of observed data given the model we have defined. The Bernoulli distribution is parameterised by a tensor of probabilities that the sigmoid function generates.
MCMC Inference
The function below performs Bayesian inference using the NUTS MCMC sampling algorithm. We recruit the NUTS sampler, an MCMC algorithm, to intelligently sample the posterior parameter space. The function uses the training feature and target data sets as parameters, the number of samples we wish to draw from our posterior and the number of chains to run.
We tell Pyro to run x number of parallel chains to sample the parameter space, where each chain starts with a different set of initial parameter values. Running multiple chains in development will enable us to assess the convergence of MCMC. Executing the function above — passing the training data, and values for the number of samples and chains — returns an instance of the MCMC class.
Inference Analysis
Applying the .summary() method to the class returned from the function above will print some summary statistics of the sampling. One of the columns printed is r_hat. This is the Gelman-Rubin statistic which assesses how well different chains have converged to the same posterior probability distribution after sampling the parameter space for each feature. A value of 1 for the Gelman-Rubin statistic is considered perfect convergence and generally, any value below 1.1 is considered so. A value greater than 1.2 indicates there is little convergence. I ran inference with four chains and 1000 samples, my output looks like this:
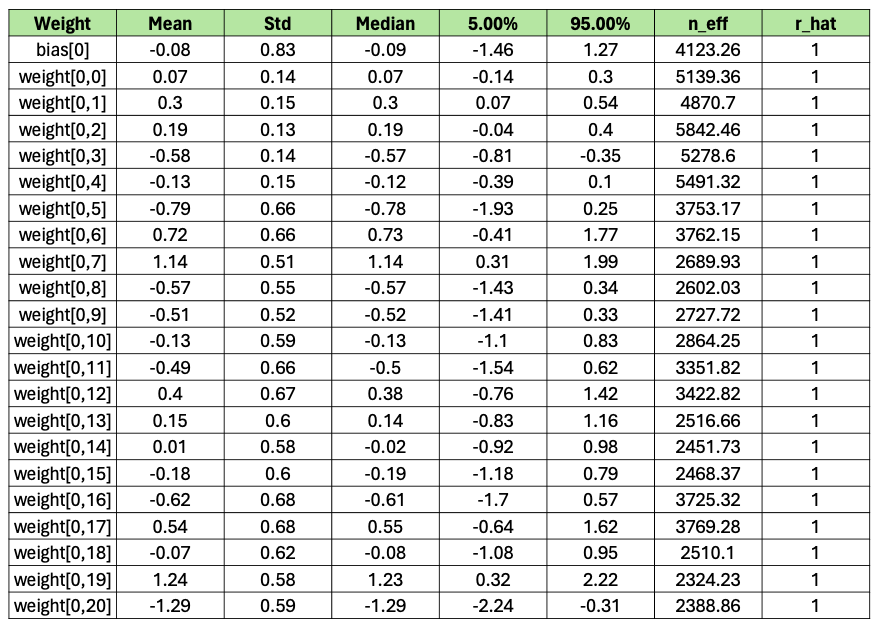
The first five columns provide descriptive statistics on the samples generated for each parameter. The r_hat values for all features indicate MCMC converged, meaning it is producing consistent estimations for each feature. The method also produces a metric ‘n_eff’, meaning an effective sample size. A large effective sample size relative to the number of samples taken is a strong sign that we have enough independent samples for reliable statistical inference, and that the samples are informative. The values of n_eff and r_hat here suggest strong model convergence and reliable results.
Plots can be generated to visualise the values sampled for each feature. Taking the first column of the matrix of weights we sampled as an example (corresponding to the first feature in the input data), generates the trace and probability density function below.

These plots help visualise uncertainty and convergence in the model. By calling the .get_samples() method and passing in the parameter group_by_chain = True, we can also evaluate the variety in sampling between chains. The plot below regenerates the plot above but groups the samples by the chain from which they were collected.

The subplot on the right demonstrates the model is consistently converging towards the same posterior distribution of the parameter value.
Generating Predictions
The prediction of the model is calculated by passing every set of samples drawn for the latent variables into the structure of the model. 4000 samples were collected, so we can generate 4000 predictions per example. The function below generates the class prediction for each example scored, a matrix of 4000 predictions per example and a tensor containing the mean prediction over 4000 samples per example scored.
The trace and kernel density plots of predictions for each example can be generated, to visualise the uncertainty of the predictions. The plots below illustrate the distribution of probabilities the model has produced for a random example in the test data set.

Over the 4000 samples, the model consistently predicts the example belongs to the positive class (does have heart disease).
Model Evaluation
The code below contains a function which produces some evaluation metrics from the Sckit-learn metrics module.
The class_prediction and mean_prediction variables returned from the create_predictions function can be passed into this function to generate a dictionary of metrics to evaluate the performance of the model for the training and test datasets. The table below summarises this information for test and training data. By nature of sampling methods, these results will vary for each independent run of the MCMC algorithm. It should be noted that accuracy should not be used as a robust measure of model performance when working with unbalanced datasets. When working with unbalanced datasets, using metrics such as the F1 score is more appropriate. Approximately 55% of the examples in the dataset belonged to the positive class, so the imbalance is small.
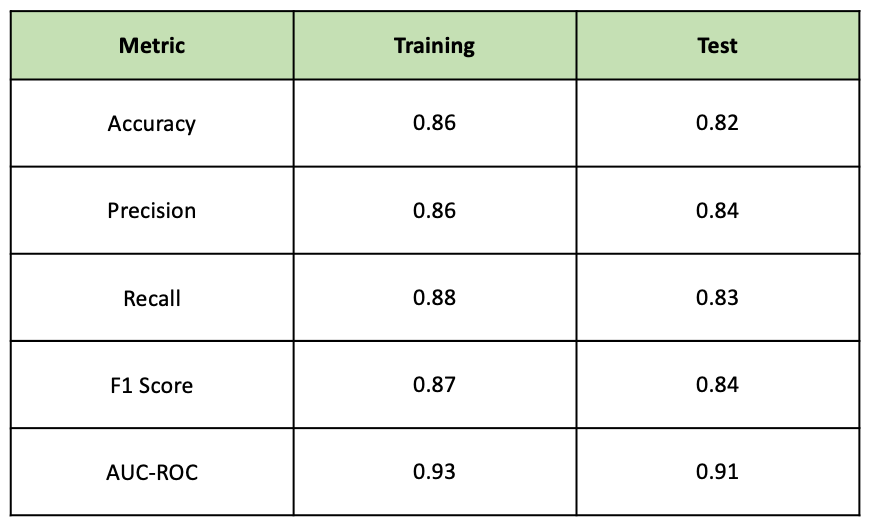
Precision tells us how many times the model predicted a patient had heart disease when they did. Recall tells us what proportion of patients who had heart disease were correctly predicted by the model. The importance of each of these metrics varies by the use case. In the medical industry, recall performance would be important as you would not want a situation where the model predicted a patient did not have heart disease when they did. In this model, the reduction in recall performance between the training and test data would be a concern. However, these metrics were generated using a standard cut-off of 0.5. The model’s threshold — the cut-off for classifying the positive and negative class — can be changed to improve recall. By reducing the threshold recall performance will improve, as fewer actual heart disease cases will be incorrectly identified. However, this will degrade the precision of the model, as more positive predictions will be false. The threshold of classification models is a method to manipulate the trade-off between these two metrics.
The AUC -ROC score for the training and test datasets is encouraging. As a general rule of thumb, a score above 0.9 indicates strong performance, which is true for both the training and test datasets. The graph below plots the AUC-ROC curve for both datasets.

Summary
This article aimed to provide a framework for solving binary classification problems using Bayesian methods, which I hope you have found useful. The model performs well across a range of evaluation metrics. However, model improvements are possible with a greater focus on feature engineering and selection.
In my previous article, I discussed Bayesian thinking in more depth. If you are interested, I have provided the link below. I have also provided a link to another article, which provides a good introduction to logistic regression modelling.
References:
Fedesoriano. (September 2021). Heart Failure Prediction Dataset. Retrieved 2024/02/17 from https://www.kaggle.com/fedesoriano/heart-failure-prediction. License: https://opendatacommons.org/licenses/odbl/1-0/
Bayesian Logistic Regression in Python was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Bayesian Logistic Regression in Python
Go Here to Read this Fast! Bayesian Logistic Regression in Python