A workflow and code walkthrough for building a Bayesian regression model in STAN
Note: Check out my previous article for a practical discussion on why Bayesian modeling may be the right choice for your task.
This tutorial will focus on a workflow + code walkthrough for building a Bayesian regression model in STAN, a probabilistic programming language. STAN is widely adopted and interfaces with your language of choice (R, Python, shell, MATLAB, Julia, Stata). See the installation guide and documentation.
I will use Pystan for this tutorial, simply because I code in Python. Even if you use another language, the general Bayesian practices and STAN language syntax I will discuss here doesn’t vary much.
For the more hands-on reader, here is a link to the notebook for this tutorial, part of my Bayesian modeling workshop at Northwestern University (April, 2024).
Let’s dive in!
Bayesian Linear Regression
Lets learn how to build a simple linear regression model, the bread and butter of any statistician, the Bayesian way. Assuming a dependent variable Y and covariate X, I propose the following simple model-
Y = α + β * X + ϵ
Where ⍺ is the intercept, β is the slope, and ϵ is some random error. Assuming that,
ϵ ~ Normal(0, σ)
we can show that
Y ~ Normal(α + β * X, σ)
We will learn how to code this model form in STAN.
Generate Data
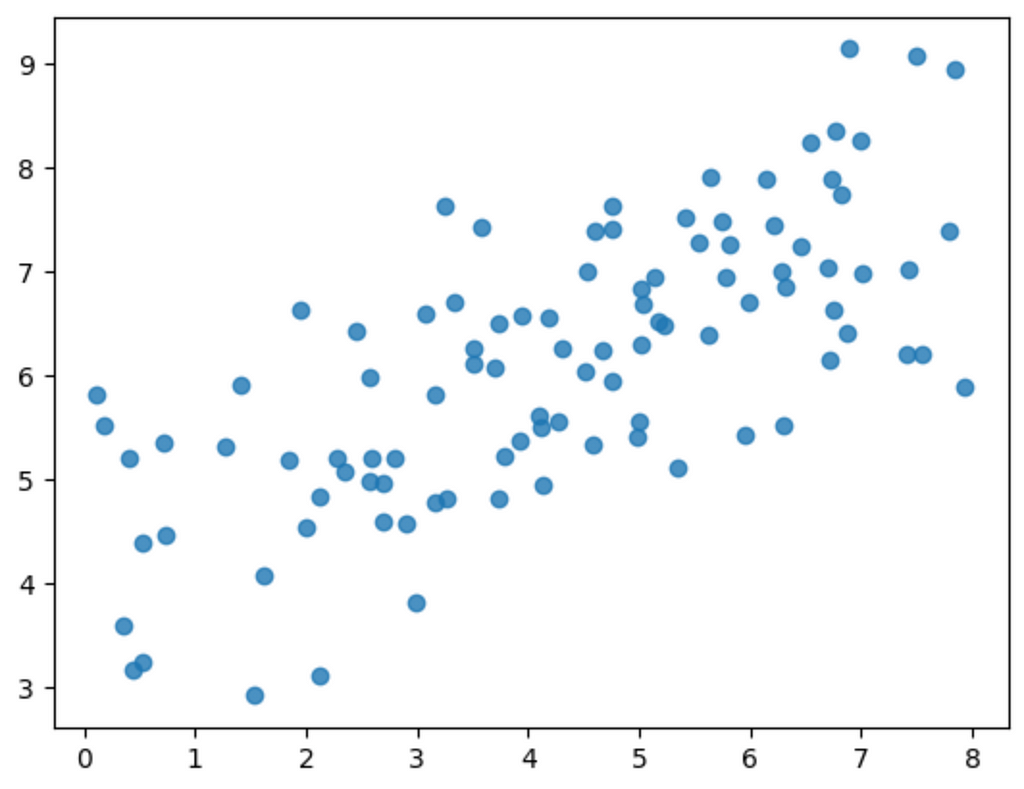
First, let’s generate some fake data.
#Model Parameters
alpha = 4.0 #intercept
beta = 0.5 #slope
sigma = 1.0 #error-scale
#Generate fake data
x = 8 * np.random.rand(100)
y = alpha + beta * x
y = np.random.normal(y, scale=sigma) #noise
#visualize generated data
plt.scatter(x, y, alpha = 0.8)
Model String
Now that we have some data to model, let’s dive into how to structure it and pass it to STAN along with modeling instructions. This is done via the model string, which typically contains 4 (occasionally more) blocks- data, parameters, model, and generated quantities. Let’s discuss each of these blocks in detail.
DATA block
data { //input the data to STAN
int<lower=0> N;
vector[N] x;
vector[N] y;
}
The data block is perhaps the simplest, it tells STAN internally what data it should expect, and in what format. For instance, here we pass-
N: the size of our dataset as type int. The <lower=0> part declares that N≥0. (Even though it is obvious here that data length cannot be negative, stating these bounds is good standard practice that can make STAN’s job easier.)
x: the covariate as a vector of length N.
y: the dependent as a vector of length N.
See docs here for a full range of supported data types. STAN offers support for a wide range of types like arrays, vectors, matrices etc. As we saw above, STAN also has support for encoding limits on variables. Encoding limits is recommended! It leads to better specified models and simplifies the probabilistic sampling processes operating under the hood.
Model Block
Next is the model block, where we tell STAN the structure of our model.
//simple model block
model {
//priors
alpha ~ normal(0,10);
beta ~ normal(0,1);
//model
y ~ normal(alpha + beta * x, sigma);
}
The model block also contains an important, and often confusing, element: prior specification. Priors are a quintessential part of Bayesian modeling, and must be specified suitably for the sampling task.
See my previous article for a primer on the role and intuition behind priors. To summarize, the prior is a presupposed functional form for the distribution of parameter values — often referred to, simply, as prior belief. Even though priors don’t have to exactly match the final solution, they must allow us to sample from it.
In our example, we use Normal priors of mean 0 with different variances, depending on how sure we are of the supplied mean value: 10 for alpha (very unsure), 1 for beta (somewhat sure). Here, I supplied the general belief that while alpha can take a wide range of different values, the slope is generally more contrained and won’t have a large magnitude.
Hence, in the example above, the prior for alpha is ‘weaker’ than beta.
As models get more complicated, the sampling solution space expands, and supplying beliefs gains importance. Otherwise, if there is no strong intuition, it is good practice to just supply less belief into the model i.e. use a weakly informative prior, and remain flexible to incoming data.
The form for y, which you might have recognized already, is the standard linear regression equation.
Generated Quantities
Lastly, we have our block for generated quantities. Here we tell STAN what quantities we want to calculate and receive as output.
generated quantities { //get quantities of interest from fitted model
vector[N] yhat;
vector[N] log_lik;
for (n in 1:N){
yhat[n] = normal_rng(alpha + x[n] * beta, sigma);
//generate samples from model
log_lik[n] = normal_lpdf( y[n] | alpha + x[n] * beta, sigma);
//probability of data given the model and parameters
}
}
Note: STAN supports vectors to be passed either directly into equations, or as iterations 1:N for each element n. In practice, I’ve found this support to change with different versions of STAN, so it is good to try the iterative declaration if the vectorized version fails to compile.
In the above example-
yhat: generates samples for y from the fitted parameter values.
log_lik: generates probability of data given the model and fitted parameter value.
The purpose of these values will be clearer when we talk about model evaluation.
Putting it all together
Altogether, we have now fully specified our first simple Bayesian regression model:
model = """
data { //input the data to STAN
int<lower=0> N;
vector[N] x;
vector[N] y;
}
parameters {
real alpha;
real beta;
real<lower=0> sigma;
}
model {
alpha ~ normal(0,10);
beta ~ normal(0,1);
y ~ normal(alpha + beta * x, sigma);
}
generated quantities {
vector[N] yhat;
vector[N] log_lik;
for (n in 1:N){
yhat[n] = normal_rng(alpha + x[n] * beta, sigma);
log_lik[n] = normal_lpdf(y[n] | alpha + x[n] * beta, sigma);
}
}
"""
All that remains is to compile the model and run the sampling.
#STAN takes data as a dict
data = {'N': len(x), 'x': x, 'y': y}
STAN takes input data in the form of a dictionary. It is important that this dict contains all the variables that we told STAN to expect in the model-data block, otherwise the model won’t compile.
#parameters for STAN fitting
chains = 2
samples = 1000
warmup = 10
# set seed
# Compile the model
posterior = stan.build(model, data=data, random_seed = 42)
# Train the model and generate samples
fit = posterior.sample(num_chains=chains, num_samples=samples)The .sample() method parameters control the Hamiltonian Monte Carlo (HMC) sampling process, where —
- num_chains: is the number of times we repeat the sampling process.
- num_samples: is the number of samples to be drawn in each chain.
- warmup: is the number of initial samples that we discard (as it takes some time to reach the general vicinity of the solution space).
Knowing the right values for these parameters depends on both the complexity of our model and the resources available.
Higher sampling sizes are of course ideal, yet for an ill-specified model they will prove to be just waste of time and computation. Anecdotally, I’ve had large data models I’ve had to wait a week to finish running, only to find that the model didn’t converge. Is is important to start slowly and sanity check your model before running a full-fledged sampling.
Model Evaluation
The generated quantities are used for
- evaluating the goodness of fit i.e. convergence,
- predictions
- model comparison
Convergence
The first step for evaluating the model, in the Bayesian framework, is visual. We observe the sampling draws of the Hamiltonian Monte Carlo (HMC) sampling process.

In simplistic terms, STAN iteratively draws samples for our parameter values and evaluates them (HMC does way more, but that’s beyond our current scope). For a good fit, the sample draws must converge to some common general area which would, ideally, be the global optima.
The figure above shows the sampling draws for our model across 2 independent chains (red and blue).
- On the left, we plot the overall distribution of the fitted parameter value i.e. the posteriors. We expect a normal distribution if the model, and its parameters, are well specified. (Why is that? Well, a normal distribution just implies that there exist a certain range of best fit values for the parameter, which speaks in support of our chosen model form). Furthermore, we should expect a considerable overlap across chains IF the model is converging to an optima.
- On the right, we plot the actual samples drawn in each iteration (just to be extra sure). Here, again, we wish to see not only a narrow range but also a lot of overlap between the draws.
Not all evaluation metrics are visual. Gelman et al. [1] also propose the Rhat diagnostic which essential is a mathematical measure of the sample similarity across chains. Using Rhat, one can define a cutoff point beyond which the two chains are judged too dissimilar to be converging. The cutoff, however, is hard to define due to the iterative nature of the process, and the variable warmup periods.
Visual comparison is hence a crucial component, regardless of diagnostic tests
A frequentist thought you may have here is that, “well, if all we have is chains and distributions, what is the actual parameter value?” This is exactly the point. The Bayesian formulation only deals in distributions, NOT point estimates with their hard-to-interpret test statistics.
That said, the posterior can still be summarized using credible intervals like the High Density Interval (HDI), which includes all the x% highest probability density points.
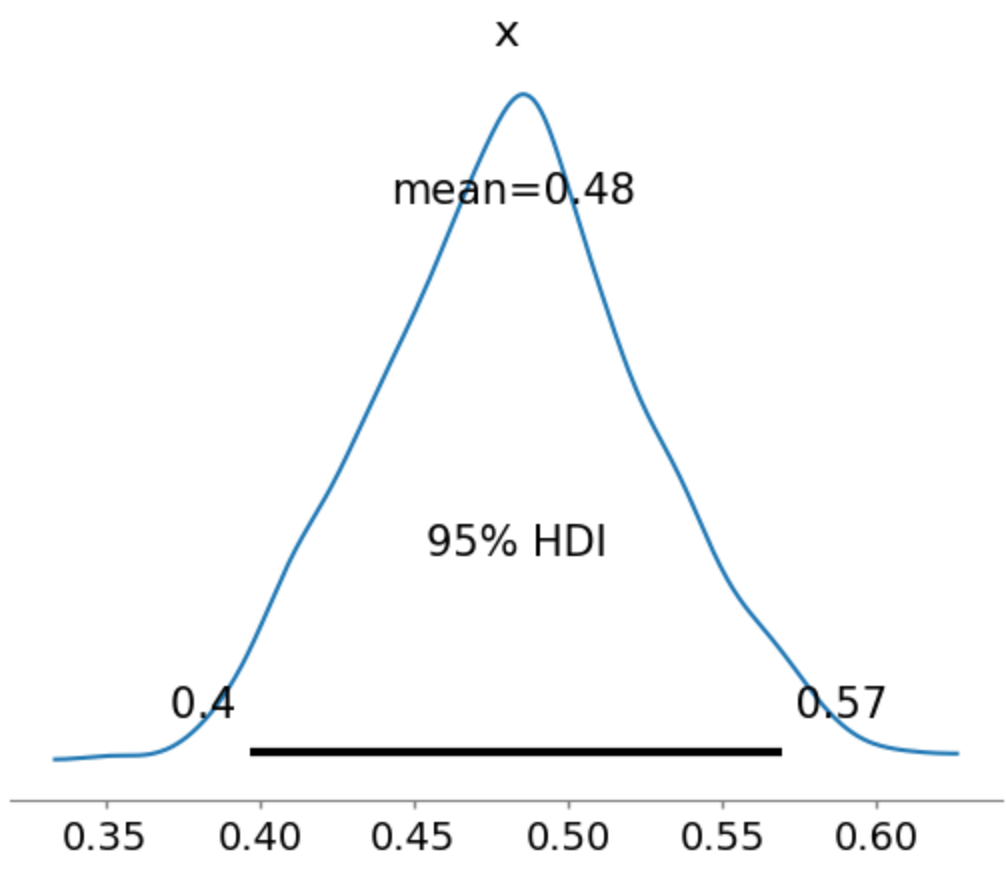
It is important to contrast Bayesian credible intervals with frequentist confidence intervals.
- The credible interval gives a probability distribution on the possible values for the parameter i.e. the probability of the parameter assuming each value in some interval, given the data.
- The confidence interval regards the parameter value as fixed, and estimates instead the confidence that repeated random samplings of the data would match.
Hence the
Bayesian approach lets the parameter values be fluid and takes the data at face value, while the frequentist approach demands that there exists the one true parameter value… if only we had access to all the data ever
Phew. Let that sink in, read it again until it does.
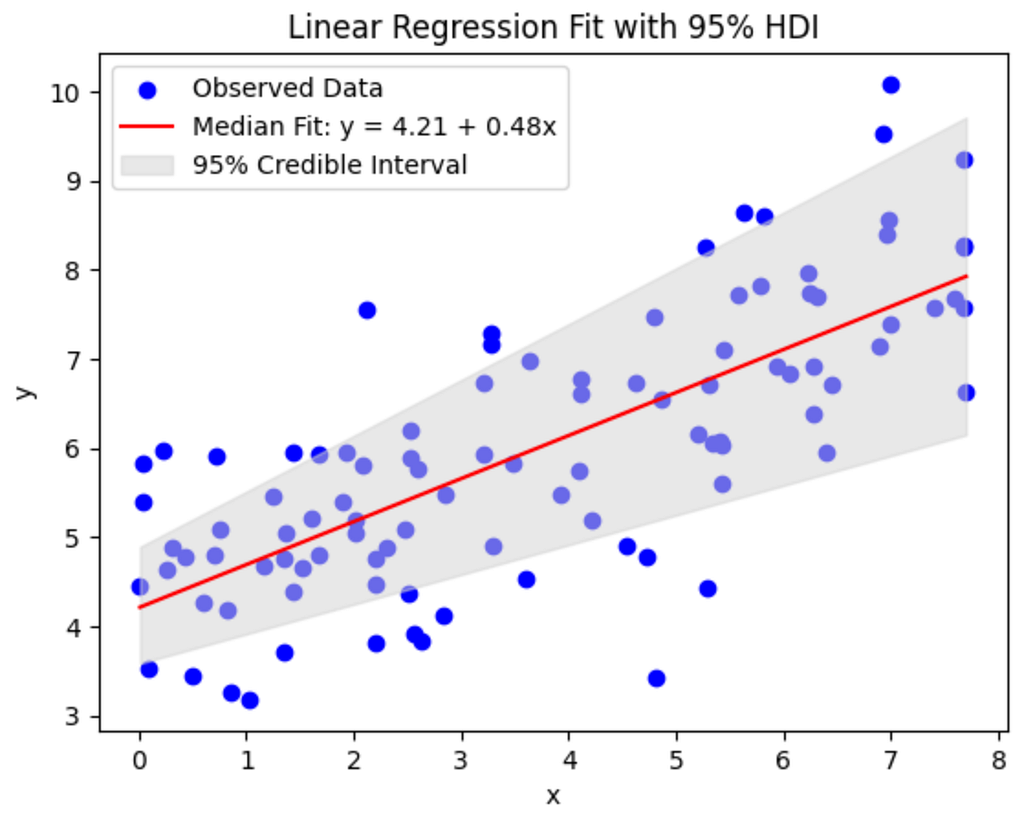
Another important implication of using credible intervals, or in other words, allowing the parameter to be variable, is that the predictions we make capture this uncertainty with transparency, with a certain HDI % informing the best fit line.
Model comparison
In the Bayesian framework, the Watanabe-Akaike Information Metric (WAIC) score is the widely accepted choice for model comparison. A simple explanation of the WAIC score is that it estimates the model likelihood while regularizing for the number of model parameters. In simple words, it can account for overfitting. This is also major draw of the Bayesian framework — one does not necessarily need to hold-out a model validation dataset. Hence,
Bayesian modeling offers a crucial advantage when data is scarce.
The WAIC score is a comparative measure i.e. it only holds meaning when compared across different models that attempt to explain the same underlying data. Thus in practice, one can keep adding more complexity to the model as long as the WAIC increases. If at some point in this process of adding maniacal complexity, the WAIC starts dropping, one can call it a day — any more complexity will not offer an informational advantage in describing the underlying data distribution.
Conclusion
To summarize, the STAN model block is simply a string. It explains to STAN what you are going to give to it (model), what is to be found (parameters), what you think is going on (model), and what it should give you back (generated quantities).
When turned on, STAN simple turns the crank and gives its output.
The real challenge lies in defining a proper model (refer priors), structuring the data appropriately, asking STAN exactly what you need from it, and evaluating the sanity of its output.
Once we have this part down, we can delve into the real power of STAN, where specifying increasingly complicated models becomes just a simple syntactical task. In fact, in our next tutorial we will do exactly this. We will build upon this simple regression example to explore Bayesian Hierarchical models: an industry standard, state-of-the-art, defacto… you name it. We will see how to add group-level radom or fixed effects into our models, and marvel at the ease of adding complexity while maintaining comparability in the Bayesian framework.
Subscribe if this article helped, and to stay-tuned for more!
References
[1] Andrew Gelman, John B. Carlin, Hal S. Stern, David B. Dunson, Aki Vehtari and Donald B. Rubin (2013). Bayesian Data Analysis, Third Edition. Chapman and Hall/CRC.
Bayesian Linear Regression: A Complete Beginner’s guide was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Bayesian Linear Regression: A Complete Beginner’s guide
Go Here to Read this Fast! Bayesian Linear Regression: A Complete Beginner’s guide