Theory and practice of an underappreciated SQL operation

Introduction
The IT area is known for its constant changes, with new tools, new frameworks, new cloud providers, and new LLMs being created every day. However, even in this busy world, some principles, paradigms, and tools seem to challenge the status quo of ‘nothing is forever’. And, in the data area, there is no example of this as imposing as the SQL language.
Since its creation back in the 80s, it passed the age of Data Warehouses, materialized itself in the Hadoop/Data-lake/Big Data as Hive, and is still alive today as one of the Spark APIs. The world changed a lot but SQL remained not only alive but very important and present.
But SQL is like chess, easy to understand the basic rules but hard to master! It is a language with many possibilities, many ways to solve the same problem, many functions and keywords, and, unfortunately, many underrated functionalities that, if better known, could help us a lot when building queries.
Because of this, in this post, I want to talk about one of the not-so-famous SQL features that I found extremely useful when building my daily queries: Window Functions.
What is a Window Function
The traditional and most famous SGBDs (PostgreSQL, MySQL, and Oracle) are based on relational algebra concepts. In it, the lines are called tuples, and, the tables, are relations. A relation is a set (in the mathematical sense) of tuples, i.e. there is no ordering or connection between them. Because of that, there is no default ordering of lines in a table, and the calculus performed on one line does not impact and it is not impacted by the results of another. Even clauses like ORDER BY, only order tables, and it is not possible to make calculus in a line based on the values of other lines.
Simply put, window functions fix this, extending the SQL functionalities, and allowing us to perform calculations in one row based on the values of other lines.
Basic cases for understanding/ The Anatomy
1-Aggregating Without Aggregation
The most trivial example to understand Windows functions is the ability to ‘aggregate without aggregation’.
When we made an aggregation with traditional GROUP BY, the whole table is condensed into a second table, where each line represents a group’s element. With Windows Functions, instead of condensing the lines, it’s possible to create a new column in the same table containing the aggregation results.
For example, if you need to add up all the expenses in your expense table, traditionally you would do:
SELECT SUM(value) AS total FROM myTable
With Windows functions, you would make something like that:
SELECT *, SUM(value) OVER() FROM myTable
-- Note that the window function is defined at column-level
-- in the query
The image below shows the results:
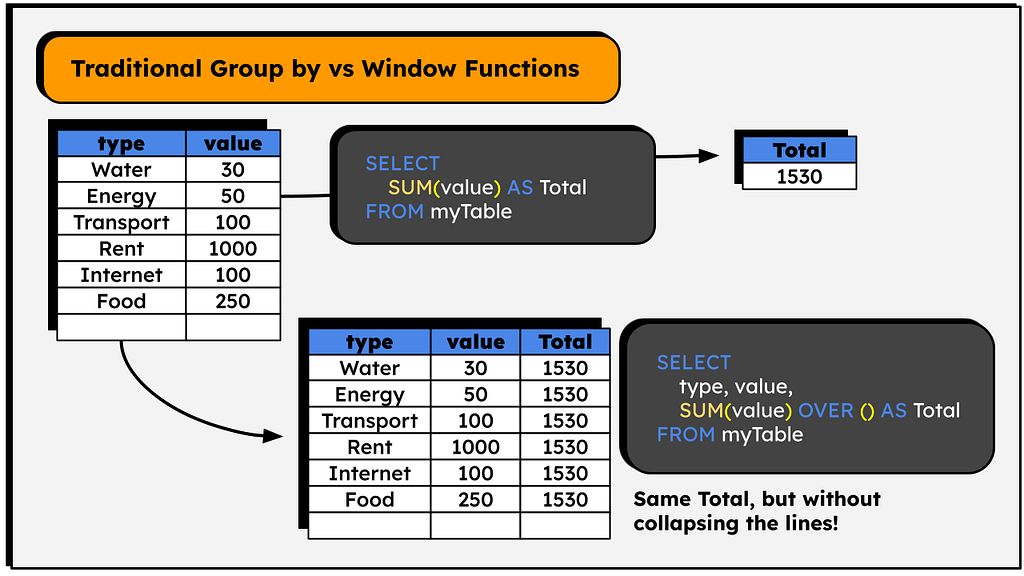
Rather than creating a new table, it will return the aggregation’s value in a new column. Note that the value is the same, but the table was not ‘summarized’, the original lines were maintained — we just calculated an aggregation without aggregating the table 😉
The OVER clause is the indication that we’re creating a window function. This clause defines over which lines the calculation will be made. It is empty in the code above, so it will calculate the SUM() over all the lines.
This is useful when we need to make calculations based on totals (or averages, minimums, maximums) of columns. For example, to calculate how much each expense contributes in percentage relative to the total.
In real cases, we might also want the detail by some category, like in the example in image 2, where we have company expenses by department. Again, we can achieve the total spent by each department with a simple GROUP BY:
SELECT depto, sum(value) FROM myTable GROUP BY depto
Or specify a PARTITION logic in the window function:
SELECT *, SUM(value) OVER(PARTITION BY depto) FROM myTable
See the result:
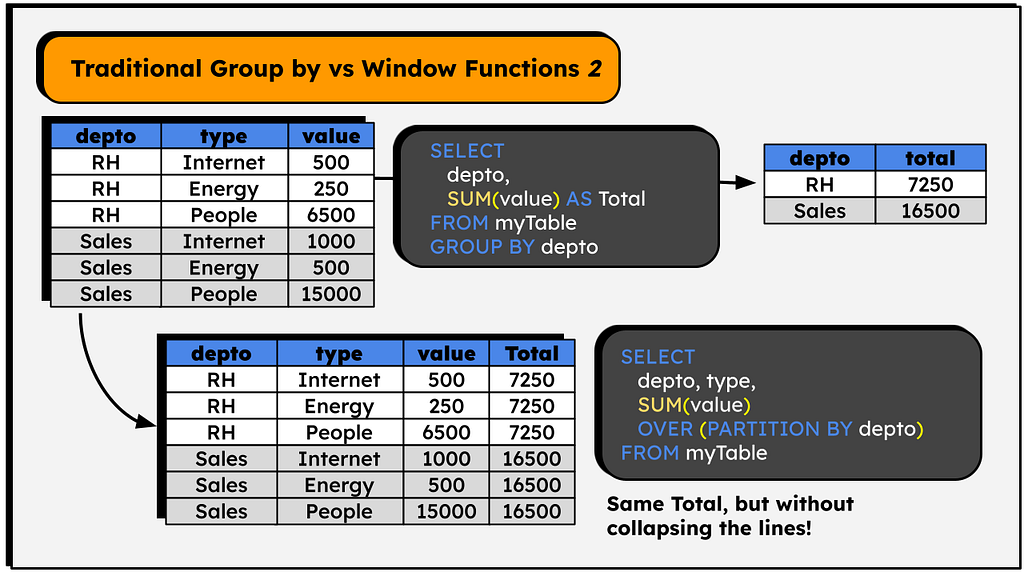
This example helps to understand why the operation is called a ‘window’ function — the OVER clause defines a set of lines over which the corresponding function will operate, a ‘window’ in the table.
In the case above, the SUM() function will operate in the partitions created by the depto column (RH and SALES) — it will sum all the values in the ‘value’ column for each item in the depto column in isolation. The group the line is part of (RH or SALES) determines the value in the ‘Total’ column.
2 — Time and Ordering awareness
Sometimes we need to calculate the value of a column in a row based on the values of other rows. A classic example is the yearly growth in a country’s GDP, computed using the current and the previous value.
Computations of this kind, where we need the value of the past year, the difference between the current and the next rows, the first value of a series, and so on are a testament to the Windows function’s power. In fact, I don’t know if this behavior could be achieved with standard SQL commands! It probably could, but would be a very complex query…
But windows functions made it straightforward, see the image below (table recording some child’s height):
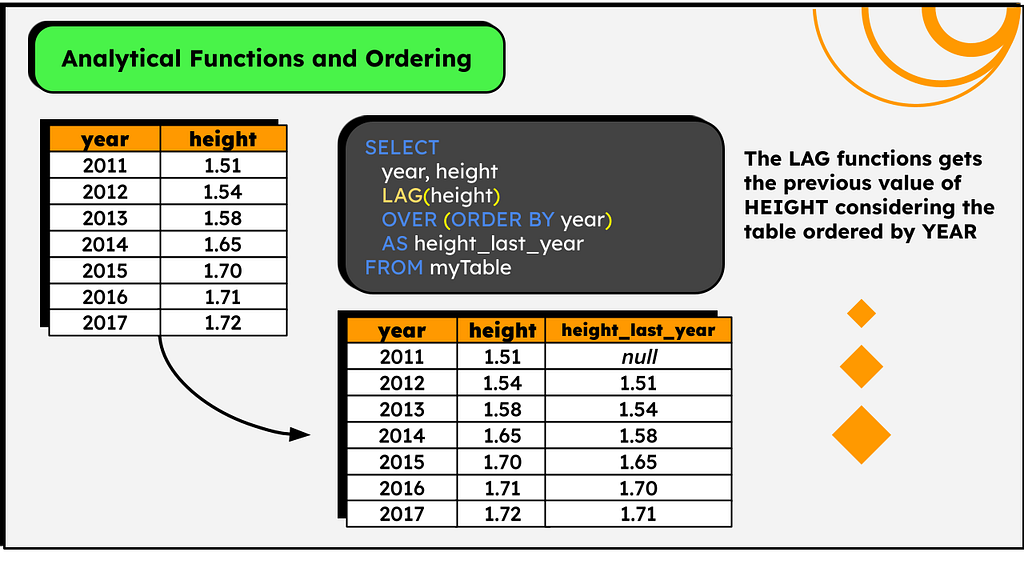
SELECT
year, height,
LAG(height) OVER (ORDER BY year) AS height_last_year
FROM myTable
The function LAG( ‘column’ ) is responsible for referencing the value of ‘column’ in the previous row. You can imagine it as a sequence of steps: In the second line, consider the value of the first; In the third, the value of the second; and so on… The first line doesn’t count (hence the NULL), as it has no predecessor.
Naturally, some ordering criterion is needed to define what the ‘previous line’ is. And that’s another important concept in Windows functions: analytical functions.
In contrast to traditional SQL functions, analytical functions (like LAG) consider that there exists an ordering in the lines — and this order is defined by the clause ORDER BY inside OVER(), i.e., the concept of first, second, third lines and so on is defined inside the OVER keyword. The main characteristic of these functions is the ability to reference other rows relative to the current row: LAG references the previous row, LEAD references the next rows, FIRST references the first row in the partition, and so on.
One nice thing about LAG and LEAD is that both accept a second argument, the offset, which specifies how many rows forward (for LEAD) or backward (for LAG) to look.
SELECT
LAG(height, 2) OVER (ORDER BY year) as height_two_years_ago,
LAG(height, 3) OVER (ORDER BY year) as height_three_years_ago,
LEAD(height) OVER (ORDER BY year) as height_next_year
FROM ...
And it is also perfectly possible to perform calculations with these functions:
SELECT
100*height/(LAG(height) OVER (ORDER BY year))
AS "annual_growth_%"
FROM ...
3 — Time Awareness and Aggregation
Time and space are only one — once said Einsteinm, or something like that, I don’t know ¯_(ツ)_/¯
Now that we know how to partition and order, we can use these two together! Going back to the previous example, let’s suppose there are more kids on that table and we need to compute the growth rate of each one. It’s very simple, just combine ordering and partitioning! Let’s order by year and partition by child name.
SELECT 1-height/LAG(height) OVER (ORDER BY year PARTITION BY name) ...

The above query does the following — Partitions the table by child and, in each partition, orders the values by year and divides the current year height value with the previous value (and subtracts the result from one).
We’re getting closer to the full concept of ‘window’! It’s a table slice, a set of rows grouped by the columns defined in PARTITION BY that are ordered by the fields in ORDER BY, where all the computations are made considering only the rows in the same group (partition) and a specific ordering.
4-Ranking and Position
Windows functions can be divided into three categories, two of which we already talked about: Aggregation functions ( COUNT, SUM, AVG, MAX, … ) and Analytical Functions ( LAG, LEAD, FIRST_VALUE, LAST_VALUE, … ).
The third group is the simplest — Ranking Functions, with its greatest exponent being the row_number() function, which returns an integer representing the position of a row in the group (based on the defined order).
SELECT row_number() OVER(ORDER BY score)
Ranking functions, as the name indicates, return values based on the position of the line in the group, defined by the ordering criteria. ROW_NUMBER, RANK, and NTILE are some of the most used.
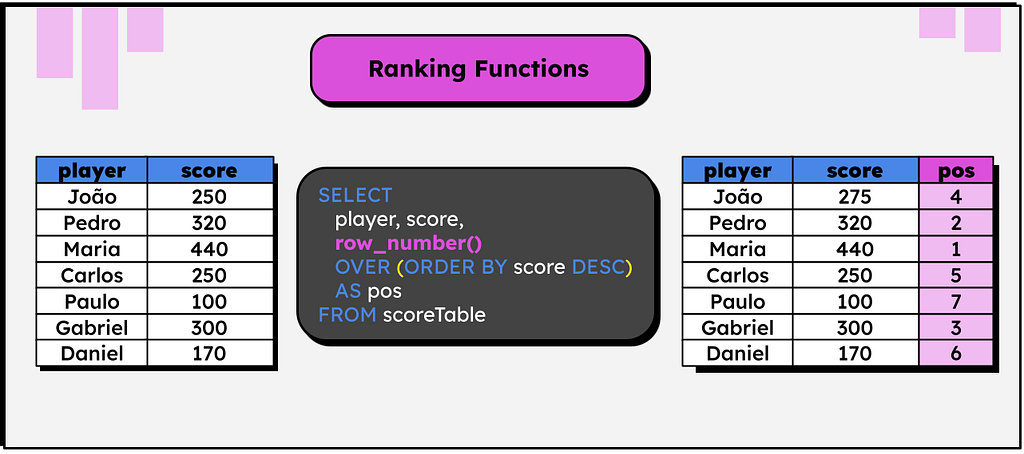
In the image above, a row number is created based on each player’s score
… and yes, it commits the atrocious programming sin of starting from 1.
5-Window size
All the functions presented till this point consider ALL the rows in the partition/group when computing the results. For example, the SUM() described in the first example considers all department’s rows to compute the total.
But it is possible to specify a smaller window size, i.e. how many lines before and after the current line should be considered in the computations. This is a helpful functionality to calculate moving averages / rolling windows.
Let’s consider the following example, with a table containing the daily number of cases of a certain disease, where we need to compute the average number of cases considering the current day and the two previous. Note that it’s possible to solve this problem with the LAG function, shown earlier:
SELECT
( n_cases + LAG(n_cases, 1) + LAG(n_cases, 2) )/3
OVER (ORDER BY date_reference)
But we can achieve the same result more elegantly using the concept of frames:
SELECT
AVG(n_cases)
OVER (
ORDER BY date_reference
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
)
The frame above specifies that we must calculate the average looking only for the two previous (PRECEDING) rows and the current row. If we desire to consider the previous, the current line, and the following line, we can change the frame:
AVG(n_cases)
OVER (
ORDER BY date_reference
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
)
And that’s all a frame is — a way to limit a function’s reach to a specific bound. By default (in most cases), windows functions consider the following frame:
ROWS BETWEEN UNBOUDED PRECEDING AND CURRENT ROW
-- ALL THE PREVIOUS ROWS + THE CURRENT ROW
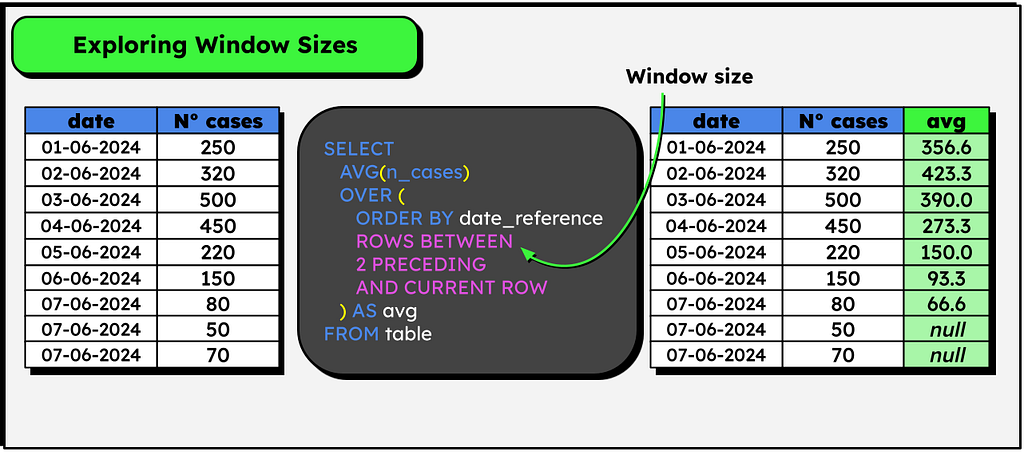
I hope this introduction helps you better understand what Windows functions are, how they work, and their syntax in practice. Naturally, many more keywords can be added to Windows functions, but I think this introduction already covers many commands you’ll likely use in everyday life. Now, let’s see some interesting practical applications that I use in my daily routine to solve problems — some are very curious!
Curious and Interesting use cases for windows functions
Cumulative Sum over time
This is one of the most classic cases of using windows functions.
Imagine a table with your salary per month and you want to know how much you earned in each month cumulatively (considering all previous months), this is how it works:

Pretty simple, right?
An interesting thing to note in this query is that the SUM() function considers the current row and all previous rows to calculate the aggregation, as mentioned previously.
Duration of events in log tables
I recently used this one in my post My First Billion (of Rows) in DuckDB, in which I manipulate logs from electronic voting machines in Brazil, it’s worth checking if you’re interested in the processing of large volumes of data.
In summary, imagine a log table in which each event is composed of a timestamp that indicates when it started, its name, and a unique identifier. Considering that each event only starts when the previous one ends, we can easily add a column with the event duration as follows:
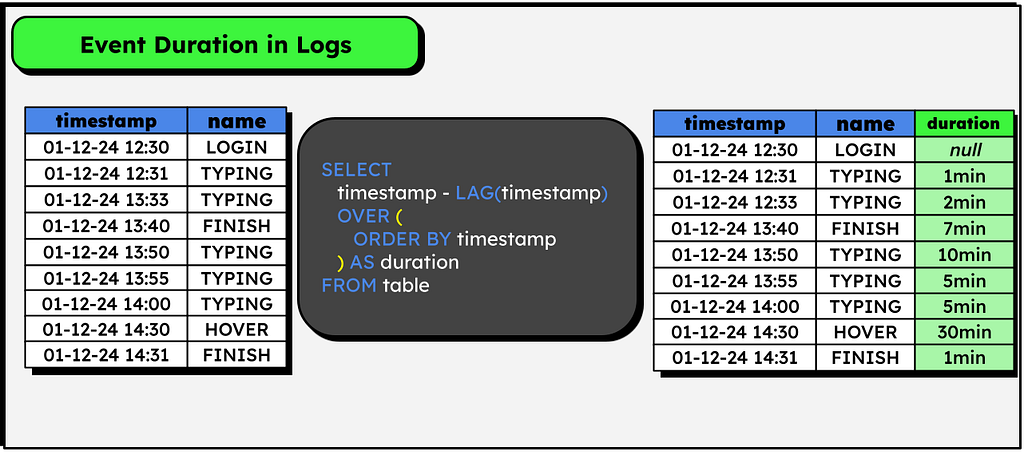
Fill missing values (With the last occurrence)
Machine learning classic with pandas! Just do a fillna, bfill or whatever, and that’s it, we fill in the null values with the last valid occurrence.
How to do this in SQL? Simple!
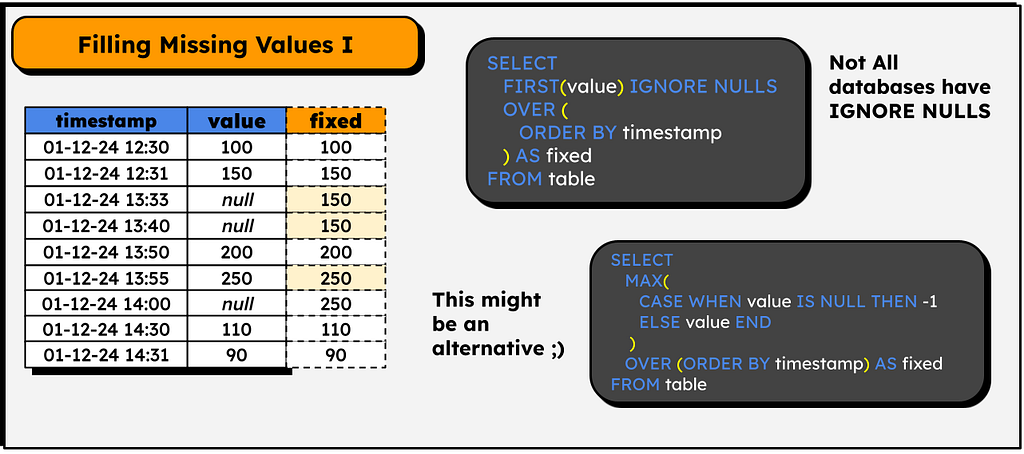
When we first study machine learning, we work a lot with pandas and get used to their high-level functions. However, when working on a real project, the data volume can be very large, so we may not be lucky enough to use pandas and need to switch to tools such as PySpark, Snowflake, Hive+hadoop, etc — all of which, in one way or another, can be operated in SQL. Therefore, I think it is important to learn how to do these treatments and preprocessing in SQL.
Filling missing values (With the avg of preceding rows)
A slightly more elaborate way of filling in null values, but still simple!
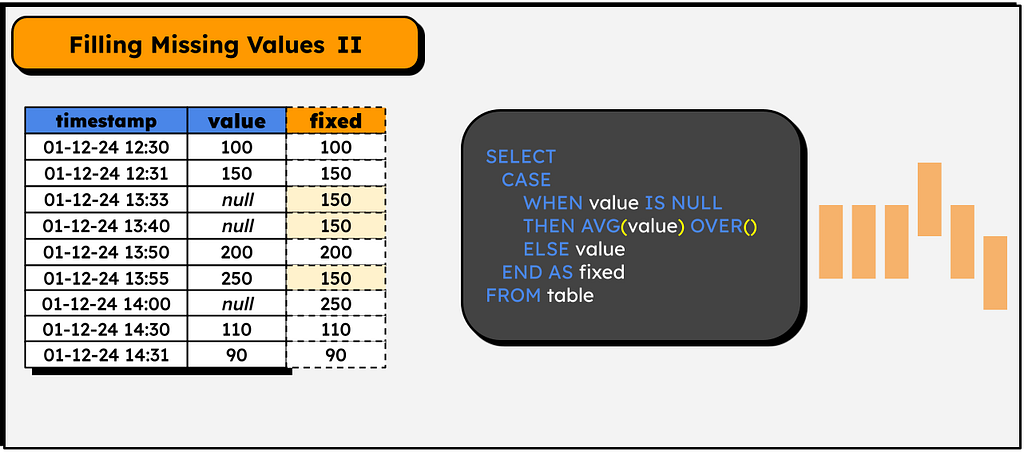
This example highlights that, despite seeming complicated and special, windows functions can be used just like normal columns! They can be included in CASE, calculations can be done with them and so on. One of the few restrictions I know of is that they cannot be placed directly in a WHERE clause:
SELECT * FROM
WHERE SUM() OVER() > 10 -- This is not possible in postgres
Row Deduplication based on a set of columns
Another classic of windows functions! Sometimes we need to deduplicate rows in a table based on just one set of columns.
Of course, in SQL we have the DISTINCT clause, but it only works if the full line is duplicated. If a table has several lines with the same value in an ID column but with different values in the remaining columns, it’s possible to deduplicate with the following logic:
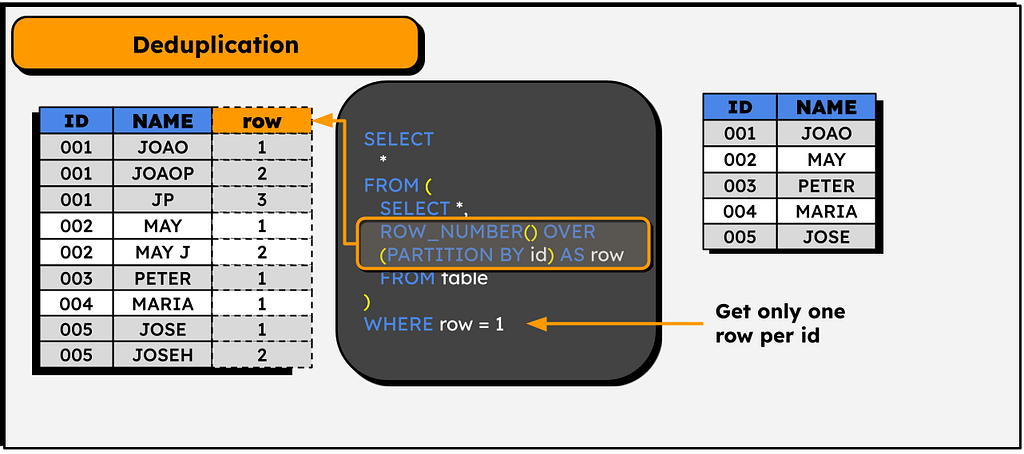
SELECT *
FROM (
SELECT
ROW_NUMBER() OVER (PARTITION BY id) as row_number
)
WHERE row_number = 1
This operation also allows data versioning! For example, if we save a new line for each time a user changed their name in the system with the date of change (instead of changing the existing line), we can retrieve each user’s current name:
SELECT
*
FROM
(
SELECT
name,
row_number() OVER (PARTITION BY id ORDER BY DATE DESC) AS row_number
FROM myTable
) AS subquery
WHERE row_number = 1
Percentage of occurrences of a group/class over the total number of rows
Consider a table that lists various pets, which can be dogs, cats, or birds. We need to add a column to each row indicating the percentage that each pet type represents out of the total count of all pets. This task is solved using not one, but two window functions!
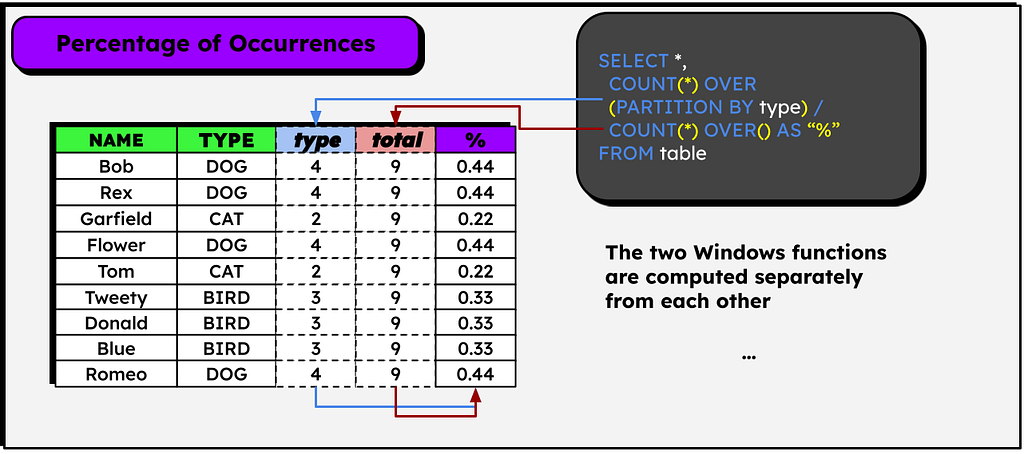
In the image above, to make it more educational, I added two columns to represent the result of each window function, but only the rightmost column is actually created.
And you, do you have any interesting windows functions cases that you would like to share? Please leave it in the comments!
Conclusion
I wouldn’t dare say that SQL is vintage or classic, as these, although positive, refer to the past. For me, SQL is present, pervasive, and, without a doubt, an essential language for anyone working in the data area.
However, several problems may seem complicated to solve using just SQL itself and, at these times, having a good knowledge of the language and its capabilities is really important. Without windows functions, many problems considered common — when looking from a Pythonic perspective — would be very difficult or even impossible to solve. But we can do magic if we know how to use the tools correctly!
I hope this post has helped you better understand how Windows functions work and what types of problems they can solve in practice. All the material presented here was mainly based on PostgreSQL syntax and may not necessarily work right away in another database, but the most important thing is the logic itself. As always, I’m not an expert on the subject and I strongly recommend deeper reading — and lots of practice — to anyone interested in the subject.
Thank you for reading! 😉
References
All the code is available in this GitHub repository.
Interested in more works like this one? Visit my posts repository.
[1] Data processing with PostgreSQL window functions. (n.d.). Timescale. Link.
[2] Kho, J. (2022, June 5). An easy guide to advanced SQL window functions — towards data science. Medium.
[3] Markingmyname. (2023, November 16). Funções analíticas (Transact-SQL) — SQL Server. Microsoft Learn.
[4] PostgreSQL Tutorial. (2021, April 27). PostgreSQL Window Functions: The Ultimate Guide. Link.
[5] VanMSFT. (2023, May 23). OVER Clause (Transact-SQL) — SQL Server. Microsoft Learn.
[6] Window Functions. (n.d.). SQLite Official docs.
[7] Window Functions. (2014, July 24). PostgreSQL Documentation.
All images in this post are made by the author.
Anatomy of Windows Functions was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Anatomy of Windows Functions