

A practical guide to tag object detection datasets with the GroundingDino algorithm. Code included.
Introduction
Until recently, object detection models performed a specific task, like detecting penguins in an image. However, recent advancements in deep learning have given rise to foundation models. These are large models trained on massive datasets in a general manner, making them adaptable for a wide range of tasks. Examples of such models include CLIP for image classification, SAM for segmentation, and GroundingDino for object detection. Foundation models are generally large and computationally demanding. When having no resources limitations, they can be used directly for zero-shot inference. Otherwise, they can be used to tag a datasets for training a smaller, more specific model in a process known as distillation.
In this guide, we’ll learn how to use GroundingDino model for zero-shot inference of a tomatoes image. We’ll explore the algorithm’s capabilities and use it to tag an entire tomato dataset. The resulted dataset can then be used to train a downstream target model such as YOLO.
GroundingDino
Background
GroundingDino is a state-of-the-art (SOTA) algorithm developed by IDEA-Research in 2023 [1]. It detects objects from images using text prompts. The name “GroundingDino” is a combination of “grounding” (a process that links vision and language understanding in AI systems) and the transformer-based detector “DINO” [2]. This algorithm is a zero-shot object detector, which means it can identify objects from categories it was not specifically trained on, without needing to see any examples (shots).
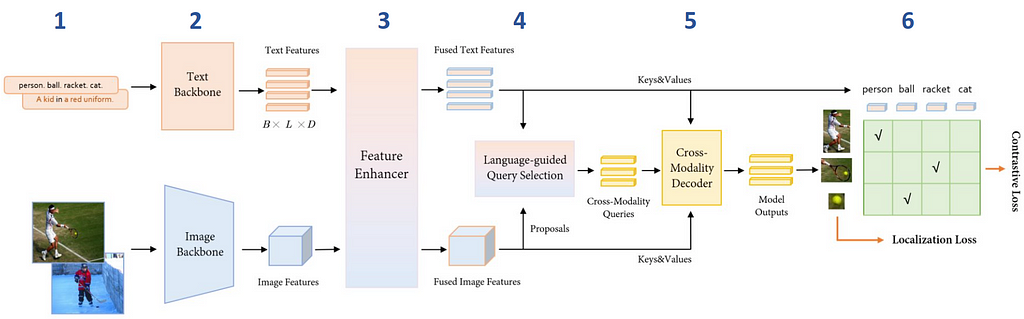
Architecture
- The model takes pairs of image and text description as inputs.
- Image features are extracted with an image backbone such as Swin Transformer, and text features with a text backbone like BERT.
- To fuse image and text modalities into a single representation, both types of features are fed into the Feature Enhancer module.
- Next, the ‘Language-guided Query Selection’ module selects the features most relevant to the input text to use as decoder queries.
- These queries are then fed into a decoder to refine the prediction of object detection boxes that best align with the text information.
- The model outputs 900 object bounding boxes and their similarity scores to the input words. The boxes with similarity scores above the box_threshold are chosen, and words whose similarities are higher than the text_threshold as predicted labels.
Prompt Engineering
The GroundingDino model encodes text prompts into a learned latent space. Altering the prompts can lead to different text features, which can affect the performance of the detector. To enhance prediction performance, it’s advisable to experiment with multiple prompts, choosing the one that delivers the best results. It’s important to note that while writing this article I had to try several prompts before finding the ideal one, sometimes encountering unexpected results.
Code Implementation
Getting Started
To begin, we’ll clone the GroundingDino repository from GitHub, set up the environment by installing the necessary dependencies, and download the pre-trained model weights.
# Clone:
!git clone https://github.com/IDEA-Research/GroundingDINO.git
# Install
%cd GroundingDINO/
!pip install -r requirements.txt
!pip install -q -e .
# Get weights
!wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
Inference on an image
We’ll start our exploration of the object detection algorithm by applying it to a single image of tomatoes. Our initial goal is to detect all the tomatoes in the image, so we’ll use the text prompt tomato. If you want to use different category names, you can separate them with a dot .. Note that the colors of the bounding boxes are random and have no particular meaning.
python3 demo/inference_on_a_image.py
--config_file 'groundingdino/config/GroundingDINO_SwinT_OGC.py'
--checkpoint_path 'groundingdino_swint_ogc.pth'
--image_path 'tomatoes_dataset/tomatoes1.jpg'
--text_prompt 'tomato'
--box_threshold 0.35
--text_threshold 0.01
--output_dir 'outputs'

GroundingDino not only detects objects as categories, such as tomato, but also comprehends the input text, a task known as Referring Expression Comprehension (REC). Let’s change the text prompt from tomato to ripened tomato, and obtain the outcome:
python3 demo/inference_on_a_image.py
--config_file 'groundingdino/config/GroundingDINO_SwinT_OGC.py'
--checkpoint_path 'groundingdino_swint_ogc.pth'
--image_path 'tomatoes_dataset/tomatoes1.jpg'
--text_prompt 'ripened tomato'
--box_threshold 0.35
--text_threshold 0.01
--output_dir 'outputs'

Remarkably, the model can ‘understand’ the text and differentiate between a ‘tomato’ and a ‘ripened tomato’. It even tags partially ripened tomatoes that aren’t fully red. If our task requires tagging only fully ripened red tomatoes, we can adjust the box_threshold from the default 0.35 to 0.5.
python3 demo/inference_on_a_image.py
--config_file 'groundingdino/config/GroundingDINO_SwinT_OGC.py'
--checkpoint_path 'groundingdino_swint_ogc.pth'
--image_path 'tomatoes_dataset/tomatoes1.jpg'
--text_prompt 'ripened tomato'
--box_threshold 0.5
--text_threshold 0.01
--output_dir 'outputs'
Generation of tagged dataset
Even though GroundingDino has remarkable capabilities, it’s a large and slow model. If real-time object detection is needed, consider using a faster model like YOLO. Training YOLO and similar models require a lot of tagged data, which can be expensive and time-consuming to produce. However, if your data isn’t unique, you can use GroundingDino to tag it. To learn more about efficient YOLO training, refer to my previous article [4].
The GroundingDino repository includes a script to annotate image datasets in the COCO format, which is suitable for YOLOx, for instance.
from demo.create_coco_dataset import main
main(image_directory= 'tomatoes_dataset',
text_prompt= 'tomato',
box_threshold= 0.35,
text_threshold = 0.01,
export_dataset = True,
view_dataset = False,
export_annotated_images = True,
weights_path = 'groundingdino_swint_ogc.pth',
config_path = 'groundingdino/config/GroundingDINO_SwinT_OGC.py',
subsample = None
)
- export_dataset — If set to True, the COCO format annotations will be saved in a directory named ‘coco_dataset’.
- view_dataset — If set to True, the annotated dataset will be displayed for visualization in the FiftyOne app.
- export_annotated_images — If set to True, the annotated images will be stored in a directory named ‘images_with_bounding_boxes’.
- subsample (int) — If specified, only this number of images from the dataset will be annotated.
Different YOLO algorithms require different annotation formats. If you’re planning to train YOLOv5 or YOLOv8, you’ll need to export your dataset in the YOLOv5 format. Although the export type is hard-coded in the main script, you can easily change it by adjusting the dataset_type argument in create_coco_dataset.main, from fo.types.COCODetectionDataset to fo.types.YOLOv5Dataset(line 72). To keep things organized, we’ll also change the output directory name from ‘coco_dataset’ to ‘yolov5_dataset’. After changing the script, run create_coco_dataset.main again.
if export_dataset:
dataset.export(
'yolov5_dataset',
dataset_type=fo.types.YOLOv5Dataset
)
Concluding remarks
GroundingDino offers a significant leap in object detection annotations by using text prompts. In this tutorial, we have explored how to use the model for automated labeling of an image or a whole dataset. It’s crucial, however, to manually review and verify these annotations before they are utilized in training subsequent models.
_________________________________________________________________
A user-friendly Jupyter notebook containing the complete code is included for your convenience:
Thank you for reading!
Want to learn more?
- Explore additional articles I’ve written
- Subscribe to get notified when I publish articles
- Follow me on Linkedin
References
[1] Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection, 2023.
[2] Dino: Detr with improved denoising anchor boxes for end-to-end object detection, 2022.
[3] An Open and Comprehensive Pipeline for Unified Object Grounding and Detection, 2023.
[4] The practical guide for Object Detection with YOLOv5 algorithm, by Dr. Lihi Gur Arie.
Automatic Labeling of Object Detection Datasets Using GroundingDino was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Automatic Labeling of Object Detection Datasets Using GroundingDino
Go Here to Read this Fast! Automatic Labeling of Object Detection Datasets Using GroundingDino