Simple techniques to alleviate LLM hallucinations using LangGraph

If you’ve worked with LLMs, you know they can sometimes hallucinate. This means they generate text that’s either nonsensical or contradicts the input data. It’s a common issue that can hurts the reliability of LLM-powered applications.
In this post, we’ll explore a few simple techniques to reduce the likelihood of hallucinations. By following these tips, you can (hopefully) improve the accuracy of your AI applications.
There are multiple types of hallucinations:
- Intrinsic hallucinations: the LLM’s response contradicts the user-provided context. This is when the response is verifiably wrong withing the current context.
- Extrinsic hallucinations: the LLM’s response cannot be verified using the user-provided context. This is when the response may or may not be wrong but we have no way of confirming that using the current context.
- Incoherent hallucinations: the LLM’s response does not answer the question or does not make sense. This is when the LLM is unable to follow the instructions.
In this post, we will target all the types mentioned above.
We will list out a set of tips and tricks that work in different ways in reducing hallucinations.
Tip 1: Use Grounding
Grounding is using in-domain relevant additional context in the input of the LLM when asking it to do a task. This gives the LLM the information it needs to correctly answer the question and reduces the likelihood of a hallucination. This is one the reason we use Retrieval augmented generation (RAG).
For example asking the LLM a math question OR asking it the same question while providing it with relevant sections of a math book will yield different results, with the second option being more likely to be right.
Here is an example of such implementation in one of my previous tutorials where I provide document-extracted context when asking a question:
Build a Document AI pipeline for ANY type of PDF With Gemini
Tip 2: Use structured outputs
Using structured outputs means forcing the LLM to output valid JSON or YAML text. This will allow you to reduce the useless ramblings and get “straight-to-the-point” answers about what you need from the LLM. It also will help with the next tips as it makes the LLM responses easier to verify.
Here is how you can do this with Gemini’s API:
import json
import google.generativeai as genai
from pydantic import BaseModel, Field
from document_ai_agents.schema_utils import prepare_schema_for_gemini
class Answer(BaseModel):
answer: str = Field(..., description="Your Answer.")
model = genai.GenerativeModel("gemini-1.5-flash-002")
answer_schema = prepare_schema_for_gemini(Answer)
question = "List all the reasons why LLM hallucinate"
context = (
"LLM hallucination refers to the phenomenon where large language models generate plausible-sounding but"
" factually incorrect or nonsensical information. This can occur due to various factors, including biases"
" in the training data, the inherent limitations of the model's understanding of the real world, and the "
"model's tendency to prioritize fluency and coherence over accuracy."
)
messages = (
[context]
+ [
f"Answer this question: {question}",
]
+ [
f"Use this schema for your answer: {answer_schema}",
]
)
response = model.generate_content(
messages,
generation_config={
"response_mime_type": "application/json",
"response_schema": answer_schema,
"temperature": 0.0,
},
)
response = Answer(**json.loads(response.text))
print(f"{response.answer=}")
Where “prepare_schema_for_gemini” is a utility function that prepares the schema to match Gemini’s weird requirements. You can find its definition here: code.
This code defines a Pydantic schema and sends this schema as part of the query in the field “response_schema”. This forces the LLM to follow this schema in its response and makes it easier to parse its output.
Tip 3: Use chain of thoughts and better prompting
Sometimes, giving the LLM the space to work out its response, before committing to a final answer, can help produce better quality responses. This technique is called Chain-of-thoughts and is widely used as it is effective and very easy to implement.
We can also explicitly ask the LLM to answer with “N/A” if it can’t find enough context to produce a quality response. This will give it an easy way out instead of trying to respond to questions it has no answer to.
For example, lets look into this simple question and context:
Context
Thomas Jefferson (April 13 [O.S. April 2], 1743 — July 4, 1826) was an American statesman, planter, diplomat, lawyer, architect, philosopher, and Founding Father who served as the third president of the United States from 1801 to 1809.[6] He was the primary author of the Declaration of Independence. Following the American Revolutionary War and before becoming president in 1801, Jefferson was the nation’s first U.S. secretary of state under George Washington and then the nation’s second vice president under John Adams. Jefferson was a leading proponent of democracy, republicanism, and natural rights, and he produced formative documents and decisions at the state, national, and international levels. (Source: Wikipedia)
Question
What year did davis jefferson die?
A naive approach yields:
Response
answer=’1826′
Which is obviously false as Jefferson Davis is not even mentioned in the context at all. It was Thomas Jefferson that died in 1826.
If we change the schema of the response to use chain-of-thoughts to:
class AnswerChainOfThoughts(BaseModel):
rationale: str = Field(
...,
description="Justification of your answer.",
)
answer: str = Field(
..., description="Your Answer. Answer with 'N/A' if answer is not found"
)
We are also adding more details about what we expect as output when the question is not answerable using the context “Answer with ‘N/A’ if answer is not found”
With this new approach, we get the following rationale (remember, chain-of-thought):
The provided text discusses Thomas Jefferson, not Jefferson Davis. No information about the death of Jefferson Davis is included.
And the final answer:
answer=’N/A’
Great ! But can we use a more general approach to hallucination detection?
We can, with Agents!
Tip 4: Use an Agentic approach
We will build a simple agent that implements a three-step process:
- The first step is to include the context and ask the question to the LLM in order to get the first candidate response and the relevant context that it had used for its answer.
- The second step is to reformulate the question and the first candidate response as a declarative statement.
- The third step is to ask the LLM to verify whether or not the relevant context entails the candidate response. It is called “Self-verification”: https://arxiv.org/pdf/2212.09561
In order to implement this, we define three nodes in LangGraph. The first node will ask the question while including the context, the second node will reformulate it using the LLM and the third node will check the entailment of the statement in relation to the input context.
The first node can be defined as follows:
def answer_question(self, state: DocumentQAState):
logger.info(f"Responding to question '{state.question}'")
assert (
state.pages_as_base64_jpeg_images or state.pages_as_text
), "Input text or images"
messages = (
[
{"mime_type": "image/jpeg", "data": base64_jpeg}
for base64_jpeg in state.pages_as_base64_jpeg_images
]
+ state.pages_as_text
+ [
f"Answer this question: {state.question}",
]
+ [
f"Use this schema for your answer: {self.answer_cot_schema}",
]
)
response = self.model.generate_content(
messages,
generation_config={
"response_mime_type": "application/json",
"response_schema": self.answer_cot_schema,
"temperature": 0.0,
},
)
answer_cot = AnswerChainOfThoughts(**json.loads(response.text))
return {"answer_cot": answer_cot}
And the second one as:
def reformulate_answer(self, state: DocumentQAState):
logger.info("Reformulating answer")
if state.answer_cot.answer == "N/A":
return
messages = [
{
"role": "user",
"parts": [
{
"text": "Reformulate this question and its answer as a single assertion."
},
{"text": f"Question: {state.question}"},
{"text": f"Answer: {state.answer_cot.answer}"},
]
+ [
{
"text": f"Use this schema for your answer: {self.declarative_answer_schema}"
}
],
}
]
response = self.model.generate_content(
messages,
generation_config={
"response_mime_type": "application/json",
"response_schema": self.declarative_answer_schema,
"temperature": 0.0,
},
)
answer_reformulation = AnswerReformulation(**json.loads(response.text))
return {"answer_reformulation": answer_reformulation}
The third one as:
def verify_answer(self, state: DocumentQAState):
logger.info(f"Verifying answer '{state.answer_cot.answer}'")
if state.answer_cot.answer == "N/A":
return
messages = [
{
"role": "user",
"parts": [
{
"text": "Analyse the following context and the assertion and decide whether the context "
"entails the assertion or not."
},
{"text": f"Context: {state.answer_cot.relevant_context}"},
{
"text": f"Assertion: {state.answer_reformulation.declarative_answer}"
},
{
"text": f"Use this schema for your answer: {self.verification_cot_schema}. Be Factual."
},
],
}
]
response = self.model.generate_content(
messages,
generation_config={
"response_mime_type": "application/json",
"response_schema": self.verification_cot_schema,
"temperature": 0.0,
},
)
verification_cot = VerificationChainOfThoughts(**json.loads(response.text))
return {"verification_cot": verification_cot}
Full code in https://github.com/CVxTz/document_ai_agents
Notice how each node uses its own schema for structured output and its own prompt. This is possible due to the flexibility of both Gemini’s API and LangGraph.
Lets work through this code using the same example as above ➡️
(Note: we are not using chain-of-thought on the first prompt so that the verification gets triggered for our tests.)
Context
Thomas Jefferson (April 13 [O.S. April 2], 1743 — July 4, 1826) was an American statesman, planter, diplomat, lawyer, architect, philosopher, and Founding Father who served as the third president of the United States from 1801 to 1809.[6] He was the primary author of the Declaration of Independence. Following the American Revolutionary War and before becoming president in 1801, Jefferson was the nation’s first U.S. secretary of state under George Washington and then the nation’s second vice president under John Adams. Jefferson was a leading proponent of democracy, republicanism, and natural rights, and he produced formative documents and decisions at the state, national, and international levels. (Source: Wikipedia)
Question
What year did davis jefferson die?
First node result (First answer):
relevant_context=’Thomas Jefferson (April 13 [O.S. April 2], 1743 — July 4, 1826) was an American statesman, planter, diplomat, lawyer, architect, philosopher, and Founding Father who served as the third president of the United States from 1801 to 1809.’
answer=’1826′
Second node result (Answer Reformulation):
declarative_answer=’Davis Jefferson died in 1826′
Third node result (Verification):
rationale=’The context states that Thomas Jefferson died in 1826. The assertion states that Davis Jefferson died in 1826. The context does not mention Davis Jefferson, only Thomas Jefferson.’
entailment=’No’
So the verification step rejected (No entailment between the two) the initial answer. We can now avoid returning a hallucination to the user.
Bonus Tip : Use stronger models
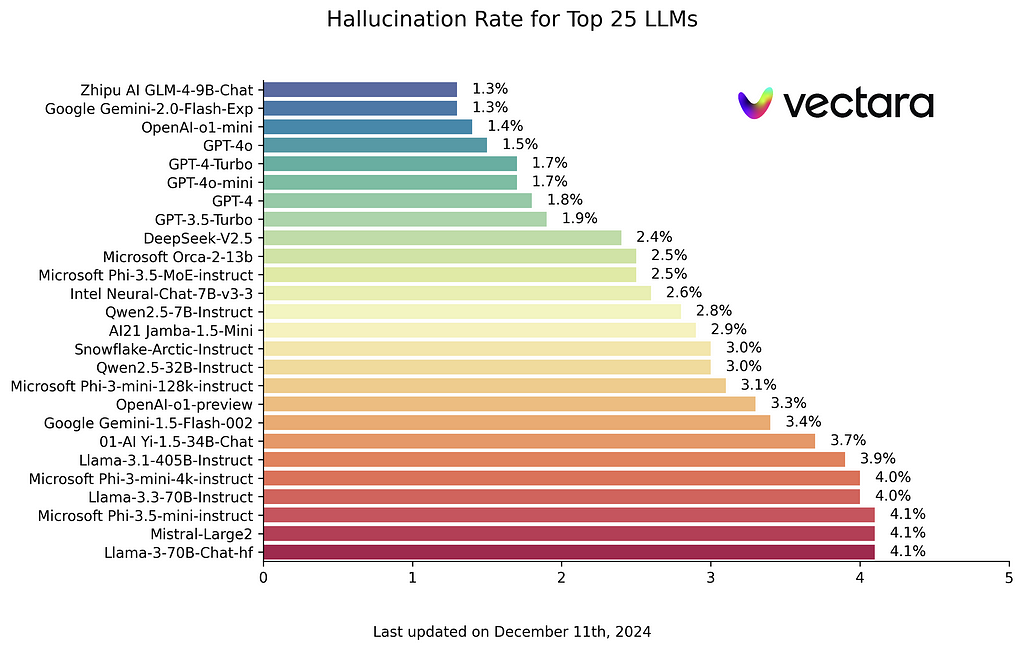
This tip is not always easy to apply due to budget or latency limitations but you should know that stronger LLMs are less prone to hallucination. So, if possible, go for a more powerful LLM for your most sensitive use cases. You can check a benchmark of hallucinations here: https://github.com/vectara/hallucination-leaderboard. We can see that the top models in this benchmark (least hallucinations) also ranks at the top of conventional NLP leader boards.
Conclusion
In this tutorial, we explored strategies to improve the reliability of LLM outputs by reducing the hallucination rate. The main recommendations include careful formatting and prompting to guide LLM calls and using a workflow based approach where Agents are designed to verify their own answers.
This involves multiple steps:
- Retrieving the exact context elements used by the LLM to generate the answer.
- Reformulating the answer for easier verification (In declarative form).
- Instructing the LLM to check for consistency between the context and the reformulated answer.
While all these tips can significantly improve accuracy, you should remember that no method is foolproof. There’s always a risk of rejecting valid answers if the LLM is overly conservative during verification or missing real hallucination cases. Therefore, rigorous evaluation of your specific LLM workflows is still essential.
Full code in https://github.com/CVxTz/document_ai_agents
An Agentic Approach to Reducing LLM Hallucinations was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
An Agentic Approach to Reducing LLM Hallucinations
Go Here to Read this Fast! An Agentic Approach to Reducing LLM Hallucinations