

AWS DeepRacer : A Practical Guide to Reducing The Sim2Real Gap — Part 2 || Training Guide
How to select action space, reward function, and training paradigm for different vehicle behaviors
This article describes how to train the AWS DeepRacer to drive safely around a track without crashing. The goal is not to train the fastest car (although I will discuss that briefly), but to train a model that can learn to stay on the track and navigate turns. Video below shows the so called “safe” model:
Link to GitRepo : https://github.com/shreypareek1991/deepracer-sim2real
In Part 1, I described how to prepare the track and the surrounding environment to maximize chances of successfully completing multiple laps using the DeepRacer. If you haven’t read Part 1, I strongly urge you to read it as it forms the basis of understanding physical factors that affect the DeepRacer’s performance.
I initially used this guide from Sam Marsman as a starting point. It helped me train fast sim models, but they had a low success rate on the track. That being said, I would highly recommend reading their blog as it provides incredible advice on how to incrementally train your model.
NOTE: We will first train a slow model, then increase speed later. The video at the top is a faster model that I will briefly explain towards the end.
Part 1 Summary
In Part 1— we identified that the DeepRacer uses grey scale images from its front facing camera as input to understand and navigate its surroundings. Two key findings were highlighted:
1. DeepRacer cannot recognize objects, rather it learns to stay on and avoid certain pixel values. The car learns to stay on the Black track surface, avoid crossing White track boundaries, and avoid Green (or rather a shade of grey) sections of the track.
2. Camera is very sensitive to ambient light and background distractions.
By reducing ambient lights and placing colorful barriers, we try and mitigate the above. Here is picture of my setup copied from Part 1.
Training
I won’t go into the details of Reinforcement Learning or the DeepRacer training environment in this article. There are numerous articles and guides from AWS that cover this.
Very briefly, Reinforcement Learning is a technique where an autonomous agent seeks to learn an optimal policy that maximizes a scalar reward. In other words, the agent learns a set of situation-based actions that would maximize a reward. Actions that lead to desirable outcomes are (usually) awarded a positive reward. Conversely, unfavorable actions are either penalized (negative reward) or awarded a small positive reward.
Instead, my goal is to focus on providing you a training strategy that will maximize the chances of your car navigating the track without crashing. I will look at five things:
- Track — Clockwise and Counterclockwise orientation
- Hyperparameters — Reducing learning rates
- Action Space
- Reward Function
- Training Paradigm/Cloning Models
Track
Ideally you want to use the same track in the sim as in real life. I used the A To Z Speedway. Additionally, for the best performance, you want to iteratively train on a clockwise and counter clockwise orientation to minimize effects of over training.
Hyperparameters
I used the defaults from AWS to train the first few models. Reduce learning rate by half every 2–3 iterations so that you can fine tune a previous best model.
Action Space
This refers to a set of actions that DeepRacer can take to navigate an environment. Two actions are available — steering angle (degrees) and throttle (m/s).
I would recommend using the discrete action space instead of continuous. Although the continuous action space leads to a smoother and faster behavior, it takes longer to train and training costs will add up quickly. Additionally, the discrete action space provides more control over executing a particular behavior. Eg. Slower speed on turns.
Start with the following action space. The maximum forward speed of the DeepRacer is 4m/s, but we will start off with much lower speeds. You can increase this later (I will show how). Remember, our first goal is to simply drive around the track.
Slow and Steady Action Space
First, we will train a model that is very slow but goes around the track without leaving it. Don’t worry if the car keeps getting stuck. You may have to give it small pushes, but as long as it can do a lap — you are on the right track (pun intended). Ensure that Advanced Configuration is selected.

Reward Function
The reward function is arguably the most crucial factor and accordingly — the most challenging aspect of reinforcement learning. It governs the behaviors your agent will learn and should be designed very carefully. Yes, the choice of your learning model, hyperparameters, etc. do affect the overall agent behavior — but they rely on your reward function.
The key to designing a good reward function is to list out the behaviors you want your agent to execute and then think about how these behaviors would interact with each other and the environment. Of course, you cannot account for all possible behaviors or interactions, and even if you can — the agent might learn a completely different policy.
Now let’s list out the desired behaviors we want our car to execute and their corresponding reward function in Python. I will first provide reward functions for each behavior individually and then Put it All Together later.
Behavior 1 — Drive On Track
This one is easy. We want our car to stay on the track and avoid going outside the white lines. We achieve this using two sub-behaviors:
#1 Stay Close to Center Line: Closer the car is to the center of the track, lower is the chance of a collision. To do this, we award a large positive reward when the car is close to the center and a smaller positive reward when it is further away. We award a small positive reward because being away from the center is not necessarily a bad thing as long as the car stays within the track.
def reward_function(params):
"""
Example of rewarding the agent to follow center line.
"""
# set an initial small but non-negative reward
reward = 1e-3
# Read input parameters
track_width = params["track_width"]
distance_from_center = params["distance_from_center"]
# Calculate 3 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward += 2.0 # large positive reward when closest to center
elif distance_from_center <= marker_2:
reward += 0.25
elif distance_from_center <= marker_3:
reward += 0.05 # very small positive reward when further from center
else:
reward = -20 # likely crashed/ close to off track
return float(reward)
#2 Keep All 4 Wheels on Track: In racing, lap times are deleted if all four wheels of a car veer off track. To this end, we apply a large negative penalty if all four wheel are off track.
def reward_function(params):
'''
Example of penalizing the agent if all four wheels are off track.
'''
# large penalty for off track
OFFTRACK_PENALTY = -20
reward = 1e-3
# Penalize if the car goes off track
if not params['all_wheels_on_track']:
return float(OFFTRACK_PENALTY)
# positive reward if stays on track
reward += 1
return float(reward)
Our hope here is that using a combination of the above sub-behaviors, our agent will learn that staying close to the center of the track is a desirable behavior while veering off leads to a penalty.
Behavior 2 — Slow Down for Turns
As in real life, we want our vehicle to slow down while navigating turns. Additionally, sharper the turn, slower the desired speed. We do this by:
- Providing a large positive reward such that if the steering angle is high (i.e. sharp turn) speed is lower than a threshold.
- Providing a smaller positive reward is high steering angle is accompanied by a speed greater than a threshold.
Unintended Zigzagging Behavior: Reward function design is a subtle balancing art. There is no free lunch. Attempting to train certain desired behavior may lead to unexpected and undesirable behaviors. In our case, by forcing the agent to stay close to the center line, our agent will learn a zigzagging policy. Anytime it veers away from the center, it will try to correct itself by steering in the opposite direction and the cycle will continue. We can reduce this by penalizing extreme steering angles by multiplying the final reward by 0.85 (i.e. a 15% reduction).
On a side note, this can also be achieved by tracking change in steering angle and penalizing large and sudden changes. I am not sure if DeepRacer API provides access to previous states to design such a reward function.
def reward_function(params):
'''
Example of rewarding the agent to slow down for turns
'''
reward = 1e-3
# fast on straights and slow on curves
steering_angle = params['steering_angle']
speed = params['speed']
# set a steering threshold above which angles are considered large
# you can change this based on your action space
STEERING_THRESHOLD = 15
if abs(steering_angle) > STEERING_THRESHOLD:
if speed < 1:
# slow speeds are awarded large positive rewards
reward += 2.0
elif speed < 2:
# faster speeds are awarded smaller positive rewards
reward += 0.5
# reduce zigzagging behavior by penalizing large steering angles
reward *= 0.85
return float(reward)
Putting it All Together
Next, we combine all the above to get our final reward function. Sam Marsman’s guide recommends training additional behaviors incrementally by training a model to learn one reward and then adding others. You can try this approach. In my case, it did not make too much of a difference.
def reward_function(params):
'''
Example reward function to train a slow and steady agent
'''
STEERING_THRESHOLD = 15
OFFTRACK_PENALTY = -20
# initialize small non-zero positive reward
reward = 1e-3
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# Penalize if the car goes off track
if not params['all_wheels_on_track']:
return float(OFFTRACK_PENALTY)
# Calculate 3 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward += 2.0
elif distance_from_center <= marker_2:
reward += 0.25
elif distance_from_center <= marker_3:
reward += 0.05
else:
reward = OFFTRACK_PENALTY # likely crashed/ close to off track
# fast on straights and slow on curves
steering_angle = params['steering_angle']
speed = params['speed']
if abs(steering_angle) > STEERING_THRESHOLD:
if speed < 1:
reward += 2.0
elif speed < 2:
reward += 0.5
# reduce zigzagging behavior
reward *= 0.85
return float(reward)
Training Paradigm/Model Cloning
The key to training a successful model is to iteratively clone and improve an existing model. In other words, instead of training one model for 10 hours, you want to:
- train an initial model for a couple of hours
- clone the best model
- train for an hour or so
- clone best model
- repeat till you get reliable 100 percent completion during validation
- switch between clockwise and counter clockwise track direction for every training iteration
- reduce the learning rate by half every 2–3 iterations
You are looking for a reward graph that looks something like this. It’s okay if you do not achieve 100% completion every time. Consistency is key here.

Test, Retrain, Test, Retrain, Repeat
Machine Learning and Robotics are all about iterations. There is no one-size-fits-all solution. So you will have to experiment.
(Bonus) Training a Faster Model
Once your car can navigate the track safely (even if it needs some pushes), you can increase the speed in the action space and the reward functions.
The video at the top of this page was created using the following action space and reward function.
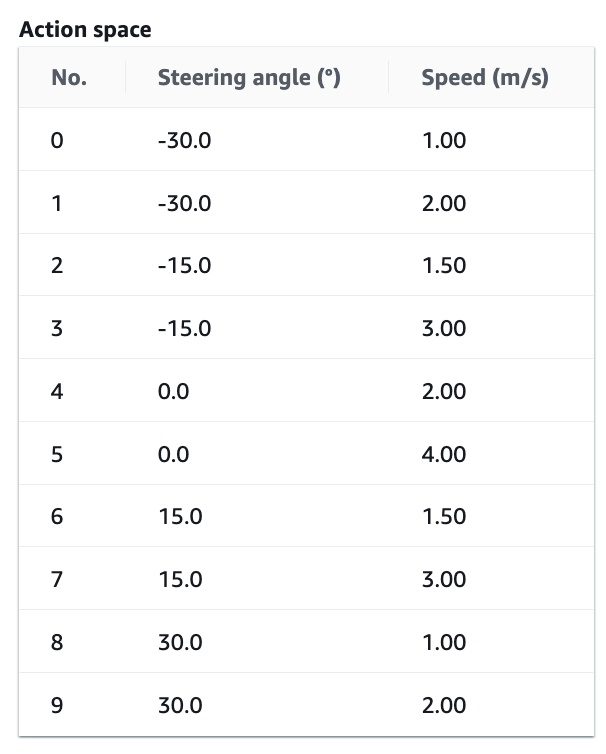
def reward_function(params):
'''
Example reward function to train a fast and steady agent
'''
STEERING_THRESHOLD = 15
OFFTRACK_PENALTY = -20
# initialize small non-zero positive reward
reward = 1e-3
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# Penalize if the car goes off track
if not params['all_wheels_on_track']:
return float(OFFTRACK_PENALTY)
# Calculate 3 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward += 2.0
elif distance_from_center <= marker_2:
reward += 0.25
elif distance_from_center <= marker_3:
reward += 0.05
else:
reward = OFFTRACK_PENALTY # likely crashed/ close to off track
# fast on straights and slow on curves
steering_angle = params['steering_angle']
speed = params['speed']
if abs(steering_angle) > STEERING_THRESHOLD:
if speed < 1.5:
reward += 2.0
elif speed < 2:
reward += 0.5
# reduce zigzagging behavior
reward *= 0.85
return float(reward)
Fast but Crashy Model — Use at your Own Risk
The video showed in Part 1 of this series was trained to prefer speed. No penalties were applied for going off track or crashing. Instead a very small positive reward was awared. This led to a fast model that was able to do a time of 10.337s in the sim. In practice, it would crash a lot but when it managed to complete a lap, it was very satisfying.
Here is the action space and reward in case you want to give it a try.
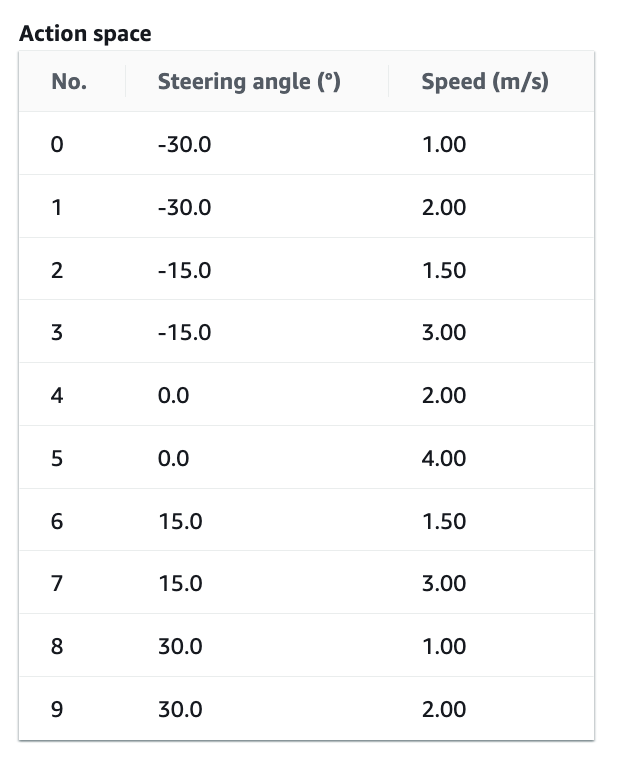
def reward_function(params):
'''
Example of fast agent that leaves the track and also is crash prone.
But it is FAAAST
'''
# Steering penality threshold
ABS_STEERING_THRESHOLD = 15
reward = 1e-3
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# Penalize if the car goes off track
if not params['all_wheels_on_track']:
return float(1e-3)
# Calculate 3 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward += 1.0
elif distance_from_center <= marker_2:
reward += 0.5
elif distance_from_center <= marker_3:
reward += 0.1
else:
reward = 1e-3 # likely crashed/ close to off track
# fast on straights and slow on curves
steering_angle = params['steering_angle']
speed = params['speed']
# straights
if -5 < steering_angle < 5:
if speed > 2.5:
reward += 2.0
elif speed > 2:
reward += 1.0
elif steering_angle < -15 or steering_angle > 15:
if speed < 1.8:
reward += 1.0
elif speed < 2.2:
reward += 0.5
# Penalize reward if the car is steering too much
if abs(steering_angle) > ABS_STEERING_THRESHOLD:
reward *= 0.75
# Reward lower steps
steps = params['steps']
progress = params['progress']
step_reward = (progress/steps) * 5 * speed * 2
reward += step_reward
return float(reward)
Conclusion
In conclusion, remember two things.
- Start by training a slow model that can successfully navigate the track, even if you need to push the car a bit at times. Once this is done, you can experiment with increasing the speed in your action space. As in real life, baby steps first. You can also gradually increase throttle percentage from 50 to 100% using the DeepRacer control UI to manage speeds. In my case 95% throttle worked best.
- Train your model incrementally. Start with a couple of hours of training, then switch track direction (clockwise/counter clockwise) and gradually reduce training times to one hour. You may also reduce the learning rate by half every 2–3 iteration to hone and improve a previous best model.
Finally, you will have to reiterate multiple times based on your physical setup. In my case I trained 100+ models. Hopefully with this guide you can get similar results with 15–20 instead.
Thanks for reading.
AWS DeepRacer : A Practical Guide to Reducing The Sim2Real Gap — Part 2 || Training Guide was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
AWS DeepRacer : A Practical Guide to Reducing The Sim2Real Gap — Part 2 || Training Guide