Tips for accelerating ML with AWS Neuron SDK

We are in a golden age of AI, with cutting-edge models disrupting industries and poised to transform life as we know it. Powering these advancements are increasingly powerful AI accelerators, such as NVIDIA H100 GPUs, Google Cloud TPUs, AWS’s Trainium and Inferentia chips, and more. With the growing number of options comes the challenge of selecting the most optimal platform for our machine learning (ML) workloads — a crucial decision considering the high costs associated with AI computation. Importantly, a comprehensive assessment of each option necessitates ensuring that we are maximizing its utilization to fully leverage its capabilities.
In this post, we will review several techniques for optimizing an ML workload on AWS’s custom-built AI chips using the AWS Neuron SDK. This continues our ongoing series of posts focused on ML model performance analysis and optimization across various platforms and environments (e.g., see here and here). While our primary focus will be on an ML training workload and AWS Inferentia2, the techniques discussed are also applicable to AWS Trainium. (Recall that although AWS Inferentia is primarily designed as an AI inference chip, we have previously demonstrated its effectiveness in training tasks as well.)
Generally speaking, performance optimization is an iterative process that includes a performance analysis step to appropriately identify performance bottlenecks and resource under-utilization (e.g., see here). However, since the techniques we will discuss are general purpose (i.e., they are potentially applicable to any model, regardless of their performance profile), we defer the discussion on performance analysis with the Neuron SDK to a future post.
Disclaimers
The code we will share is intended for demonstrative purposes only — we make no claims regarding its accuracy, optimality, or robustness. Please do not view this post as a substitute for the official Neuron SDK documentation. Please do not interpret our mention of any platforms, libraries, or optimization techniques as an endorsement for their use. The best options for you will depend greatly on the specifics of your use-case and will require your own in-depth investigation and analysis.
The experiments described below were run on an Amazon EC2 inf2.xlarge instance (containing two Neuron cores and four vCPUs). We used the most recent version of the Deep Learning AMI for Neuron available at the time of this writing, “Deep Learning AMI Neuron (Ubuntu 22.04) 20240927”, with AWS Neuron 2.20 and PyTorch 2.1. See the SDK documentation for more details on setup and installation. Keep in mind that the Neuron SDK is under active development and that the APIs we refer to, as well as the runtime measurements we report, may become outdated by the time you read this. Please be sure to stay up-to-date with the latest SDK and documentation available.
Toy Model
To facilitate our discussion, we introduce the following simple Vision Transformer (ViT)-backed classification model (based on timm version 1.0.10):
from torch.utils.data import Dataset
import time, os
import torch
import torch_xla.core.xla_model as xm
import torch_xla.distributed.parallel_loader as pl
from timm.models.vision_transformer import VisionTransformer
# use random data
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
rand_image = torch.randn([3, 224, 224], dtype=torch.float32)
label = torch.tensor(data=index % 1000, dtype=torch.int64)
return rand_image, label
def train(batch_size=16, num_workers=0):
# Initialize XLA process group for torchrun
import torch_xla.distributed.xla_backend
torch.distributed.init_process_group('xla')
# multi-processing: ensure each worker has same initial weights
torch.manual_seed(0)
dataset = FakeDataset()
model = VisionTransformer()
# load model to XLA device
device = xm.xla_device()
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters())
data_loader = torch.utils.data.DataLoader(dataset,
batch_size=batch_size,
num_workers=num_workers)
data_loader = pl.MpDeviceLoader(data_loader, device)
loss_function = torch.nn.CrossEntropyLoss()
summ = 0
count = 0
t0 = time.perf_counter()
for step, (inputs, targets) in enumerate(data_loader, start=1):
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_function(outputs, targets)
loss.backward()
xm.optimizer_step(optimizer)
batch_time = time.perf_counter() - t0
if step > 10: # skip first steps
summ += batch_time
count += 1
t0 = time.perf_counter()
if step > 500:
break
print(f'average step time: {summ/count}')
if __name__ == '__main__':
train()
# Initialization command:
# torchrun --nproc_per_node=2 train.py
Running our baseline model on the two cores of our AWS Inferentia instance, results in a training speed of 251.98 samples per second.
In the next sections, we will iteratively apply a number of potential optimization techniques and assess their impact on step time performance. While we won’t go into the full details of each method, we will provide references for further reading (e.g., here). Importantly, the list we will present is not all-inclusive — there are many techniques beyond what we will cover. We will organize the methods into three categories: PyTorch optimizations, OpenXLA optimizations, and Neuron-specific optimizations. However, the order of presentation is not binding. In fact, some of the techniques are interdependent — for example, applying the mixed precision optimization may free up enough device memory to enable increasing the batch size.
PyTorch Performance Optimizations
In previous posts (e.g., here) we have covered the topic of PyTorch model performance analysis and optimization on GPU, extensively. Many of the techniques we discussed are relevant to other AI accelerators. In this section we will revisit few of these techniques and apply them to AWS Inferentia.
Multi-process Data Loading
In multi process data loading the input data is prepared in one or more dedicated CPU processes rather than in the same process that runs the training step. This allows for overlapping the data loading and training which can increase system utilization and lead to a significant speed-up. The number of processes is controlled by the num_workers parameter of the PyTorch DataLoader. In the following block we run our script with num_workers set to one:
train(num_workers=1)
This change results in a training speed of 253.56 samples per second for a boost of less than 1%.
Batch Size Optimization
Another important hyperparameter that can influence training speed is the training batch size. Often, we have found that increasing the batch size improves system utilization and results in better performance. However, the effects can vary based on the model and platform. In the case of our toy model on AWS Inferentia, we find that running with a batch size of 8 samples per neuron core results in a speed of 265.68 samples per second — roughly 5% faster than a batch size of 16 samples per core.
train(batch_size=8, num_workers=1)
PyTorch Automatic Mixed Precision
Another common method for boosting performance is to use lower precision floats such as the 16-bit BFloat16. Importantly, some model components might not be compatible with reduced precision floats. PyTorch’s Automatic Mixed Precision (AMP) mode attempts to match the most appropriate floating point type to each model operation automatically. Although, the Neuron compiler offers different options for employing mixed precision, it also supports the option of using PyTorch AMP. In the code block below we include the modifications required to use PyTorch AMP.
def train(batch_size=16, num_workers=0):
# Initialize XLA process group for torchrun
import torch_xla.distributed.xla_backend
torch.distributed.init_process_group('xla')
# multi-processing: ensure each worker has same initial weights
torch.manual_seed(0)
dataset = FakeDataset()
model = VisionTransformer()
# load model to XLA device
device = xm.xla_device()
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters())
data_loader = torch.utils.data.DataLoader(dataset,
batch_size=batch_size,
num_workers=num_workers)
data_loader = pl.MpDeviceLoader(data_loader, device)
loss_function = torch.nn.CrossEntropyLoss()
summ = 0
count = 0
t0 = time.perf_counter()
for step, (inputs, targets) in enumerate(data_loader, start=1):
optimizer.zero_grad()
# use PyTorch AMP
with torch.autocast(dtype=torch.bfloat16, device_type='cuda'):
outputs = model(inputs)
loss = loss_function(outputs, targets)
loss.backward()
xm.optimizer_step(optimizer)
batch_time = time.perf_counter() - t0
if step > 10: # skip first steps
summ += batch_time
count += 1
t0 = time.perf_counter()
if step > 500:
break
print(f'average step time: {summ/count}')
if __name__ == '__main__':
# disable neuron compilar casting
os.environ["NEURON_CC_FLAGS"] = "--auto-cast=none"
torch.cuda.is_bf16_supported = lambda: True
train(batch_size=8, num_workers=1)
The resultant training speed is 196.64 samples per second, about 26% lower than the default mixed precision setting of the Neuron compiler. It’s important to note that while this post focuses on performance, in real-world scenarios, we would also need to evaluate the effect of the mixed precision policy we choose on model accuracy.
OpenXLA Optimizations
As discussed in a previous post, Neuron Cores are treated as XLA devices and the torch-neuronx Python package implements the PyTorch/XLA API. Consequently, any optimization opportunities provided by the OpenXLA framework, and specifically those offered by the PyTorch/XLA API, can be leveraged on AWS Inferentia and Trainium. In this section we consider a few of these opportunities.
BFloat16 Precision
OpenXLA supports the option of casting all floats to BFloat16 via the XLA_USE_BF16 environment variable, as shown in the code block below:
if __name__ == '__main__':
os.environ['XLA_USE_BF16'] = '1'
train(batch_size=8, num_workers=1)
The resultant training speed is 394.51 samples per second, nearly 50% faster than the speed of the default mixed precision option.
Multi-process Device Loading
The PyTorch/XLA MpDeviceLoader and its internal ParallelLoader, which are responsible for loading input data on to the accelerator, include a number of parameters for controlling the transfer of data from the host to the device. In the code block below we tune batches_per_execution setting which determines the number of batches copied to the device for each execution cycle of the ParallelLoader. By increasing this setting, we aim to reduce the overhead of the host-to-device communication:
data_loader = torch.utils.data.DataLoader(dataset,
batch_size=batch_size,
num_workers=num_workers
)
data_loader = pl.MpDeviceLoader(data_loader,
device, batches_per_execution=10)
As a result of this optimization, the training speed increased to 1,027.39 samples per second, representing an additional 260% speed-up.
Torch Compilation with OpenXLA Backend
In previous posts (e.g., here), we have demonstrated the potential performance gains from using PyTorch’s graph compilation offering. Although OpenXLA includes its own graph creation and Just-In-Time (JIT) compilation mechanisms, torch.compile can provide additional acceleration by eliminating the need for tracing the model operations at every step. The following code snippet demonstrates the use of the dedicated openxla backend for compiling the model:
model = model.to(device)
model = torch.compile(backend='openxla')
Although torch.compile is currently not yet supported by the Neuron SDK, we include its mention in anticipation of its future release.
Neuron SDK Optimizations
In this section we consider some of the optimization opportunities offered by the AWS Neuron SDK and, more specifically, by the Neuron compiler.
Mixed Precision
The Neuron SDK supports a variety of mixed precision settings. In the code block below we program the compiler to cast all floats to BFloat16 via the NEURON_CC_FLAGS environment variable.
if __name__ == '__main__':
os.environ["NEURON_CC_FLAGS"] = "--auto-cast all --auto-cast-type bf16"
train(batch_size=8, num_workers=1)
This results (unsurprisingly) in a similar training speed to the OpenXLA BFloat16 experiment described above.
FP8
One of the unique features of NeuronCoreV2 is its support of the eight-bit floating point type, fp8_e4m3. The code block below demonstrates how to configure the Neuron compiler to automatically cast all floating-point operations to FP8:
if __name__ == '__main__':
os.environ["NEURON_CC_FLAGS"] = "--auto-cast all --auto-cast-type fp8_e4m3"
train(batch_size=8, num_workers=1)
While FP8 can accelerate training in some cases, maintaining stable convergence can be more challenging than when using BFloat16 due its reduced precision and dynamic range. Please see our previous post for more on the potential benefits and challenges of FP8 training.
In the case of our model, using FP8 actually harms runtime performance compared to BFloat16, reducing the training speed to 940.36 samples per second.
Compiler Optimizations
The Neuron compiler includes a number of controls for optimizing the runtime performance of the compiled graph. Two key settings are model-type and opt-level. The model-type setting applies optimizations tailored to specific model architectures, such as transformers, while the opt-level setting allows for balancing compilation time against runtime performance. In the code block below, we program the model-type setting to tranformer and the opt-level setting to the highest performance option. We further specify the target runtime device, inf2, to ensure that the model is optimized for the target device.
if __name__ == '__main__':
os.environ['XLA_USE_BF16'] = '1'
os.environ["NEURON_CC_FLAGS"] = "--model-type transformer "
"--optlevel 3"
" --target inf2"
train(batch_size=8, num_workers=1)
The above configuration resulted in a training speed of 1093.25 samples per second, amounting to a modest 6% improvement.
Results
We summarize the results of our experiments in the table below. Keep in mind that the effect of each of the optimization methods we discussed will depend greatly on the model and the runtime environment.
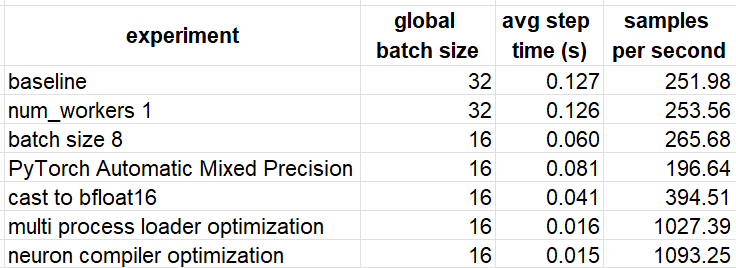
The techniques we employed resulted in a 435% performance boost compared to our baseline experiment. It is likely that additional acceleration could be achieved by revisiting and fine-tuning some of the methods we discussed, or by applying other optimization techniques not covered in this post.
Our goal has been demonstrate some of the available optimization strategies and demonstrate their potential impact on runtime performance. However, in a real-world scenario, we would need to assess the manner in which each of these optimizations impact our model convergence. In some cases, adjustments to the model configuration may be necessary to ensure optimal performance without sacrificing accuracy. Additionally, using a performance profiler to identify bottlenecks and measure system resource utilization is essential for guiding and informing our optimization activities.
Summary
Nowadays, we are fortunate to have a wide variety of systems on which to run our ML workloads. No matter which platform we choose, our goal is to maximize its capabilities. In this post, we focused on AWS Inferentia and reviewed several techniques for accelerating ML workloads running on it. Be sure to check out our other posts for more optimization strategies across various AI accelerators.
AI Model Optimization on AWS Inferentia and Trainium was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
AI Model Optimization on AWS Inferentia and Trainium
Go Here to Read this Fast! AI Model Optimization on AWS Inferentia and Trainium