

How the Bud Light boycott and SalesForce’s innovation plans confuse the best LLMs
Can the best AI models today, accurately pick up the most important message out of a company earnings call? They can certainly pick up SOME points but how do we know if those are the important ones? Can we prompt them into to doing a better job? To find those answers, we look at what the best journalists in the field have done and try to get as close to that with AI
The Challenge
In this article, I look at 8 recent company earnings calls and ask the current contestants for smartest AIs (Claude 3, GPT-4 and Mistral Large) what they think is important. Then compare the results to what some of the best names in Journalism (Reuters, Bloomberg, and Barron’s) have said about those exact reports.
Why care about this?
The Significance of Earnings Calls
Earnings calls are quarterly events where senior management reviews the company’s financial results. They discuss the company’s performance, share commentary, and sometimes preview future plans. These discussions can significantly impact the company’s stock price. Management explains their future expectations and reasons for meeting or surpassing past forecasts. The management team offers invaluable insights into the company’s actual condition and future direction.
The Power of Automation in Earnings Analysis
Statista reports that there are just under 4000 companies listed on the NASDAQ and about 58,000 globally according to one estimate.
A typical conference call lasts roughly 1 hour. To just listen to all NASDAQ companies, one would need at least 10 people working full-time for the entire quarter. And this doesn’t even include the more time-consuming tasks like analyzing and comparing financial reports.
Large brokerages might manage this workload, but it’s unrealistic for individual investors. Automation in this area could level the playing field, making it easier for everyone to understand quarterly earnings.
While this may just be within reach of large brokerages, it is not feasible for private investors. Therefore, any reliable automation in this space will be a boon, especially for democratizing the understanding of quarterly earnings.
The Process of Testing AI as a Financial Analyst
To test how well the best LLMs of the day can do this job. I decided to compare the main takeaways by humans and see how well AI can mimic that. Here are the steps:
- Pick some companies with recent earnings call transcripts and matching news articles.
- Provide the LLMs with the full transcript as context and ask them to provide the top three bullet points that seem most impactful for the value of the company. This is important as, providing a longer summary becomes progressively easier — there are only so many important things to say.
- To ensure we maximise the quality of the output, I vary the way I phrase the problem to the AI (using different prompts): Ranging from simply asking for a summary, adding more detailed instructions, adding previous transcripts and some combinations of those.
- Finally, compare those with the 3 most important points from the respective news article and use the overlap as a measure of success.
Summary of Results
GPT-4 shows best performance at 80% when providing it the previous quarter’s transcript and using a set of instructions on how to analyse transcripts well (Chain of Thought). Notably, just using correct instructions increases GPT-4 performance from 51% to 75%.
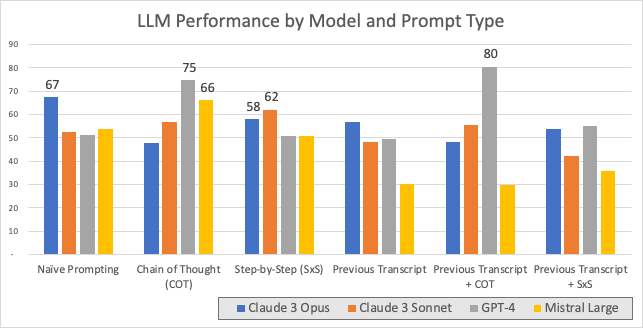
- Next best performers are:
— Claude 3 Opus (67%) — Without sophisticated prompting, Claude 3 Opus works best.
— Mistral Large (66%) when adding supporting instructions (i.e. Chain of Thought) - Chain-of-thought (CoT) and Think Step by Step (SxS) seem to work well for GPT-4 but are detrimental for other models. This suggests there is still a lot to be learned about what prompts work for each LLM.
- Chain-of-Thought (CoT) seems almost always outperforms Step-by-step (SxS). This means tailored financial knowledge of priorities for analysis helps. The specific instructions provided are listed at the bottom of the article.
- More data-less sense: Adding a previous period transcript to the model context seems to be at least slightly and at worst significantly detrimental to results across the board than just focusing on the latest results (except for GPT-4 + CoT). Potentially, there is much irrelevant information introduced from a previous transcript and a relatively small amount of specific facts to make a quarter-on-quarter comparison. Mistral Large’s performance drops significantly, note that its context window is just 32k tokens vs the significantly larger ones for the others (2 transcripts + prompt actually just barely fit under 32k tokens).
- Claude-3 Opus and Sonnet perform very closely, with Sonnet actually outperforming Opus in some cases. However, this tends to be by a few %-age points and can therefore be attributed to the randomness of results.
- Note that, as mentioned, results show a high degree of variability and the range of outcomes is within +/-6%. For that reason, I have rerun all analysis 3 times and am showing the averages. However, the +/-6% range is not sufficient to significantly upend any of the above conclusions
What do LLMs get right and wrong?
How the Bud Light Boycott and Salesforce’s AI plans confused the best AIs
This task offers some easy wins: guessing that results are about the latest revenue numbers and next year’s projections is fairly on the nose. Unsurprisingly, this is where models get things right most of the time.
The table below gives an overview of what was mentioned in the news and what LLMs chose differently when summarized in just a few words.
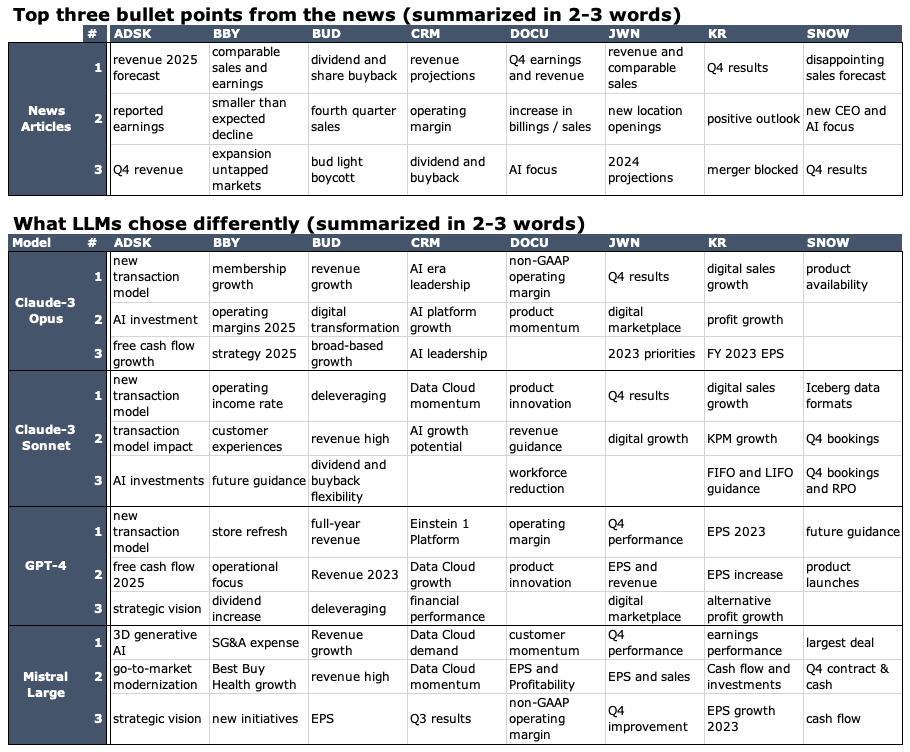
Next, I tried to look for any trends of what the models consistently miss. Those generally Fall into a few categories:
- Making sense of changes: In the above results, LLMs have been able to understand fairly reliably what to look for: earnings, sales, dividend, and guidance, however, making sense of what is significant is still very elusive. For instance, common-sense might suggest that Q4 2023 results will be a key topic for any company and this is what the LLMs pick. However, Nordstrom talks about muted revenue and demand expectations for 2024 which pushes Q4 2023 results aside in terms of importance
- Hallucinations: as is well documented, LLMs tend to make up facts. In this case, despite having instructions to “only include facts and metrics from the context” some metrics and dates end up being made up. The models unfortunately will not be shy about talking about the Q4 2024 earnings by referring to them as already available and using the 2023 numbers for them.
- Significant one-off events: Unexpected one-off events are surprisingly often missed by LLMs. For instance, the boycott of Bud Light drove sales of the best-selling beer in the US down by 15.9% for Anheuser-Busch and is discussed at length in the transcripts. The number alone should appear significant, however it was missed by all models in the sample.
- Actions speak louder than words: Both GPT and Claude highlight innovation and the commitment to AI as important.
— Salesforce (CRM) talks at length about a heavy focus on AI and Data Cloud
— Snowflake appointed their SVP of AI and former exec of Google Ads as CEO (Sridhar Ramaswamy), similarly signaling a focus on leveraging AI technology.
Both signal a shift to innovation & AI. However, journalists and analysts are not as easily tricked into mistaking words for actions. In the article analyzing CRM’s earnings, the subtitle reads Salesforce Outlook Disappoints as AI Fails to Spark Growth. However, Salesforce has been trying to tango with AI for a while and the forward-looking plans to use AI are not even mentioned. Salesforce’s transcript mentions AI 91 times while Snowflake’s less than half of that at 39. However, humans can make the distinction in meaning: Bloomberg’s article [link] on the appointment of a new CEO: His elevation underscores a focus on AI for Snowflake.
Experiment design and choices
- Why Earnings call transcripts? The more intuitive choice may be company filings, however, I find transcripts to present a more natural and less formal discussion of events. I believe transcripts give the LLM as a reasoning engine a better chance to glean more natural commentary of events as opposed to the dry and highly regulated commentary of earnings. The calls are mostly management presentations, which might skew things toward a more positive view. However, my analysis has shown the performance of the LLMs seems similar between positive and negative narratives.
- Choice of Companies: I chose stocks that have published Q4 2023 earnings reports between 25 Feb and 5 March and have been reported on by one of Reuters, Bloomberg, or Barron’s. This ensures that the results are timely and that the models have not been trained on that data yet. Plus, everyone always talks about AAPL and TSLA, so this is something different. Finally, the reputation of these journalistic houses ensures a meaningful comparison. The 8 stocks we ended up with are: Autodesk (ADSK), BestBuy (BBY), Anheuser-Busch InBev (BUD), Salesforce (CRM), DocuSign (DOCU), Nordstrom (JWN), Kroger (KR), Snowflake (SNOW)
- Variability of results LLM results can vary between runs so I have run all experiments 3 times and show an average. All analysis for all models was done using temperature 0 which is commonly used to minimize variation of results. In this case, I have observed different runs have as much as 10% difference in performance. This is due to the small sample (only 24 data points 8 stocks by 3 statements) and the fact that we are basically asking an LLM to choose one of many possible statements for the summary, so when this happens with some randomness it can naturally lead to picking some of them differently.
- Choice of Prompts: For each of the 3 LLMs in comparison try out 4 different prompting approaches:
- Naive — The prompt simply asks the model to determine the most likely impact on the share price.
- Chain-of-Thought (CoT) — where I provide a detailed list of steps to follow when choosing a summary. This is inspired and loosely follows [Wei et. al. 2022] work outlining the Chain of Thought approach, providing reasoning steps as part of the prompt dramatically improves results. These additional instructions, in the context of this experiment, include typical drivers of price movements: changes to expected performance in revenue, costs, earnings, litigation, etc.
- Step by Step (SxS) aka Zero-shot CoT, inspired by Kojima et.al (2022) where they discovered that simply adding the phrase “Let’s think step by step” improves performance. I ask the LLMs to think step-by-step and describe their logic before answering.
- Previous transcript — finally, I run all three of the above prompts once more by including the transcript from the previous quarter (in this case Q3)
Conclusion
From what we can see above, Journalists’ and Research Analysts’ jobs seem safe for now, as most LLMs struggle to get more than two of three answers correctly. In most cases, this just means guessing that the meeting was about the latest revenue and next year’s projections.
However, despite all the limitations of this test, we can still see some clear conclusions:
- The accuracy level is fairly low for most models. Even GPT-4’s best performance of 80% will be problematic at scale without human supervision — giving wrong advice one in five times is not convincing.
- GPT4 seems to still be a clear leader in complex tasks it was not specifically trained for.
- There are significant gains when correctly prompt engineering the task
- Most models seem easily confused by extra information as adding the previous transcript generally reduces performance.
Where to from here?
We have all witnessed that LLM capabilities continuously improve. Will this gap be closed and how? We have observed three types of cognitive issues that have impacted performance: hallucinations, understanding what is important and what isn’t (e.g. really understanding what is surprising for a company), more complex company causality issues (e.g. like the Bud Light boycott and how important the US sales are relative to an overall business):
- Hallucinations or scenarios where the LLM cannot correctly reproduce factual information are a major stumbling block in applications that require strict adherence to factuality. Advanced RAG approaches, combined with research in the area continue to make progress, [Huang et al 2023] give an overview of current progress
- Understanding what is important — fine-tuning LLM models for the specific use case should lead to some improvements. However, those come with much bigger requirements on team, cost, data, and infrastructure.
- Complex Causality Links — this one may be a good direction for AI Agents. For instance, in the Bud Light boycott case, the model might need to:
1. the importance of Bud Light to US sales, which is likely peppered through many presentations and management commentary
2. The importance of US sales ot the overall company, which could be gleaned from company financials
3. Finally stack those impacts to all other impacts mentioned
Such causal logic is more akin to how a ReAct AI Agent might think instead of just a standalone LLM [Yao, et al 2022]. Agent planning is a hot research topic [Chen, et al 2024]
Disclaimers
The views, opinions, and conclusions expressed in this article are my own and do not reflect the views or positions of any of the entities mentioned or any other entities.
No data was used to model training nor was systematically collected from the sources mentioned, all techniques were limited to prompt engineering.
Resources
Earnings Call Transcripts (Motley Fool)
- Anheuser-Busch InBev (BUD) Q4 2024
- Autodesk (ADSK) Q4 2024
- Best Buy (BBY) Q4 2024
- DocuSign (DOCU) Q4 2024
- Kroger (KR) Q4 2024
- Nordstrom (JWN) Q4 2024
- Salesforce (CRM) Q4 2024
- Snowflake (SNOW) Q4 2024
News Articles
- Anheuser-Busch InBev (Reuters)
- Autodesk (Reuters)
- BestBuy (Bloomberg)
- DocuSign (Barron’s)
- Kroger (Barron’s)
- Nordstrom (Bloomberg)
- Salesforce (Bloomberg)
- Snowflake (Bloomberg)
AI vs. Human Insight in Financial Analysis was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
AI vs. Human Insight in Financial Analysis
Go Here to Read this Fast! AI vs. Human Insight in Financial Analysis