

A complete guide to big data analysis using Apache Hadoop (HDFS) and PySpark library in Python on game reviews on the Steam gaming platform.
With over 100 zettabytes (= 10¹²GB) of data produced every year around the world, the significance of handling big data is one of the most required skills today. Data Analysis, itself, could be defined as the ability to handle big data and derive insights from the never-ending and exponentially growing data. Apache Hadoop and Apache Spark are two of the basic tools that help us untangle the limitless possibilities hidden in large datasets. Apache Hadoop enables us to streamline data storage and distributed computing with its Distributed File System (HDFS) and the MapReduce-based parallel processing of data. Apache Spark is a big data analytics engine capable of EDA, SQL analytics, Streaming, Machine Learning, and Graph processing compatible with the major programming languages through its APIs. Both when combined form an exceptional environment for dealing with big data with the available computational resources — just a personal computer in most cases!
Let us unfold the power of Big Data and Apache Hadoop with a simple analysis project implemented using Apache Spark in Python.
To begin with, let’s dive into the installation of Hadoop Distributed File System and Apache Spark on a MacOS. I am using a MacBook Air with macOS Sonoma with an M1 chip.
Jump to the section —
- Installing Hadoop Distributed File System
- Installing Apache Spark
- Steam Review Analysis using PySpark
- What next?
1. Installing Hadoop Distributed File System
Thanks to Code With Arjun for the amazing article that helped me with the installation of Hadoop on my Mac. I seamlessly installed and ran Hadoop following his steps which I will show you here as well.
- a. Installing HomeBrew
I use Homebrew for installing applications on my Mac for ease. It can be directly installed on the system with the below code —
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
Once it is installed, you can run the simple code below to verify the installation.
brew --version
However, you will likely encounter an error saying, command not found, this is because the homebrew will be installed in a different location (Figure 2) and it is not executable from the current directory. For it to function, we add a path environment variable for the brew, i.e., adding homebrew to the .bash_profile.

You can avoid this step by using the full path to Homebrew in your commands, however, it might become a hustle at later stages, so not recommended!
echo ‘eval “$(/opt/homebrew/bin/brew shellenv)”’ >> /Users/rindhujajohnson/.bash_profile
eval “$(/opt/homebrew/bin/brew shellenv)”
Now, when you try, brew –version, it should show the Homebrew version correctly.
- b. Installing Hadoop
Disclaimer! Hadoop is a Java-based application and is supported by a Java Development Kit (JDK) version older than 11, preferably 8 or 11. Install JDK before continuing.
Thanks to Code With Arjun again for this video on JDK installation on MacBook M1.
Now, we install the Hadoop on our system using the brew command.
brew install hadoop
This command should install Hadoop seamlessly. Similar to the steps followed while installing HomeBrew, we should edit the path environment variable for Java in the Hadoop folder. The environment variable settings for the installed version of Hadoop can be found in the Hadoop folder within HomeBrew. You can use which hadoop command to find the location of the Hadoop installation folder. Once you locate the folder, you can find the variable settings at the below location. The below command takes you to the required folder for editing the variable settings (Check the Hadoop version you installed to avoid errors).
cd /opt/homebrew/Cellar/hadoop/3.3.6/libexec/etc/hadoop
You can view the files in this folder using the ls command. We will edit the hadoop-env.sh to enable the proper running of Hadoop on the system.

Now, we have to find the path variable for Java to edit the hadoop-ev.sh file using the following command.
/usr/libexec/java_home

We can open the hadoop-env.sh file in any text editor. I used VI editor, you can use any editor for the purpose. We can copy and paste the path — Library/Java/JavaVirtualMachines/adoptopenjdk-11.jdk/Contents/Home at the export JAVA_HOME = position.

Next, we edit the four XML files in the Hadoop folder.
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
</value>
</property>
</configuration>
With this, we have successfully completed the installation and configuration of HDFS on the local. To make the data on Hadoop accessible with Remote login, we can go to Sharing in the General settings and enable Remote Login. You can edit the user access by clicking on the info icon.
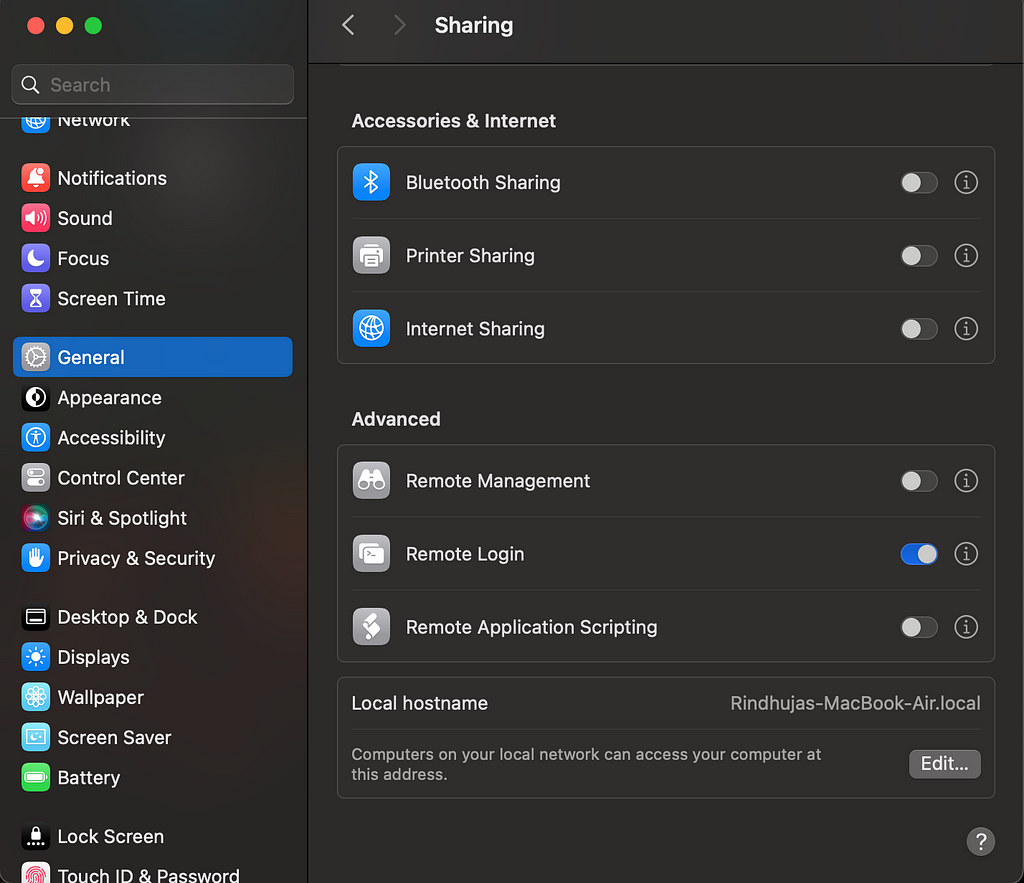
Let’s run Hadoop!
Execute the following commands
hadoop namenode -format
# starts the Hadoop environment
% start-all.sh
# Gathers all the nodes functioning to ensure that the installation was successful
% jps
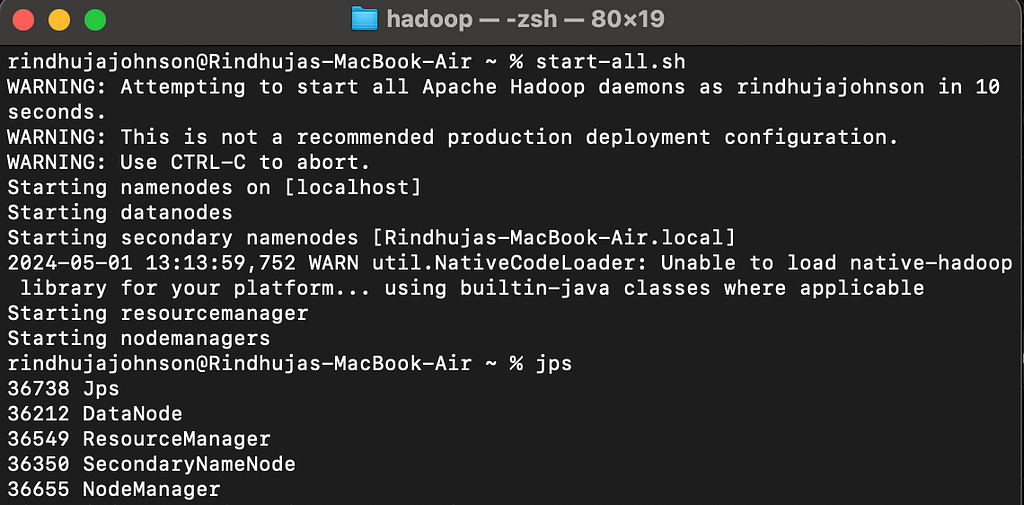
We are all set! Now let’s create a directory in HDFS and add the data will be working on. Let’s quickly take a look at our data source and details.
Data
The Steam Reviews Dataset 2021 (License: GPL 2) is a collection of reviews from about 21 million gamers covering over 300 different games in the year 2021. the data is extracted using Steam’s API — Steamworks — using the Get List function.
GET store.steampowered.com/appreviews/<appid>?json=1
The dataset consists of 23 columns and 21.7 million rows with a size of 8.17 GB (that is big!). The data consists of reviews in different languages and a boolean column that tells if the player recommends the game to other players. We will be focusing on how to handle this big data locally using HDFS and analyze it using Apache Spark in Python using the PySpark library.
- c. Uploading Data into HDFS
Firstly, we create a directory in the HDFS using the mkdir command. It will throw an error if we try to add a file directly to a non-existing folder.
hadoop fs -mkdir /user
hadoop fs - mkdir /user/steam_analysis
Now, we will add the data file to the folder steam_analysis using the put command.
hadoop fs -put /Users/rindhujajohnson/local_file_path/steam_reviews.csv /user/steam_analysis
Apache Hadoop also uses a user interface available at http://localhost:9870/.
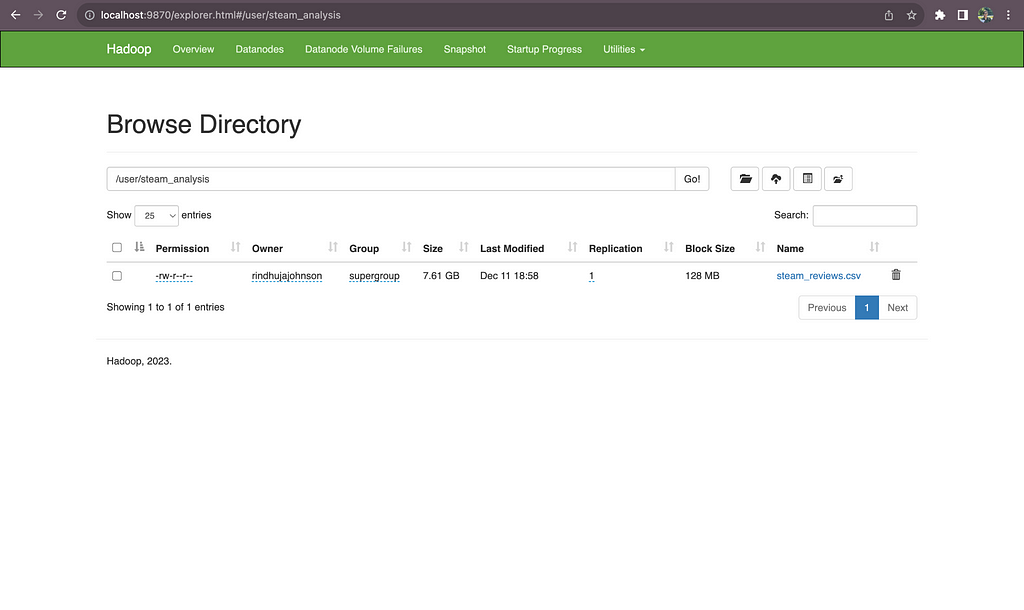
We can see the uploaded files as shown below.
Once the data interaction is over, we can use stop-all.sh command to stop all the Apache Hadoop daemons.
Let us move to the next step — Installing Apache Spark
2. Installing Apache Spark
Apache Hadoop takes care of data storage (HDFS) and parallel processing (MapReduce) of the data for faster execution. Apache Spark is a multi-language compatible analytical engine designed to deal with big data analysis. We will run the Apache Spark on Python in Jupyter IDE.
After installing and running HDFS, the installation of Apache Spark for Python is a piece of cake. PySpark is the Python API for Apache Spark that can be installed using the pip method in the Jupyter Notebook. PySpark is the Spark Core API with its four components — Spark SQL, Spark ML Library, Spark Streaming, and GraphX. Moreover, we can access the Hadoop files through PySpark by initializing the installation with the required Hadoop version.
# By default, the Hadoop version considered will be 3 here.
PYSPARK_HADOOP_VERSION=3 pip install pyspark
Let’s get started with the Big Data Analytics!
3. Steam Review Analysis using PySpark
Steam is an online gaming platform that hosts over 30,000 games streaming across the world with over 100 million players. Besides gaming, the platform allows the players to provide reviews for the games they play, a great resource for the platform to improve customer experience and for the gaming companies to work on to keep the players on edge. We used this review data provided by the platform publicly available on Kaggle.
3. a. Data Extraction from HDFS
We will use the PySpark library to access, clean, and analyze the data. To start, we connect the PySpark session to Hadoop using the local host address.
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
# Initializing the Spark Session
spark = SparkSession.builder.appName("SteamReviewAnalysis").master("yarn").getOrCreate()
# Providing the url for accessing the HDFS
data = "hdfs://localhost:9000/user/steam_analysis/steam_reviews.csv"
# Extracting the CSV data in the form of a Schema
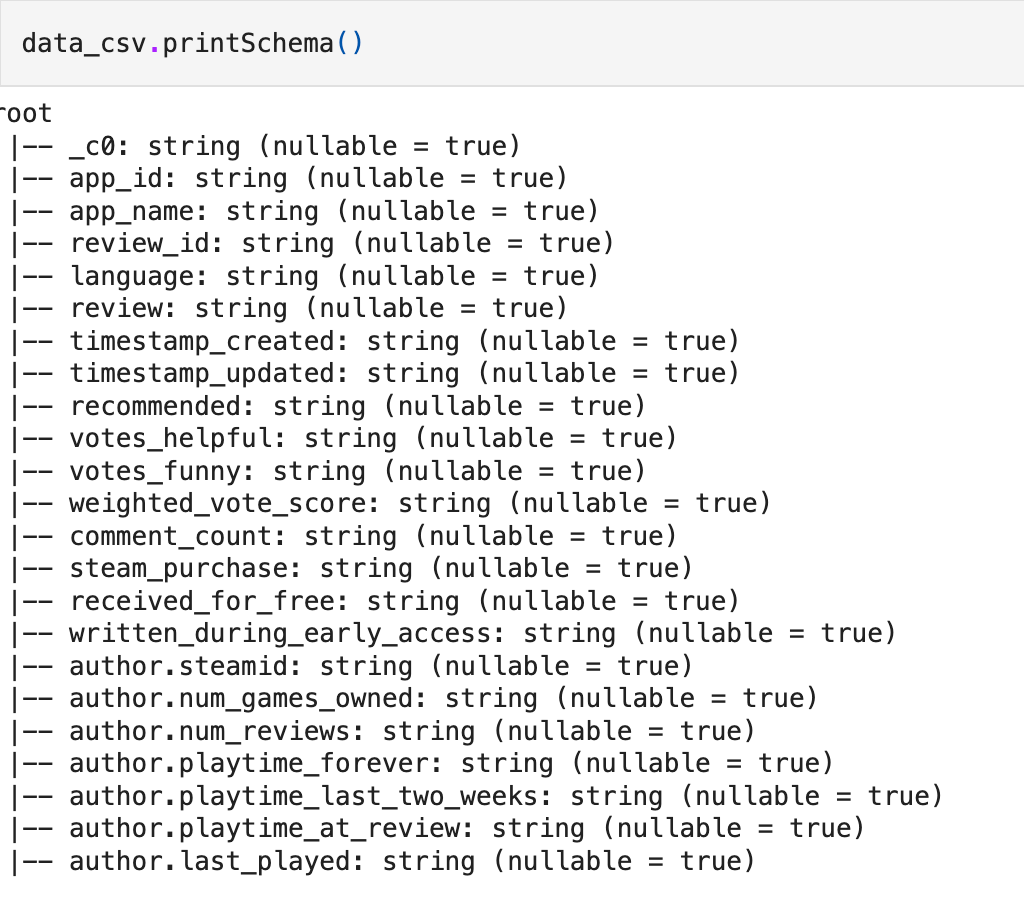
data_csv = spark.read.csv(data, inferSchema = True, header = True)
# Visualize the structure of the Schema
data_csv.printSchema()
# Counting the number of rows in the dataset
data_csv.count() # 40,848,659
3. b. Data Cleaning and Pre-Processing
We can start by taking a look at the dataset. Similar to the pandas.head() function in Pandas, PySpark has the SparkSession.show() function that gives a glimpse of the dataset.
Before that, we will remove the reviews column in the dataset as we do not plan on performing any NLP on the dataset. Also, the reviews are in different languages making any sentiment analysis based on the review difficult.
# Dropping the review column and saving the data into a new variable
data = data_csv.drop("review")
# Displaying the data
data.show()
We have a huge dataset with us with 23 attributes with NULL values for different attributes which does not make sense to consider any imputation. Therefore, I have removed the records with NULL values. However, this is not a recommended approach. You can evaluate the importance of the available attributes and remove the irrelevant ones, then try imputing data points to the NULL values.
# Drops all the records with NULL values
data = data.na.drop(how = "any")
# Count the number of records in the remaining dataset
data.count() # 16,876,852
We still have almost 17 million records in the dataset!
Now, we focus on the variable names of the dataset as in Figure 11. We can see that the attributes have a few characters like dot(.) that are unacceptable as Python identifiers. Also, we change the data type of the date and time attributes. So we change these using the following code —
from pyspark.sql.types import *
from pyspark.sql.functions import from_unixtime
# Changing the data type of each columns into appropriate types
data = data.withColumn("app_id",data["app_id"].cast(IntegerType())).
withColumn("author_steamid", data["author_steamid"].cast(LongType())).
withColumn("recommended", data["recommended"].cast(BooleanType())).
withColumn("steam_purchase", data["steam_purchase"].cast(BooleanType())).
withColumn("author_num_games_owned", data["author_num_games_owned"].cast(IntegerType())).
withColumn("author_num_reviews", data["author_num_reviews"].cast(IntegerType())).
withColumn("author_playtime_forever", data["author_playtime_forever"].cast(FloatType())).
withColumn("author_playtime_at_review", data["author_playtime_at_review"].cast(FloatType()))
# Converting the time columns into timestamp data type
data = data.withColumn("timestamp_created", from_unixtime("timestamp_created").cast("timestamp")).
withColumn("author_last_played", from_unixtime(data["author_last_played"]).cast(TimestampType())).
withColumn("timestamp_updated", from_unixtime(data["timestamp_updated"]).cast(TimestampType()))

The dataset is clean and ready for analysis!
3. c. Exploratory Data Analysis
The dataset is rich in information with over 20 variables. We can analyze the data from different perspectives. Therefore, we will be splitting the data into different PySpark data frames and caching them to run the analysis faster.
# Grouping the columns for each analysis
col_demo = ["app_id", "app_name", "review_id", "language", "author_steamid", "timestamp_created" ,"author_playtime_forever","recommended"]
col_author = ["steam_purchase", 'author_steamid', "author_num_games_owned", "author_num_reviews", "author_playtime_forever", "author_playtime_at_review", "author_last_played","recommended"]
col_time = [ "app_id", "app_name", "timestamp_created", "timestamp_updated", 'author_playtime_at_review', "recommended"]
col_rev = [ "app_id", "app_name", "language", "recommended"]
col_rec = ["app_id", "app_name", "recommended"]
# Creating new pyspark data frames using the grouped columns
data_demo = data.select(*col_demo)
data_author = data.select(*col_author)
data_time = data.select(*col_time)
data_rev = data.select(*col_rev)
data_rec = data.select(*col_rec)
i. Games Analysis
In this section, we will try to understand the review and recommendation patterns for different games. We will consider the number of reviews analogous to the popularity of the game and the number of True recommendations analogous to the gamer’s preference for the game.
- Finding the Most Popular Games
# the data frame is grouped by the game and the number of occurrences are counted
app_names = data_rec.groupBy("app_name").count()
# the data frame is ordered depending on the count for the highest 20 games
app_names_count = app_names.orderBy(app_names["count"].desc()).limit(20)
# a pandas data frame is created for plotting
app_counts = app_names_count.toPandas()
# A pie chart is created
fig = plt.figure(figsize = (10,5))
colors = sns.color_palette("muted")
explode = (0.1,0.075,0.05,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0)
plt.pie(x = app_counts["count"], labels = app_counts["app_name"], colors = colors, explode = explode, shadow = True)
plt.title("The Most Popular Games")
plt.show()
- Finding the Most Recommended Games
# Pick the 20 highest recommended games and convert it in to pandas data frame
true_counts = data_rec.filter(data_rec["recommended"] == "true").groupBy("app_name").count()
recommended = true_counts.orderBy(true_counts["count"].desc()).limit(20)
recommended_apps = recommended.toPandas()
# Pick the games such that both they are in both the popular and highly recommended list
true_apps = list(recommended_apps["app_name"])
true_app_counts = data_rec.filter(data_rec["app_name"].isin(true_apps)).groupBy("app_name").count()
true_app_counts = true_app_counts.orderBy(true_app_counts["count"].desc())
true_app_counts = true_app_counts.toPandas()
# Evaluate the percent of true recommendations for the top games and sort them
true_perc = []
for i in range(0,20,1):
percent = (true_app_counts["count"][i]-recommended_apps["count"][i])/true_app_counts["count"][i]*100
true_perc.append(percent)
recommended_apps["recommend_perc"] = true_perc
recommended_apps = recommended_apps.sort_values(by = "recommend_perc", ascending = False)
# Built a pie chart to visualize
fig = plt.figure(figsize = (10,5))
colors = sns.color_palette("muted")
explode = (0.1,0.075,0.05,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0)
plt.pie(x = recommended_apps["recommend_perc"], labels = recommended_apps["app_name"], colors = colors, explode = explode, shadow = True)
plt.title("The Most Recommended Games")
plt.show()
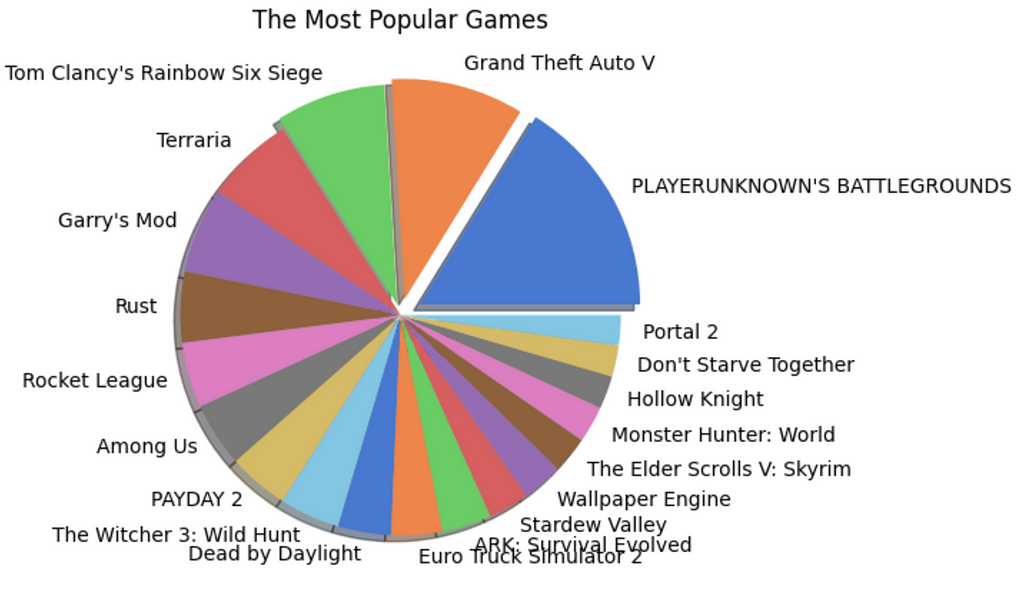
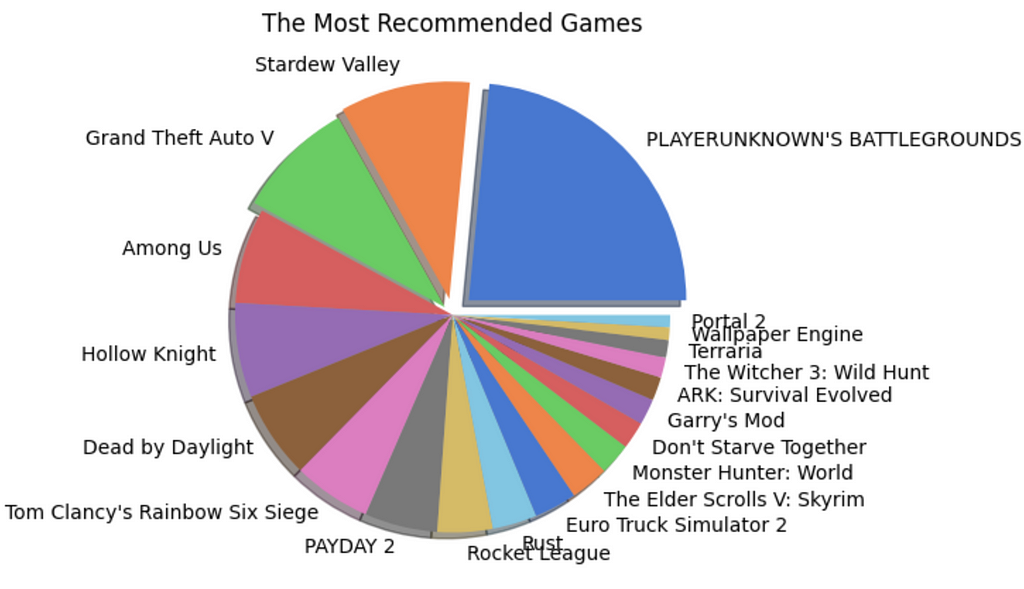
Insights
- Player Unknown’s Battlegrounds (PUBG) is the most popular and most recommended game of 2021.
- However, the second positions for the two categories are held by Grand Theft Auto V (GTA V) and Stardew Valley respectively. This shows that being popular does not mean all the players recommend the game to another player.
- The same pattern is observed with other games also. However, the number of reviews for a game significantly affects this trend.
ii. Demographic Analysis
We will find the demography, especially, the locality of the gamers using the data_demo data frame. This analysis will help us understand the popular languages used for review and languages used by reviewers of popular games. We can use this trend to determine the demographic influence and sentiments of the players to be used for recommending new games in the future.
- Finding Popular Review Languages
# We standardize the language names in the language column, then group them,
# Count by the groups and convert into pandas df after sorting them the count
author_lang = data_demo.select(lower("language").alias("language"))
.groupBy("language").count().orderBy(col("count").desc()).
limit(20).toPandas()
# Plotting a bar graph
fig = plt.figure(figsize = (10,5))
plt.bar(author_lang["language"], author_lang["count"])
plt.xticks(rotation = 90)
plt.xlabel("Popular Languages")
plt.ylabel("Number of Reviews (in Millions)")
plt.show()
- Finding Review Languages of Popular Games
# We group the data frame based on the game and language and count each occurrence
data_demo_new = data_demo.select(lower("language").
alias("language"), "app_name")
games_lang = data_demo_new.groupBy("app_name","language").count().orderBy(col("count").desc()).limit(100).toPandas()
# Plot a stacked bar graph to visualize
grouped_games_lang = games_lang_df.pivot(index='app_name', columns='language', values='count')
grouped_games_lang.plot(kind='bar', stacked=True, figsize=(12, 6))
plt.title('Count of Different App Names and Languages')
plt.xlabel('App Name')
plt.ylabel('Count')
plt.show()
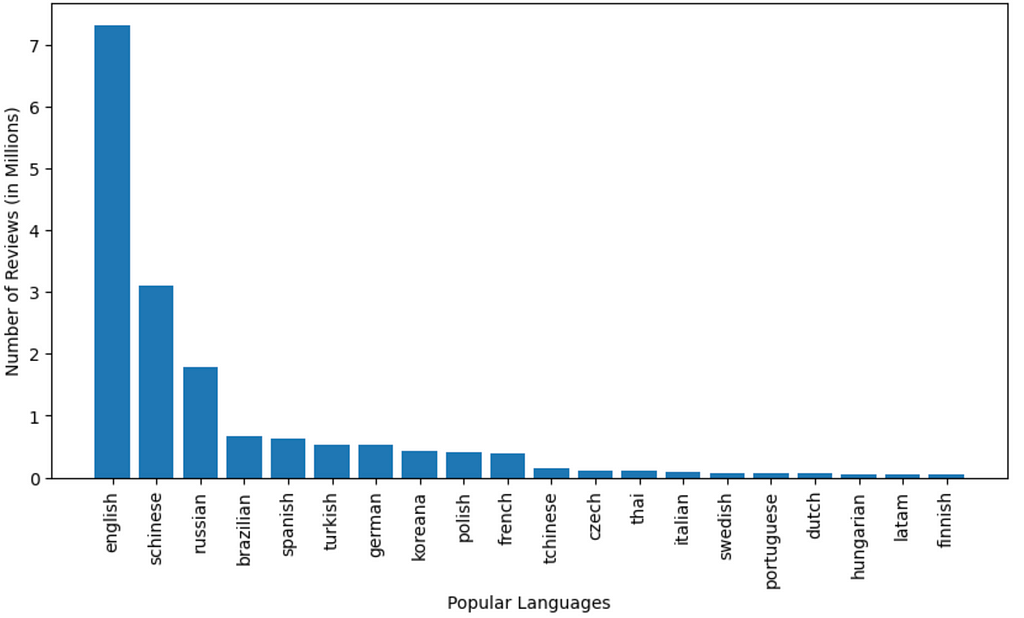
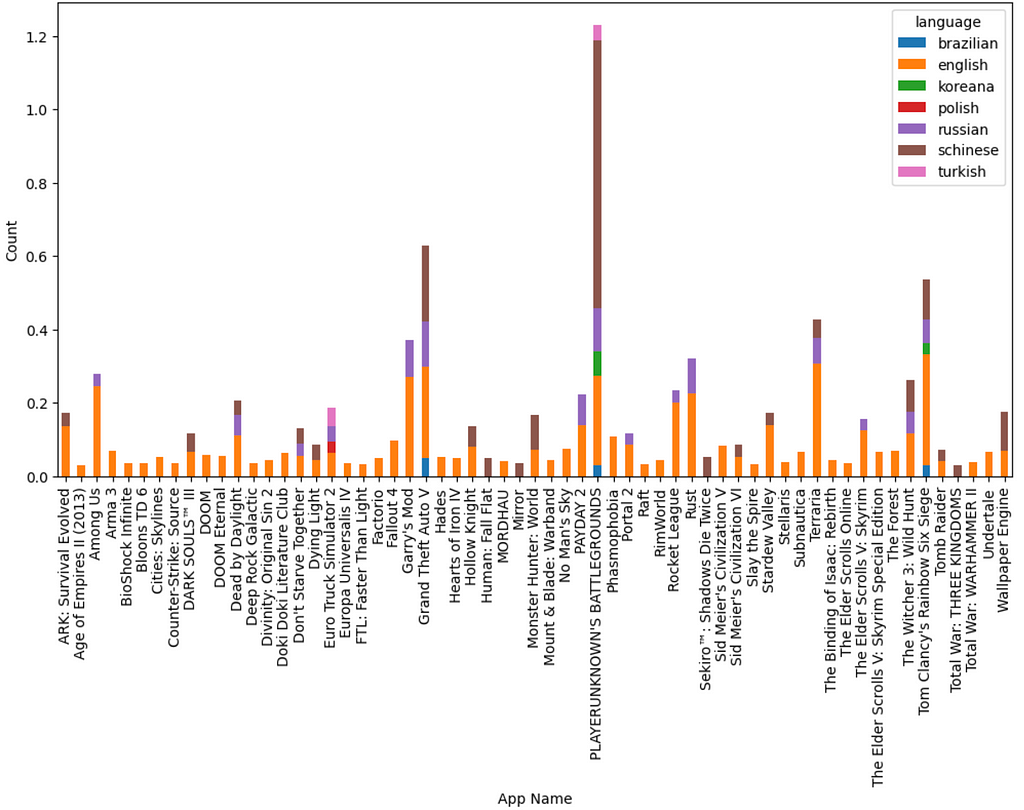
Insights
- English is the most popular language used by reviewers followed by Schinese and Russian
- Schinese is the most widely used language for the most popular game (PUBG), whereas, English is widely used for the second most popular game (GTA V) and almost all others!
- The popularity of a game seems to have roots in the area of origin. PUBG is a product of a South Korean gaming company and we observe that it has the Korean language among one of the highly used.
Time, author, and review analyses are also performed on this data, however, do not give any actionable insights. Feel free to visit the GitHub repository for the full project documentation.
3. d. Game Recommendation using Spark ML Library
We have reached the last stage of this project, where we will implement the Alternating Least Squares (ALS) machine-learning algorithm from the Spark ML Library. This model utilizes the collaborative filtering technique to recommend games based on player’s behavior, i.e., the games they played before. This algorithm identifies the game selection pattern for players who play each available game on the Steam App.
For the algorithm to work,
- We require three variables — the independent variable, target variable(s) — depending on the number of recommendations, here 5, and a rating variable.
- We encode the games and the authors to make the computation easier. We also convert the booleanrecommended column into a rating column with True = 5, and False = 1.
- Also, we will be recommending 5 new games for each played game and therefore we consider the data of the players who have played more than five for modeling the algorithm.
Let’s jump to the modeling and recommending part!
new_pair_games = data_demo.filter(col("author_playtime_forever")>=5*mean_playtime)
new_pair_games = new_pair_games.filter(new_pair_games["author_steamid"]>=76560000000000000).select("author_steamid","app_id", "app_name","recommended")
# Convert author_steamid and app_id to indices, and use the recommended column for rating
author_indexer = StringIndexer(inputCol="author_steamid", outputCol="author_index").fit(new_pair_games)
app_indexer = StringIndexer(inputCol="app_name", outputCol="app_index").fit(new_pair_games)
new_pair_games = new_pair_games.withColumn("Rating", when(col("recommended") == True, 5).otherwise(1))
# We apply the indexing to the data frame by invoking the reduce phase function transform()
new_pair = author_indexer.transform(app_indexer.transform(new_pair_games))
new_pair.show()
# The reference chart for games
games = new_pair.select("app_index","app_name").distinct().orderBy("app_index")

Implementing ALS Algorithm
# Create an ALS (Alternating Least Squares) model
als = ALS(maxIter=10, regParam=0.01, userCol="app_index", itemCol="author_index", ratingCol="Rating", coldStartStrategy="drop")
# Fit the model to the data
model = als.fit(new_pair)
# Generate recommendations for all items
app_recommendations = model.recommendForAllItems(5) # Number of recommendations per item
# Display the recommendations
app_recommendations.show(truncate=False)

We can cross-match the indices from Figure 16 to find the games recommended for each player. Thus, we implemented a basic recommendation system using the Spark Core ML Library.
3. e. Conclusion
In this project, we could successfully implement the following —
- Download and install the Hadoop ecosystem — HDFS and MapReduce — to store, access, and extract big data efficiently, and implement big data analytics much faster using a personal computer.
- Install the Apache Spark API for Python (PySpark) and integrate it with the Hadoop ecosystem, enabling us to carry out big data analytics and some machine-learning operations.
- The games and demographic analysis gave us some insights that can be used to improve the gaming experience and control the player churn. Keeping the players updated and informed about the trends in their peers should be a priority for the Steam platform. Suggestions like “most played”, “most played in your region”, “most recommended”, and “don’t miss out on these new games” can keep the players active.
- The Steam Application can use the ALS recommendation system to recommend new games to existing players based on their profile and keep them engaged and afresh.
4. What Next?
- Implement Natural Language Processing techniques in the review column, for different languages to extract the essence of the reviews and improve the gaming experience.
- Steam can report bugs in the games based on the reviews. Developing an AI algorithm that captures the review content, categorizes it, and sends it to appropriate personnel could do wonders for the platform.
- Comment what you think can be done more!
5. References
- Apache Hadoop. Apache Hadoop. Apache Hadoop
- Statista. (2021). Volume of data/information created, captured, copied, and consumed worldwide from 2010 to 2020, with forecasts from 2021 to 2025 statista
- Dey, R. (2023). A Beginner’s Guide to Big Data and Hadoop Distributed File System (HDFS). Medium
- Code with Arjun (2021). Install Hadoop on Mac OS (MacBook M1). Medium
- Apache Spark. PySpark Installation. Apache Spark
- Apache Spark. Collaborative Filtering with ALS). Apache Spark
- Let’s Uncover it. (2023). PUBG. Let’s Uncover It
You can find the complete big data analysis project in my GitHub repository.
Let’s connect on LinkedIn and discuss more!
If you found this article useful, clap, share, and comment!
Apache Hadoop and Apache Spark for Big Data Analysis was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Apache Hadoop and Apache Spark for Big Data Analysis
Go Here to Read this Fast! Apache Hadoop and Apache Spark for Big Data Analysis