Prosecutors in South Korea have reportedly arrested three top executives of HaruInvest, a crypto deposit platform, for allegedly defrauding customers and embezzling over 1 trillion won in coins, according to Yonhap News. Just a day after a statement promising stricter screening of crypto executives was issued, the Seoul Southern District Prosecutors’ Office’s Joint Investigation Team […]
The Mollars token presale has moved back to their original ‘.com’ domain name. It appears after news broke that Peter Sunde owned ‘Njal.la’ was attempting to hi-jack the domain, the Pirate-bay cofounder found it better to return the TLD to its rightful owner. Relaunching earlier today, the initial coin offering sales surged past 1.3-million […]
A practical guide to tag object detection datasets with the GroundingDino algorithm. Code included.
Annotations by the author using GroundingDino with the ‘ripened tomato’ prompt. Image by Markus Spiske.
Introduction
Until recently, object detection models performed a specific task, like detecting penguins in an image. However, recent advancements in deep learning have given rise to foundation models. These are large models trained on massive datasets in a general manner, making them adaptable for a wide range of tasks. Examples of such models include CLIP for image classification, SAM for segmentation, and GroundingDino for object detection. Foundation models are generally large and computationally demanding. When having no resources limitations, they can be used directly for zero-shot inference. Otherwise, they can be used to tag a datasets for training a smaller, more specific model in a process known as distillation.
In this guide, we’ll learn how to use GroundingDino model for zero-shot inference of a tomatoes image. We’ll explore the algorithm’s capabilities and use it to tag an entire tomato dataset. The resulted dataset can then be used to train a downstream target model such as YOLO.
GroundingDino
Background
GroundingDino is a state-of-the-art (SOTA) algorithm developed by IDEA-Research in 2023 [1]. It detects objects from images using text prompts. The name “GroundingDino” is a combination of “grounding” (a process that links vision and language understanding in AI systems) and the transformer-based detector “DINO” [2]. This algorithm is a zero-shot object detector, which means it can identify objects from categories it was not specifically trained on, without needing to see any examples (shots).
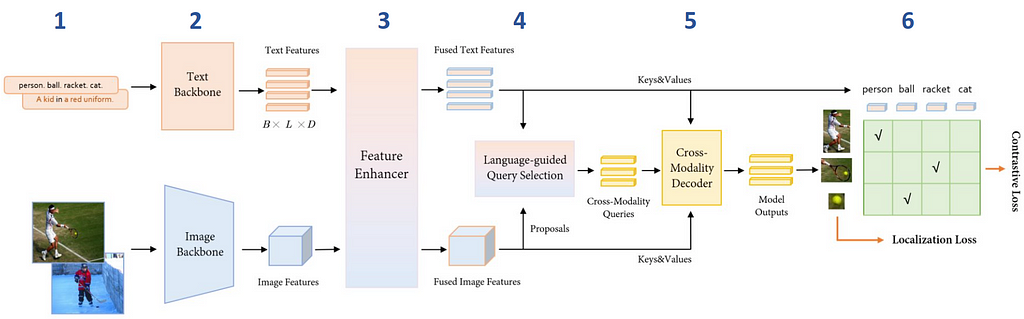
Architecture
The model takes pairs of image and text description as inputs.
Image features are extracted with an image backbone such as Swin Transformer, and text features with a text backbone like BERT.
To fuse image and text modalities into a single representation, both types of features are fed into the Feature Enhancer module.
Next, the ‘Language-guided Query Selection’ module selects the features most relevant to the input text to use as decoder queries.
These queries are then fed into a decoder to refine the prediction of object detection boxes that best align with the text information.
The model outputs 900 object bounding boxes and their similarity scores to the input words. The boxes with similarity scores above the box_threshold are chosen, and words whose similarities are higher than the text_threshold as predicted labels.
Image by Xiangyu et al., 2023 [3]
Prompt Engineering
The GroundingDino model encodes text prompts into a learned latent space. Altering the prompts can lead to different text features, which can affect the performance of the detector. To enhance prediction performance, it’s advisable to experiment with multiple prompts, choosing the one that delivers the best results. It’s important to note that while writing this article I had to try several prompts before finding the ideal one, sometimes encountering unexpected results.
Code Implementation
Getting Started
To begin, we’ll clone the GroundingDino repository from GitHub, set up the environment by installing the necessary dependencies, and download the pre-trained model weights.
# Get weights !wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
Inference on an image
We’ll start our exploration of the object detection algorithm by applying it to a single image of tomatoes. Our initial goal is to detect all the tomatoes in the image, so we’ll use the text prompt tomato. If you want to use different category names, you can separate them with a dot .. Note that the colors of the bounding boxes are random and have no particular meaning.
Annotations with the ‘tomato’ prompt. Image by Markus Spiske.
GroundingDino not only detects objects as categories, such as tomato, but also comprehends the input text, a task known as Referring Expression Comprehension (REC). Let’s change the text prompt from tomato to ripened tomato, and obtain the outcome:
Annotations with the ‘ripened tomato’ prompt. Image by Markus Spiske.
Remarkably, the model can ‘understand’ the text and differentiate between a ‘tomato’ and a ‘ripened tomato’. It even tags partially ripened tomatoes that aren’t fully red. If our task requires tagging only fully ripened red tomatoes, we can adjust the box_threshold from the default 0.35 to 0.5.
Annotations with the ‘ripened tomato’ prompt, with box_threshold = 0.5. Image by Markus Spiske.
Generation of tagged dataset
Even though GroundingDino has remarkable capabilities, it’s a large and slow model. If real-time object detection is needed, consider using a faster model like YOLO. Training YOLO and similar models require a lot of tagged data, which can be expensive and time-consuming to produce. However, if your data isn’t unique, you can use GroundingDino to tag it. To learn more about efficient YOLO training, refer to my previous article [4].
The GroundingDino repository includes a script to annotate image datasets in the COCO format, which is suitable for YOLOx, for instance.
export_dataset — If set to True, the COCO format annotations will be saved in a directory named ‘coco_dataset’.
view_dataset — If set to True, the annotated dataset will be displayed for visualization in the FiftyOne app.
export_annotated_images — If set to True, the annotated images will be stored in a directory named ‘images_with_bounding_boxes’.
subsample (int) — If specified, only this number of images from the dataset will be annotated.
Different YOLO algorithms require different annotation formats. If you’re planning to train YOLOv5 or YOLOv8, you’ll need to export your dataset in the YOLOv5 format. Although the export type is hard-coded in the main script, you can easily change it by adjusting the dataset_type argument in create_coco_dataset.main, from fo.types.COCODetectionDataset to fo.types.YOLOv5Dataset(line 72). To keep things organized, we’ll also change the output directory name from ‘coco_dataset’ to ‘yolov5_dataset’. After changing the script, run create_coco_dataset.main again.
if export_dataset: dataset.export( 'yolov5_dataset', dataset_type=fo.types.YOLOv5Dataset )
Concluding remarks
GroundingDino offers a significant leap in object detection annotations by using text prompts. In this tutorial, we have explored how to use the model for automated labeling of an image or a whole dataset. It’s crucial, however, to manually review and verify these annotations before they are utilized in training subsequent models.
The UK government is investing over £100mn in AI R&D and regulation, in its first official response to the AI white paper consultation it released in March 2023. Unlike the EU’s sweeping AI law, the UK’s announcement further backs the white paper’s “pro-innovation” approach. Aiming to establish rules that can be “more agile” than those of competitor nations, the government confirmed once again that it “will not rush to legislate.” Instead, it will retain a context-based approach that empowers regulators to address potential risks. For this reason, the UK is pledging £10mn to prepare and upskill regulators to evaluate the opportunities…
Webex for Apple Vision Pro is built as a native app with Spatial Audio and Persona support, plus it includes all of the usual Webex features.
Webex is available on Apple Vision Pro
Apple Vision Pro launched on February 2 with around 600 native apps available. Webex was one of those apps and has been promoted as one of the four productivity picks in the App Store.
Even though the app is already available, it is being officially launched during the Cisco Live Amsterdam conference. Cisco EVP and GM of Security and Collaboration Jerry Patel shared his thoughts on spatial computing and working with Apple on the future of hybrid work.
Subtitles can be useful, but they can also be a pain if you can’t figure out how to get rid of them. Fortunately, turning them off in Netflix is fairly simple.
Spam and other unwelcome emails can be annoying. But if you’re a Gmail user who wants to block someone from messaging you, the process is simple. Here’s how.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.