Transform raw transcripts into well-structured documents

Video chaptering is the task of segmenting a video into distinct chapters. Besides its use as a navigation aid as seen with YouTube chapters, it is also core to a series of downstream applications ranging from information retrieval (e.g., RAG semantic chunking), to referencing or summarization.
In a recent project, I needed to automate this task and was suprised by the limited options available, especially in the open-source domain. While some professional tools or paid APIs offer such services, I couldn’t find any library or tutorial that provided a sufficiently robust and accurate solution. If you know of any, please share them in the comment!
And in case you wonder why not simply copy and paste the transcript into a large language model (LLM) and ask for chapter headings, this won’t be effective for two reasons. First, LLMs cannot consistently preserve timestamp information to link them back to chapter titles. Second, LLMs often overlook important sections when dealing with long transcripts.
I therefore ended up designing a custom workflow by relying on LLMs for different language processing subtasks (text formatting, paragraph structuring, chapter segmentation and title generation), and on a TF-IDF statistics to add timestamps back after the paragraph structuring.

The resulting workflow turns out to work pretty well, often generating chapters that replicate or enhance YouTube’s suggested ones. The tool additionally allows to export poorly formatted transcripts into well-structured documents, as illustrated above and on this HuggingFace space.
This blog post aims at explaining its main steps, which are outlined in the diagram below:
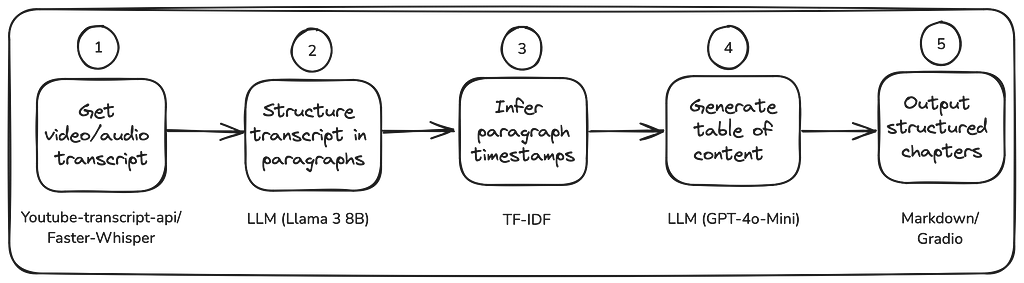
The key steps in the workflow lie in structuring the transcript in paragraphs (step 2) before grouping the paragraphs into chapters from which a table of contents is derived (step 4). Note that these two steps may rely on different LLMs: A fast and cheap LLM such as LLama 3 8B for the simple task of text editing and paragraph identification, and a more sophisticated LLM such as GPT-4o-mini for the generation of the table of contents. In between, TF-IDF is used to add back timestamp information to the structured paragraphs.
The rest of the post describes each step in more detail.
Check out the accompanying Github repository and Colab notebook to explore on your own!
1) Get the video/audio transcript
Let us use as an example the first lecture of the course ‘MIT 6.S191: Introduction to Deep Learning’ (IntroToDeepLearning.com) by Alexander Amini and Ava Amini (licensed under the MIT License).
Note that chapters are already provided in the video description.

This provides us with a baseline to qualitatively compare our chaptering later in this post.
YouTube transcript API
For YouTube videos, an automatically generated transcript is usually made available by YouTube. A convenient way to retrieve that transcript is by calling the get_transcript method of the Python youtube_transcript_api library. The method takes the YouTube video_id library as argument:
# https://www.youtube.com/watch?v=ErnWZxJovaM
video_id = "ErnWZxJovaM" # MIT Introduction to Deep Learning - 2024
# Retrieve transcript with the youtube_transcript_api library
from youtube_transcript_api import YouTubeTranscriptApi
transcript = YouTubeTranscriptApi.get_transcript(video_id, languages=["en"])
This returns the transcript as a list of text and timestamp key-value pairs:
[{'text': '[Music]', 'start': 1.17},
{'text': 'good afternoon everyone and welcome to', 'start': 10.28},
{'text': 'MIT sus1 191 my name is Alexander amini', 'start': 12.88},
{'text': "and I'll be one of your instructors for", 'start': 16.84},
...]
The transcript is however poorly formatted: it lacks punctuation and contains typos (‘MIT sus1 191’ instead of ‘MIT 6.S191′, or ‘amini’ instead of ‘Amini’).
Speech-to-text with Whisper
Alternatively, a speech-to-text library can be used to infer the transcript from a video or audio file. We recommend using faster-whisper, which is a fast implementation of the state-of-the-art open-source whisper model.
The models come in different size. The most accurate is the ‘large-v3’, which is able to transcribe about 15 minutes of audio per minute on a T4 GPU (available for free on Google Colab).
from faster_whisper import WhisperModel
# Load Whisper model
whisper_model = WhisperModel("large-v3",
device="cuda" if torch.cuda.is_available() else "cpu",
compute_type="float16",
)
# Call the Whisper transcribe function on the audio file
initial_prompt = "Use punctuation, like this."
segments, transcript_info = whisper_model.transcribe(audio_file, initial_prompt=initial_prompt, language="en")
The result of the transcription is provided as segments which can be easily converted in a list of text and timestamps as with the youtube_transcript_api library.
Tip: Whisper may sometimes not include the punctuation. The initial_prompt argument can be used to nudge the model to add punctuation by providing a small sentence containing punctuation.
Below is an excerpt of the transcription of the our video example with whisper large-v3:
[{'start': 0.0, 'text': ' Good afternoon, everyone, and welcome to MIT Success 191.'},
{'start': 15.28, 'text': " My name is Alexander Amini, and I'll be one of your instructors for the course this year"},
{'start': 19.32, 'duration': 2.08, 'text': ' along with Ava.'}
...]
Note that compared to the YouTube transcription, the punctuation is added. Some transcription errors however still remain (‘MIT Success 191’ instead of ‘MIT 6.S191′).
2) Structure the transcript in paragraphs
Once a transcript is available, the second stage consists in editing and structuring the transcript in paragraphs.
Transcript editing refers to changes made to improve readability. This involves, for example, adding punctuation if it is missing, correcting grammatical errors, removing verbal tics, etc.
The structuring in paragraphs also improves readability, and additionnally serves as a preprocessing step for identifying chapters in stage 4, since chapters will be formed by grouping paragraphs together.
Paragraph editing and structuring can be carried out in a single operation, using an LLM. We illustrated below the expected result of this stage:

This task does not require a very sophisticated LLM since it mostly consists in reformulating content. At the time of writing this article, decent results could be obtained with for example GPT-4o-mini or Llama 3 8B, and the following system prompt:
You are a helpful assistant.
Your task is to improve the user input’s readability: add punctuation if needed and remove verbal tics, and structure the text in paragraphs separated with ‘nn’.
Keep the wording as faithful as possible to the original text.
Put your answer within <answer></answer> tags.
We rely on OpenAI compatible chat completion API for LLM calling, with messages having the roles of either ‘system’, ‘user’ or ‘assistant’. The code below illustrates the instantiation of an LLM client with Groq, using LLama 3 8B:
# Connect to Groq with a Groq API key
llm_client = Groq(api_key=api_key)
model = "llama-8b-8192"
# Extract text from transcript
transcript_text = ' '.join([s['text'] for s in transcript])
# Call LLM
response = client.chat.completions.create(
messages=[
{
"role": "system",
"content": system_prompt
},
{
"role": "user",
"content": transcript_text
}
],
model=model,
temperature=0,
seed=42
)
Given a piece of raw ‘transcript_text’ as input, this returns an edited piece of text within <answer> tags:
response_content=response.choices[0].message.content
print(response_content)
"""
<answer>
Good afternoon, everyone, and welcome to MIT 6.S191. My name is Alexander Amini, and I'll be one of your instructors for the course this year, along with Ava. We're really excited to welcome you to this incredible course.
This is a fast-paced and intense one-week course that we're about to go through together. We'll be covering the foundations of a rapidly changing field, and a field that has been revolutionizing many areas of science, mathematics, physics, and more.
Over the past decade, AI and deep learning have been rapidly advancing and solving problems that we didn't think were solvable in our lifetimes. Today, AI is solving problems beyond human performance, and each year, this lecture is getting harder and harder to teach because it's supposed to cover the foundations of the field.
</answer>
"""
Let us then extract the edited text from the <answer> tags, divide it into paragraphs, and structure the results as a JSON dictionary consisting of paragraph numbers and pieces of text:
import re
pattern = re.compile(r'<answer>(.*?)</answer>', re.DOTALL)
response_content_edited = pattern.findall(response_content)
paragraphs = response_content_edited.strip().split('nn')
paragraphs_dict = [{'paragraph_number': i, 'paragraph_text': paragraph} for i, paragraph in enumerate(paragraphs)
print(paragraph_dict)
[{'paragraph_number': 0,
'paragraph_text': "Good afternoon, everyone, and welcome to MIT 6.S191. My name is Alexander Amini, and I'll be one of your instructors for the course this year, along with Ava. We're really excited to welcome you to this incredible course."},
{'paragraph_number': 1,
'paragraph_text': "This is a fast-paced and intense one-week course that we're about to go through together. We'll be covering the foundations of a rapidly changing field, and a field that has been revolutionizing many areas of science, mathematics, physics, and more."},
{'paragraph_number': 2,
'paragraph_text': "Over the past decade, AI and deep learning have been rapidly advancing and solving problems that we didn't think were solvable in our lifetimes. Today, AI is solving problems beyond human performance, and each year, this lecture is getting harder and harder to teach because it's supposed to cover the foundations of the field."}]
Note that the input should not be too long as the LLM will otherwise ‘forget’ part of the text. For long inputs, the transcript must be split in chunks to improve reliability. We noticed that GPT-4o-mini handles well up to 5000 characters, while Llama 3 8B can only handle up to 1500 characters. The notebook provides the function transcript_to_paragraphs which takes care of splitting the transcript in chunks.
3) Infer paragraph timestamps with TF-IDF
The transcript is now structured as a list of edited paragraphs, but the timestamps have been lost in the process.
The third stage consists in adding back timestamps, by inferring which segment in the raw transcript is the closest to each paragraph.
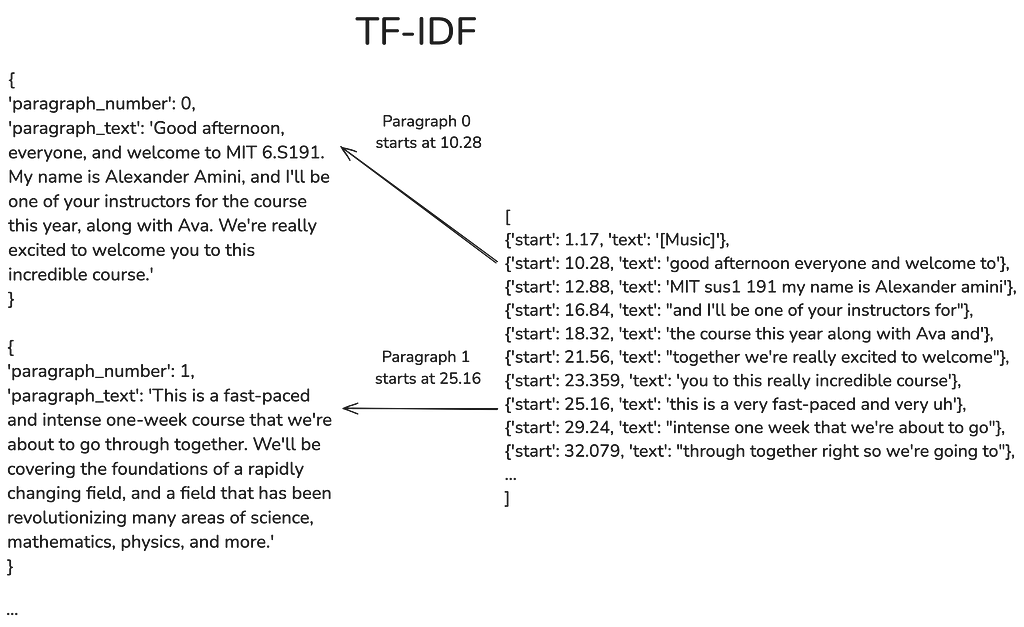
We rely for this task on the TF-IDF metric. TF-IDF stands for term frequency–inverse document frequency and is a similarity measure for comparing two pieces of text. The measure works by computing the number of similar words, giving more weight to words which appear less frequently.
As a preprocessing step, we adjust the transcript segments and paragraph beginnings so that they contain the same number of words. The text pieces should be long enough so that paragraph beginnings can be successfully matched to a unique transcript segment. We find that using 50 words works well in practice.
num_words = 50
transcript_num_words = transform_text_segments(transcript, num_words=num_words)
paragraphs_start_text = [{"start": p['paragraph_number'], "text": p['paragraph_text']} for p in paragraphs]
paragraphs_num_words = transform_text_segments(paragraphs_start_text, num_words=num_words)
We then rely on the sklearn library and its TfidfVectorizer and cosine_similarity function to run TF-IDF and compute similarities between each paragraph beginning and transcript segment. below is an example of code for finding the best match index in the transcript segments for the first paragraph.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# Paragraph for which to find the timestamp
paragraph_i = 0
# Create a TF-IDF vectorizer
vectorizer = TfidfVectorizer().fit_transform(transcript_num_words + paragraphs_num_words)
# Get the TF-IDF vectors for the transcript and the excerpt
vectors = vectorizer.toarray()
# Extract the TF-IDF vector for the paragraph
paragraph_vector = vectors[len(transcript_num_words) + paragraph_i]
# Calculate the cosine similarity between the paragraph vector and each transcript chunk
similarities = cosine_similarity(vectors[:len(transcript_num_words)], paragraph_vector.reshape(1, -1))
# Find the index of the most similar chunk
best_match_index = int(np.argmax(similarities))
We wrapped the process in a add_timestamps_to_paragraphs function, which adds timestamps to paragraphs, together with the matched segment index and text:
paragraphs = add_timestamps_to_paragraphs(transcript, paragraphs, num_words=50)
#Example of output for the first paragraph:
print(paragraphs[0])
{'paragraph_number': 0,
'paragraph_text': "Good afternoon, everyone, and welcome to MIT 6.S191. My name is Alexander Amini, and I'll be one of your instructors for the course this year, along with Ava. We're really excited to welcome you to this incredible course.",
'matched_index': 1,
'matched_text': 'good afternoon everyone and welcome to',
'start_time': 10}
In the example above, the first paragraph (numbered 0) is found to match the transcript segment number 1 that starts at time 10 (in seconds).
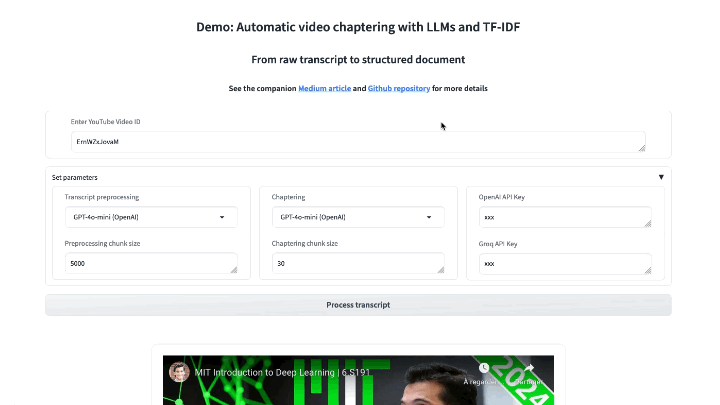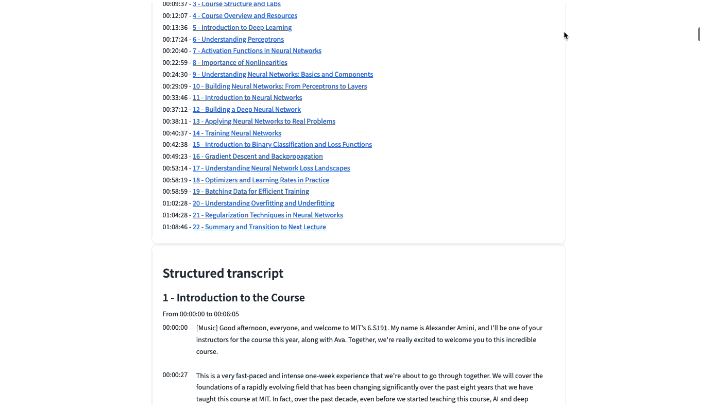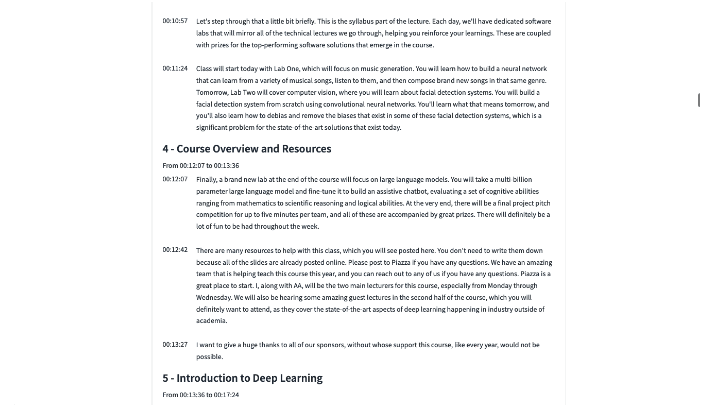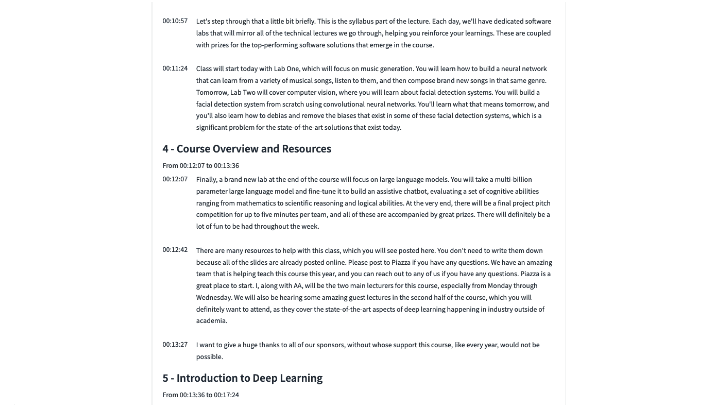
4) Generate table of content
The table of content is then found by grouping consecutive paragraphs into chapters and identifying meaningful chapter titles. The task is mostly carried out by an LLM, which is instructed to transform an input consisting in a list of JSON paragraphs into an output consisting in a list of JSON chapter titles with the starting paragraph numbers:
system_prompt_paragraphs_to_toc = """
You are a helpful assistant.
You are given a transcript of a course in JSON format as a list of paragraphs, each containing 'paragraph_number' and 'paragraph_text' keys.
Your task is to group consecutive paragraphs in chapters for the course and identify meaningful chapter titles.
Here are the steps to follow:
1. Read the transcript carefully to understand its general structure and the main topics covered.
2. Look for clues that a new chapter is about to start. This could be a change of topic, a change of time or setting, the introduction of new themes or topics, or the speaker's explicit mention of a new part.
3. For each chapter, keep track of the paragraph number that starts the chapter and identify a meaningful chapter title.
4. Chapters should ideally be equally spaced throughout the transcript, and discuss a specific topic.
Format your result in JSON, with a list dictionaries for chapters, with 'start_paragraph_number':integer and 'title':string as key:value.
Example:
{"chapters":
[{"start_paragraph_number": 0, "title": "Introduction"},
{"start_paragraph_number": 10, "title": "Chapter 1"}
]
}
"""
An important element is to specifically ask for a JSON output, which increases the chances to get a correctly formatted JSON output that can later be loaded back in Python.
GPT-4o-mini is used for this task, as it is more cost-effective than OpenAI’s GPT-4o and generally provides good results. The instructions are provided through the ‘system’ role, and paragraphs are provided in JSON format through the ‘user’ role.
# Connect to OpenAI with an OpenAI API key
llm_client_get_toc = OpenAI(api_key=api_key)
model_get_toc = "gpt-4o-mini-2024-07-18"
# Dump JSON paragraphs as text
paragraphs_number_text = [{'paragraph_number': p['paragraph_number'], 'paragraph_text': p['paragraph_text']} for p in paragraphs]
paragraphs_json_dump = json.dumps(paragraphs_number_text)
# Call LLM
response = client_get_toc.chat.completions.create(
messages=[
{
"role": "system",
"content": system_prompt_paragraphs_to_toc
},
{
"role": "user",
"content": paragraphs_json_dump
}
],
model=model_get_toc,
temperature=0,
seed=42
)
Et voilà! The call returns the list of chapter titles together with the starting paragraph number in JSON format:
print(response)
{
"chapters": [
{
"start_paragraph_number": 0,
"title": "Introduction to the Course"
},
{
"start_paragraph_number": 17,
"title": "Foundations of Intelligence and Deep Learning"
},
{
"start_paragraph_number": 24,
"title": "Course Structure and Expectations"
}
....
]
}
As in step 2, the LLM may struggle with long inputs and dismiss part of the input. The solution consists again in splitting the input into chunks, which is implemented in the notebook with the paragraphs_to_toc function and the chunk_size parameter.
5) Output structured chapters
This last stage combines the paragraphs and the table of content to create a structured JSON file with chapters, an example of which is provided in the accompanying Github repository.
We illustrate below the resulting chaptering (right), compared to the baseline chaptering that was available from the YouTube description (left):
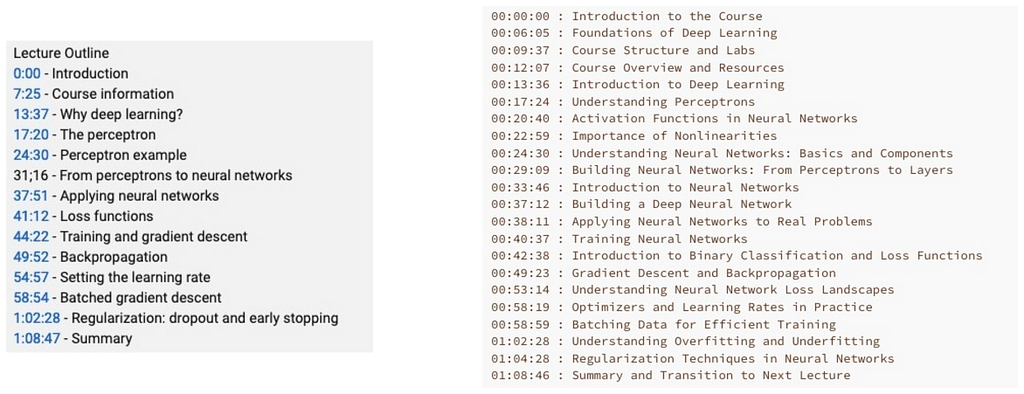
The comparison is mostly qualitative as there is no ‘ground truth’. Overall, the approach described in this post identified similar chapters but provides a slightly more refined segmentation of the video. A manual check of both chapterings revealed that the baseline chaptering is off regarding course information, which indeed starts at 9:37 and not at 7:25.
A couple of other examples of chaptering are given on this HuggingFace space. The whole workflow is bundled as a Gradio app at the end of the accompanying notebook, making it easier to test it on your own videos.
To go further
- From Text Segmentation to Smart Chaptering:
A Novel Benchmark for Structuring Video Transcriptions - Review of existing solutions for transcript summarizers
- https://paperswithcode.com/task/text-segmentation
- https://en.wikipedia.org/wiki/Video_chapter
Note:
- Unless otherwise noted, all images are by the author
Enjoyed this post? Share your thoughts, give it claps, or connect with me on LinkedIn .
Automate Video Chaptering with LLMs and TF-IDF was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Automate Video Chaptering with LLMs and TF-IDF
Go Here to Read this Fast! Automate Video Chaptering with LLMs and TF-IDF