Ronin (RON) saw its value plummet by 26% right after its listing on the Binance exchange, erasing a 15% gain and marking a nearly 30% drop in the last 24 hours. Following a short-lived recovery that pushed Ronin above the $3 mark for the first time since February 2022, the digital asset encountered strong resistance […]
In the rapidly evolving digital landscape, the narrative surrounding Decentralized Physical Infrastructure Networks (DePIN) is gaining significant traction, marking a pivotal shift in the development and management of infrastructures. DePIN, with its diverse sectors ranging from data storage to computing and beyond, exemplifies decentralised solutions’ broad applicability and potential in reshaping traditional infrastructures. Among these […]
Get answers to your crypto investment questions. Learn about trends, promising coins, market risks, and whether investing in cryptocurrency is wise in 2024. Despite a buoyant surge in Dec. 2023, leading to an over 16% increase in the total crypto…
Digital Currency Group (DCG), the parent company of the defunct crypto lender Genesis, has filed an objection against the approval of its subsidiary’s bankruptcy plan, which was created via a “clandestine approach.” In a Feb. 5 court filing, DCG argued that Genesis’ plan aims to exceed legal obligations by overcompensating creditors. According to the firm, […]
In a bold move, cross-border remittance giant Ripple is set to re-engage with the U.S. market following a partial victory against the U.S. Securities and Exchange Commission (SEC) mid-last year.
For a data engineer building analytics from transactional systems such as ERP (enterprise resource planning) and CRM (customer relationship management), the main challenge lies in navigating the gap between raw operational data and domain knowledge. ERP and CRM systems are designed and built to fulfil a broad range of business processes and functions. This generalisation makes their data models complex and cryptic and require domain expertise.
Even harder to manage, a common setup within large organisations is to have several instances of these systems with some underlaying processes in charge of transmitting data among them, which could lead to duplications, inconsistencies, and opacity.
The disconnection between the operational teams immersed in the day-to-day functions and those extracting business value from data generated in the operational processes still remains a significant friction point.
Searching for data
Imagine being a data engineer/analyst tasked with identifying the top-selling products within your company. Your first step might be to locate the orders. Then you begin researching database objects and find a couple of views, but there are some inconsistencies between them so you do not know which one to use. Additionally, it is really hard to identify the owners, one of them has even recently left the company. As you do not want to start your development with uncertainty, you decide to go for the operational raw data directly. Does it sound familiar?
Accessing Operational Data
I used to connect to views in transactional databases or APIs offered by operational systems to request the raw data.
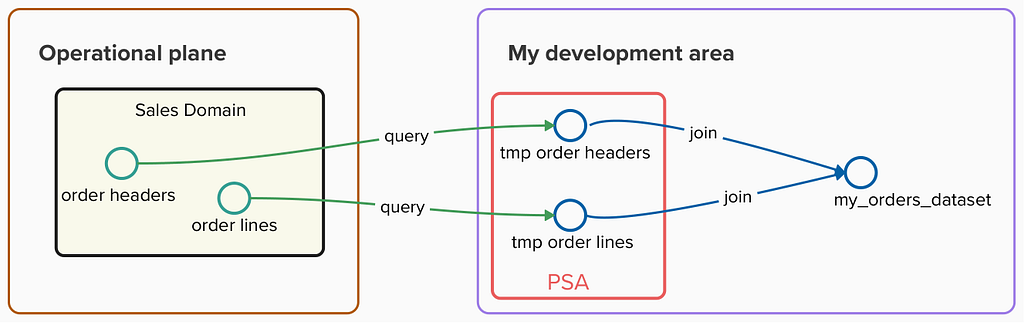
Order snapshots are stored in my own development area (image by the author)
To prevent my extractions from impacting performance on the operational side, I queried this data regularly and stored it in a persistent staging area (PSA) within my data warehouse. This allowed me to execute complex queries and data pipelines using these snapshots without consuming any resource from operational systems, but could result in unnecessary duplication of data in case I was not aware of other teams doing the same extraction.
Understanding Operational Data
Once the raw operational data was available, then I needed to deal with the next challenge: deciphering all the cryptic objects and properties and dealing with the labyrinth of dozens of relationships between them (i.e. General Material Data in SAP documented https://leanx.eu/en/sap/table/mara.html)
Even though standard objects within ERP or CRM systems are well documented, I needed to deal with numerous custom objects and properties that require domain expertise as these objects cannot be found in the standard data models. Most of the time I found myself throwing ‘trial-and-error’ queries in an attempt to align keys across operational objects, interpreting the meaning of the properties according to their values and checking with operational UI screenshots my assumptions.
Operational data management in Data Mesh
A Data Mesh implementation improved my experience in these aspects:
Knowledge: I could quickly identify the owners of the exposed data. The distance between the owner and the domain that generated the data is key to expedite further analytical development.
Discoverability: A shared data platform provides a catalog of operational datasets in the form of source-aligned data products that helped me to understand the status and nature of the data exposed.
Accessibility: I could easily request access to these data products. As this data is stored in the shared data platform and not in the operational systems, I did not need to align with operational teams for available windows to run my own data extraction without impacting operational performance.
Source-aligned Data Products
According to the Data Mesh taxonomy, data products built on top of operational sources are named Source-aligned Data Products:
Source domain datasets represent closely the raw data at the point of creation, and are not fitted or modelled for a particular consumer — Zhamak Dehghani
Source-aligned data products aim to represent operational sources within a shared data platform in a one-to-one relationship with operational entities and they should not hold any business logic that could alter any of their properties.
Ownership
In a Data Mesh implementation, these data products should strictlybe owned by the business domain that generates the raw data. The owner is responsible for the quality, reliability, and accessibility of their data and data is treated as a product that can be used by the same team and other data teams in other parts of the organisation.
This ownership ensures domain knowledge is close to the exposed data. This is critical to enabling the fast development of analytical data products, as any clarification needed by other data teams can be handled quickly and effectively.
Implementation
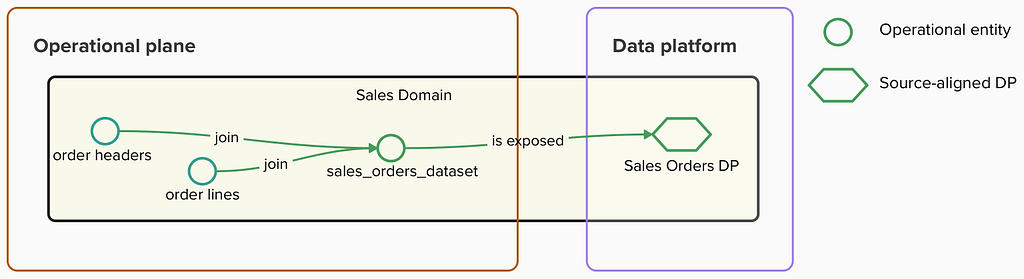
Following this approach, the Sales domain is responsible for publishing a ‘sales_orders’ data product and making it available in a shared data catalog.
Sales Orders DP exposing sales_orders_dataset (image by the author)
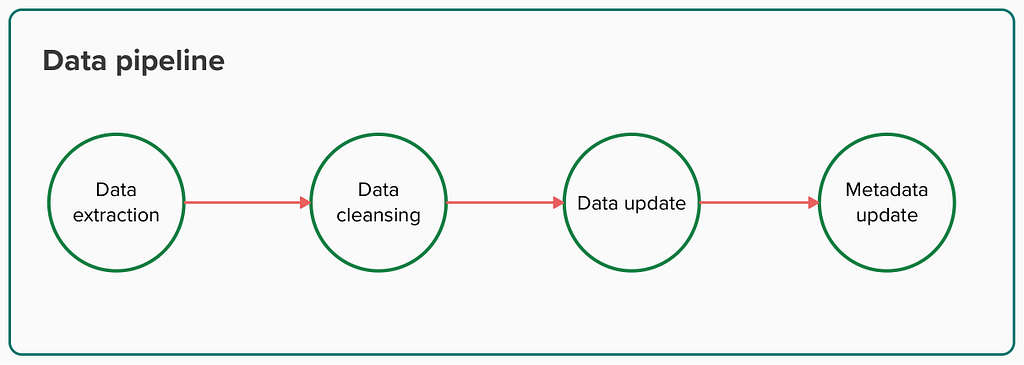
The data pipeline in charge of maintaining the data product could be defined like this:
Data pipeline steps (image by the author)
Data extraction
The first step to building source-aligned data products is to extract the data we want to expose from operational sources. There are a bunch of Data Integration tools that offer a UI to simplify the ingestion. Data teams can create a job there to extract raw data from operational sources using JDBC connections or APIs. To avoid wasting computational work, and whenever possible, only the updated raw data since the last extraction should be incrementally added to the data product.
Data cleansing
Now that we have obtained the desired data, the next step involves some curation, so consumers do not need to deal with existing inconsistencies in the real sources. Although any business logic should not not be implemented when building source-aligned data products, basic cleansing and standardisation is allowed.
-- Example of property standardisation in a sql query used to extract data case when lower(SalesDocumentCategory) = 'invoice' then 'Invoice' when lower(SalesDocumentCategory) = 'invoicing' then 'Invoice' else SalesDocumentCategory end as SALES_DOCUMENT_CATEGORY
Data update
Once extracted operational data is prepared for consumption, the data product’s internal dataset is incrementally updated with the latest snapshot.
One of the requirements for a data product is to be interoperable. This means that we need to expose global identifiers so our data product might be universally used in other domains.
Metadata update
Data products need to be understandable. Producers need to incorporate meaningful metadata for the entities and properties contained. This metadata should cover these aspects for each property:
Business description: What each property represents for the business. For example, “Business category for the sales order”.
Source system: Establish a mapping with the original property in the operational domain. For instance, “Original Source: ERP | MARA-MTART table BIC/MARACAT property”.
Data characteristics: Specific characteristics of the data, such as enumerations and options. For example, “It is an enumeration with these options: Invoice, Payment, Complaint”.
Data products also need to be discoverable. Producers need to publish them in a shared data catalog and indicate how the data is to be consumed by defining output port assets that serve as interfaces to which the data is exposed.
And data products must be observable. Producers need to deploy a set of monitors that can be shown within the catalog. When a potential consumer discovers a data product in the catalog, they can quickly understand the health of the data contained.
Consumer experience
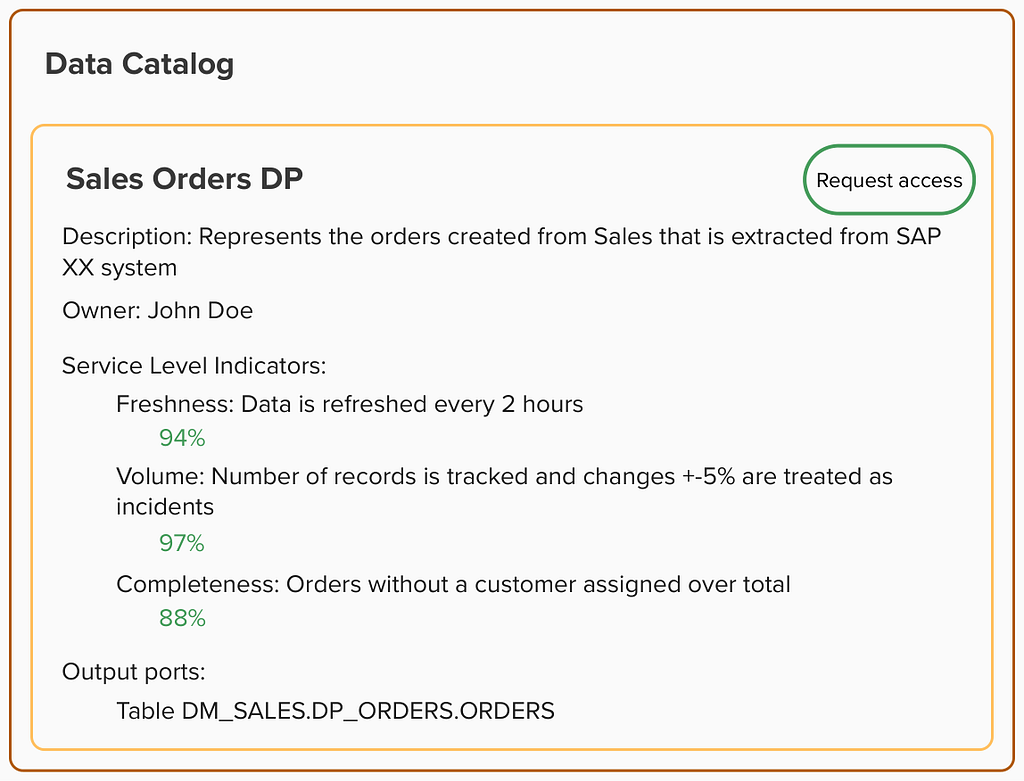
Now, again, imagine being a data engineer tasked with identifying the top-selling products within your company. But this time, imagine that you have access to a data catalog that offers data products that represent the truth of each domain shaping the business. You simply input ‘orders’ into the data product catalog and find the entry published by the Sales data team. And, at a glance, you can assess the quality and freshness of the data and read a detailed description of its contents.
Entry for Sales Orders DP within the Data Catalog example (image by the author)
This upgraded experience eliminates the uncertainties of traditional discovery, allowing you to start working with the data right away. But what’s more, you know who is accountable for the data in case further information is needed. And whenever there is an issue with the Sales orders data product, you will receive a notification so that you can take actions in advance.
Conclusion
We have identified several benefits of enabling operational data through source-aligned data products, especially when they are owned by data producers:
Curated operational data accessibility: In large organisations, source-aligned data products represent a bridge between operational and analytical planes.
Collision reduction with operational work: Operational systems accesses are isolated within source-aligned data products pipelines.
Source of truth: A common data catalog with a list of curated operational business objects reducing duplication and inconsistencies across the organisation.
Clear data ownership: Source-aligned data products should be owned by the domain that generates the operational data to ensure domain knowledge is close to the exposed data.
Based on my own experience, this approach works exceptionally well in scenarios where large organisations struggle with data inconsistencies across different domains and friction when building their own analytics on top of operational data. Data Mesh encourages each domain to build the ‘source of truth’ for the core entities they generate and make them available in a shared catalog allowing other teams to access them and create consistent metrics across the whole organisation. This enables analytical data teams to accelerate their work in generating analytics that drive real business value.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.